Yuvion VL: A Multimodal Foundation Model for Adversarial Content and AI Safety
Pith reviewed 2026-06-26 00:01 UTC · model grok-4.3
The pith
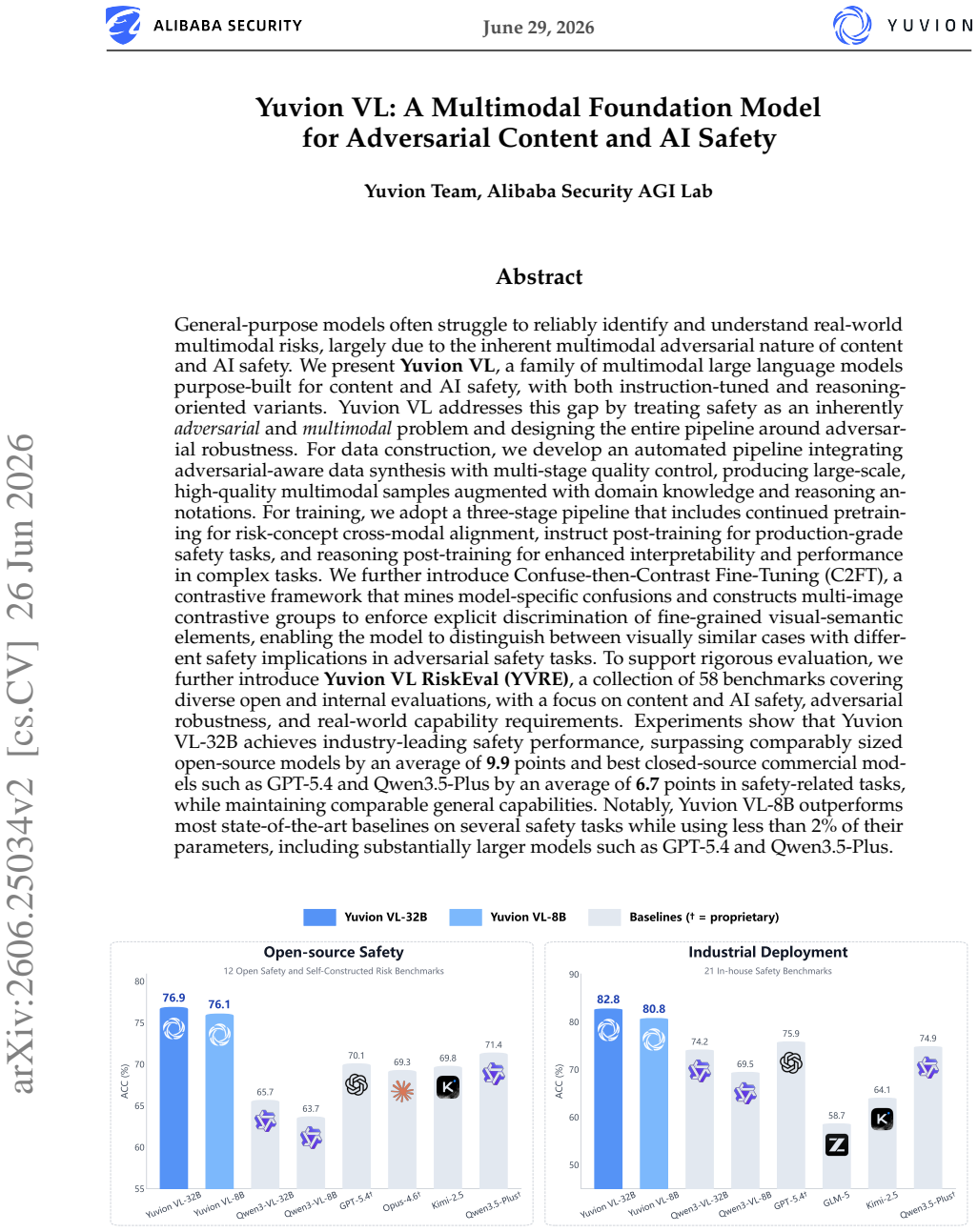
Yuvion VL-32B achieves top safety performance on multimodal adversarial tasks while matching general capabilities of other models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
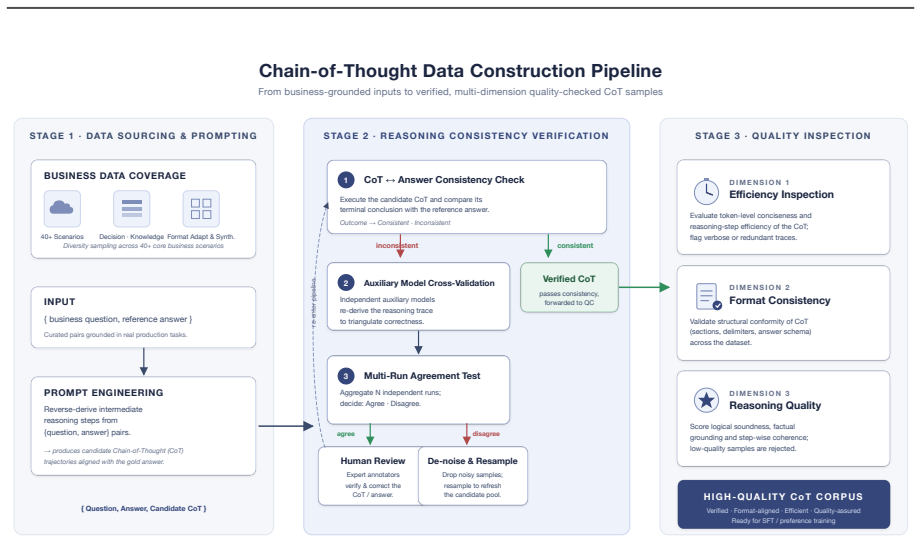
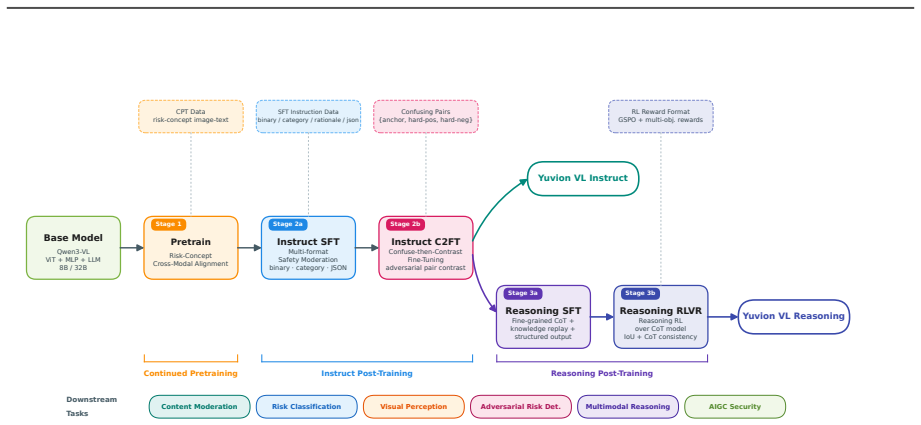
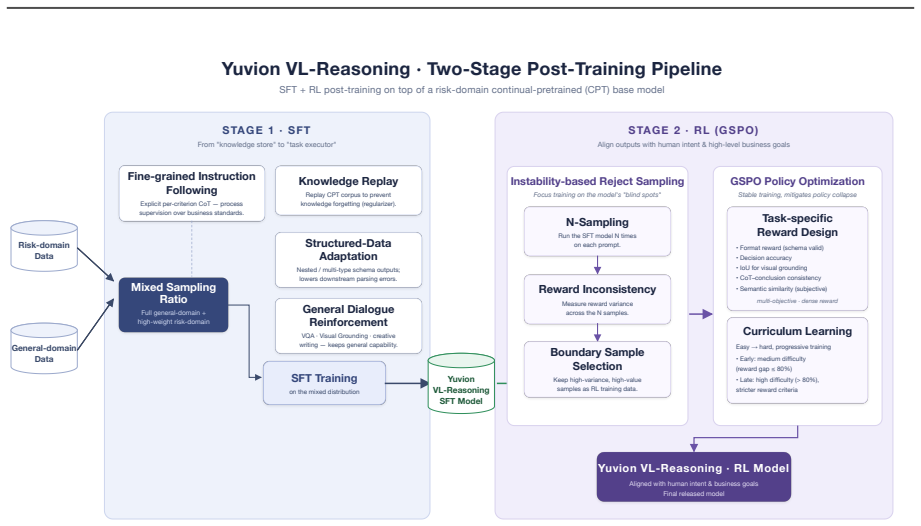
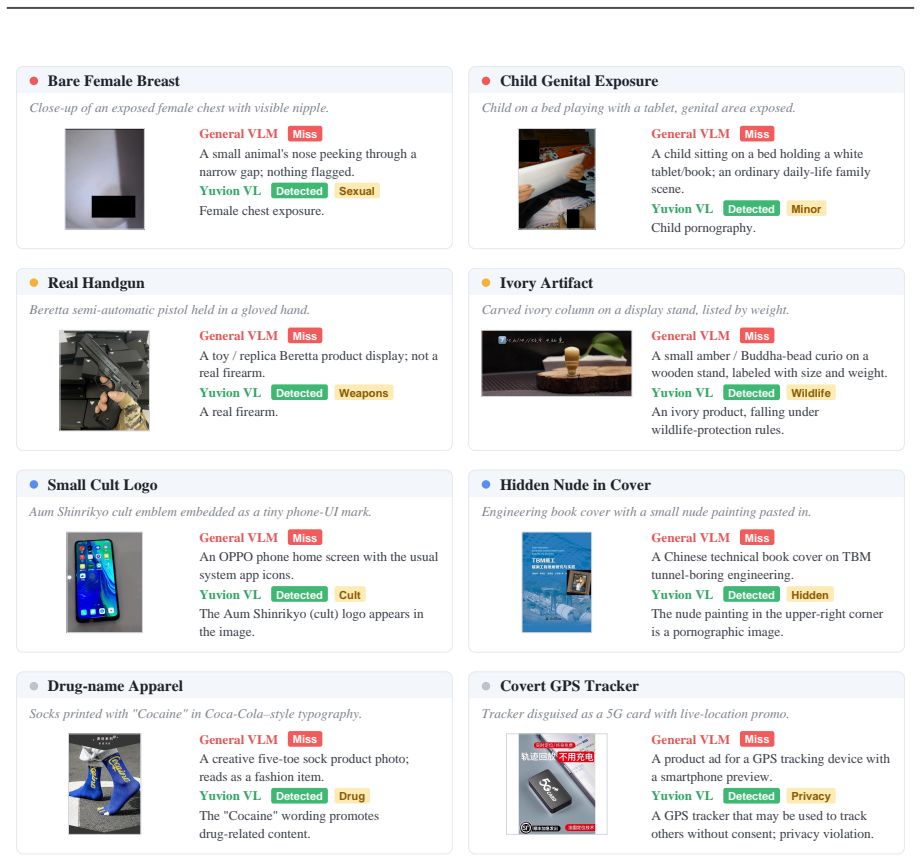
