PopuLoRA: Co-Evolving LLM Populations for Reasoning Self-Play
Pith reviewed 2026-05-19 21:33 UTC · model grok-4.3
The pith
A population of specialized LoRA adapters in asymmetric self-play creates a co-evolutionary arms race that improves LLM reasoning over single-agent baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
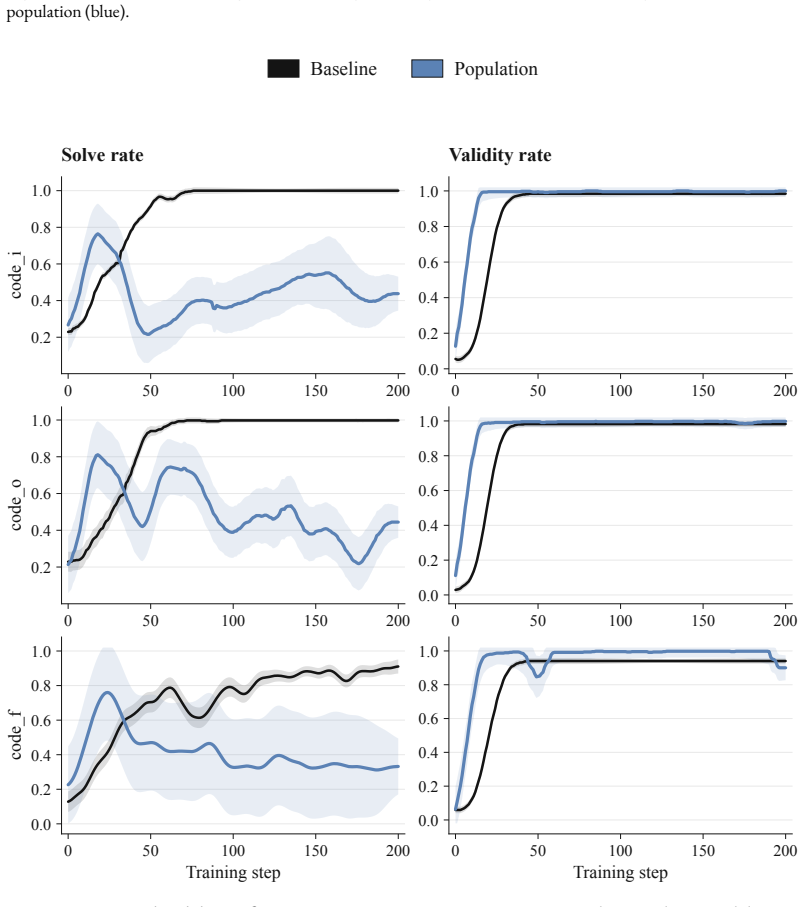
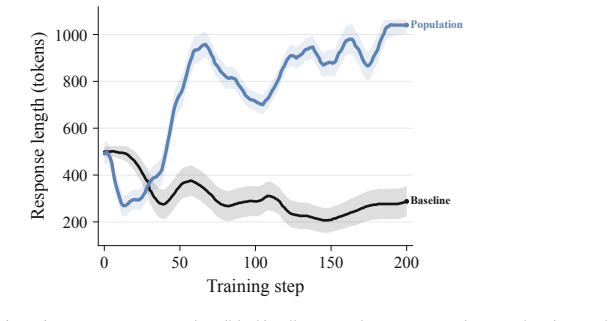
PopuLoRA places specialized LoRA adapters into asymmetric self-play where teachers propose problems solved by matched students under a programmatic verifier, with cross-evaluation between sub-populations replacing single-agent self-calibration. LoRA weight-space evolution operators generate mutations and crossovers to maintain same-rank population members. Against a per-adapter compute-matched single-agent baseline, the population avoids convergence on easy problems, enters a co-evolutionary arms race with rising problem complexity and oscillating solve rates, and delivers higher benchmark scores despite lower training-time reward.
What carries the argument
Asymmetric teacher-student roles among specialized LoRA adapters on a shared base, combined with cross-evaluation between sub-populations and LoRA weight-space mutations plus crossovers for population evolution.
