When Softmax Fails at the Top: Extreme Value Corrections for InfoNCE
Pith reviewed 2026-06-28 22:50 UTC · model grok-4.3
The pith
InfoNCE softmax misaligns with extreme-value distribution of normalized similarities, and an online batch correction fixes it
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Using extreme value theory, the paper shows that the softmax form of InfoNCE is misaligned with the normalized embedding setting in modern contrastive learning. Motivated by this, WEINCE modifies InfoNCE by blending the usual softmax logits with an endpoint shortfall correction derived from anchor-wise online batch statistics, adding no trainable parameters. On five vision benchmarks this yields consistent improvements in frozen-feature evaluation, demonstrating that a more faithful statistical treatment of hard negatives can strengthen contrastive objectives.
What carries the argument
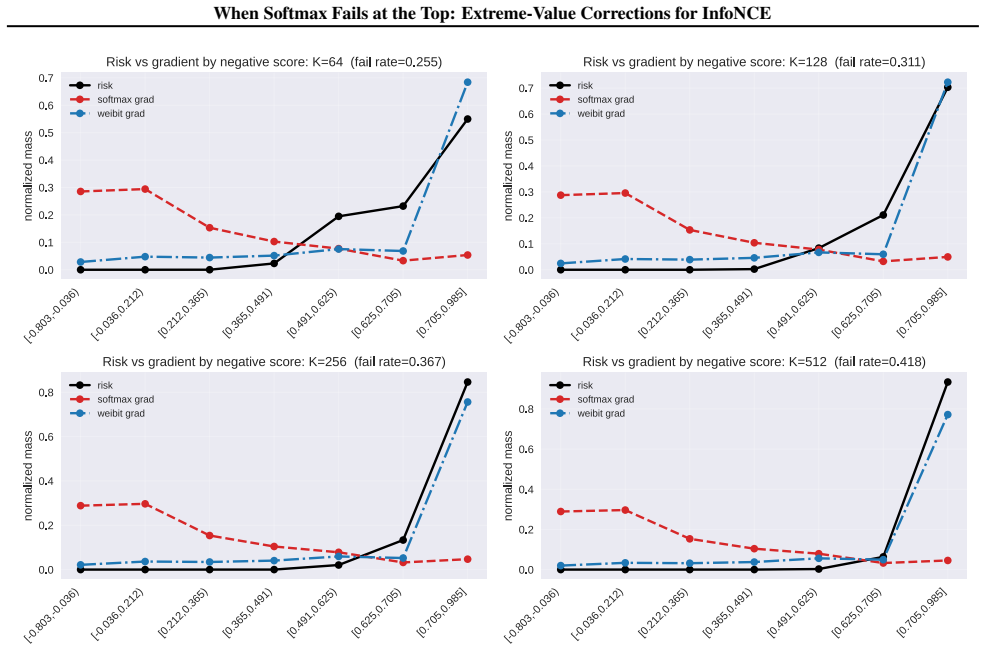
The endpoint shortfall correction, which adjusts InfoNCE logits using extreme-value estimates of the maximum similarity drawn from per-anchor batch statistics.
If this is right
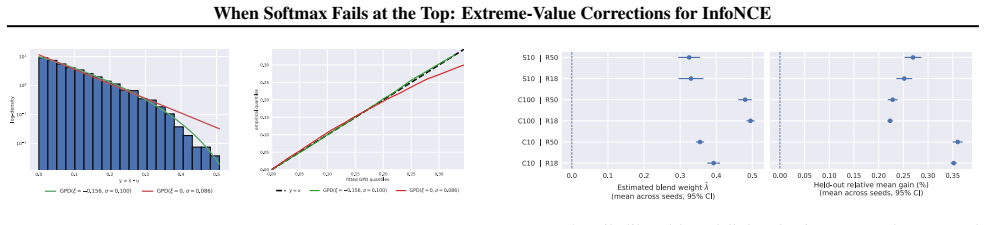
- WEINCE produces consistent gains in frozen-feature evaluation across five vision benchmarks.
- The method introduces no new trainable parameters.
- The correction is computed solely from anchor-wise online batch statistics.
- A more faithful statistical treatment of hard negatives improves the contrastive objective.
- The approach directly addresses the mismatch between softmax assumptions and normalized embedding distributions.
Where Pith is reading between the lines
- The same extreme-value correction could be applied to other softmax-based contrastive losses beyond InfoNCE.
- Performance benefits may shrink in regimes where batch statistics become unreliable, such as very small batches.
