Cybersecurity AI (CAI) Dataset
Pith reviewed 2026-06-29 12:04 UTC · model grok-4.3
The pith
A dataset of 230,935 cybersecurity LLM sessions reveals operators pasting live credentials into cloud prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
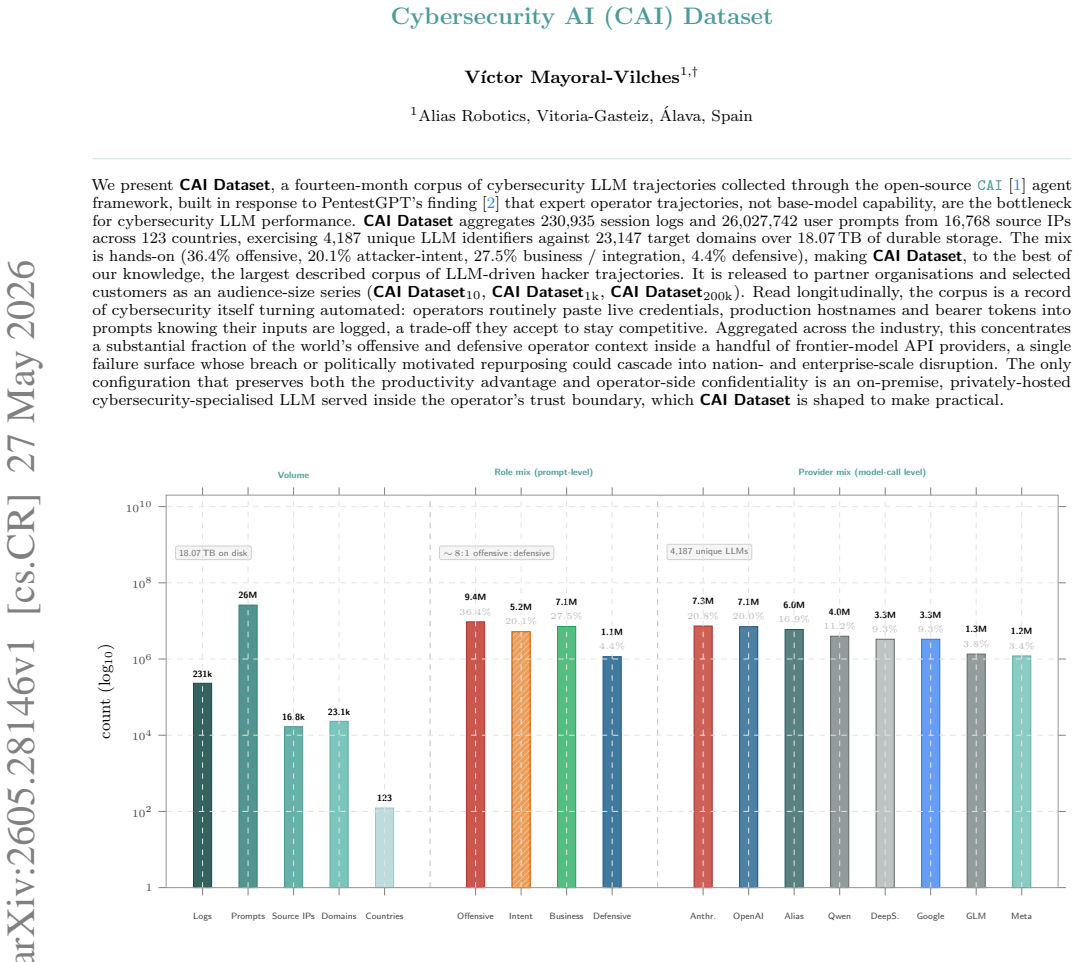
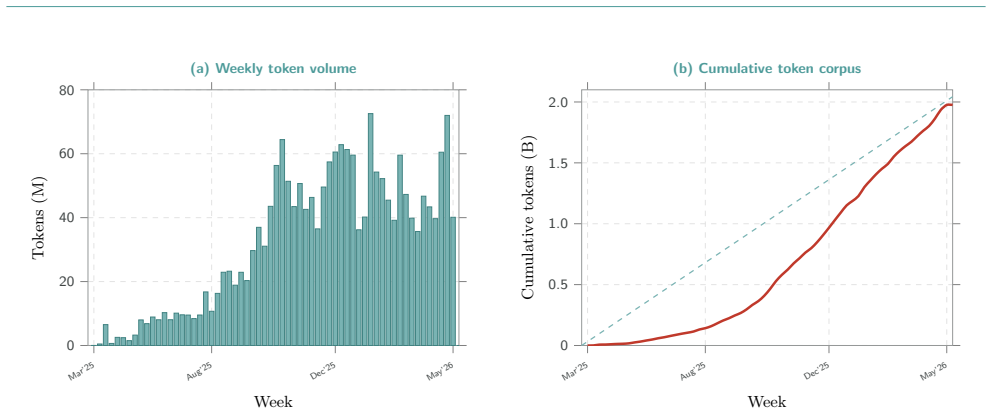
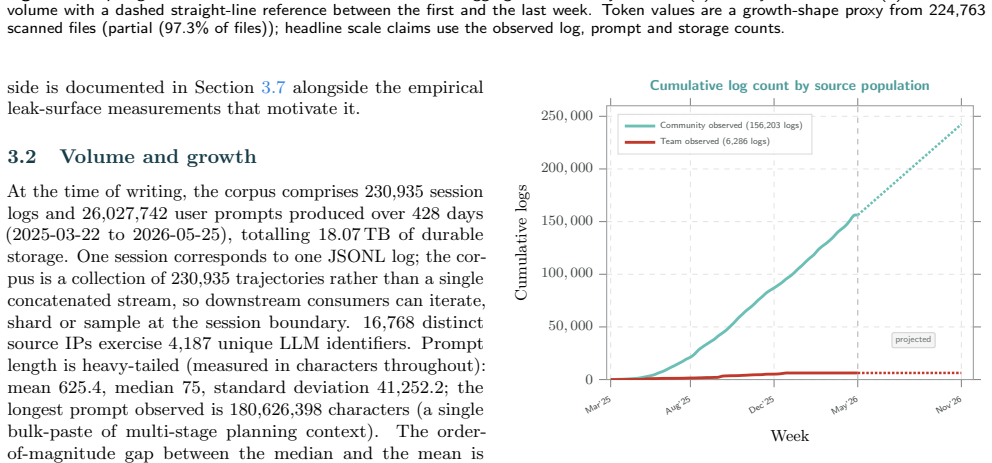
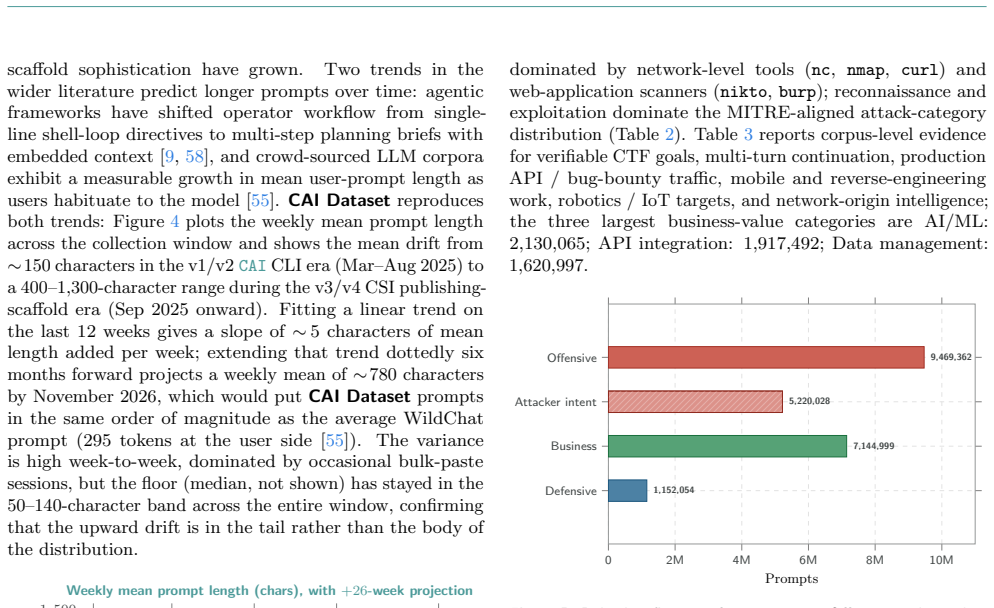
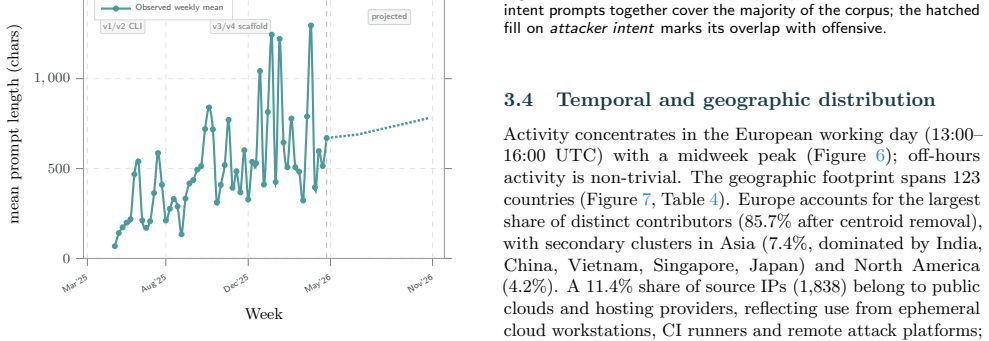
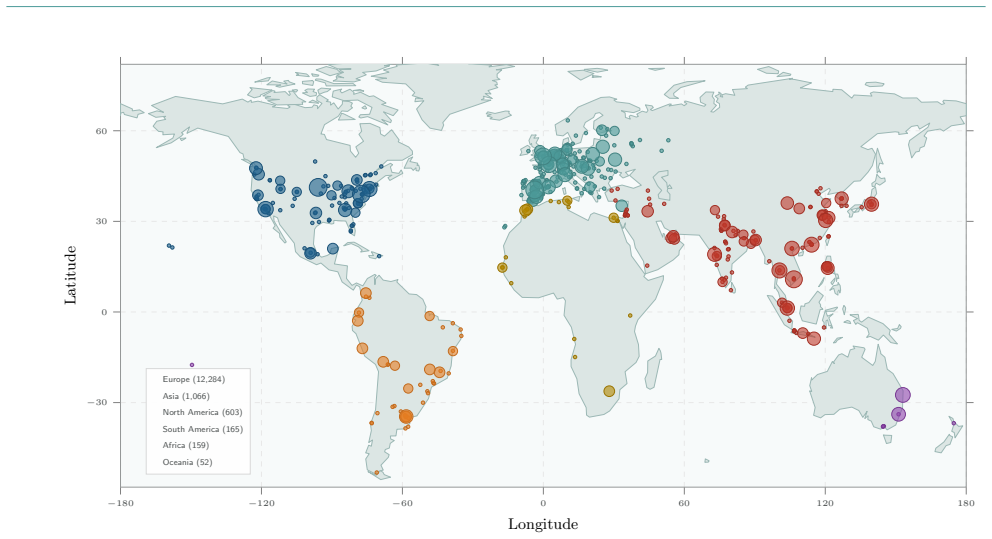
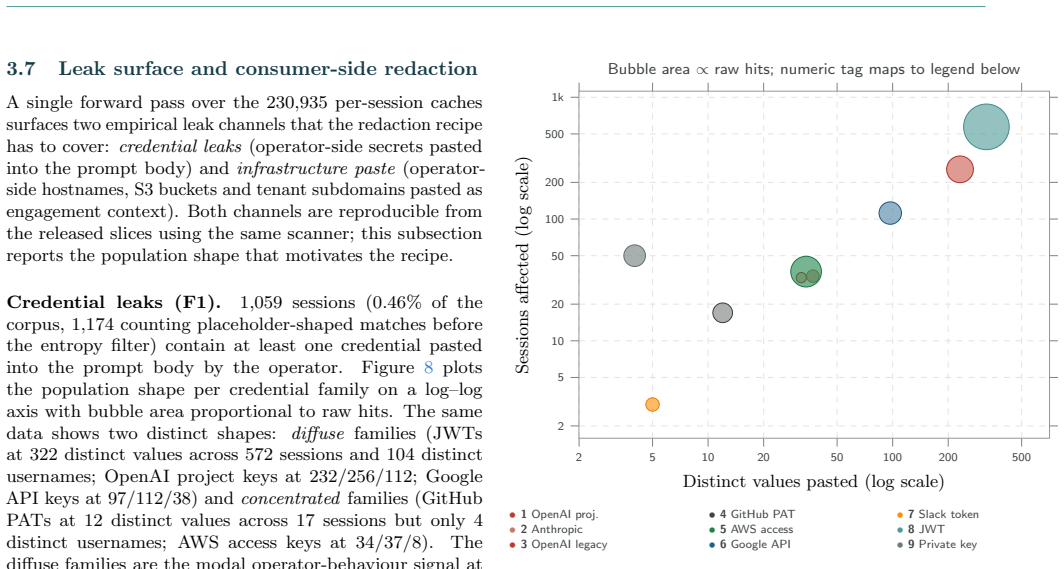
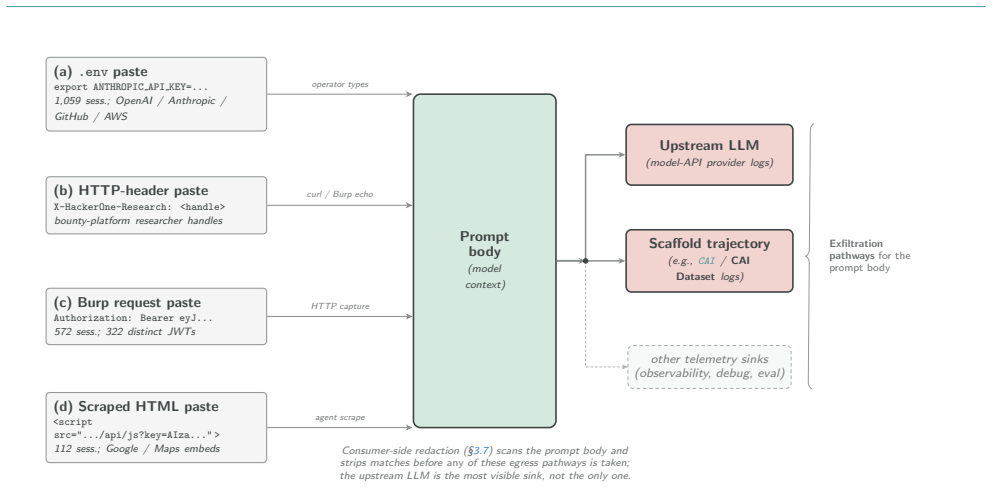
CAI Dataset aggregates 230,935 session logs and 26,027,742 user prompts from 16,768 source IPs across 123 countries, exercising 4,187 unique LLM identifiers against 23,147 target domains over 18.07 TB of durable storage. The mix includes 36.4% offensive, 20.1% attacker-intent, 27.5% business / integration, and 4.4% defensive sessions. Read longitudinally, the corpus records cybersecurity turning automated as operators paste live credentials, production hostnames and bearer tokens into prompts. This concentrates a substantial fraction of the world's offensive and defensive operator context inside a handful of frontier-model API providers, creating a single failure surface whose breach or poli
What carries the argument
The CAI Dataset itself, which serves as a record of LLM-driven hacker trajectories collected through the open-source CAI agent framework.
If this is right
- The concentration of operator context creates a single point of failure for cybersecurity operations worldwide.
- On-premise LLMs become necessary to maintain confidentiality while using AI assistance.
- The dataset enables training of specialized models for offensive and defensive tasks without cloud exposure.