If this is right
- The population mean outperforms the single-agent baseline on HumanEval+, MBPP+, LiveCodeBench and on AIME 24/25, AMC 23, MATH-500, Minerva, GSM8K, OlympiadBench.
- Even the weakest population member beats the baseline on aggregate across those benchmarks.
- Teachers generate increasingly complex problems throughout training rather than easy ones the students already solve.
- Student solve rates oscillate instead of converging to a stable high value.
- Problem-space coverage continues to expand for the duration of training.
Where Pith is reading between the lines
- Measuring the distribution of problem difficulty scores over training steps could directly test whether the arms race persists.
- The oscillation pattern may indicate a dynamic equilibrium that keeps the population from overfitting to any fixed problem subset.
- Extending the same teacher-student cross-evaluation structure to non-reasoning RLVR domains could sustain diversity in other verifiable tasks.
- Population members could be periodically archived to create a growing library of increasingly capable specialist adapters.
Load-bearing premise
Cross-evaluation between sub-populations reliably blocks self-calibration and maintains an expanding problem-space arms race instead of letting the group settle on a narrow set of solvable problems.
What would settle it
Observing that generated problem difficulty or diversity stops rising after early training steps, or that student solve rates flatten without continued oscillation, would indicate the claimed arms race has collapsed.
Figures

















read the original abstract
We introduce PopuLoRA, a population-based asymmetric self-play framework for reinforcement learning with verifiable rewards (RLVR) post-training of LLMs. Teachers and students are specialised LoRA adapters on a shared frozen base: teachers propose problems, matched students solve them under a programmatic verifier, and cross-evaluation between sub-populations replaces the self-calibration that limits single-agent self-play. A family of LoRA weight-space evolution operators (mutations and crossovers that produce same-rank population members in seconds) serves as the replacement step of a population-based training loop at 7B scale. We instantiate PopuLoRA on top of Absolute Zero Reasoner and compare it against a per-adapter compute-matched single-agent baseline. Where the single agent self-calibrates to generating easy problems it can reliably solve, the population enters a co-evolutionary arms race: teachers produce increasingly complex problems, student solve rates oscillate, and problem-space coverage keeps expanding throughout training. Despite lower training-time reward, the population mean outperforms the baseline on three code benchmarks (HumanEval+, MBPP+, LiveCodeBench) and seven math benchmarks (AIME 24/25, AMC 23, MATH-500, Minerva, GSM8K, OlympiadBench), and even the weakest member of the population beats the baseline on aggregate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PopuLoRA, a population-based asymmetric self-play framework for RLVR post-training of LLMs. Teachers and students are specialized LoRA adapters on a shared frozen base; teachers propose problems that matched students solve under a programmatic verifier, with cross-evaluation between sub-populations replacing self-calibration. A family of LoRA weight-space mutation and crossover operators enables population evolution at 7B scale. The central claim is that this induces a co-evolutionary arms race (increasingly complex problems, oscillating solve rates, expanding coverage) that yields superior benchmark performance: the population mean and even its weakest member outperform a compute-matched per-adapter single-agent baseline on three code benchmarks (HumanEval+, MBPP+, LiveCodeBench) and seven math benchmarks (AIME 24/25, AMC 23, MATH-500, Minerva, GSM8K, OlympiadBench), despite lower training-time reward.
Significance. If the claimed mechanism is substantiated, the work would demonstrate a practical route to scaling self-play for reasoning without the self-calibration trap that limits single-agent approaches, offering a population-level alternative to standard RLVR post-training.
major comments (2)
- [Abstract and experimental results] Abstract and experimental results section: the attribution of outperformance to a sustained co-evolutionary arms race with expanding problem-space coverage rests on qualitative descriptions of oscillating solve rates. No time-series statistics are reported on problem metrics (e.g., average solution length, verifier pass-rate on fixed hard subsets, or entropy of problem types) that would distinguish progressive difficulty growth from static diversity or ensemble effects.