- The insight suggests examining distribution assumptions in other self-supervised objectives that rely on top-k selection.
- Testing the method on non-vision modalities would reveal whether the normalized-embedding mismatch is domain-specific.
- The paper's results imply that endpoint corrections might also help in settings with learned temperature parameters.
Load-bearing premise
Anchor-wise online batch statistics suffice to compute an accurate endpoint shortfall correction that aligns the loss with the true extreme-value distribution of normalized similarities, without post-hoc tuning or distribution mismatch.
What would settle it
Running WEINCE and standard InfoNCE head-to-head on a held-out vision benchmark and finding no consistent gain, or verifying that the batch-derived correction deviates systematically from the empirical distribution of maximum similarities.
Figures

read the original abstract
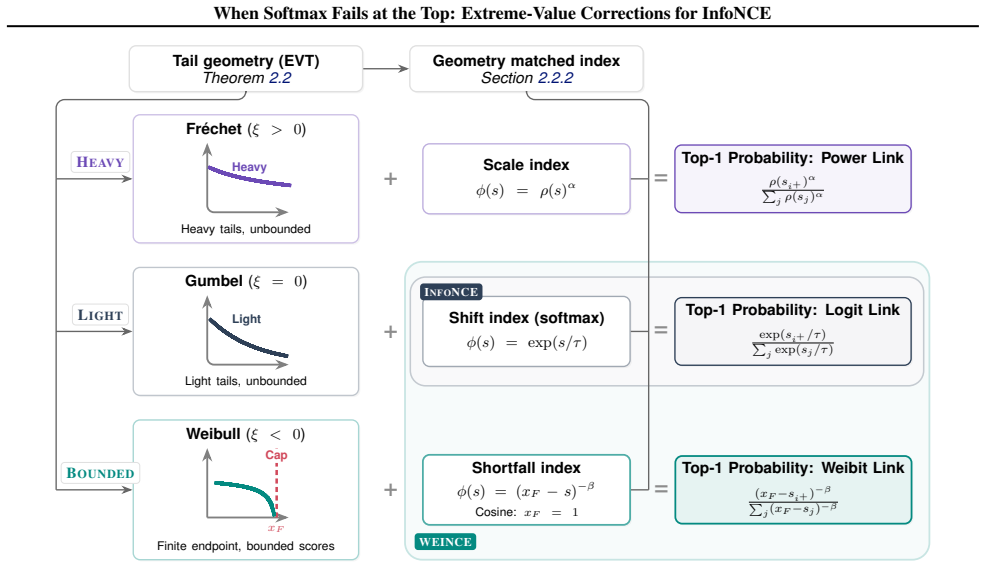
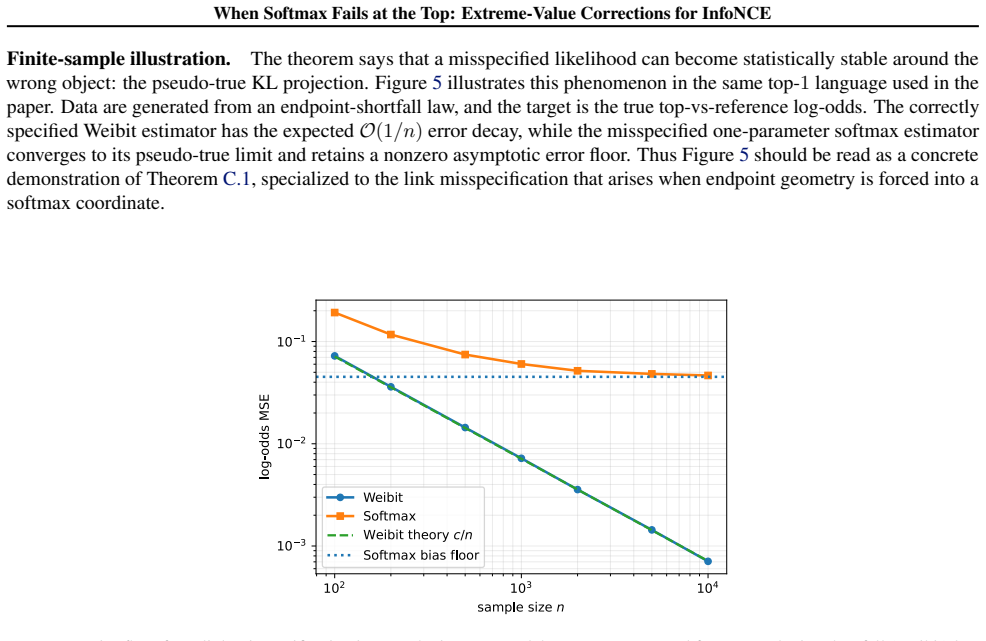
InfoNCE is the standard contrastive learning objective, but its softmax form is not only a computational convenience: it also encodes a statistical assumption about how the top-scoring example is selected. Using extreme value theory, we show that this assumption is often misaligned with the normalized embedding setting used in modern contrastive learning. Motivated by this mismatch, we propose \textsc{WEINCE}, a simple modification of InfoNCE that uses anchor-wise online batch statistics to blend the usual softmax logits with an endpoint shortfall correction, adding no trainable parameters. Across five vision benchmarks, \textsc{WEINCE} yields consistent improvements in frozen-feature evaluation. These results show that a more faithful statistical treatment of hard negatives can improve contrastive objectives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that the softmax formulation in InfoNCE encodes an assumption about top-scoring example selection that is misaligned with the distribution of normalized (L2) similarities in modern contrastive learning. Using extreme value theory, it identifies this mismatch and proposes WEINCE, a parameter-free modification that blends standard softmax logits with an anchor-wise endpoint shortfall correction estimated from online batch statistics. Experiments on five vision benchmarks show consistent gains in frozen-feature linear evaluation.