- Release in audience-size series allows controlled distribution to partners and customers.
Where Pith is reading between the lines
- Similar concentration risks may exist in other fields like legal or medical AI applications where sensitive data enters prompts.
- This observation points to the potential value of decentralized or federated approaches to AI training in security domains.
- Future work could measure the actual performance gap between cloud and on-premise models using subsets of this dataset.
Load-bearing premise
The logs collected from 16,768 source IPs represent a substantial and representative fraction of global cybersecurity operator practices, and the pasting of live credentials is a widespread trend rather than specific to the users or collection method.
What would settle it
Finding that most cybersecurity professionals avoid pasting live production credentials into any LLM prompts, or that the 16,768 IPs correspond to a narrow subset of operators not representative of the field.
Figures

read the original abstract
We present CAI Dataset, a fourteen-month corpus of cybersecurity LLM trajectories collected through the open-source CAI agent framework, built in response to PentestGPT's finding that expert operator trajectories, not base-model capability, are the bottleneck for cybersecurity LLM performance. CAI Dataset aggregates 230,935 session logs and 26,027,742 user prompts from 16,768 source IPs across 123 countries, exercising 4,187 unique LLM identifiers against 23,147 target domains over 18.07 TB of durable storage. The mix is hands-on (36.4% offensive, 20.1% attacker-intent, 27.5% business / integration, 4.4% defensive), making CAI Dataset, to the best of