Projected gradient methods for nonconvex and stochastic smooth optimization: new complexities and auto-conditioned stepsizes
Pith reviewed 2026-05-23 06:21 UTC · model grok-4.3
The pith
Auto-conditioned projected gradient methods achieve the same iteration complexity as constant-stepsize PG without needing the Lipschitz constant or line search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
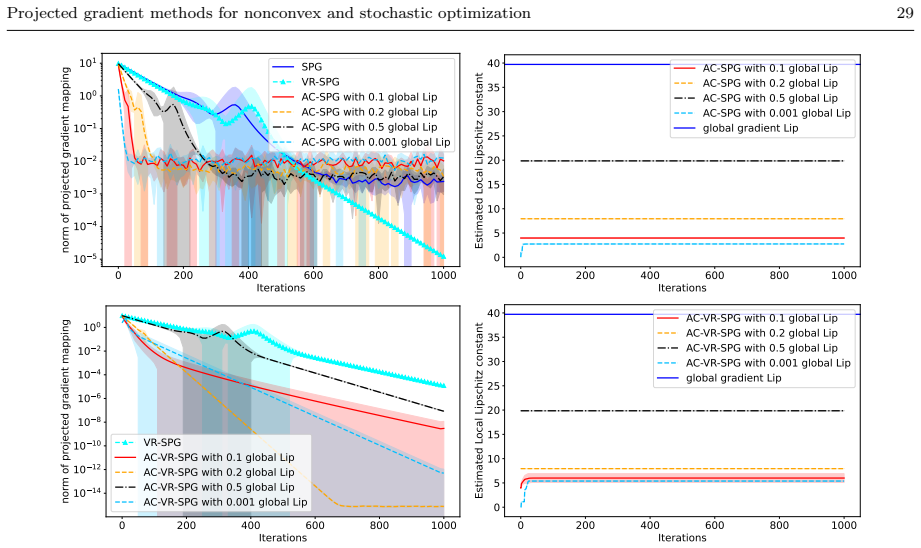
By estimating the Lipschitz constant using first-order information gathered from the previous iterations, and showing that the error caused by underestimating the Lipschitz constant can be properly controlled, the auto-conditioned projected gradient method achieves the same iteration complexity as the constant-stepsize projected gradient method for finding an approximate stationary point of a smooth nonconvex function over a convex compact set, without requiring the input of the Lipschitz constant or any line search procedure. The methods are also generalized to the stochastic setting with new complexity bounds.
What carries the argument
The auto-conditioned projected gradient (AC-PG) variant, which estimates the Lipschitz constant on the fly from previous first-order information while controlling underestimation error.
If this is right
- The constant-stepsize PG method attains the best-known iteration complexity for nonconvex smooth optimization over convex sets.
- The AC-PG method matches this complexity without knowledge of the Lipschitz constant or use of line search.
- Stochastic PG and variance-reduced SPG methods deliver new complexity bounds in different oracle settings.
- Auto-conditioned stepsize policies for the stochastic variants achieve comparable convergence guarantees.
Where Pith is reading between the lines
- Implementation becomes simpler for problems where the Lipschitz constant is unknown or expensive to compute in advance.
- The error-control technique for underestimation may transfer to adaptive stepsize rules in other first-order methods for nonconvex problems.
- These policies could reduce the need for manual stepsize tuning across a range of optimization applications.
Load-bearing premise
The error caused by underestimating the Lipschitz constant can be properly controlled so that it does not degrade the overall convergence rate.
What would settle it
A concrete smooth nonconvex function over a convex set where the underestimation error from the auto-conditioned Lipschitz estimate accumulates and produces strictly worse than the claimed iteration complexity for reaching an epsilon-stationary point.
Figures




read the original abstract
We present a novel class of projected gradient (PG) methods for minimizing a smooth but not necessarily convex function over a convex compact set. We first provide a novel analysis of the constant-stepsize PG method, achieving the best-known iteration complexity for finding an approximate stationary point of the problem. We then develop an "auto-conditioned" projected gradient (AC-PG) variant that achieves the same iteration complexity without requiring the input of the Lipschitz constant of the gradient or any line search procedure. The key idea is to estimate the Lipschitz constant using first-order information gathered from the previous iterations, and to show that the error caused by underestimating the Lipschitz constant can be properly controlled. We then generalize the PG methods to the stochastic setting, by proposing a stochastic projected gradient (SPG) method and a variance-reduced stochastic gradient (VR-SPG) method, achieving new complexity bounds in different oracle settings. We also present auto-conditioned stepsize policies for both stochastic PG methods and establish comparable convergence guarantees.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper provides a new analysis of constant-stepsize projected gradient (PG) methods for smooth nonconvex minimization over convex compact sets, claiming best-known O(1/ε²) iteration complexity for approximate stationarity. It introduces an auto-conditioned PG (AC-PG) variant that estimates the gradient Lipschitz constant L from prior first-order information and controls underestimation error to match the same complexity without inputting L or using line search. Stochastic extensions (SPG, VR-SPG) and their auto-conditioned versions are analyzed with new oracle complexities under different settings.