Significance. If the central claim holds, the work supplies a statistically grounded, zero-parameter adjustment to a widely used objective, with potential to improve representation quality in self-supervised settings. The absence of new trainable parameters and the use of falsifiable EVT-derived corrections are strengths; the consistent benchmark gains, if reproducible, would constitute a practical contribution to contrastive learning.
major comments (3)
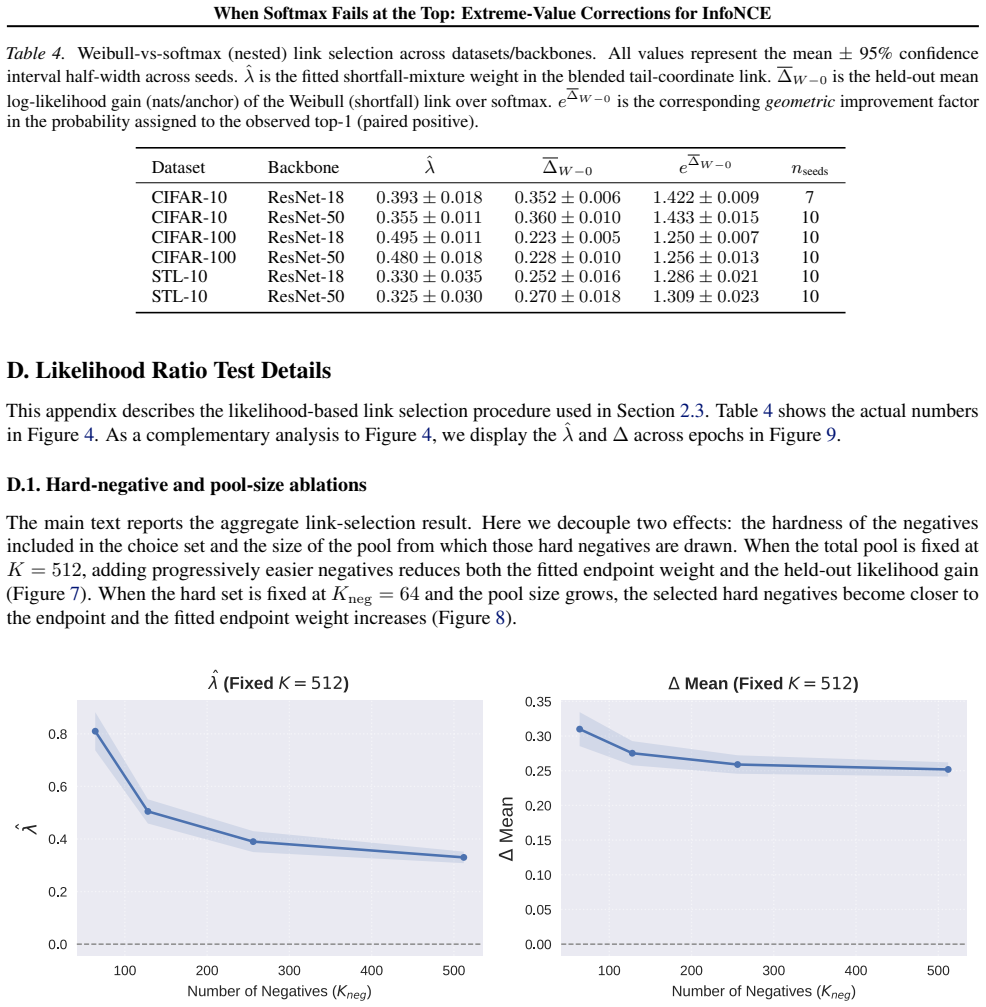
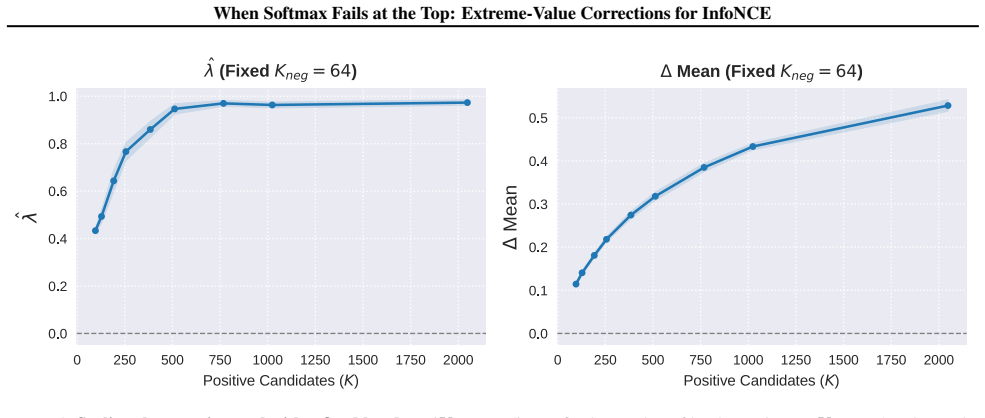
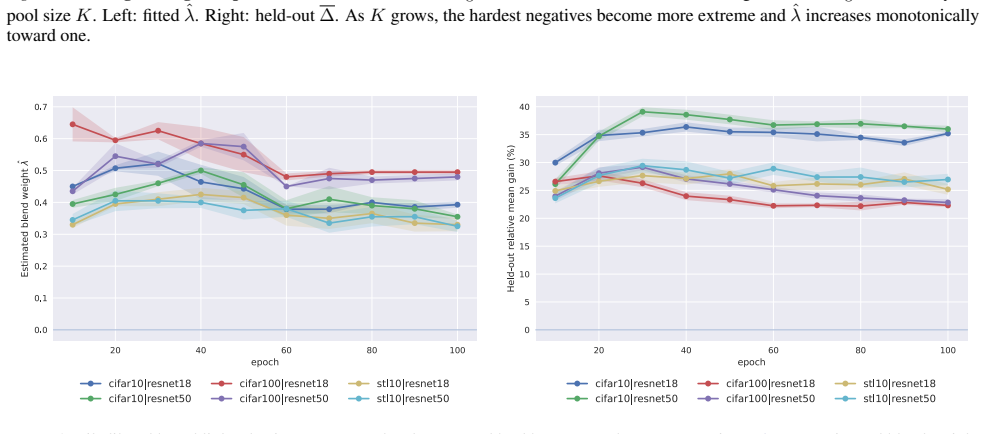
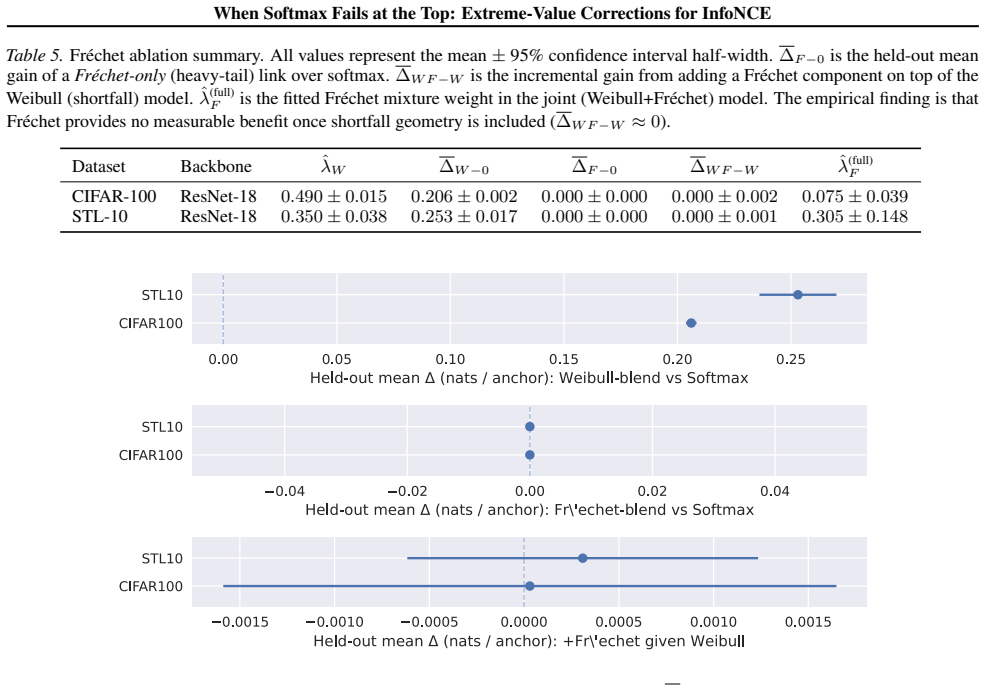
- [§3] §3 (Method): The endpoint shortfall correction is defined using per-anchor batch moments to estimate location/scale parameters of the limiting extreme-value law. No analysis is provided of the sampling variability of these estimators when the batch contains only 256–512 normalized cosine values whose support is bounded in [-1,1]; the paper must demonstrate (via simulation or concentration bounds) that the resulting correction term is stable enough to be distinguishable from an ad-hoc logit shift.
- [§4.1, Eq. (7)] §4.1, Eq. (7): The derivation assumes that the batch-maximum tail is well-approximated by the chosen extreme-value limiting distribution without residual dependence on the embedding dimension or the temperature. The manuscript