our knowledge, the largest described corpus of LLM-driven hacker trajectories. It is released to partner organisations and selected customers as an audience-size series (CAI Dataset10, CAI Dataset1k, CAI Dataset200k). Read longitudinally, the corpus is a record of cybersecurity itself turning automated: operators routinely paste live credentials, production hostnames and bearer tokens into prompts knowing their inputs are logged, a trade-off they accept to stay competitive. Aggregated across the industry, this concentrates a substantial fraction of the world's offensive and defensive operator context inside a handful of frontier-model API providers, a single failure surface whose breach or politically motivated repurposing could cascade into nation- and enterprise-scale disruption. The only configuration that preserves both the productivity advantage and operator-side confidentiality is an on-premise, privately-hosted cybersecurity-specialised LLM served inside the operator's trust boundary, which CAI Dataset is shaped to make practical.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the CAI Dataset, a 14-month corpus of 230,935 cybersecurity LLM session logs (26,027,742 prompts) collected via the open-source CAI agent framework from 16,768 source IPs across 123 countries and 23,147 target domains. It reports usage statistics (36.4% offensive, 20.1% attacker-intent, etc.), claims this is the largest described corpus of LLM-driven hacker trajectories, notes operators pasting live credentials into prompts, and argues that concentration of such context in frontier-model API providers creates a single failure surface risking nation- and enterprise-scale disruption, recommending on-premise specialized LLMs instead.