Significance. If the error-control argument for underestimation holds, the auto-conditioned stepsize removes a practical barrier to applying PG methods while preserving optimal rates, which is a meaningful contribution for implementation. The stochastic complexity results, if tighter than prior work, would also be useful. No machine-checked proofs or reproducible code are mentioned, but the parameter-free derivation via auto-conditioning is a clear strength if rigorously established.
major comments (2)
- [§3] Abstract and §3 (AC-PG construction): the claim that underestimation error from the Lipschitz estimate can be controlled without degrading the O(1/ε²) rate is the central technical step, yet the specific descent inequality or potential-function argument that absorbs the error term while preserving the complexity is not visible in the provided description; this must be made explicit with the precise bound on the accumulated error.
- [§2] Theorem on constant-stepsize PG (likely §2): the 'best-known' iteration complexity is asserted, but the precise dependence on the diameter of the constraint set, smoothness constant, and target accuracy ε should be compared explicitly to the prior reference (e.g., the exact big-O expression) to confirm improvement or equivalence.
minor comments (2)
- [§3] Notation for the estimated Lipschitz constant (e.g., L_k) should be introduced with a clear recursive definition and boundedness argument early in the AC-PG section.
- [§5] The stochastic sections would benefit from a table summarizing the oracle complexities (gradient evaluations, variance-reduced calls) across SPG, VR-SPG, and their auto-conditioned variants for direct comparison.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive suggestions. We address the two major comments below and will revise the manuscript to improve clarity on the technical arguments and comparisons.
read point-by-point responses
-
Referee: [§3] Abstract and §3 (AC-PG construction): the claim that underestimation error from the Lipschitz estimate can be controlled without degrading the O(1/ε²) rate is the central technical step, yet the specific descent inequality or potential-function argument that absorbs the error term while preserving the complexity is not visible in the provided description; this must be made explicit with the precise bound on the accumulated error.
Authors: We agree that the error-control argument requires explicit highlighting. The full analysis in Section 3 derives a descent inequality for the AC-PG iterates by using the underestimated stepsize η_k = 1/L_k, where L_k is the running estimate. The resulting inequality includes an additive error term bounded by the sum of ||g_{t} - g_{t-1}||² over prior steps; this sum is controlled via a telescoping argument that absorbs into the potential function without changing the leading O(1/ε²) term. We will add a dedicated lemma stating the precise accumulated-error bound (including all constants) immediately before the main complexity theorem. revision: yes
-
Referee: [§2] Theorem on constant-stepsize PG (likely §2): the 'best-known' iteration complexity is asserted, but the precise dependence on the diameter of the constraint set, smoothness constant, and target accuracy ε should be compared explicitly to the prior reference (e.g., the exact big-O expression) to confirm improvement or equivalence.
Authors: We will revise the theorem statement and surrounding discussion in Section 2 to include the explicit comparison. Our bound is O(D² L / ε²) iterations to reach an ε-stationary point, where D denotes the diameter of the feasible set. This matches the leading term in the best prior results for projected gradient methods on nonconvex problems (e.g., the O(D² L / ε²) rate obtained via standard analysis in Nesterov’s work and subsequent papers on constrained nonconvex optimization). We will insert a short table or paragraph listing the exact big-O expressions from the cited references. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's core contribution is a new analysis of constant-stepsize projected gradient methods achieving O(1/ε²) complexity for nonconvex problems, followed by an AC-PG variant that estimates the gradient Lipschitz constant from prior first-order information and proves that underestimation error can be controlled without degrading the rate. This is presented as a direct extension of standard PG analysis with explicit error bounds, not as a fit or self-referential definition. No load-bearing self-citations, ansatzes smuggled via prior work, or renamings of known results appear in the provided abstract or claim structure; the derivation chain remains independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The objective function is smooth (gradient is Lipschitz continuous).
- domain assumption The feasible set is convex and compact.
Forward citations
Cited by 4 Pith papers
-
Stochastic Auto-conditioned Fast Gradient Methods with Optimal Rates
Stochastic AC-FGM achieves optimal O(1/√ε) iteration complexity and O(1/ε²) sample complexity while being fully adaptive to smoothness, horizon, and noise under bounded conditional variance.