should include a diagnostic (e.g., QQ plots or Kolmogorov–Smirnov statistics on held-out batches) showing that the fitted correction actually aligns with the empirical distribution of the maximum similarity.
- [Table 3] Table 3 (ablation on batch size): The reported gains are shown only for the default training batch size; an explicit sweep that varies the batch size used solely for the online EVT correction (while keeping the contrastive batch fixed) is needed to test whether the improvement collapses when the tail sample becomes smaller.
minor comments (2)
- [§2] Notation for the endpoint shortfall term is introduced without an explicit reference to the classical Pickands–Balkema–de Haan theorem; adding one sentence and a citation would clarify the statistical grounding.
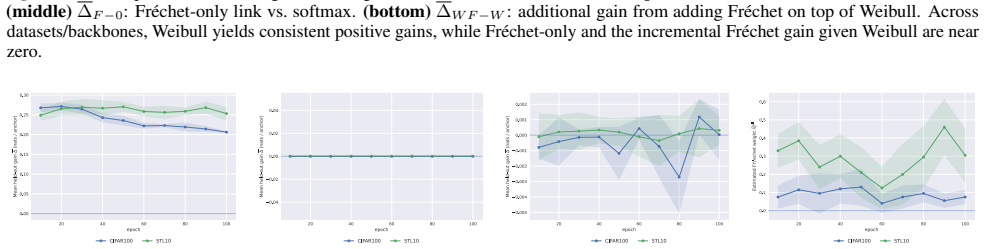
- [Figure 2] Figure 2 caption should state the exact batch size and temperature used when plotting the empirical versus corrected distributions.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The three major comments identify areas where additional analysis would strengthen the manuscript. We address each point below and commit to incorporating the requested material in a revised version.
read point-by-point responses
-
Referee: [§3] §3 (Method): The endpoint shortfall correction is defined using per-anchor batch moments to estimate location/scale parameters of the limiting extreme-value law. No analysis is provided of the sampling variability of these estimators when the batch contains only 256–512 normalized cosine values whose support is bounded in [-1,1]; the paper must demonstrate (via simulation or concentration bounds) that the resulting correction term is stable enough to be distinguishable from an ad-hoc logit shift.
Authors: We agree that the current manuscript lacks a dedicated stability analysis of the per-anchor moment estimators. In the revision we will add Monte Carlo simulations that repeatedly sample batches of size 256 and 512 from the empirical distribution of normalized similarities observed during training, compute the resulting correction terms, and report their empirical variance and range. Where possible we will also supply a simple concentration argument leveraging the bounded support [-1,1]. revision: yes
-
Referee: [§4.1, Eq. (7)] §4.1, Eq. (7): The derivation assumes that the batch-maximum tail is well-approximated by the chosen extreme-value limiting distribution without residual dependence on the embedding dimension or the temperature. The manuscript should include a diagnostic (e.g., QQ plots or Kolmogorov–Smirnov statistics on held-out batches) showing that the fitted correction actually aligns with the empirical distribution of the maximum similarity.