Significance. If the collection methodology, representativeness, and bias controls can be established, the dataset release would be a valuable resource for research on real-world LLM trajectories in offensive and defensive cybersecurity, enabling studies of operator behavior and model misuse. The scale (18 TB, 4,187 LLMs) and longitudinal nature provide a concrete record of automation trends. The credential-pasting observation is a concrete, falsifiable finding that could inform API security practices.
major comments (2)
- [Abstract] Abstract: The central claims that the dataset is 'the largest described corpus' and that the 16,768 IPs represent 'a substantial fraction of the world's offensive and defensive operator context' whose breach 'could cascade into nation- and enterprise-scale disruption' rest on aggregate counts alone. No collection methodology, filtering rules, validation steps, bias controls, or baseline comparison to global LLM cybersecurity operator population or industry adoption statistics is supplied, rendering the extrapolation untestable and the security implications unsupported.
- [Dataset construction] Dataset construction (throughout): The paper supplies raw counts (230k sessions, 123 countries) and a usage mix but provides no description of how sessions were logged, deduplicated, or filtered from the CAI framework, nor any analysis of selection bias from users of one open-source tool who knowingly log credentials. This is load-bearing for all representativeness and industry-wide claims.
minor comments (2)
- [Abstract] Abstract, final sentence: The phrasing 'Read longitudinally, the corpus is a record of cybersecurity itself turning automated' is unclear; specify what longitudinal analysis is performed or intended.
- [Release description] Release description: The audience-size series (CAI Dataset10, CAI Dataset1k, CAI Dataset200k) is mentioned without defining the sampling or subsampling criteria used to create each tier.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address the major comments point by point below. Where the manuscript lacks necessary detail, we agree revisions are required and will incorporate them.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims that the dataset is 'the largest described corpus' and that the 16,768 IPs represent 'a substantial fraction of the world's offensive and defensive operator context' whose breach 'could cascade into nation- and enterprise-scale disruption' rest on aggregate counts alone. No collection methodology, filtering rules, validation steps, bias controls, or baseline comparison to global LLM cybersecurity operator population or industry adoption statistics is supplied, rendering the extrapolation untestable and the security implications unsupported.
Authors: We agree the abstract's strong claims on scale and security implications require explicit support. The full manuscript describes collection via the open-source CAI framework but does not include the requested methodology details, filtering rules, or bias analysis. In revision we will add a dedicated Dataset Construction section covering logging, deduplication, filtering, validation, and selection bias discussion, and will revise the abstract to qualify the 'largest described' and 'substantial fraction' statements with appropriate caveats tied to the CAI user population. revision: yes
-
Referee: [Dataset construction] Dataset construction (throughout): The paper supplies raw counts (230k sessions, 123 countries) and a usage mix but provides no description of how sessions were logged, deduplicated, or filtered from the CAI framework, nor any analysis of selection bias from users of one open-source tool who knowingly log credentials. This is load-bearing for all representativeness and industry-wide claims.
Authors: The current manuscript text does not supply the requested description of logging, deduplication, filtering, or selection-bias analysis. We will add this material in a new section, including how the open-source CAI agent records sessions, any deduplication steps applied, and explicit discussion of the bias inherent to users who choose to run and log with this particular framework. The credential-pasting observation is drawn directly from visible prompt content and does not depend on broader representativeness. revision: yes
- No public statistics exist on the total global population or industry adoption rates of LLM-driven cybersecurity operators, so a quantitative baseline comparison cannot be supplied.
Circularity Check
Dataset description contains no derivations or self-referential reductions
full rationale
The paper is a descriptive corpus release that reports raw collection statistics (230935 sessions, 16768 IPs, 123 countries) and qualitative observations about operator behavior. It contains no equations, fitted parameters, uniqueness theorems, or ansatzes. The central inference that the sample represents a substantial global fraction is an unquantified extrapolation rather than a reduction to any prior result by construction; the text supplies no self-citations that bear load on a derivation chain. The work is therefore self-contained as a data release with no circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 230,935 session logs collected through the CAI agent framework are representative of broader industry cybersecurity LLM usage.