- [Methods] Methods section on population loop and cross-evaluation: the claim that cross-evaluation between sub-populations reliably prevents self-calibration and sustains an expanding problem space lacks quantitative verification. The manuscript does not report how sub-population splits and matching are implemented or whether problem coverage continues to expand after initial exploration.
minor comments (2)
- [Results] Add error bars or multiple-run statistics to benchmark tables and training curves to support the reported outperformance claims.
- [Experimental setup] Clarify the exact values and sensitivity of free parameters (LoRA mutation/crossover rates, population size, sub-population split) in the experimental setup.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to strengthen the empirical support for the co-evolutionary mechanism. We respond to each major comment below and will incorporate revisions to provide additional quantitative analyses where the current evidence is primarily qualitative.
read point-by-point responses
-
Referee: [Abstract and experimental results] Abstract and experimental results section: the attribution of outperformance to a sustained co-evolutionary arms race with expanding problem-space coverage rests on qualitative descriptions of oscillating solve rates. No time-series statistics are reported on problem metrics (e.g., average solution length, verifier pass-rate on fixed hard subsets, or entropy of problem types) that would distinguish progressive difficulty growth from static diversity or ensemble effects.
Authors: We agree that the current presentation relies on qualitative descriptions of oscillating solve rates and expanding coverage. To better substantiate the distinction between progressive difficulty growth and alternative explanations such as static diversity or ensemble effects, we will add time-series statistics and plots in the revised experimental results section. These will include average solution length, verifier pass-rates on fixed hard subsets, and entropy of problem types over training steps. revision: yes
-
Referee: [Methods] Methods section on population loop and cross-evaluation: the claim that cross-evaluation between sub-populations reliably prevents self-calibration and sustains an expanding problem space lacks quantitative verification. The manuscript does not report how sub-population splits and matching are implemented or whether problem coverage continues to expand after initial exploration.
Authors: The methods section (Section 3) describes the population loop, including the division into sub-populations and the cross-evaluation matching procedure used to replace self-calibration. We acknowledge, however, that quantitative verification of continued expansion after initial exploration is not fully reported. In the revision we will add metrics and visualizations tracking problem coverage (e.g., unique problem-type counts and difficulty distributions) across training phases to confirm sustained expansion beyond the early stages. revision: yes
Circularity Check
Empirical benchmark comparison with no self-referential derivation or fitted prediction
full rationale
The manuscript describes an algorithmic framework (PopuLoRA) instantiated on top of Absolute Zero Reasoner and evaluated via direct, compute-matched comparison to a single-adapter baseline on fixed external benchmarks (HumanEval+, MBPP+, LiveCodeBench, AIME, AMC, MATH-500, etc.). No equations, uniqueness theorems, or first-principles derivations are presented that reduce the reported performance gains to quantities defined by the method itself. The co-evolutionary narrative is supported by qualitative observations of oscillating solve rates and expanding coverage rather than any closed-loop mathematical reduction or self-citation chain. This is a standard empirical RLVR study whose central claims rest on external test sets and are therefore self-contained against the listed circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (2)