Authors: The manuscript currently presents only the theoretical EVT justification. We will augment §4.1 with QQ plots and Kolmogorov–Smirnov statistics computed on held-out batches drawn from the same training runs, separately for each benchmark and for the two temperatures used in the experiments. These diagnostics will be added to the revised manuscript. revision: yes
-
Referee: [Table 3] Table 3 (ablation on batch size): The reported gains are shown only for the default training batch size; an explicit sweep that varies the batch size used solely for the online EVT correction (while keeping the contrastive batch fixed) is needed to test whether the improvement collapses when the tail sample becomes smaller.
Authors: Table 3 reports results only under the default training batch size. We will add a new experiment that keeps the contrastive batch size fixed at the default while varying the batch size used exclusively for the online EVT statistics (e.g., 64, 128, 256, 512). The results of this controlled sweep will be reported in the revised Table 3 or a supplementary table. revision: yes
Circularity Check
No circularity: derivation invokes external EVT and computes correction from batch moments without self-definition or fitted-input reduction
full rationale
The paper's central step applies standard extreme-value theory (external to the authors) to identify a mismatch between softmax and the limiting distribution of the maximum normalized similarity, then defines an endpoint-shortfall correction whose location/scale parameters are computed directly from per-anchor batch moments. No equation reduces a claimed prediction to a quantity fitted on the target metric, no uniqueness theorem is imported from prior self-work, and the modification adds no trainable parameters. The result is therefore not equivalent to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Extreme value theory accurately describes the tail behavior of the highest similarity scores in normalized embedding spaces for contrastive batches.
Reference graph
Works this paper leans on
-
[1]
An Application of the Principle of Maximum Information Preservation to Linear Systems , url =
Linsker, Ralph , booktitle = NIPS, editor =. An Application of the Principle of Maximum Information Preservation to Linear Systems , url =
-
[2]
3D Object Representations for Fine-Grained Categorization , year=
Krause, Jonathan and Stark, Michael and Deng, Jia and Fei-Fei, Li , booktitle=. 3D Object Representations for Fine-Grained Categorization , year=
-
[3]
2005 , pages =
Distance Metric Learning for Large Margin Nearest Neighbor Classification , author =. 2005 , pages =
2005
-
[4]
and Hadsell, R
Chopra, S. and Hadsell, R. and LeCun, Y. , booktitle=CVPR, title=. 2005 , volume=
2005
-
[5]
Journal of Machine Learning Research , volume =
Large Scale Online Learning of Image Similarity Through Ranking , author =. Journal of Machine Learning Research , volume =
-
[6]
Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics (AISTATS) , pages =
Noise‐contrastive estimation: A new estimation principle for unnormalized statistical models , author =. Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics (AISTATS) , pages =. 2010 , editor =
2010
-
[7]
Journal of Machine Learning Research , volume =
Noise-Contrastive Estimation of Unnormalized Statistical Models, with Applications to Natural Image Statistics , author =. Journal of Machine Learning Research , volume =
-
[8]
2016 , pages =
Improved Deep Metric Learning with Multi-class N-pair Loss Objective , author =. 2016 , pages =
2016
-
[9]
2020 , pages=
Momentum Contrast for Unsupervised Visual Representation Learning , author=. 2020 , pages=
2020
-
[10]
2020 , publisher =
Janne Spijkervet , title =. 2020 , publisher =
2020
-
[11]
2021 , pages=
Contrastive Learning Inverts the Data Generating Process , author=. 2021 , pages=
2021
-
[12]
2020 , organization=
Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere , author=. 2020 , organization=
2020
-
[13]
2021 , pages =
Bukchin, Guy and Schwartz, Eli and Saenko, Kate and Shahar, Ori and Feris, Rogerio and Giryes, Raja and Karlinsky, Leonid , title =. 2021 , pages =
2021
-
[14]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Xu, Yuanhong and Qian, Qi and Li, Hao and Jin, Rong and Hu, Juhua , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2021 , pages =
2021
-
[15]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
Grafit: Learning Fine-Grained Image Representations with Coarse Labels , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