Reference graph
Works this paper leans on
-
[1]
V´ ıctor Mayoral-Vilches, Mar´ ıa Sanz-G´ omez, Francesco Balassone, Stefan Rass, Lidia Salas-Espejo, Ben- jamin Jablonski, Luis Javier Navarrete-Lozano, Maite del Mundo de Torres, and Crist´ obal RJ Chavez. Cyber- security ai: A game-theoretic ai for guiding attack and defense.arXiv preprint arXiv:2601.05887, 2026
-
[2]
Pentestgpt: Evaluating and harnessing large language models for automated penetration testing.33rd USENIX Security Symposium (USENIX Security 24), pages 847–864, 2024
Gelei Deng, Yi Liu, V´ ıctor Mayoral-Vilches, Peng Liu, Yuekang Li, Yuan Xu, Tianwei Zhang, Yang Liu, Martin Pinzger, and Stefan Rass. Pentestgpt: Evaluating and harnessing large language models for automated penetration testing.33rd USENIX Security Symposium (USENIX Security 24), pages 847–864, 2024
2024
-
[3]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V. Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, Yuling Gu, Saumya Malik, Victoria Graf, Jena D. Hwang, Jiangjiang Yang, Ronan Le Bras, Oyvind Tafjord, Chris Wilhelm, Luca Soldaini, Noah A. Smith, Yizhong Wang, Pradeep Dasigi, and Hannaneh Ha- jishir...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
OpenHermes-2.5: An open dataset of synthetic data for generalist LLM assistants
Teknium. OpenHermes-2.5: An open dataset of synthetic data for generalist LLM assistants. https:// huggingface.co/datasets/teknium/OpenHermes-2.5,
-
[5]
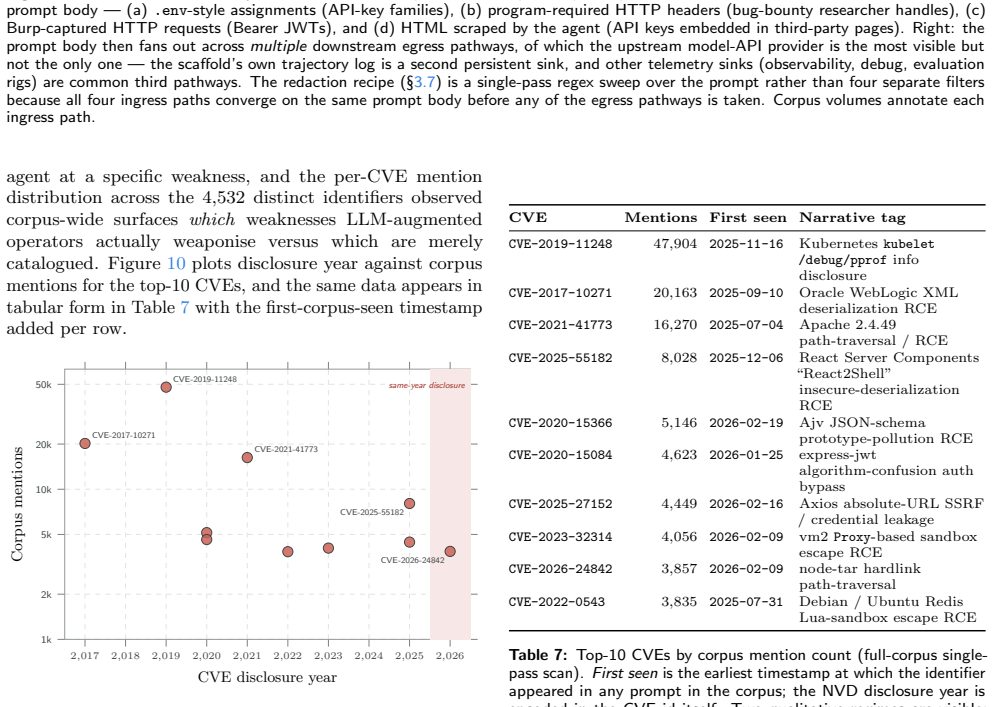
Accessed 2026-05-21
1,001,551 conversations. Accessed 2026-05-21
2026
-
[6]
Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing
Zhangchen Xu, Fengqing Jiang, Luyao Niu, Yuntian Deng, Radha Poovendran, Yejin Choi, and Bill Yuchen Lin. Magpie: Alignment data synthesis from scratch by prompting aligned LLMs with nothing. InProceedings of the International Conference on Learning Represen- tations (ICLR), 2025. URL https://arxiv.org/abs/ 2406.08464. arXiv:2406.08464. Self-synthesised S...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Nemotron-Post-Training-Dataset- v1
NVIDIA. Nemotron-Post-Training-Dataset- v1. https://huggingface.co/datasets/nvidia/ Nemotron-Post-Training-Dataset-v1 , 2025. 40 M+ post-training samples covering code, math, reasoning, tool use, and general chat. Released under permissive licence; the largest open post-training mixture as of late 2025
2025
-
[8]
Fixing it in post: A comparative study of LLM post-training data quality and model performance, 2025
Cagri Aktas et al. Fixing it in post: A comparative study of LLM post-training data quality and model performance, 2025. URL https://arxiv.org/abs/ 2506.06522. arXiv:2506.06522. Direct comparison of Tulu-3-SFT-Mix and SmolTalk under matched training
-
[9]
CyberLLMInstruct authors. CyberLLMInstruct: A pseudo-malicious dataset revealing safety-performance trade-offs in cyber security LLM fine-tuning. InProceed- ings of the 18th ACM Workshop on Artificial Intelligence and Security (AISec ’25), 2025. URL https://arxiv. org/abs/2503.09334. arXiv:2503.09334. 54,928 pseudo- malicious instruction-response pairs
-
[10]
Agent data protocol: Unifying datasets for diverse, effective fine-tuning of LLM agents, 2025
Yueqi Song, Ketan Ramaneti, Zaid Sheikh, Ziru Chen, Boyu Gou, et al. Agent data protocol: Unifying datasets for diverse, effective fine-tuning of LLM agents, 2025. URL https://arxiv.org/abs/2510. 24702. arXiv:2510.24702. Cross-framework agent trajec- tory transfer loses 15–25% without format alignment
-
[12]
Two- stage offline-RL (GRPO over 14K Thought-Command- Observation tuples) + online-RL pipeline
URL https://arxiv.org/abs/2508.07382. Two- stage offline-RL (GRPO over 14K Thought-Command- Observation tuples) + online-RL pipeline. 24.2% on AutoPenBench, 15.0% on Cybench
-
[13]
Cordeiro, and Vasileios Mavroeidis
Norbert Tihanyi, Tam´ as Bisztray, Ridhi Jain, Mo- hamed Amine Ferrag, Lucas C. Cordeiro, and Vasileios Mavroeidis. CyberMetric: A benchmark dataset based on retrieval-augmented generation for eval- uating LLMs in cybersecurity knowledge.arXiv preprint, 2024. URL https://arxiv.org/abs/2402. 07688. arXiv:2402.07688
-
[14]
Zefang Liu. SecQA: A concise question-answering dataset for evaluating large language models in com- puter security.arXiv preprint, 2023. URL https: //arxiv.org/abs/2312.15838. arXiv:2312.15838
-
[15]
