RSEdit: Text-Guided Image Editing for Remote Sensing
Pith reviewed 2026-05-21 10:57 UTC · model grok-4.3
The pith
RSEdit adapts text-to-image models with conditioning strategies to enable faithful edits on remote sensing images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
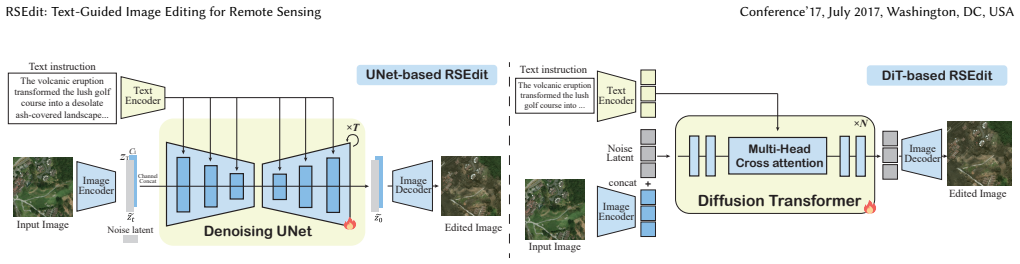
RSEdit consists of models ranging from U-Net to Diffusion Transformer architectures in different setups. Through a comprehensive study of conditioning strategies, these models deliver the most accurate edits that follow the given text instructions and maintain the original geospatial structure in remote sensing images.
What carries the argument
RSEdit, a collection of models from U-Net to DiT with various configurations, carries the argument by enabling the first full examination of how conditioning strategies transfer from general text-to-image models to the remote sensing domain.
If this is right
- Text instructions can guide precise modifications to elements in remote sensing scenes without shifting positions or scales.
- Both U-Net and DiT-based models support effective editing once appropriate conditioning is applied.
- Instruction adherence improves while geospatial structure stays intact compared with direct use of general models.
- The method supports practical updates to imagery for monitoring or planning tasks that rely on accurate location data.
Where Pith is reading between the lines
- The same conditioning patterns might transfer to other domains that demand strict structural preservation, such as medical or architectural imagery.
- Integration with mapping tools could allow natural-language corrections to satellite data in near real time.
- Broader user studies with varied phrasing and complex multi-step instructions would test how far the current results generalize.
Load-bearing premise
Conditioning strategies developed for general text-to-image models transfer effectively to the remote sensing domain without major degradation in structural fidelity or instruction adherence.
What would settle it
An independent test on new remote sensing images where RSEdit edits either deviate from the text instructions or distort geospatial features more than baseline methods would falsify the central performance claim.
Figures









read the original abstract
In this paper, we explore text-guided image editing in the remote sensing domain using generative modeling. We propose \rsedit, a collection of models from U-Net to DiT with various configurations. Specifically, we present the first comprehensive study of conditioning strategies for building image editing models from off-the-shelf text-to-image ones. Our experiments show that \rsedit achieves the best instruction-faithful edits while preserving geospatial structure. We release the code at \url{https://github.com/Bili-Sakura/RSEdit-Preview} and checkpoints at \url{https://huggingface.co/collections/BiliSakura/rsedit}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RSEdit, a collection of U-Net and DiT-based models for text-guided image editing in the remote sensing domain. It presents the first comprehensive study of conditioning strategies adapted from off-the-shelf text-to-image models and claims that experiments demonstrate RSEdit achieves the best instruction-faithful edits while preserving geospatial structure. Code and checkpoints are released publicly.
Significance. If substantiated with appropriate metrics, the work could meaningfully extend generative editing techniques to remote sensing, where structural fidelity is critical for applications like change detection and urban analysis. The explicit release of code at https://github.com/Bili-Sakura/RSEdit-Preview and checkpoints on Hugging Face is a clear strength that enables reproducibility and follow-on research.
major comments (1)
- [Experiments] Experiments section: the central claim that RSEdit produces edits that are both instruction-faithful and preserve geospatial structure (orthographic geometry, scale consistency, object-level spatial relations) is under-supported if evaluation relies primarily on general perceptual or CLIP-based scores rather than domain-appropriate controls such as geometric distortion scores or segmentation-consistency IoU between edited and original imagery.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment below and outline the revisions we will make to strengthen the experimental support for our claims.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim that RSEdit produces edits that are both instruction-faithful and preserve geospatial structure (orthographic geometry, scale consistency, object-level spatial relations) is under-supported if evaluation relies primarily on general perceptual or CLIP-based scores rather than domain-appropriate controls such as geometric distortion scores or segmentation-consistency IoU between edited and original imagery.