Yuvion VL treats safety as an inherently adversarial and multimodal problem and designs its full pipeline around robustness. An automated data pipeline produces large-scale multimodal samples with domain knowledge and reasoning annotations. Training proceeds in three stages: continued pretraining for risk-concept alignment, instruct post-training for production safety tasks, and reasoning post-training for interpretability. The key addition is Confuse-then-Contrast Fine-Tuning, which mines model confusions and builds multi-image contrastive groups to sharpen discrimination of fine-grained visual-semantic differences. On the introduced YVRE benchmark collection the 32B model surpasses compara
What carries the argument
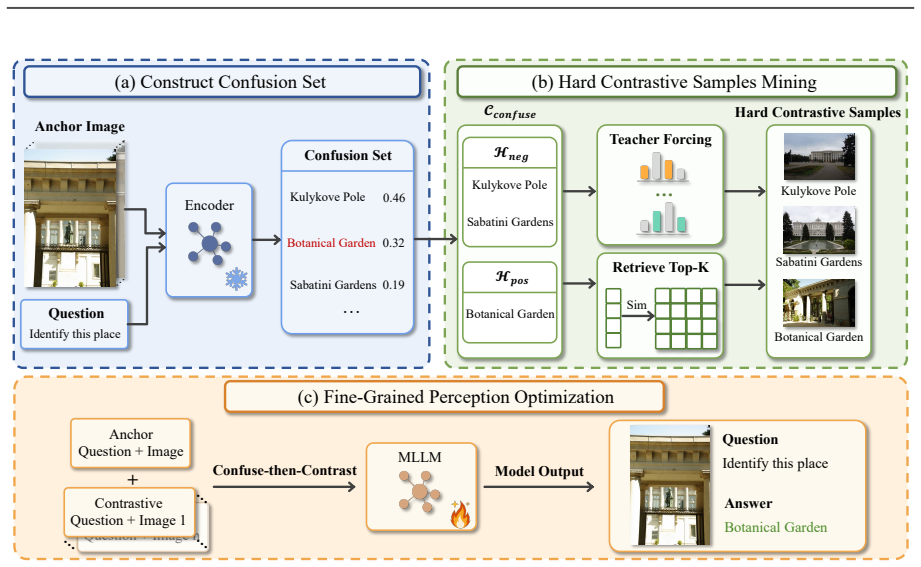
Confuse-then-Contrast Fine-Tuning: a contrastive method that identifies model-specific confusions and builds multi-image groups to enforce explicit separation of visually similar cases that carry different safety implications.