Johan Wahr´ eus, Ahmed Mohamed Hussain, and Pana- giotis Papadimitratos. CySecBench: Generative AI- based CyberSecurity-focused prompt dataset for bench- marking large language models, 2024. URL https: //arxiv.org/abs/2501.01335. arXiv:2501.01335
-
[16]
MITRE ATT&CK frame- work
The MITRE Corporation. MITRE ATT&CK frame- work. https://attack.mitre.org/, 2024. Accessed 2026-05-21
2024
-
[17]
Scaling trusted access for cyber with gpt-5.5 and gpt-5.5-cyber
OpenAI. Scaling trusted access for cyber with gpt-5.5 and gpt-5.5-cyber. https://openai.com/index/gpt-5- 5-with-trusted-access-for-cyber/ , 2026. Accessed 2026-05-22
2026
-
[18]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. DeepSeek-R1: Incentivizing reason- ing capability in LLMs via reinforcement learn- ing, 2025. URL https://arxiv.org/abs/2501.12948. arXiv:2501.12948. 800,000-record reasoning-trace SFT mix
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
CTIBench: A benchmark for evaluating LLMs in cyber threat intelligence, 2024
Md Tanvirul Alam, Dipkamal Bhatt, and Nidhi Rastogi. CTIBench: A benchmark for evaluating LLMs in cyber threat intelligence, 2024. URL https://arxiv.org/ abs/2406.07599. arXiv:2406.07599
-
[20]
Heimdall v1.1: Cybersecurity dataset for defensive LLM fine-tuning
Innovatiana. Heimdall v1.1: Cybersecurity dataset for defensive LLM fine-tuning. https://www.innovatiana. com/en/datasets/cybersecurity-heimdall-v1-1 ,
-
[21]
Accessed 2026-05-21
21,000+ defensive system/user/assistant dialogues. Accessed 2026-05-21
2026
-
[22]
Zhang, Neil Perry, Riya Dulepet, Joey Jones, Justin W
Andy K. Zhang, Neil Perry, Riya Dulepet, Eliot Jones, Justin W. Lin, Joey Ji, Celeste Menders, Gashon Hussein, Samantha Liu, Donovan Jasper, et al. Cybench: A framework for evaluating cybersecurity capabilities and risks of language models, 2024. URL https: //arxiv.org/abs/2408.08926. arXiv:2408.08926
-
[23]
Meet Udeshi, Minghao Shao, Haoran Xi, Jaeyong Jeon, Ezra Chen, Soham Mukherjee, Ramesh Karri, Siddharth Garg, Hammond Pearce, Brendan Dolan-Gavitt, and Muhammad Shafique. D-CIPHER: Dynamic collab- orative intelligent multi-agent system with LLMs for offensive security, 2025. URL https://arxiv.org/abs/ 2502.10931. arXiv:2502.10931
-
[24]
CTFTiny / CTFJudge authors. Towards effec- tive offensive security LLM agents: Hyperparameter tuning, LLM as a judge, and a lightweight CTF benchmark, 2025. URL https://arxiv.org/abs/2508. 05674. arXiv:2508.05674
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
CyberPal.AI: Empowering LLMs with expert- driven cybersecurity instructions, 2024
Matan Levi, Meir Kalech, Ofir Inbar, Boaz Carmeli, et al. CyberPal.AI: Empowering LLMs with expert- driven cybersecurity instructions, 2024. URL https:// arxiv.org/abs/2408.09304. arXiv:2408.09304. Source of the SecKnowledge instruction dataset
-
[27]
Foundation-Sec-8B: A cyberse- curity foundation model, 2025
Amin Karbasi et al. Foundation-Sec-8B: A cyberse- curity foundation model, 2025. URL https://arxiv. org/abs/2504.21039. arXiv:2504.21039. Llama-3.1-8B continued pretrained on 5.1B curated cybersecurity tokens; matches Llama-3.1-70B / GPT-4o-mini on cyber- specific tasks
-
[28]
Trend Micro Research. Llama-Primus: Continued pre- training, instruction-following, and reasoning variants for cybersecurity, 2025. URL https://arxiv.org/abs/ 2502.11191. arXiv:2502.11191. Llama-3.1-8B-Instruct base; +15.88% aggregated cybersec benchmark gain
-
[29]
SecureBERT 2.0: A modernbert- based cybersecurity encoder, 2025
Ehsan Aghaei et al. SecureBERT 2.0: A modernbert- based cybersecurity encoder, 2025. URL https:// arxiv.org/abs/2510.00240. arXiv:2510.00240. 13B text tokens + 53M code tokens of continued MLM pretraining
-
[30]
CySecBERT: A domain-adapted language model for the cybersecurity domain.arXiv preprint, 2024
Markus Bayer, Philipp Kuehn, Ramin Shanehsaz, and Christian Reuter. CySecBERT: A domain-adapted language model for the cybersecurity domain.arXiv preprint, 2024. URL https://arxiv.org/abs/2212. 02974. arXiv:2212.02974. 4.3M cybersec documents ( 528M tokens) of continued MLM pretraining
-
[31]
Salahuddin Salahuddin, Ahmed Hussain, Jussi L¨ opp¨ onen, Toni Jutila, and Panos Papadimitratos. Less data, more security: Advancing cybersecurity LLMs specialization via resource-efficient domain- adaptive continuous pre-training with minimal to- kens, 2025. URL https://arxiv.org/abs/2507.02964. arXiv:2507.02964. 126 M-word cybersecurity corpus; DAP on L...