-
Adaptive Newton-CG methods with global and local analysis for unconstrained optimization with H\"older continuous Hessian
Adaptive Newton-CG methods achieve the best-known iteration complexity for epsilon-stationary points in nonconvex optimization with Holder continuous Hessians while ensuring local superlinear convergence.
-
Universal and Parameter-free Gradient Sliding for Composite Optimization
PFUGS is the first parameter-free gradient sliding method for composite convex problems with unknown Hölder and Lipschitz constants, using O((M_ν/ε)^{2/(1+3ν)}) subgradient evaluations of f and O((L/ε)^{1/2}) gradient...
-
Auto-Conditioned Frank-Wolfe Algorithms
Auto-conditioned Frank-Wolfe methods use local Lipschitz estimators from first-order information to achieve convergence guarantees in convex and nonconvex settings without prior global smoothness knowledge.
Reference graph
Works this paper leans on
-
[1]
1 γ(i) t ∥g(i) X,t−1∥2 − L(i) 1 2 ∥x(i) 1 − x(i) 0 ∥2 (ii) ≥ (si−1)(si−2) 8γ(i) si min t∈[1,si−1] ∥g(i) X,t∥2 − L(i) 1 2 ∥x(i) 1 − x(i) 0 ∥2, (2.26) where step (i) follows from the definition of projected gradient in (2.2) and the fact γ(i) 1 ≥ 0, and step (ii) is due to γ(i) si ≥ γ(i) si−1 ≥ ... ≥ γ(i) 2 . Then by summing up Si for i = 1, ..., m, we obta...
-
[2]
− Lt)2] ≤ E[ 1 b′ t (Lt(¯ξt 1))2] ≤ ¯L2 b′ t . (3.26) Then by using Bernstein’s inequality and | ¯Lt − Lt| ≤ ˆL + L almost surely, we have that for any λ > 0, P ¯Lt − Lt ≥ ( ˆL+L)λ 3b′ t + q 2 ¯L2λ b′ t ≤ exp(−λ), (3.27) Projected gradient methods for nonconvex and stochastic optimization 13 which indicates (3.23). In AC-SPG, the output at time step k is ...
-
[3]
Therefore, while this approach may potentially increase a few higher-order terms in sample complexity, it allows us to achieve the iteration complexity of O L2D2 X log δ−1 ϵ2 after ignoring some log-log factors. Nevertheless, all the sample complexities above still exhibit polynomial dependence on δ. To reduce this dependence to a logarithmic factor, we i...
-
[4]
¯L0 + 3kσ2 8 ¯L0N ≤ E X 1≤t≤k,I(t)=0 γt 4 ∥xt − xt−1∥2 + 3 ˆL2D2 X ¯L0 + 3kσ2 8 ¯L0N , (4.38) where the step (i) follows from that for two consecutive I(t) = 1 points, denoted as t1 < t 2, we have ˜Lt2 > 2√ 3 Lt1. Finally, by combining Ineqs. (4.37) and (4.38), and invoking the output rule (4.30), we obtain E hPk t=1 1 4γt ∥gX,R(k)∥2 i = E hPk t=1 1 4γt ∥...
-
[5]
S. Andrad´ ottir. A review of simulation optimization techniques. In 1998 winter simulation conference. Proceedings (Cat. No. 98CH36274) , volume 1, pages 151–158. IEEE, 1998
work page 1998
-
[6]
Y. Arjevani, Y. Carmon, J. C. Duchi, D. J. Foster, N. Srebro, and B. Woodworth. Lower bounds for non-convex stochastic optimization. Mathematical Programming, 199(1):165–214, 2023
work page 2023
-
[7]
L. Armijo. Minimization of functions having lipschitz continuous first partial derivatives. Pacific Journal of mathe- matics, 16(1):1–3, 1966
work page 1966
-
[8]
Y. Carmon and O. Hinder. Making sgd parameter-free. In Conference on Learning Theory, pages 2360–2389. PMLR, 2022
work page 2022
- [9]
-
[10]
A. Cutkosky and F. Orabona. Momentum-based variance reduction in non-convex sgd. Advances in neural information processing systems, 32, 2019
work page 2019
-
[11]
D. Davis and D. Drusvyatskiy. Stochastic model-based minimization of weakly convex functions. SIAM Journal on Optimization, 29(1):207–239, 2019
work page 2019
-
[12]
D. Davis and B. Grimmer. Proximally guided stochastic subgradient method for nonsmooth, nonconvex problems. SIAM Journal on Optimization , 29(3):1908–1930, 2019
work page 1908
-
[13]
C. Fang, C. J. Li, Z. Lin, and T. Zhang. Spider: Near-optimal non-convex optimization via stochastic path-integrated differential estimator. Advances in neural information processing systems , 31, 2018
work page 2018
-
[14]
M. C. Fu. Optimization for simulation: Theory vs. practice. INFORMS Journal on Computing , 14(3):192–215, 2002
