SWE-Doctor: Guiding Software Engineering Agents with Runtime Diagnosis from Multi-Faceted Bug Reproduction Tests
Pith reviewed 2026-07-02 08:20 UTC · model grok-4.3
The pith
SWE-Doctor improves software issue resolution by guiding patch generation with runtime diagnoses from multi-faceted bug reproduction tests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
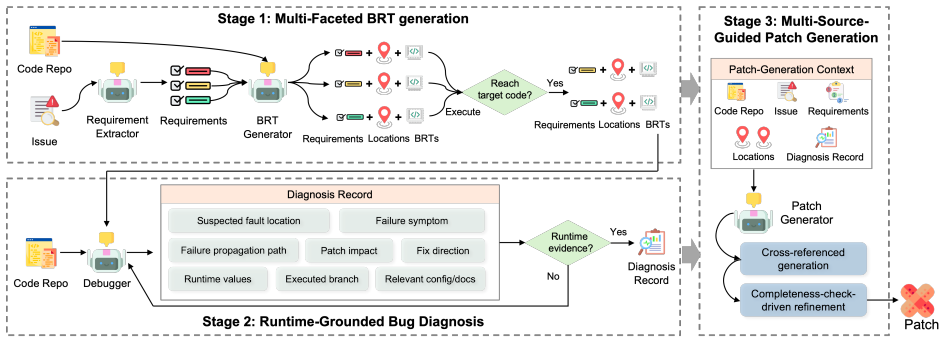
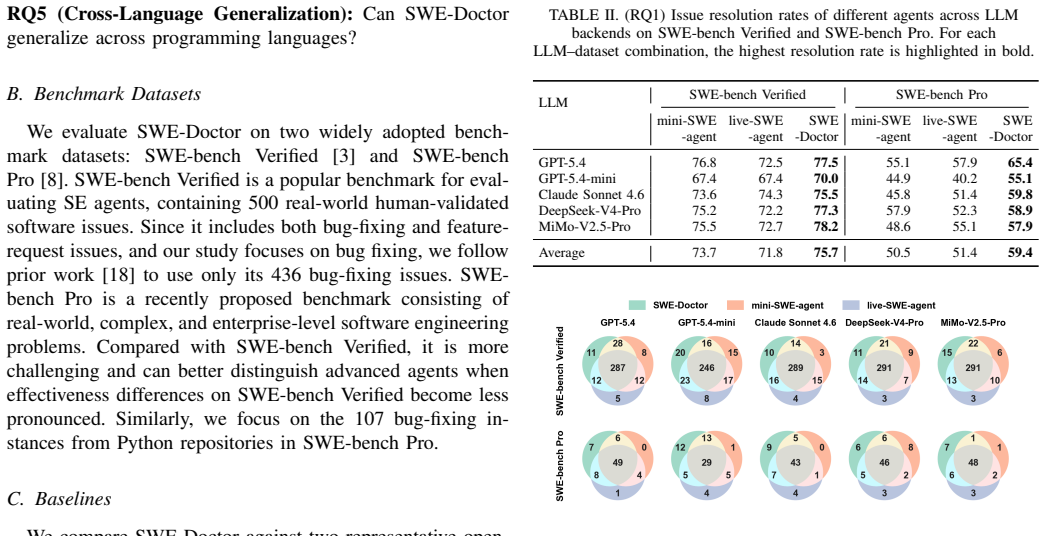
SWE-Doctor first generates multi-faceted BRTs for different behavioral requirements stated in the issue, then executes and debugs these BRTs to construct runtime-grounded diagnosis records, and finally uses the diagnoses together with localization information inferred during BRT generation to guide patch generation and reduce partial patches. It outperforms baselines across all LLM-benchmark combinations with average rates of 75.7% on SWE-bench Verified and 59.4% on SWE-bench Pro, improving the latter by 8.0-8.9 points.
What carries the argument
Runtime-grounded diagnosis records built from executing and debugging multi-faceted bug reproduction tests.
If this is right
- Outperforms existing agents on all 10 LLM-benchmark combinations tested.