-
[32]
Mohamed Amine Ferrag, Ammar Battah, Norbert Tihanyi, et al. SecureFalcon: Detecting software vulner- abilities with a small cybersecurity-specialised falcon- based model.arXiv preprint, 2023. URL https:// arxiv.org/abs/2307.06616. arXiv:2307.06616. Falcon- 40B distilled to 121M / 44M; 94% binary / 92% multi- class on FormAI
-
[34]
Lily-Cybersecurity-7B-v0.2: Mistral- 7b sft on a curated cybersecurity qa mix
Segolily Labs. Lily-Cybersecurity-7B-v0.2: Mistral- 7b sft on a curated cybersecurity qa mix. https://huggingface.co/segolilylabs/Lily- Cybersecurity-7B-v0.2, 2024. 22k hand-crafted cybersec QA pairs; 5 epochs on 1xA100
2024
-
[35]
ZySec-7B (SecurityLLM): Dpo-tuned zephyr- 7b for cybersecurity
ZySec AI. ZySec-7B (SecurityLLM): Dpo-tuned zephyr- 7b for cybersecurity. https://huggingface.co/ZySec- AI/SecurityLLM, 2024. DPO on a 30+ cybersec domain preferences set (CIS, FedRAMP, PCI DSS, ATT&CK)
2024
-
[36]
WhiteRabbitNeo: Uncensored red/blue-team models on llama-2 and qwen2.5 bases
Migel Tissera. WhiteRabbitNeo: Uncensored red/blue-team models on llama-2 and qwen2.5 bases. https://huggingface.co/WhiteRabbitNeo/ WhiteRabbitNeo-13B-v1, 2023. Reference uncensored offensive-security LLM family; v2.5 rebases on Qwen2.5 with 1.7M offensive/defensive samples
2023
-
[37]
DeepHat-V1 / V2 (whiterabbitneo successor)
Migel Tissera and DeepHat AI. DeepHat-V1 / V2 (whiterabbitneo successor). https://huggingface.co/ DeepHat/DeepHat-V1-7B, 2025. Qwen2.5-Coder-7B base; 131K context. V1-32B reportedly matches models 10x its size on Cybench autonomous CTF
2025
-
[38]
SEvenLLM: A bilingual instruction-tuned cybersecurity lm and benchmark,
Hangyuan Ji et al. SEvenLLM: A bilingual instruction-tuned cybersecurity lm and benchmark,
- [39]
-
[40]
SecLM / Sec-Gemini v1: Security-specialised foundation api
Google Cloud Security. SecLM / Sec-Gemini v1: Security-specialised foundation api. https: //medium.com/google-cloud/seclm-what-why-and- how-c899dc44bcee, 2024. Gemini-in-Security backbone with Mandiant + VirusTotal grounding; +15–20% on malware / query generation, -40% triage time
2024
-
[41]
Terry Zhuo et al. Cyber-Zero: Runtime-free trajectory synthesis for cybersecurity agents, 2025. URL https: //arxiv.org/abs/2508.00910. arXiv:2508.00910. Persona-driven LLM simulation of CTF writeups; +13.1% absolute on InterCode-CTF / NYU-CTF / Cybench
-
[42]
CTF-Dojo: Executable-environment trajectory training for cyber agents, 2025
Terry Zhuo et al. CTF-Dojo: Executable-environment trajectory training for cyber agents, 2025. URL https: //arxiv.org/abs/2508.18370. arXiv:2508.18370
-
[43]
Tuan Luong et al. xOffense: Multi-agent cot pen- test framework on qwen3-32b, 2025. URL https:// arxiv.org/abs/2509.13021. arXiv:2509.13021. 79.17% sub-task completion on AutoPenBench + AI-Pentest- Benchmark
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Reinforcement learning for cryptographic CTF solving on Llama-3.1-8B,
Imre Muzsai et al. Reinforcement learning for cryptographic CTF solving on Llama-3.1-8B,
-
[45]
URL https://arxiv.org/abs/2506.02048. arXiv:2506.02048. GRPO on Random-Crypto; Pass@8 0.35 -¿ 0.88
-
[46]
Post-training local LLM agents for Linux privilege escalation with verifiable re- wards, 2026
Philipp Normann, Andreas Happe, J¨ urgen Cito, and Daniel Arp. Post-training local LLM agents for Linux privilege escalation with verifiable re- wards, 2026. URL https://arxiv.org/abs/2603. 17673. arXiv:2603.17673. PrivEsc-LLM (Qwen3-4B); SFT on 1,000 procedural traces + RLVR; 95.8% root@R=20
-
[47]
Hackphyr: A local fine-tuned LLM agent for network se- curity environments.arXiv preprint, 2024
Maria Rigaki, Carlos Catania, and Sebastian Garcia. Hackphyr: A local fine-tuned LLM agent for network se- curity environments.arXiv preprint, 2024. URL https: //arxiv.org/abs/2409.11276. arXiv:2409.11276
-
[48]
Foundation-sec-8b- reasoning: A specialized cybersecurity reasoning model
Cisco Foundation AI Team. Foundation-sec-8b- reasoning: A specialized cybersecurity reasoning model. https://blogs.cisco.com/security/ foundation-sec-8b-reasoning-worlds-first- security-reasoning-model, 2025. Accessed 2026-05- 21
2025
-
[49]
Fine-tuning of large language models for domain-specific cybersecurity knowledge,
Yuan Huang. Fine-tuning of large language models for domain-specific cybersecurity knowledge,
-
[50]
URL https://arxiv.org/abs/2509.25241. arXiv:2509.25241. Head-to-head comparison of SFT, LoRA, and QLoRA on cybersecurity tasks; documents the prompt-length distribution shift under domain- specific fine-tuning
-
[51]
Toward cybersecurity-expert small language models, 2025
Xiaoxiao Yu et al. Toward cybersecurity-expert small language models, 2025. URL https://arxiv.org/abs/ 2510.14113. arXiv:2510.14113
-
[52]
SmolTalk: An open synthetic multi-source sft dataset for small language models
Loubna Ben Allal, Anton Lozhkov, Elie Bakouch, Guilherme Penedo, Leandro von Werra, et al. SmolTalk: An open synthetic multi-source sft dataset for small language models. https://huggingface.co/datasets/ HuggingFaceTB/smoltalk, 2024. Approximately 1.1 M records. Accessed 2026-05-21
2024
-
[53]
Llama-nemotron: Efficient reasoning models,
Akhiad Bercovich, Suchet Chowdhury, Patrick Curtis, Megha Davis, Aria Diran, Coleman Hooper, Erez Issakov, Kris Kanada, Pawel Kuijper, et al. Llama-nemotron: Efficient reasoning models,
-
[54]
Llama-nemotron: Efficient reasoning models [J]
URL https://arxiv.org/abs/2505.00949. arXiv:2505.00949. NVIDIA Llama-Nemotron family; five-stage NAS+CPT+SFT+RL+RLHF post-training; SFT mixes reasoning and non-reasoning traces
-
[55]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal
Teknium, Dakota Mahan, and Nous Research. Hermes 3 technical report, 2024. URL https://arxiv.org/ abs/2408.11857. arXiv:2408.11857. Llama-3.1-based; canonical ChatML +<tool call>XML format