- LoRA mutation and crossover rates
- Population size and sub-population split
axioms (1)
- domain assumption Programmatic verifier supplies accurate and unbiased rewards for generated problems
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
teachers propose problems, matched students solve them under a programmatic verifier, and cross-evaluation between sub-populations replaces the self-calibration... LoRA weight-space evolution operators (mutations and crossovers...)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Vinyals, Oriol and Babuschkin, Igor and Czarnecki, Wojciech M. and Mathieu, Micha. Grandmaster Level in. Nature , volume =. 2019 , doi =
work page 2019
-
[2]
International Conference on Learning Representations , year =
Intrinsic Motivation and Automatic Curricula via Asymmetric Self-Play , author =. International Conference on Learning Representations , year =
-
[3]
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Bi, Xiao and Zhang, Haowei and Zhang, Mingchuan and Li, Y. K. and Wu, Y. and Guo, Daya , year =. doi:10.48550/arXiv.2402.03300 , url =. 2402.03300 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.03300
-
[4]
Proximal Policy Optimization Algorithms
Proximal Policy Optimization Algorithms , author =. 2017 , eprint =. doi:10.48550/arXiv.1707.06347 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1707.06347 2017
-
[5]
Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning , author =. Machine Learning , volume =. 1992 , doi =
work page 1992
-
[6]
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization
Hu, Jian and Liu, Jason Klein and Xu, Haotian and Shen, Wei , year =. doi:10.48550/arXiv.2501.03262 , url =. 2501.03262 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.03262
-
[7]
Advances in Neural Information Processing Systems , volume =
Training Language Models to Follow Instructions with Human Feedback , author =. Advances in Neural Information Processing Systems , volume =. 2022 , url =
work page 2022
-
[8]
Illuminating search spaces by mapping elites
Illuminating Search Spaces by Mapping Elites , author =. 2015 , eprint =. doi:10.48550/arXiv.1504.04909 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1504.04909 2015
-
[9]
Vassiliades, Vassilis and Chatzilygeroudis, Konstantinos and Mouret, Jean-Baptiste , journal =. Using Centroidal. 2018 , doi =
work page 2018
-
[10]
Advances in Neural Information Processing Systems , volume =
Emergent Complexity and Zero-Shot Transfer via Unsupervised Environment Design , author =. Advances in Neural Information Processing Systems , volume =. 2020 , url =
work page 2020
-
[11]
Wang, Rui and Lehman, Joel and Clune, Jeff and Stanley, Kenneth O. , booktitle =. 2019 , publisher =. doi:10.1145/3321707.3321799 , url =
-
[12]
Proceedings of the 39th International Conference on Machine Learning , pages =
Evolving Curricula with Regret-Based Environment Design , author =. Proceedings of the 39th International Conference on Machine Learning , pages =. 2022 , volume =
work page 2022
-
[13]
International Conference on Learning Representations , year =
Emergent Tool Use from Multi-Agent Autocurricula , author =. International Conference on Learning Representations , year =
-
[14]
Deep Reinforcement Learning from Self-Play in Imperfect-Information Games
Deep Reinforcement Learning from Self-Play in Imperfect-Information Games , author =. 2016 , eprint =. doi:10.48550/arXiv.1603.01121 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1603.01121 2016
-
[15]
Qwen2.5-Coder Technical Report
Hui, Binyuan and Yang, Jian and Cui, Zeyu and Yang, Jiaxi and Liu, Dayiheng and Zhang, Lei and Liu, Tianyu and Zhang, Jiajun and Yu, Bowen and Lu, Keming and Dang, Kai and Fan, Yang and Zhang, Yichang and Yang, An and Men, Rui and Huang, Fei and Zheng, Bo and Miao, Yibo and Quan, Shanghaoran and Feng, Yunlong and Ren, Xingzhang and Ren, Xuancheng and Zhou...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2409.12186