- Achieves 75.7% average resolution on SWE-bench Verified and 59.4% on SWE-bench Pro.
- Improves resolution by 8.0-8.9 percentage points on the more challenging SWE-bench Pro.
- Reduces partial patches by incorporating diagnoses from multiple behavioral aspects of the issue.
Where Pith is reading between the lines
- This could allow agents to handle issues with more complex or multi-part symptoms by systematically covering behavioral requirements.
- Combining such diagnoses with other tools like static analysis might further improve localization accuracy in future agent designs.
- Applying the same multi-faceted approach to test generation in non-bug-fixing tasks like feature addition could yield similar benefits.
- The method suggests that runtime feedback can be more effective when structured as diagnostic records rather than raw test outcomes.
Load-bearing premise
Multi-faceted BRTs for different behavioral requirements will yield reliable runtime-grounded diagnosis records that reduce partial patches without adding misleading signals or gaps in coverage.
What would settle it
Observing lower resolution rates than baselines on a set of issues where the generated multi-faceted BRTs fail to cover key manifestations or produce incorrect debug information.
Figures

read the original abstract
Large language model (LLM)-based software engineering agents are increasingly developed to resolve software issues by generating patches from issue reports and code repositories. Bug reproduction tests (BRTs) are an important building block for such agents and have been shown useful for patch validation. However, it remains unclear whether BRTs can also help the more central stage of patch generation. We first conduct a preliminary study and find that directly using advanced BRT generators to guide patch generation is not beneficial: fail-to-fail BRTs can mislead agents, while even fail-to-pass BRTs bring limited or negative gains. Our analysis reveals two reasons: fail-to-pass BRTs may cover only one manifestation of the reported issue, leading to partial patches, whereas fail-to-fail BRTs are unreliable as direct patch-generation targets. Motivated by these insights, we propose SWE-Doctor, a software issue resolution agent that guides patch generation with runtime diagnoses derived from multi-faceted BRT executions. SWE-Doctor first generates multi-faceted BRTs for different behavioral requirements stated in the issue, then executes and debugs these BRTs to construct runtime-grounded diagnosis records, and finally uses the diagnoses together with localization information inferred during BRT generation to guide patch generation and reduce partial patches. We evaluate SWE-Doctor on Python bug-fixing issues from the widely adopted SWE-bench Verified and SWE-bench Pro across five LLM backends. SWE-Doctor consistently outperforms existing agents across all 10 LLM-benchmark combinations, achieving average resolution rates of 75.7% on SWE-bench Verified and 59.4% on SWE-bench Pro. In particular, on the more challenging SWE-bench Pro, SWE-Doctor improves the average resolution rate by 8.0-8.9 percentage points over the baseline agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SWE-Doctor, an LLM-based software engineering agent that addresses limitations of direct bug reproduction test (BRT) use for patch generation. A preliminary study identifies that fail-to-pass BRTs can lead to partial patches (covering only one issue manifestation) and fail-to-fail BRTs are unreliable. SWE-Doctor generates multi-faceted BRTs for different behavioral requirements in the issue, executes and debugs them to build runtime-grounded diagnosis records, and combines these with localization information to guide patch generation. Evaluation on SWE-bench Verified and SWE-bench Pro across five LLM backends shows consistent outperformance, with average resolution rates of 75.7% and 59.4%, and gains of 8.0-8.9 percentage points on the Pro benchmark over baselines.
Significance. If the results hold, the work offers a concrete way to extend BRTs from validation to the patch-generation stage in SE agents, directly targeting the partial-patch and unreliability issues identified in the preliminary study. The evaluation on two widely used external benchmarks (SWE-bench Verified and Pro) across multiple backends is a positive aspect, as is the explicit diagnosis of failure modes before proposing the solution. This could inform practical improvements in agent design for real-world bug fixing.
major comments (2)
- [§3] §3 (Method description): The central claim that runtime diagnoses from multi-faceted BRT executions reliably steer patch generation and reduce partial patches rests on the assumption that these diagnoses avoid misleading signals or coverage gaps. However, the method provides no explicit mechanism (such as cross-BRT consistency checks, coverage metrics, or oracle validation of diagnosis records) to ensure this, despite the preliminary study explicitly documenting these risks for single BRTs. This is load-bearing for the reported performance gains.