work page 2002
-
[15]
S. Ghadimi and G. Lan. Stochastic first-and zeroth-order methods for nonconvex stochastic programming. SIAM journal on optimization , 23(4):2341–2368, 2013. Projected gradient methods for nonconvex and stochastic optimization 31
work page 2013
-
[16]
S. Ghadimi and G. Lan. Accelerated gradient methods for nonconvex nonlinear and stochastic programming. Mathe- matical Programming, 156(1):59–99, 2016
work page 2016
-
[17]
S. Ghadimi, G. Lan, and H. Zhang. Mini-batch stochastic approximation methods for constrained nonconvex stochastic programming. Mathematical Programming, 155:267–305, 2016
work page 2016
-
[18]
S. Ghadimi, G. Lan, and H. Zhang. Mini-batch stochastic approximation methods for nonconvex stochastic composite optimization. Mathematical Programming, 155(1):267–305, 2016
work page 2016
-
[19]
W. Hare and C. Sagastiz´ abal. Computing proximal points of nonconvex functions. Mathematical Programming, 116(1):221–258, 2009
work page 2009
- [20]
-
[21]
G. Lan. First-order and stochastic optimization methods for machine learning , volume 1. Springer, 2020
work page 2020
- [22]
- [23]
- [24]
-
[25]
P. Latafat, A. Themelis, L. Stella, and P. Patrinos. Adaptive proximal algorithms for convex optimization under local lipschitz continuity of the gradient. arXiv preprint arXiv:2301.04431 , 2023
- [26]
-
[27]
J. Liang and R. D. Monteiro. An average curvature accelerated composite gradient method for nonconvex smooth composite optimization problems. SIAM Journal on Optimization , 31(1):217–243, 2021
work page 2021
-
[28]
J. Liang and R. D. Monteiro. Average curvature fista for nonconvex smooth composite optimization problems. Com- putational Optimization and Applications , 86(1):275–302, 2023
work page 2023
-
[29]
B. Liu, M. Wang, H. Foroosh, M. Tappen, and M. Pensky. Sparse convolutional neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition , pages 806–814, 2015
work page 2015
- [30]
-
[31]
Y. Malitsky and K. Mishchenko. Adaptive gradient descent without descent. arXiv preprint arXiv:1910.09529 , 2019
-
[32]
G. Mancino-Ball, S. Miao, Y. Xu, and J. Chen. Proximal stochastic recursive momentum methods for nonconvex composite decentralized optimization. In Proceedings of the AAAI Conference on Artificial Intelligence , volume 37, pages 9055–9063, 2023
work page 2023
- [33]
- [34]
-
[35]
Y. E. Nesterov. Introductory Lectures on Convex Optimization: A Basic Course . Kluwer Academic Publishers, Mas- sachusetts, 2004
work page 2004
-
[36]
F. Orabona and D. P´ al. Coin betting and parameter-free online learning. Advances in Neural Information Processing Systems, 29, 2016
work page 2016
-
[37]
M. L. Puterman. Markov decision processes: discrete stochastic dynamic programming . John Wiley & Sons, 2014
work page 2014
-
[38]
R. T. Rockafellar. Monotone operators and the proximal point algorithm. SIAM Journal on Control and Optimization , 14(5):877–898, 1976
work page 1976
-
[39]
J. V. Shi, Y. Xu, and R. G. Baraniuk. Sparse bilinear logistic regression. arXiv preprint arXiv:1404.4104 , 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[40]
R. S. Sutton and A. G. Barto. Reinforcement learning: An introduction. MIT press, 2018
work page 2018
-
[41]
Q. Tran-Dinh, N. H. Pham, D. T. Phan, and L. M. Nguyen. A hybrid stochastic optimization framework for composite nonconvex optimization. Mathematical Programming, 191(2):1005–1071, 2022
work page 2022
-
[42]
Z. Wang, K. Ji, Y. Zhou, Y. Liang, and V. Tarokh. Spiderboost and momentum: Faster variance reduction algorithms. Advances in Neural Information Processing Systems , 32, 2019
work page 2019
- [43]
-
[44]
W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y. Hou, Y. Min, B. Zhang, J. Zhang, Z. Dong, et al. A survey of large language models. arXiv preprint arXiv:2303.18223 , 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [45]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.