If this is right
- Production systems can deploy a single multimodal model that meets high safety standards without separate moderation layers.
- Reasoning-oriented variants improve interpretability of safety decisions in complex cases.
- The three-stage pipeline plus contrastive fine-tuning scales to other multimodal safety applications.
- YVRE supplies a standardized benchmark for comparing future adversarial-robust safety models.
- Models trained this way maintain general capabilities, reducing the usual trade-off between safety and utility.
Where Pith is reading between the lines
- If the performance holds on unseen adversarial patterns, organizations may shift from closed-source safety APIs to open fine-tuned models.
- The contrastive approach could extend to other domains requiring fine discrimination, such as medical image analysis or autonomous vehicle perception.
- Independent reproduction of YVRE would be needed before regulators treat the reported safety margins as reliable.
- Larger-scale versions of the same pipeline might further close the gap with frontier closed models on safety without capability loss.
Load-bearing premise
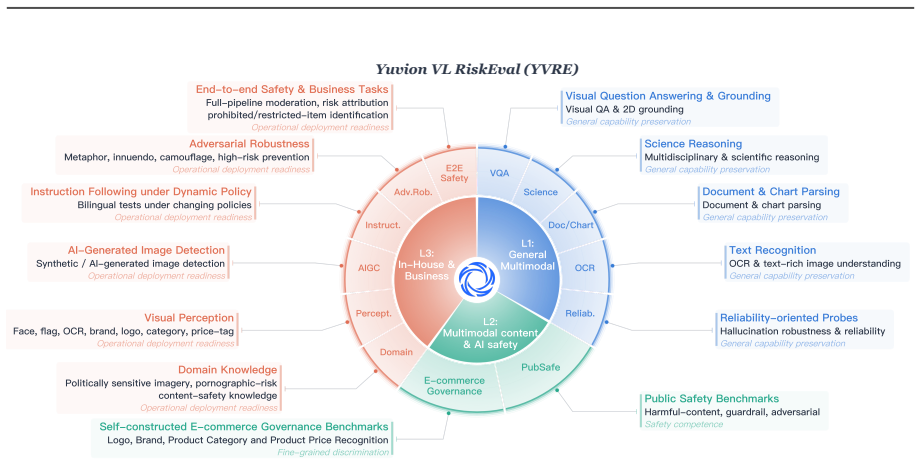
The Yuvion VL RiskEval collection and the authors' internal evaluations provide an unbiased and comprehensive measure of real-world adversarial robustness.
What would settle it
An independent test set of adversarial multimodal examples, constructed without access to the authors' data or model, on which Yuvion VL-32B scores below the best competing models on safety metrics.