- [Evaluation / Abstract] Evaluation section and abstract: The headline results (75.7% on Verified, 59.4% on Pro, +8.0-8.9 pp on Pro across all 10 LLM-benchmark combinations) are presented as averages without reported statistical significance, variance across runs, or detailed experimental controls. This weakens the ability to assess whether the consistent outperformance is robust rather than sensitive to specific conditions.
minor comments (1)
- [Abstract] Abstract: The range '8.0-8.9 percentage points' is stated without clarifying whether it represents the minimum and maximum improvements across the five backends or a different aggregation; adding this detail would improve precision.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below with clarifications from the manuscript and indicate planned revisions.
read point-by-point responses
-
Referee: [§3] §3 (Method description): The central claim that runtime diagnoses from multi-faceted BRT executions reliably steer patch generation and reduce partial patches rests on the assumption that these diagnoses avoid misleading signals or coverage gaps. However, the method provides no explicit mechanism (such as cross-BRT consistency checks, coverage metrics, or oracle validation of diagnosis records) to ensure this, despite the preliminary study explicitly documenting these risks for single BRTs. This is load-bearing for the reported performance gains.
Authors: The preliminary study documents risks specifically for single BRTs, which directly motivated SWE-Doctor's use of multi-faceted BRTs that target distinct behavioral requirements stated in the issue. Each BRT is executed and debugged to produce runtime-grounded diagnosis records; the debugging step analyzes execution traces and failure modes to derive actionable diagnoses rather than raw pass/fail signals. These diagnoses are then combined with localization information obtained during BRT generation. We agree that §3 would benefit from more explicit discussion of how this design reduces (rather than eliminates) coverage gaps and misleading signals. We will revise the method section to elaborate on the role of multi-faceted coverage and debugging in mitigating the risks identified in the preliminary study, and we will add a brief description of an optional cross-BRT consistency step during diagnosis aggregation. revision: partial
-
Referee: [Evaluation / Abstract] Evaluation section and abstract: The headline results (75.7% on Verified, 59.4% on Pro, +8.0-8.9 pp on Pro across all 10 LLM-benchmark combinations) are presented as averages without reported statistical significance, variance across runs, or detailed experimental controls. This weakens the ability to assess whether the consistent outperformance is robust rather than sensitive to specific conditions.
Authors: The reported averages reflect performance across five distinct LLM backends on two separate benchmarks, with outperformance observed in every one of the 10 LLM-benchmark combinations. This cross-backend consistency is presented as the primary indicator of robustness. We did not report per-run variance or conduct formal significance tests, primarily because of the substantial computational cost of repeated full agent runs. We will revise the evaluation section to explicitly acknowledge this limitation, to highlight the 10/10 consistency result as supporting evidence, and to note any available seed-level data if it can be extracted from our existing logs without new experiments. revision: partial
Circularity Check
No significant circularity; empirical results on external benchmarks
full rationale
The paper conducts a preliminary study on limitations of single BRTs, proposes SWE-Doctor using multi-faceted BRTs for diagnosis-guided patching, and reports resolution rates on the external SWE-bench Verified and SWE-bench Pro benchmarks across multiple LLMs. These benchmarks are standard, independent datasets not constructed or fitted inside the paper. The headline performance figures (75.7%, 59.4%, +8–8.9 pp) are measured outcomes on those benchmarks rather than quantities derived by construction from the method. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the load-bearing steps; the reliability assumption for diagnoses is an empirical claim tested on the external data rather than a self-definitional reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption BRT generators can reliably produce tests that each target a distinct behavioral requirement stated in the issue report.
- domain assumption Runtime execution and debugging of BRTs produces diagnosis records that are more informative for patch generation than the BRTs themselves.