-
[16]
Efficient Memory Management for Large Language Model Serving with PagedAttention , booktitle =
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph E. and Zhang, Hao and Stoica, Ion , booktitle =. Efficient Memory Management for Large Language Model Serving with. 2023 , publisher =. doi:10.1145/3600006.3613165 , url =
-
[17]
Sheng, Ying and Cao, Shiyi and Li, Dacheng and Hooper, Coleman and Lee, Nicholas and Yang, Shuo and Chou, Christopher and Zhu, Banghua and Zheng, Lianmin and Keutzer, Kurt and Gonzalez, Joseph E. and Stoica, Ion , booktitle =. 2024 , url =
work page 2024
-
[18]
Evaluating Large Language Models Trained on Code
Evaluating Large Language Models Trained on Code , author =. 2021 , eprint =. doi:10.48550/arXiv.2107.03374 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2107.03374 2021
-
[19]
Liu, Jiawei and Xia, Chunqiu Steven and Wang, Yuyao and Zhang, Lingming , booktitle =. Is Your Code Generated by. 2023 , url =
work page 2023
-
[20]
Program Synthesis with Large Language Models
Program Synthesis with Large Language Models , author =. 2021 , eprint =. doi:10.48550/arXiv.2108.07732 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2108.07732 2021
-
[21]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Jain, Naman and Han, King and Gu, Alex and Li, Wen-Ding and Yan, Fanjia and Zhang, Tianjun and Wang, Sida and Solar-Lezama, Armando and Sen, Koushik and Stoica, Ion , year =. doi:10.48550/arXiv.2403.07974 , url =. 2403.07974 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2403.07974
-
[22]
Measuring Mathematical Problem Solving with the
Hendrycks, Dan and Burns, Collin and Kadavath, Saurav and Arora, Akul and Basart, Steven and Tang, Eric and Song, Dawn and Steinhardt, Jacob , booktitle =. Measuring Mathematical Problem Solving with the. 2021 , url =
work page 2021
-
[23]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author =. 2021 , eprint =. doi:10.48550/arXiv.2110.14168 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2110.14168 2021
-
[24]
Advances in Neural Information Processing Systems , volume =
Solving Quantitative Reasoning Problems with Language Models , author =. Advances in Neural Information Processing Systems , volume =. 2022 , url =
work page 2022
-
[25]
He, Chaoqun and Luo, Renjie and Bai, Yuzhuo and Hu, Shengding and Thai, Zhen and Shen, Junhao and Hu, Jinyi and Han, Xu and Huang, Yujie and Zhang, Yuxiang and Liu, Jie and Qi, Lei and Liu, Zhiyuan and Sun, Maosong , booktitle =. 2024 , address =. doi:10.18653/v1/2024.acl-long.211 , url =
-
[26]
International Conference on Learning Representations , year =
Let's Verify Step by Step , author =. International Conference on Learning Representations , year =
-
[27]
Le, Hung and Wang, Yue and Gotmare, Akhilesh Deepak and Savarese, Silvio and Hoi, Steven C. H. , booktitle =. 2022 , url =
work page 2022
-
[28]
Absolute Zero: Reinforced Self-play Reasoning with Zero Data
Absolute Zero: Reinforced Self-play Reasoning with Zero Data , author =. 2025 , eprint =. doi:10.48550/arXiv.2505.03335 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.03335 2025
-
[29]
Population Based Training of Neural Networks
Population Based Training of Neural Networks , author =. 2017 , eprint =. doi:10.48550/arXiv.1711.09846 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1711.09846 2017
-
[30]
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =. 2022 , url =
work page 2022
-
[31]
Yu, Le and Yu, Bowen and Yu, Haiyang and Huang, Fei and Li, Yongbin , booktitle =. 2024 , volume =
work page 2024
-
[32]
Yadav, Prateek and Tam, Derek and Choshen, Leshem and Raffel, Colin and Bansal, Mohit , booktitle =. 2023 , url =
work page 2023
-
[33]
International Conference on Learning Representations , year =