-
[16]
2020 , url =
Hard Negative Mixing for Contrastive Learning , author =. 2020 , url =
2020
-
[17]
International Conference on Learning Representations , year =
Contrastive Learning with Hard Negative Samples , author =. International Conference on Learning Representations , year =
-
[18]
2020 , url =
Debiased Contrastive Learning , author =. 2020 , url =
2020
- [19]
-
[20]
arXiv preprint arXiv:2501.17683 (2025)
Temperature-Free Loss Function for Contrastive Learning , author =. arXiv preprint arXiv:2501.17683 , year =
-
[21]
Proceedings of the 33rd International Conference on Machine Learning , series =
From Softmax to Sparsemax: A Sparse Model of Attention and Multi-Label Classification , author =. Proceedings of the 33rd International Conference on Machine Learning , series =. 2016 , url =
2016
-
[22]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages =
Sparse Sequence-to-Sequence Models , author =. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages =. 2019 , doi =
2019
-
[23]
Journal of Machine Learning Research , volume =
Learning with Fenchel-Young Losses , author =. Journal of Machine Learning Research , volume =. 2020 , url =
2020
-
[24]
2021 , url =
Understanding the Behaviour of Contrastive Loss , author =. 2021 , url =
2021
-
[25]
Deng, Jiankang and Guo, Jia and Xue, Niannan and Zafeiriou, Stefanos , booktitle = CVPR, year =
-
[26]
2020 , url =
Circle Loss: A Unified Perspective of Pair Similarity Optimization , author =. 2020 , url =
2020
-
[27]
arXiv preprint arXiv:2110.06848 , year =
Decoupled Contrastive Learning , author =. arXiv preprint arXiv:2110.06848 , year =
-
[28]
2023 , pages =
Feng, Chen and Patras, Ioannis , title =. 2023 , pages =
2023
-
[29]
Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics , series =
Noise-Contrastive Estimation: A New Estimation Principle for Unnormalized Statistical Models , author =. Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics , series =. 2010 , url =
2010
-
[30]
Journal of Machine Learning Research , volume =
Noise-Contrastive Estimation of Unnormalized Statistical Models, with Applications to Natural Image Statistics , author =. Journal of Machine Learning Research , volume =. 2012 , url =
2012
-
[31]
Information Theory: From Coding to Learning , publisher=
Polyanskiy, Yury and Wu, Yihong , year=. Information Theory: From Coding to Learning , publisher=
-
[32]
Wordnet: An electronic lexical database
-
[33]
, title =
Alon, Noga and Spencer, Joel H. , title =. 2016 , isbn =
2016
-
[34]
2023 , url =
Mauck, Chris , title =. 2023 , url =
2023
-
[35]
2015 , eprint=
Deep Residual Learning for Image Recognition , author=. 2015 , eprint=
2015
-
[36]
Guiver, John and Snelson, Edward , title =. 2009 , isbn =. doi:10.1145/1553374.1553423 , abstract =
-
[37]
Hoffmann and Nadine Behrmann and Juergen Gall and Thomas Brox and Mehdi Noroozi , title =
David T. Hoffmann and Nadine Behrmann and Juergen Gall and Thomas Brox and Mehdi Noroozi , title =. CoRR , volume =. 2022 , url =. 2201.11736 , timestamp =
-
[38]
2024 , eprint=
Contrastive Preference Learning: Learning from Human Feedback without RL , author=. 2024 , eprint=
2024
-
[40]
End-to-End Learning of Visual Representations from Uncurated Instructional Videos , journal =
Antoine Miech and Jean. End-to-End Learning of Visual Representations from Uncurated Instructional Videos , journal =. 2019 , url =. 1912.06430 , timestamp =
-
[41]
Transportation Research Part B: Methodological , author=
Closed form expressions for choice probabilities in the Weibull case , year=. Transportation Research Part B: Methodological , author=. doi:None , url=
-
[42]
Extreme Value Theory
De Haan, Laurens and Ferreira, Ana. Extreme Value Theory
-
[43]
Transportation Research Part B: Methodological , author=
Unified closed-form expression of logit and weibit and its extension to a transportation network equilibrium assignment , year=. Transportation Research Part B: Methodological , author=. doi:10.1016/j.trb.2015.07.019 , url=
-
[44]
Journal of choice modelling , author=
Weibit choice models: Properties, mode choice application and graphical illustrations , year=. Journal of choice modelling , author=. doi:10.1016/j.jocm.2022.100373 , url=
-
[45]
2021 , eprint=
Learning-to-Rank with Partitioned Preference: Fast Estimation for the Plackett-Luce Model , author=. 2021 , eprint=
2021
-
[46]
Resnick, S. I. , title =
-
[47]
Embrechts, P. and Kl
-
[48]
and Ferreira, A