Authors: We appreciate this observation. Our current experiments evaluate instruction faithfulness primarily via CLIP-based similarity and perceptual metrics such as FID and LPIPS, while visual inspection is used to illustrate preservation of geospatial structure. We agree that these are indirect for the specific properties mentioned (orthographic geometry, scale consistency, and object-level spatial relations). In the revised manuscript we will add quantitative domain-appropriate controls: (1) geometric distortion scores computed via keypoint matching and homography estimation between original and edited images, and (2) segmentation-consistency IoU obtained by running a fixed remote-sensing segmentation model on both images and measuring overlap of corresponding object masks. These results will be reported in an expanded Experiments section with corresponding tables and discussion. revision: yes
Circularity Check
No circularity: empirical adaptation study with released code
full rationale
The paper describes an empirical application of off-the-shelf text-to-image models (U-Net and DiT variants) to remote sensing image editing. It conducts a study of conditioning strategies and reports experimental outcomes on instruction faithfulness and geospatial preservation, with code and checkpoints released for external verification. No derivation chain, equations, or first-principles results are claimed that reduce by construction to fitted parameters, self-definitions, or self-citation load-bearing premises. The central claims rest on experimental comparisons rather than any self-referential reduction, satisfying the criteria for a self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Off-the-shelf text-to-image models can be effectively conditioned for remote sensing image editing tasks.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose RSEdit, a unified framework that adapts pre-trained text-to-image diffusion models—both U-Net and DiT—into instruction-following RS editors via channel concatenation and in-context token concatenation.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
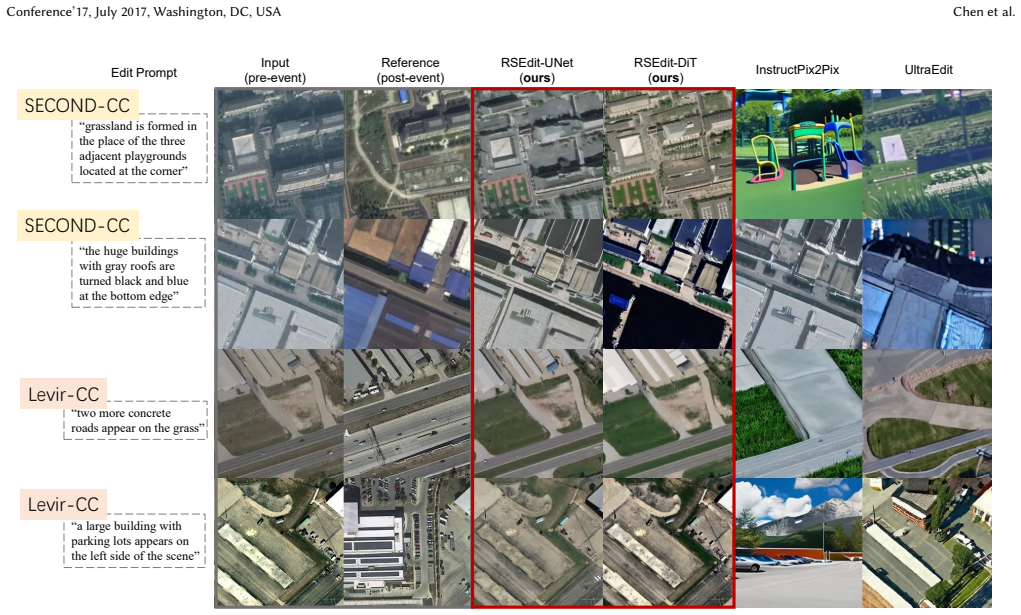
Experiments show clear gains over general and commercial baselines, demonstrating strong generalizability across diverse scenarios including disaster impacts, urban growth, and seasonal shifts.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Learning from Multimodal and Multitem- poral Earth Observation Data for Building Damage Mapping.ISPRS Journal of Pho- togrammetry and Remote Sensing175 (May 2021), 132–143. doi:10.1016/j.isprsjprs. 2021.02.016 Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine
-
[2]
InThe Twelfth International Conference on Learning Representations
Train- ing Diffusion Models with Reinforcement Learning. InThe Twelfth International Conference on Learning Representations. Conference’17, July 2017, Washington, DC, USA Chen et al. Black Forest Labs
work page 2017
-
[3]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