Editing Models with Task Arithmetic , author =. International Conference on Learning Representations , year =
-
[34]
Jain, Neel and Chiang, Ping-Yeh and Wen, Yuxin and Kirchenbauer, John and Chu, Hong-Min and Somepalli, Gowthami and Bartoldson, Brian R. and Kailkhura, Bhavya and Schwarzschild, Avi and Saha, Aniruddha and Goldblum, Micah and Geiping, Jonas and Goldstein, Tom , booktitle =. 2024 , url =
work page 2024
-
[35]
Valipour, Mojtaba and Rezagholizadeh, Mehdi and Kobyzev, Ivan and Ghodsi, Ali , booktitle =. 2023 , address =. doi:10.18653/v1/2023.eacl-main.239 , url =
-
[36]
Della-merging: Reducing interference in model merging through magnitude-based sampling
Deep, Pala Tej and Bhardwaj, Rishabh and Poria, Soujanya , year =. doi:10.48550/arXiv.2406.11617 , url =. 2406.11617 , archivePrefix =
-
[37]
Advances in Neural Information Processing Systems , volume =
Merging Models with Fisher-Weighted Averaging , author =. Advances in Neural Information Processing Systems , volume =. 2022 , url =
work page 2022
-
[38]
Proceedings of the 41st International Conference on Machine Learning , pages =
Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , volume =
work page 2024
-
[39]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and others , journal =. 2025 , doi =
work page 2025
-
[40]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Lambert, Nathan and Morrison, Jacob and Pyatkin, Valentina and Huang, Shengyi and Ivison, Hamish and Brahman, Faeze and Miranda, Lester James V. and Liu, Alisa and Dziri, Nouha and Lyu, Shane and Gu, Yuling and Malik, Saumya and Graf, Victoria and Hwang, Jena D. and Yang, Jiangjiang and Le Bras, Ronan and Tafjord, Oyvind and Wilhelm, Chris and Soldaini, L...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2411.15124
-
[41]
Chen, Jiaqi and Zhang, Bang and Ma, Ruotian and Wang, Peisong and Liang, Xiaodan and Tu, Zhaopeng and Li, Xiaolong and Wong, Kwan-Yee K. , booktitle =. 2025 , url =
work page 2025
-
[42]
ICLR 2026 Workshop on AI with Recursive Self-Improvement , year =
Jana, Swadesh and Sancaktar, Cansu and Dani. ICLR 2026 Workshop on AI with Recursive Self-Improvement , year =. 2603.15957 , archivePrefix =
-
[43]
Spice: Self-play in corpus environments improves reasoning.arXiv preprint arXiv:2510.24684, 2025
Liu, Bo and Jin, Chuanyang and Kim, Seungone and Yuan, Weizhe and Zhao, Wenting and Kulikov, Ilia and Li, Xian and Sukhbaatar, Sainbayar and Lanchantin, Jack and Weston, Jason , year =. doi:10.48550/arXiv.2510.24684 , url =. 2510.24684 , archivePrefix =
-
[44]
doi:10.48550/arXiv.2602.05472 , url =
Duan, Yiwen and Ye, Jing and Zhao, Xinpei , year =. doi:10.48550/arXiv.2602.05472 , url =. 2602.05472 , archivePrefix =
work page internal anchor Pith review doi:10.48550/arxiv.2602.05472
-
[45]
doi:10.48550/arXiv.2601.18292 , url =
Tan, Zhewen and Yu, Wenhan and Si, Jianfeng and Liu, Tongxin and Guan, Kaiqi and Jin, Huiyan and Tao, Jiawen and Yuan, Xiaokun and Ma, Duohe and Zhang, Xiangzheng and Yang, Tong and Sun, Lin , year =. doi:10.48550/arXiv.2601.18292 , url =. 2601.18292 , archivePrefix =
-
[46]
Language self-play for data-free training.arXiv preprint arXiv:2509.07414, 2025
Language Self-Play For Data-Free Training , author =. 2025 , eprint =. doi:10.48550/arXiv.2509.07414 , url =
-
[47]
Chowdhury, Md Tahmid Ashraf and Ullah, Fasee and Hassan, Mohd Hilmi and Bhushan, Shashi and Kamal, Shahid and Khan, Arfat Ahmad , journal =. 2026 , doi =
work page 2026
-
[48]
Teaching Models to Teach Themselves: Reasoning at the Edge of Learnability , author =. 2026 , eprint =. doi:10.48550/arXiv.2601.18778 , url =
-
[49]
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains , author =. 2025 , eprint =. doi:10.48550/arXiv.2507.17746 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.17746 2025
-
[50]
Nature Machine Intelligence , volume =