de Haan, L. and Ferreira, A. , title =
-
[49]
Bingham, N. H. and Goldie, C. M. and Teugels, J. L. , title =. 1987 , isbn =
1987
-
[50]
Bingham, N. H. and Goldie, C. M. and Teugels, J. L. , title =. 1987 , publisher =
1987
-
[51]
, title =
van der Vaart, Aad W. , title =. 1998 , publisher =
1998
-
[52]
Econometrica , volume =
White, Halbert , title =. Econometrica , volume =
-
[53]
2009 , publisher =
Train, Kenneth , title =. 2009 , publisher =
2009
-
[54]
2026 , url=
Contrastive Predictive Coding Done Right for Mutual Information Estimation , author=. 2026 , url=
2026
-
[55]
1994 , series =
White, Halbert , title =. 1994 , series =
1994
-
[56]
Colin and Trivedi, Pravin K
Cameron, A. Colin and Trivedi, Pravin K. , title =. 2005 , isbn =
2005
-
[57]
2008 , series =
Claeskens, Gerda and Hjort, Nils Lid , title =. 2008 , series =
2008
-
[58]
Representation Learning with Contrastive Predictive Coding
Representation Learning with Contrastive Predictive Coding , author =. arXiv preprint arXiv:1807.03748 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
Proceedings of the 37th International Conference on Machine Learning , pages =
A Simple Framework for Contrastive Learning of Visual Representations , author =. Proceedings of the 37th International Conference on Machine Learning , pages =. 2020 , publisher =
2020
-
[60]
1959 , publisher =
Individual Choice Behavior: A Theoretical Analysis , author =. 1959 , publisher =
1959
-
[61]
Applied Statistics , volume =
The Analysis of Permutations , author =. Applied Statistics , volume =
-
[62]
Frontiers in Econometrics , pages =
Conditional Logit Analysis of Qualitative Choice Behavior , author =. Frontiers in Econometrics , pages =. 1974 , publisher =
1974
-
[63]
Proceedings of the Cambridge Philosophical Society , volume =
Limiting Forms of the Frequency Distribution of the Largest or Smallest Member of a Sample , author =. Proceedings of the Cambridge Philosophical Society , volume =
-
[64]
Sur la distribution limite du terme maximum d'une s
Gnedenko, Boris , journal =. Sur la distribution limite du terme maximum d'une s
-
[65]
Annals of Probability , volume =
Residual Life Time at Great Age , author =. Annals of Probability , volume =
-
[66]
Annals of Statistics , volume =
Statistical Inference Using Extreme Order Statistics , author =. Annals of Statistics , volume =
-
[67]
An Introduction to Statistical Modeling of Extreme Values , author =
-
[68]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =
Probability Models for Open Set Recognition , author =. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =
-
[69]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages =
Towards Open Set Deep Networks , author =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages =
-
[70]
2024 , url=
Weiqin Yang and Jiawei Chen and Xin Xin and Sheng Zhou and Binbin Hu and Yan Feng and Chun Chen and Can Wang , booktitle=. 2024 , url=
2024
-
[71]
Provable Guarantees for Self-Supervised Deep Learning with Spectral Contrastive Loss , author =
-
[72]
The Twelfth International Conference on Learning Representations (ICLR) , year =
Contrastive Learning Is Spectral Clustering On Similarity Graph , author =. The Twelfth International Conference on Learning Representations (ICLR) , year =
-
[73]
2019 , volume =
A Theoretical Analysis of Contrastive Unsupervised Representation Learning , author =. 2019 , volume =
2019
-
[74]
Deep Reinforcement Learning from Human Preferences , author =
-
[75]
, journal =
Bradley, Ralph Allan and Terry, Milton E. , journal =. Rank Analysis of Incomplete Block Designs:
-
[76]
Learning Multiple Layers of Features from Tiny Images , author =
-
[77]
Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics (AISTATS) , pages =
An Analysis of Single-Layer Networks in Unsupervised Feature Learning , author =. Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics (AISTATS) , pages =
-
[78]
2009 , organization =
Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li , booktitle = CVPR, pages =. 2009 , organization =
2009
-
[79]
A Downsampled Variant of
Chrabaszcz, Patryk and Loshchilov, Ilya and Hutter, Frank , booktitle =. A Downsampled Variant of
-
[80]
Journal of the Royal Statistical Society: Series C (Applied Statistics) , volume =
The Analysis of Permutations , author =. Journal of the Royal Statistical Society: Series C (Applied Statistics) , volume =
-
[81]
Individual Choice Behavior: A Theoretical Analysis , author =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.