FLUX.1 Kontext: Flow Matching for In-Context Image Gener- ation and Editing in Latent Space. arXiv:2506.15742 [cs] doi:10.48550/arXiv.2506. 15742 Tim Brooks, Aleksander Holynski, and Alexei A Efros
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506
-
[4]
Controllable Generation with Text-to-Image Diffusion Models: A Survey.IEEE Transactions on Pattern Analysis and Machine Intelligence(2025), 1–20. doi:10.1109/TPAMI.2025.3646548 Hongruixuan Chen, Jian Song, Olivier Dietrich, Clifford Broni-Bediako, Weihao Xuan, Junjue Wang, Xinlei Shao, Yimin Wei, Junshi Xia, Cuiling Lan, Konrad Schindler, and Naoto Yokoya...
-
[5]
InThe Twelfth International Conference on Learning Representations
PixArt-𝛼: Fast Train- ing of Diffusion Transformer for Photorealistic Text-to-Image Synthesis. InThe Twelfth International Conference on Learning Representations. Weizhi Chen, Yupeng Deng, Wei Jin, Jingbo Chen, Jiansheng Chen, Yuman Feng, Zhi- hao Xi, Diyou Liu, Kai Li, and Yu Meng. 2025a. DGTRSD and DGTRSCLIP: A Dual- Granularity Remote Sensing Image–Tex...
-
[6]
Functional Map of the World - Sentinel-2 Corresponding Images. (2022). doi:10.25740/vg497cb6002 Runmin Dong, Shuai Yuan, Litong Feng, Jinxiao Zhang, Weijia Li, Mengxuan Chen, Bin Luo, Wayne Zhang, and Haohuan Fu
-
[7]
Information Fusion127 (March 2026), 103839
Transferable Image Synthesis for Remote Sensing Semantic Segmentation via Joint Reference-Semantic Fusion. Information Fusion127 (March 2026), 103839. doi:10.1016/j.inffus.2025.103839 Ying Fan, Olivia Watkins, Yuqing Du, Hao Liu, Moonkyung Ryu, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, Kangwook Lee, and Kimin Lee
-
[8]
Surv.57, 9 (May 2025), 243:1– 243:66
AI-Generated Content (AIGC) for Various Data Modalities: A Survey.ACM Comput. Surv.57, 9 (May 2025), 243:1– 243:66. doi:10.1145/3728633 Shiran Ge, Chenyi Huang, Yuang Ai, Qihang Fan, Huaibo Huang, and Ran He
-
[9]
Expand and Prune: Maximizing Trajectory Diversity for Effective GRPO in Gener- ative Models. arXiv:2512.15347 [cs] doi:10.48550/arXiv.2512.15347 Ritwik Gupta, Bryce Goodman, Nirav Patel, Ricky Hosfelt, Sandra Sajeev, Eric Heim, Jigar Doshi, Keane Lucas, Howie Choset, and Matthew Gaston
-
[10]
doi:10.1109/JSTARS.2025.3584418 Jonathan Ho, Ajay Jain, and Pieter Abbeel
Exploring Text-Guided Single Image Editing for Remote Sensing Images.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing(2025), 18117–18133. doi:10.1109/JSTARS.2025.3584418 Jonathan Ho, Ajay Jain, and Pieter Abbeel
-
[11]
Cascaded Diffusion Models for High Fidelity Image Gen- eration.JMLR 202223, 1 (Jan. 2022), 47:2249–47:2281. Yi Huang, Jiancheng Huang, Yifan Liu, Mingfu Yan, Jiaxi Lv, Jianzhuang Liu, Wei Xiong, He Zhang, Liangliang Cao, and Shifeng Chen
work page 2022
-
[12]
Diffusion Model-Based Image Editing: A Survey.IEEE Transactions on Pattern Analysis and Machine Intel- ligence(2025), 1–27. doi:10.1109/TPAMI.2025.3541625 Ali Can Karaca, Enes Ozelbas, Saadettin Berber, Orkhan Karimli, Turabi Yildirim, and M. Fatih Amasyali