Evolutionary Optimization of Model Merging Recipes , author =. Nature Machine Intelligence , volume =. 2025 , doi =
work page 2025
-
[51]
Nature-Inspired Population-Based Evolution of Large Language Models , author =. 2025 , eprint =. doi:10.48550/arXiv.2503.01155 , url =
-
[52]
Evolution Strategies at the Hyperscale , author =. 2025 , eprint =. doi:10.48550/arXiv.2511.16652 , url =
-
[53]
Evolutionary Strategies for Scalable Alignment , author =. 2025 , eprint =. doi:10.48550/arXiv.2507.04453 , url =
-
[54]
Qiu, Xin and Gan, Yulu and Hayes, Conor F. and Liang, Qiyao and Xu, Yinggan and Dailey, Roberto and Meyerson, Elliot and Hodjat, Babak and Miikkulainen, Risto , year =. Evolution Strategies at Scale:. doi:10.48550/arXiv.2509.24372 , url =. 2509.24372 , archivePrefix =
-
[55]
Model Swarms: Collaborative Search to Adapt
Feng, Shangbin and Wang, Zifeng and Wang, Yike and Ebrahimi, Sayna and Palangi, Hamid and Miculicich, Lesly and Kulshrestha, Achin and Rauschmayr, Nathalie and Choi, Yejin and Tsvetkov, Yulia and Lee, Chen-Yu and Pfister, Tomas , booktitle =. Model Swarms: Collaborative Search to Adapt. 2025 , volume =
work page 2025
-
[56]
Heterogeneous Swarms: Jointly Optimizing Model Roles and Weights for Multi-
Feng, Shangbin and Wang, Zifeng and Goyal, Palash and Wang, Yike and Shi, Weijia and Xia, Huang and Palangi, Hamid and Zettlemoyer, Luke and Tsvetkov, Yulia and Lee, Chen-Yu and Pfister, Tomas , booktitle =. Heterogeneous Swarms: Jointly Optimizing Model Roles and Weights for Multi-. 2025 , url =
work page 2025
-
[57]
Huang, Chengsong and Liu, Qian and Lin, Bill Yuchen and Pang, Tianyu and Du, Chao and Lin, Min , year =. doi:10.48550/arXiv.2307.13269 , url =. 2307.13269 , archivePrefix =
-
[58]
Buehler, Eric L. and Buehler, Markus J. , year =. doi:10.48550/arXiv.2402.07148 , url =. 2402.07148 , archivePrefix =
-
[59]
and Tan, Qijun and Liu, Yuan , year =
Ye, Ziyu and Agarwal, Rishabh and Liu, Tianqi and Joshi, Rishabh and Velury, Sarmishta and Le, Quoc V. and Tan, Qijun and Liu, Yuan , year =. doi:10.48550/arXiv.2411.00062 , url =. 2411.00062 , archivePrefix =
-
[60]
R-Zero: Self-Evolving Reasoning LLM from Zero Data
Huang, Chengsong and Yu, Wenhao and Wang, Xiaoyang and Zhang, Hongming and Li, Zongxia and Li, Ruosen and Huang, Jiaxin and Mi, Haitao and Yu, Dong , year =. doi:10.48550/arXiv.2508.05004 , url =. 2508.05004 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.05004
-
[61]
Liu, Bo and Guertler, Leon and Yu, Simon and Liu, Zichen and Qi, Penghui and Balcells, Daniel and Liu, Mickel and Tan, Cheston and Shi, Weiyan and Lin, Min and Lee, Wee Sun and Jaques, Natasha , booktitle =. 2026 , url =
work page 2026
-
[62]
and Valentino, Marco and Minervini, Pasquale , year =
Kwan, Wai-Chung and Leang, Joshua Ong Jun and Vougiouklis, Pavlos and Pan, Jeff Z. and Valentino, Marco and Minervini, Pasquale , year =. doi:10.48550/arXiv.2511.00602 , url =. 2511.00602 , archivePrefix =
-
[63]
Proceedings of the 41st International Conference on Machine Learning , pages =
Self-Rewarding Language Models , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , volume =
work page 2024
-
[64]
rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking
Guan, Xinyu and Zhang, Li Lyna and Liu, Yifei and Shang, Ning and Sun, Youran and Zhu, Yi and Yang, Fan and Yang, Mao , year =. doi:10.48550/arXiv.2501.04519 , url =. 2501.04519 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.04519
-
[65]
Zelikman, Eric and Wu, Yuhuai and Mu, Jesse and Goodman, Noah D. , booktitle =. 2022 , url =
work page 2022
-
[66]
Proceedings of the 41st International Conference on Machine Learning , pages =
Promptbreeder: Self-Referential Self-Improvement via Prompt Evolution , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , volume =
work page 2024
-
[67]
Herbrich, Ralf and Minka, Tom and Graepel, Thore , booktitle =. 2006 , url =
work page 2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.