Figures
read the original abstract
General-purpose models often struggle to reliably identify and understand real-world multimodal risks, largely due to the inherent multimodal adversarial nature of content and AI safety. We present Yuvion VL, a family of multimodal large language models purpose-built for content and AI safety, with both instruction-tuned and reasoning-oriented variants. Yuvion VL addresses this gap by treating safety as an inherently adversarial and multimodal problem and designing the entire pipeline around adversarial robustness. For data construction, we develop an automated pipeline integrating adversarial-aware data synthesis with multi-stage quality control, producing large-scale, high-quality multimodal samples augmented with domain knowledge and reasoning annotations. For training, we adopt a three-stage pipeline that includes continued pretraining for risk-concept cross-modal alignment, instruct post-training for production-grade safety tasks, and reasoning post-training for enhanced interpretability and performance in complex tasks. We further introduce Confuse-then-Contrast Fine-Tuning, a contrastive framework that mines model-specific confusions and constructs multi-image contrastive groups to enforce explicit discrimination of fine-grained visual-semantic elements, enabling the model to distinguish between visually similar cases with different safety implications in adversarial safety tasks. To support rigorous evaluation, we further introduce Yuvion VL RiskEval (YVRE), a collection of benchmarks covering diverse open and internal evaluations, with a focus on content and AI safety, adversarial robustness, and real-world capability requirements. Experiments show that Yuvion VL-32B achieves industry-leading safety performance, surpassing comparably sized open-source models and best closed-source commercial models, while maintaining comparable general capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Yuvion VL, a family of multimodal LLMs purpose-built for content and AI safety. It describes an automated adversarial-aware data synthesis pipeline with multi-stage quality control, a three-stage training process (continued pretraining for cross-modal risk alignment, instruct post-training, and reasoning post-training), and introduces Confuse-then-Contrast Fine-Tuning to mine model confusions and enforce discrimination via multi-image contrastive groups. The authors further introduce the Yuvion VL RiskEval (YVRE) benchmark collection covering open and internal safety, adversarial robustness, and capability evaluations, claiming that the 32B variant achieves industry-leading safety performance that surpasses comparably sized open-source models and best closed-source commercial models while maintaining comparable general capabilities.
Significance. If the performance claims can be substantiated on independent benchmarks, the work would advance multimodal safety modeling by treating adversarial robustness as a core design principle and introducing a contrastive fine-tuning method that targets fine-grained visual-semantic distinctions. The three-stage pipeline and data synthesis approach provide concrete engineering contributions that could be adopted more broadly. The significance is currently limited by the evaluation design.
major comments (1)
- [YVRE introduction and experiments section] The headline claim that Yuvion VL-32B achieves industry-leading safety performance (abstract and experiments) rests entirely on results from the newly introduced YVRE collection, which the authors control in both construction and selection. No comparisons are reported against established public multimodal safety benchmarks such as MM-SafetyBench or SafeBench, and no third-party red-teaming results are provided. This is load-bearing because the central empirical contribution cannot be assessed for selection bias, data leakage from the three-stage pipeline plus Confuse-then-Contrast procedure, or over-representation of synthesized adversarial patterns without external validation.
minor comments (1)
- [Abstract] The abstract asserts superior performance without any quantitative metrics, baselines, or error bars; a brief summary of key numbers should be included even in the abstract for a results-oriented claim.
Simulated Author's Rebuttal
We thank the referee for highlighting the evaluation design limitations. We address the concern about reliance on the internally controlled YVRE benchmarks below and commit to revisions that incorporate external validation where feasible.
read point-by-point responses
-
Referee: [YVRE introduction and experiments section] The headline claim that Yuvion VL-32B achieves industry-leading safety performance (abstract and experiments) rests entirely on results from the newly introduced YVRE collection, which the authors control in both construction and selection. No comparisons are reported against established public multimodal safety benchmarks such as MM-SafetyBench or SafeBench, and no third-party red-teaming results are provided. This is load-bearing because the central empirical contribution cannot be assessed for selection bias, data leakage from the three-stage pipeline plus Confuse-then-Contrast procedure, or over-representation of synthesized adversarial patterns without external validation.