-
[13]
Robust Change Captioning in Remote Sensing: SECOND- CC Dataset and MModalCC Framework.IEEE Journal of Selected Topics in Ap- plied Earth Observations and Remote Sensing(2025), 1–21. doi:10.1109/JSTARS. 2025.3600613 Samar Khanna, Patrick Liu, Linqi Zhou, Chenlin Meng, Robin Rombach, Marshall Burke, David B. Lobell, and Stefano Ermon
-
[14]
VIEScore: Towards Explainable Metrics for Conditional Image Synthesis Evaluation. InPro- ceedings of the 62nd Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vivek Sriku- mar (Eds.). Association for Computational Linguistics, Bangkok, Thailand, 12268– 12290. doi:10.18653/v1/2024.acl...
-
[15]
Flow-GRPO: Training Flow Matching Models via Online RL
Re- mote Sensing Image Change Captioning With Dual-Branch Transformers: A New Method and a Large Scale Dataset.TGRS(2022), 1–20. doi:10.1109/TGRS.2022. 3218921 Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. 2025d. Flow-GRPO: Training Flow Matching Models via Online RL. arXiv:2505.05470 [...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/tgrs.2022 2022
-
[16]
Inference-Time Scaling for Diffusion Models beyond Scaling Denoising Steps
Inference- time scaling for diffusion models beyond scaling denoising steps.arXiv preprint arXiv:2501.09732(2025). Oscar Mañas, Alexandre Lacoste, Xavier Giró-i-Nieto, David Vazquez, and Pau Ro- dríguez
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
EarthSynth: Generating Informa- tive Earth Observation with Diffusion Models. arXiv:2505.12108 [cs] doi:10.48550/ arXiv.2505.12108 Li Pang, Xiangyong Cao, Datao Tang, Shuang Xu, Xueru Bai, Feng Zhou, and Deyu Meng
-
[18]
IEEE Transactions on Pattern Analysis and Machine Intelligence48, 1 (Jan
HSIGene: A Foundation Model for Hyperspectral Image Generation. IEEE Transactions on Pattern Analysis and Machine Intelligence48, 1 (Jan. 2026), 730–746. doi:10.1109/TPAMI.2025.3610927 William Peebles and Saining Xie
-
[19]
doi:10.1007/978-3-319-24574-4_28 Srikumar Sastry, Subash Khanal, Aayush Dhakal, and Nathan Jacobs
Springer International Publishing, Cham, 234–241. doi:10.1007/978-3-319-24574-4_28 Srikumar Sastry, Subash Khanal, Aayush Dhakal, and Nathan Jacobs
-
[20]
RSDiff: Remote Sensing Image Generation from Text Using Diffusion Model.Neural Computing and Applications36, 36 (Dec. 2024), 23103–23111. doi:10.1007/s00521-024-10363-3 RSEdit: Text-Guided Image Editing for Remote Sensing Conference’17, July 2017, Washington, DC, USA Adam Stewart, Nils Lehmann, Isaac Corley, Yi Wang, Yi-Chia Chang, Nassim Ait Ait Ali Brah...
-
[21]
Zhenxiong Tan, Songhua Liu, Xingyi Yang, Qiaochu Xue, and Xinchao Wang
Curran Associates, Inc., 59787–59807. Zhenxiong Tan, Songhua Liu, Xingyi Yang, Qiaochu Xue, and Xinchao Wang. 2025a. OminiControl: Minimal and Universal Control for Diffusion Transformer. InPro- ceedings of the IEEE/CVF International Conference on Computer Vision. 14940– 14950. Zhenxiong Tan, Qiaochu Xue, Xingyi Yang, Songhua Liu, and Xinchao Wang. 2025b....