-
[56]
Qwen3 technical report
Qwen Team. Qwen3 technical report. https://qwenlm. github.io/blog/qwen3/, 2025. Accessed 2026-05-21
2025
-
[57]
Front-loading reasoning: The synergy between pretraining and post-training data
NVIDIA ADLR. Front-loading reasoning: The synergy between pretraining and post-training data. https://research.nvidia.com/labs/adlr/files/ Front_Loading_Reasoning_The_Synergy_between_ Pretraining_and_Post_Training_Data.pdf, 2025. NVIDIA technical report. Shows reasoning data in pretraining stabilises subsequent SFT and reduces catastrophic forgetting
2025
-
[58]
Toolace: Winning the points of llm function calling
Weiwen Liu, Xu Huang, Xingshan Zeng, Xinlong Hao, Shuai Yu, Dexun Li, Shuai Wang, Weinan Gan, Zhengying Liu, Yuanqing Yu, et al. ToolACE: Winning the points of LLM function calling, 2024. URL https: //arxiv.org/abs/2409.00920. arXiv:2409.00920. Syn- thetic function-calling SFT dataset; ToolACE-8B is a Llama-3.1-8B-Instruct SFT’d on it
-
[59]
ToolMind technical report: A large-scale, reasoning-enhanced tool-use dataset,
ToolMind authors. ToolMind technical report: A large-scale, reasoning-enhanced tool-use dataset,
-
[60]
URL https://arxiv.org/abs/2511.15718. arXiv:2511.15718. Reasoning-enhanced multi-turn tool- use SFT dataset addressing scale, multi-turn and diversity limitations of earlier function-call corpora
-
[61]
Han Zhao, Haotian Wang, Yiping Peng, Sitong Zhao, Xiaoyu Tian, et al. AM-DeepSeek-R1-Distilled: 1.4 million open-source distilled reasoning dataset to em- power large language model training, 2025. URL https: //arxiv.org/abs/2503.19633. arXiv:2503.19633
-
[62]
Lmsys-chat-1m: A large-scale real-world llm conversation dataset,
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Tianle Li, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zhuohan Li, Zi Lin, Eric P. Xing, Joseph E. Gonzalez, Ion Stoica, and Hao Zhang. LMSYS-Chat-1M: A large-scale real-world LLM conversation dataset. In Proceedings of the International Conference on Learning Representations (ICLR), 2024. URL https://arxiv. org/...
-
[63]
WildChat: 1m ChatGPT interaction logs in the wild
Wenting Zhao, Xiang Ren, Jack Hessel, Claire Cardie, Yejin Choi, and Yuntian Deng. WildChat: 1m ChatGPT interaction logs in the wild. InProceedings of the International Conference on Learning Representations (ICLR), 2024. URL https://arxiv.org/abs/2405. 01470
2024
-
[64]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? InProceedings of the International Conference on Learning Representations (ICLR), 2024. URL https://arxiv.org/abs/2310. 06770
2024
-
[65]
ToolACE- R: Iterative refinement for function-calling generalisa- tion, 2025
Weiwen Liu, Xu Huang, Xingshan Zeng, et al. ToolACE- R: Iterative refinement for function-calling generalisa- tion, 2025. URL https://arxiv.org/abs/2504.01400. arXiv:2504.01400. Cross-template generalisation on BFCL and API-Bank
-
[66]
Executable code actions elicit better LLM agents, 2024
Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, and Heng Ji. Executable code actions elicit better LLM agents, 2024. URL https: //arxiv.org/abs/2402.01030. arXiv:2402.01030. Col- lapses heterogeneous tool calls into a single Python action space; up to +20% success-rate over JSON tool- calling baselines on API-Bank
-
[67]
What do agents learn from trajectory- SFT: Semantics or interfaces?, 2025
PIPE authors. What do agents learn from trajectory- SFT: Semantics or interfaces?, 2025. URL https:// arxiv.org/abs/2602.01611. arXiv:2602.01611. Across 16 environments from AgentBench and Agent-Gym, trajectory-SFT amplifies interface shortcutting; trained agents degrade sharply under minimal interface rewrites
-
[68]
Natural earth 1:110m physical vectors: Land
Natural Earth. Natural earth 1:110m physical vectors: Land. https://www.naturalearthdata. com/downloads/110m-physical-vectors/110m-land/ ,
-
[69]
Used for the simplified land silhouettes in the contributor map
Accessed 2026-05-22. Used for the simplified land silhouettes in the contributor map
2026
-
[70]
Duplodocus: Exact and MinHash deduplication of large-scale text datasets
Allen Institute for AI. Duplodocus: Exact and MinHash deduplication of large-scale text datasets. https:// github.com/allenai/duplodocus, 2024. Rust imple- mentation; memory- and disk-based modes for JSONL corpora. Accessed 2026-05-21
2024
-
[71]
SEDD: Scalable and Efficient Dataset Deduplication with GPUs
Donghyun Kim et al. FED: Fast and efficient dataset deduplication framework with GPU acceleration. In arXiv preprint, 2025. URL https://arxiv.org/abs/ 2501.01046. arXiv:2501.01046. 107 × speedup over SlimPajama CPU baseline
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[72]
RealSafe-R1: Safety-aligned DeepSeek-R1 without compromising reasoning capabil- ity, 2025
Yichi Zhang et al. RealSafe-R1: Safety-aligned DeepSeek-R1 without compromising reasoning capabil- ity, 2025. URL https://arxiv.org/abs/2504.10081. arXiv:2504.10081. 15,000-trajectory safety SFT layer that recovers refusal rates without erasing reasoning gains
-
[73]
CVE-2021- 41773: Apache HTTP Server 2.4.49 path-traversal / rce,
NIST National Vulnerability Database. CVE-2021- 41773: Apache HTTP Server 2.4.49 path-traversal / rce,
2021
-
[74]
chat.completion
URL https://nvd.nist.gov/vuln/detail/CVE- 2021-41773. Path-traversal vulnerability in Apache 2.4.49 enabling source-code disclosure and remote code execution under specific configuration. A Log-format evolution The corpus spans four on-disk schema versions, produced as the publishing scaffold changed. Versions v1 and v2 originate from the CAI CLI; version...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.