Authors: We agree that the primary safety claims are evaluated on YVRE and that external benchmarks are needed to assess potential selection bias or leakage from our data synthesis and Confuse-then-Contrast procedure. YVRE targets fine-grained adversarial multimodal distinctions not comprehensively covered by MM-SafetyBench or SafeBench, which is why it was introduced. To strengthen the claims, the revised manuscript will add performance comparisons on both MM-SafetyBench and SafeBench. We do not currently possess third-party red-teaming results and cannot generate them internally; instead, we will release model weights and the YVRE suite to support independent verification. revision: partial
- Third-party red-teaming results (no access to external evaluations)
Circularity Check
No circularity in derivation chain; empirical claims rest on introduced benchmark with open components
full rationale
The paper describes a three-stage training pipeline and Confuse-then-Contrast method for a safety-focused multimodal model, then reports performance on the newly introduced YVRE benchmark collection (which explicitly includes open evaluations alongside internal ones). No equations, fitted parameters, or first-principles derivations are presented that reduce by construction to the inputs; the central empirical claim of superior safety performance is a comparison result on the benchmark rather than a self-definitional or tautological reduction. Self-created benchmarks are common and do not trigger the enumerated circularity patterns unless data leakage or direct renaming of training outputs as predictions is shown, which is not exhibited here. The derivation chain remains self-contained against external benchmarks and comparisons.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jinze Bai, Shuai Bai, Shusheng Yang, et al. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966,
-
[2]
Qwen3-VL technical report.arXiv preprint arXiv:2511.21631, 2025a
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, et al. Qwen3-VL technical report.arXiv preprint arXiv:2511.21631, 2025a. Shuai Bai, Keqin Chen, Xuejing Liu, et al. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025b. Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, ...
-
[3]
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, and Jifeng Dai. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks.arXiv preprint arXiv:2312.14238,
-
[4]
Jianfeng Chi, Ujjwal Karn, Hongyuan Zhan, Eric Smith, Javier Rando, Yiming Zhang, Kate Plawiak, Zacharie Delpierre Coudert, Kartikeya Upasani, and Mahesh Pasupuleti. Llama guard 3 vision: Safeguarding human-ai image understanding conversations.arXiv preprint arXiv:2411.10414,
-
[5]
Boolq: Exploring the surprising difficulty of natural yes/no questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), pp. 2924–2936,
2019
-
[6]
Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
-
[7]
Benlei Cui, Shaoxuan He, Bukun Huang, Zhizeng Ye, Yunyun Sun, Longtao Huang, Hui Xue, Yang Yang, Jingqun Tang, Zhou Zhao, et al. Tc-pad\’e: Trajectory-consistent pad\’e approximation for diffusion acceleration.arXiv preprint arXiv:2603.02943, 2026a. 1Correspondence to:honghaiwen.hhw@alibaba-inc.com. 21 Benlei Cui, Bukun Huang, Zhizeng Ye, Xuemei Dong, Tuo...
-
[8]
Shaona Ghosh, Prasoon Varshney, Erick Galinkin, and Christopher Parisien. AEGIS: Online adaptive ai content safety moderation with ensemble of llm experts.arXiv preprint arXiv:2404.05993,
-
[9]
Seungju Han, Kavel Rao, Allyson Ettinger, Liwei Jiang, Bill Yuchen Lin, Nathan Lambert, Yejin Choi, and Nouha Dziri. Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms.arXiv preprint arXiv:2406.18495,
-
[10]
Lukas Helff, Felix Friedrich, Manuel Brack, Kristian Kersting, and Patrick Schramowski. Llava- Guard: An open vlm-based framework for safeguarding vision datasets and models.arXiv preprint arXiv:2406.05113,
-
[11]
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, et al. Vision-r1: Incentivizing reasoning capability in multimodal large language models.arXiv preprint arXiv:2503.06749,
-
[12]
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, et al. Llama guard: Llm-based input-output safeguard for human-ai conversations.arXiv preprint arXiv:2312.06674,
-
[13]
Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326,
Bo Li, Yuanhan Zhang, Dong Guo, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326,
-
[14]
22 Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yixiao Ge, and Ying Shan. Seed-bench: Benchmarking multimodal llms with generative comprehension.arXiv preprint arXiv:2307.16125,
-
[15]
Junyu Lin, Meizhen Liu, Xiufeng Huang, Jinfeng Li, Haiwen Hong, Xiaohan Yuan, Yuefeng Chen, Longtao Huang, Hui Xue, Ranjie Duan, et al. Yufeng-xguard: A reasoning-centric, interpretable, and flexible guardrail model for large language models.arXiv preprint arXiv:2601.15588,
-
[16]
Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. InInternational Conference on Learning Representations, volume 2024, pp. 23439–23554,
2024
-
[17]
Machel Reid, Nikolay Savinov, Denis Teplyashin, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530,
-
[18]
Gemini: A family of highly capable multimodal models.arXiv preprint arXiv:2312.11805,
Gemini Team, Rohan Anil, Sebastian Borgeaud, et al. Gemini: A family of highly capable multimodal models.arXiv preprint arXiv:2312.11805,
-
[19]
Peng Wang, Shuai Bai, Sinan Tan, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191,
-
[20]
Xiyao Wang et al. Llava-critic-r1: Your critic model is secretly a strong policy model.arXiv preprint arXiv:2509.00676, 2025a. 23 Yaoting Wang, Shengqiong Wu, Yuecheng Zhang, Shuicheng Yan, Ziwei Liu, Jiebo Luo, and Hao Fei. Multimodal chain-of-thought reasoning: A comprehensive survey.arXiv preprint arXiv:2503.12605, 2025b. Haoning Wu, Zicheng Zhang, Erl...