-
[22]
CRS-Diff: Controllable Remote Sensing Image Generation With Dif- fusion Model.TGRS(2024), 1–14. doi:10.1109/TGRS.2024.3453414 Datao Tang, Hao Wang, Yudeng Xin, Hui Qiao, Dongsheng Jiang, Yin Li, Zhiheng Yu, and Xiangyong Cao
-
[23]
TerraGen: A Unified Multi-Task Layout Generation Framework for Remote Sensing Data Augmentation. arXiv:2510.21391 [cs] doi:10. 48550/arXiv.2510.21391 Aysim Toker, Marvin Eisenberger, Daniel Cremers, and Laura Leal-Taixé
-
[24]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Dif- fusion Model Alignment Using Direct Preference Optimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8228–8238. Junjue Wang, Ailong Ma, Zihang Chen, Zhuo Zheng, Yuting Wan, Liangpei Zhang, and Yanfei Zhong. 2024a. EarthVQANet: Multi-task Visual Question Answering for Remote Sensing Image Understanding.ISPR...
-
[25]
DisasterM3: A Remote Sensing Vision-Language Dataset for Disaster Damage Assessment and Response. InNeurIPS. Junjue Wang, Zhuo Zheng, Zihang Chen, Ailong Ma, and Yanfei Zhong. 2024c. Earth- VQA: Towards Queryable Earth via Relational Reasoning-Based Remote Sensing Visual Question Answering.Proceedings of the AAAI Conference on Artificial Intel- ligence38,...
-
[26]
EarthVL: A Progressive Earth Vision-Language Understanding and Generation Framework. arXiv:2601.02783 [cs] doi:10.48550/arXiv.2601.02783 Mingze Wang, Lili Su, Cilin Yan, Sheng Xu, Pengcheng Yuan, Xiaolong Jiang, and Baochang Zhang. 2024b. RSBuilding: Toward General Remote Sensing Image Building Extraction and Change Detection With Foundation Model.IEEE Tr...
-
[27]
SSL4EO-S12: A Large-Scale Multimodal, Multitempo- ral Dataset for Self-Supervised Learning in Earth Observation [Software and Data Sets].IEEE Geoscience and Remote Sensing Magazine11, 3 (Sept. 2023), 98–106. doi:10.1109/MGRS.2023.3281651 Fan Wei, Runmin Dong, Yushan Lai, Yixiang Yang, Zhaoyang Luo, Jinxiao Zhang, Miao Yang, Shuai Yuan, Jiyao Zhao, Bin Luo...
-
[28]
RS-Prune: Training-Free Data Pruning at High Ratios for Efficient Remote Sensing Diffusion Foundation Models. arXiv:2512.23239 [cs] doi:10.48550/arXiv.2512.23239 Xiaobo Xia, Jiale Liu, Jun Yu, Xu Shen, Bo Han, and Tongliang Liu
-
[29]
In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV)
Good Seed Makes a Good Crop: Discovering Secret Seeds in Text-to-Image Diffusion Models. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV). 3024–3034. doi:10. 1109/WACV61041.2025.00299 Weihao Xuan, Junjue Wang, Heli Qi, Zihang Chen, Zhuo Zheng, Yanfei Zhong, Jun- shi Xia, and Naoto Yokoya
-
[30]
Task-Oriented Data Synthesis and Control-Rectify Sampling for Remote Sensing Semantic Segmentation. arXiv:2512.16740 [cs] doi:10.48550/arXiv.2512.16740 Srikar Yellapragada, Alexandros Graikos, Kostas Triaridis, Prateek Prasanna, Rajarsi Gupta, Joel Saltz, and Dimitris Samaras
-
[31]
ZoomLDM: Latent Diffusion Model for Multi-scale Image Generation. InCVPR. 23453–23463. Qifan Yu, Wei Chow, Zhongqi Yue, Kaihang Pan, Yang Wu, Xiaoyang Wan, Juncheng Li, Siliang Tang, Hanwang Zhang, and Yueting Zhuang. 2025a. Anyedit: Mastering unified high-quality image editing for any idea. InProceedings of the Computer Vision and Pattern Recognition Con...