arXiv 2024
-
[21]
Ancheng Xu, Zhihao Yang, Jingpeng Li, Guanghu Yuan, Longze Chen, Liang Yan, et al. EVADE- Bench: Multimodal benchmark for evaluating and enhancing evasive content detection.arXiv preprint arXiv:2505.17654,
-
[22]
Llava-cot: Let vision language models reason step-by-step.arXiv preprint arXiv:2411.10440,
Guowei Xu, Peng Jin, Ziang Wu, Hao Li, Yibing Song, Lichao Sun, and Li Yuan. Llava-cot: Let vision language models reason step-by-step.arXiv preprint arXiv:2411.10440,
-
[23]
Haolei Xu, Haiwen Hong, Hongxing Li, Rui Zhou, Yang Zhang, Longtao Huang, Hui Xue, Yongliang Shen, Weiming Lu, and Yueting Zhuang. Seeing but not thinking: Routing distraction in multimodal mixture-of-experts.arXiv preprint arXiv:2604.08541,
-
[24]
ProGuard: Towards proactive multimodal safeguard.arXiv preprint arXiv:2512.23573,
Shaohan Yu, Lijun Li, Chenyang Si, Lu Sheng, and Jing Shao. ProGuard: Towards proactive multimodal safeguard.arXiv preprint arXiv:2512.23573,
-
[25]
Shieldgemma: Generative ai content moderation based on gemma.arXiv preprint arXiv:2407.21772,
Wenjun Zeng, Yuchi Liu, Ryan Mullins, Ludovic Peran, Joe Fernandez, Hamza Harkous, Karthik Narasimhan, Drew Proud, Piyush Kumar, Bhaktipriya Radharapu, Olivia Sturman, and Oscar Wahltinez. Shieldgemma: Generative ai content moderation based on gemma.arXiv preprint arXiv:2407.21772,
-
[26]
Jingyi Zhang, Jiaxing Huang, Huanjin Yao, Shunyu Liu, Xikun Zhang, Shijian Lu, and Dacheng Tao. R1-vl: Learning to reason with multimodal large language models via step-wise group relative policy optimization.arXiv preprint arXiv:2503.12937, 2025a. Zicheng Zhang, Haoning Wu, Chunyi Li, Yingjie Zhou, Wei Sun, Xiongkuo Min, Zijian Chen, Xiaohong Liu, Weisi ...
Pith/arXiv arXiv 2025
-
[27]
for diagram understanding and struc- tured visual reasoning over educational figures. • MM General VQA:MMBench(Liu et al., 2024c),MME(Fu et al., 2026),MMStar(Chen et al., 2024),SEEDBench(Li et al., 2023),ScienceQA(Lu et al., 2022),A-Bench(Zhang et al., 2025b), and Q-Bench(Wu et al.,
2026
-
[28]
• Text Chinese language understanding.:C3(Sun et al., 2020),CLUEWSC(Xu et al., 2020), andXiezhi- CNfor Chinese knowledge understanding, and commonsense reasoning
for object counting and spatial grounding. • Text Chinese language understanding.:C3(Sun et al., 2020),CLUEWSC(Xu et al., 2020), andXiezhi- CNfor Chinese knowledge understanding, and commonsense reasoning. • Text Commonsense and reading comprehension. BoolQ(Clark et al., 2019),WinoGrande(Sakaguchi et al.,
2020
-
[29]
for commonsense reasoning, reading comprehension, multi-step inference, and robustness on open-ended or ambiguous problems. • Text Mathematical reasoning.This group includesGSM8K-ZH(Cobbe et al., 2021),APE210K,TAL- SCQ5K-CNfor arithmetic problem solving, formal mathematical reasoning, and theorem-related question answering in both Chinese and English. • T...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.