-
[32]
ChangeDiff: A Multi-Temporal Change Detection Data Generator with Flexible Text Prompts via Diffusion Model.Proceedings of the AAAI Conference on Artificial Intelligence39, 9 (April 2025), 9763–9771. doi:10.1609/aaai.v39i9.33058 Zheyuan Zhan, Defang Chen, Jian-Ping Mei, Zhenghe Zhao, Jiawei Chen, Chun Chen, Siwei Lyu, and Can Wang
-
[33]
Jiawei Zhang, Xiaolin Zhou, Weidong Jiang, Xiaolong Su, Zhen Liu, and Li Liu
Conditional Image Synthesis with Diffusion Mod- els: A Survey.Transactions on Machine Learning Research(2025). Jiawei Zhang, Xiaolin Zhou, Weidong Jiang, Xiaolong Su, Zhen Liu, and Li Liu
work page 2025
-
[34]
Extrapolate Azimuth Angles: Text and Edge Guided ISAR Image Generation Based on Foundation Model.ISPRS Journal of Photogrammetry and Remote Sensing232 (Feb. 2026), 109–123. doi:10.1016/j.isprsjprs.2025.12.002 Kai Zhang, Lingbo Mo, Wenhu Chen, Huan Sun, and Yu Su. 2023a. MagicBrush: A Manually Annotated Dataset for Instruction-Guided Image Editing. InNeura...
-
[35]
In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV), pp
Curran Associates, Inc., 31428–31449. Kai Zhang, Lingbo Mo, Wenhu Chen, Huan Sun, and Yu Su. 2023b. Magicbrush: A man- ually annotated dataset for instruction-guided image editing.Advances in Neural Information Processing Systems(2023), 31428–31449. Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. 2023c. Adding Conditional Control to Text-to-Image Diffusion M...
-
[36]
ChangeBridge: Spatiotemporal Image Generation with Multimodal Controls for Remote Sensing
ChangeBridge: Spatiotemporal Image Generation with Multimodal Controls for Remote Sensing. arXiv:2507.04678 [cs] doi:10.48550/arXiv.2507.04678 Zhuo Zheng, Stefano Ermon, Dongjun Kim, Liangpei Zhang, and Yanfei Zhong. 2024a. Changen2: Multi-Temporal Remote Sensing Generative Change Foundation Model. IEEE Transactions on Pattern Analysis and Machine Intelli...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.04678 2024
-
[37]
In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV), pp
Scal- able Multi-Temporal Remote Sensing Change Data Generation via Simulating Sto- chastic Change Process. InProceedings of the IEEE/CVF International Conference on Computer Vision. 21761–21770. doi:10.1109/ICCV51070.2023.01994 Zhuo Zheng, Yanfei Zhong, Zijing Wan, Liangpei Zhang, and Stefano Ermon
-
[38]
Neural Disaster Simulation for Transferable Building Damage Assessment.Remote Sensing of Environment(Dec. 2025), 114979. doi:10.1016/j.rse.2025.114979 Zhuo Zheng, Yanfei Zhong, Junjue Wang, Ailong Ma, and Liangpei Zhang. 2021b. Building Damage Assessment for Rapid Disaster Response with a Deep Object- Based Semantic Change Detection Framework: From Natura...
-
[39]
InThe Thirteenth International Conference on Learning Representations
DSPO: Direct Score Prefer- ence Optimization for Diffusion Model Alignment. InThe Thirteenth International Conference on Learning Representations. Conference’17, July 2017, Washington, DC, USA Chen et al. Input (pre-event) Reference (post-event) RSEdit-UNet (ours) RSEdit-DiT (ours)Damage Mask SD 1.5 SD 2.1 Text2Earth InstructPix2Pix UltraEdit Flux.1 Konte...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.