Reference graph
Works this paper leans on
-
[1]
SWE-agent: Agent-computer interfaces enable automated software engineering,
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press, “SWE-agent: Agent-computer interfaces enable automated software engineering,” inAdvances in Neural Information Processing Systems 37 (NeurIPS), 2024
2024
-
[2]
Demystifying LLM-based software engineering agents,
C. S. Xia, Y . Deng, S. Dunn, and L. Zhang, “Demystifying LLM-based software engineering agents,”Proceedings of the ACM on Software Engineering (PACMSE), vol. 2, no. FSE, pp. 801–824, 2025
2025
-
[3]
SWE-bench: Can language models resolve real-world GitHub issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. R. Narasimhan, “SWE-bench: Can language models resolve real-world GitHub issues?” inThe Twelfth International Conference on Learning Representations (ICLR), 2024
2024
-
[4]
Heterogeneous prompting and execution feedback for software engineering issue test generation and selection,
T. Ahmed, J. Ganhotra, A. Shinnar, and M. Hirzel, “Heterogeneous prompting and execution feedback for software engineering issue test generation and selection,” inProceedings of the 48th IEEE/ACM Inter- national Conference on Software Engineering (ICSE), 2026
2026
-
[5]
Agentic bug reproduction for effective automated program repair at google,
R. Cheng, M. Tufano, J. Cito, J. Cambronero, P. Rondon, R. Wei, A. Sun, and S. Chandra, “Agentic bug reproduction for effective automated program repair at google,”arXiv, 2025
2025
-
[6]
Issue2Test: Gen- erating reproducing test cases from issue reports,
N. Nashid, I. Bouzenia, M. Pradel, and A. Mesbah, “Issue2Test: Gen- erating reproducing test cases from issue reports,” inProceedings of the 48th IEEE/ACM International Conference on Software Engineering (ICSE), 2026, to appear
2026
-
[7]
AssertFlip: Reproducing bugs via inversion of llm-generated passing tests,
L. Khatib, N. S. Mathews, and M. Nagappan, “AssertFlip: Reproducing bugs via inversion of llm-generated passing tests,” inProceedings of the 48th IEEE/ACM International Conference on Software Engineering (ICSE), 2026
2026
-
[8]
SWE-Bench Pro: Can AI agents solve long-horizon software engineer- ing tasks?
X. Deng, J. Da, E. Pan, Y . He, C. Ide, K. Garg, N. Lauffer, A. Park, N. Pasari, C. Rane, K. Sampath, M. Krishnan, S. Kundurthy, S. M. Hendryx, Z. Wang, C. B. C. Zhang, N. Jacobson, B. Liu, and B. Kenstler, “SWE-Bench Pro: Can AI agents solve long-horizon software engineer- ing tasks?”arXiv, 2025
2025
-
[9]
Live-SWE-agent: Can software engineering agents self-evolve on the fly?
C. S. Xia, Z. Wang, Y . Yang, Y . Wei, and L. Zhang, “Live-SWE-agent: Can software engineering agents self-evolve on the fly?”arXiv, 2025
2025
-
[10]
SWE-Doctor,
“SWE-Doctor,” https://github.com/SWE-Doctor/SWE-Doctor, 2026
2026
-
[11]
Gistify! codebase-level understanding via runtime execution,
H. Lee, M. Kim, C. Singh, M. Pereira, A. Sonwane, I. White, E. Stengel- Eskin, M. Bansal, Z. Shi, A. Sordoni, M.-A. C ˆot´e, X. Yuan, and L. Cac- cia, “Gistify! codebase-level understanding via runtime execution,” in International Conference on Learning Representations (ICLR), 2026
2026
-
[12]
Swenergy: An em- pirical study on energy efficiency in agentic issue resolution frameworks with slms,
A. Tripathy, C. P. Harshit, and K. Vaidhyanathan, “Swenergy: An em- pirical study on energy efficiency in agentic issue resolution frameworks with slms,” inProceedings of the 2026 International Workshop on Agentic Engineering, 2026, pp. 104–111
2026
-
[13]
Zeller,Why Programs Fail: A Guide to Systematic Debugging, 2nd ed
A. Zeller,Why Programs Fail: A Guide to Systematic Debugging, 2nd ed. Morgan Kaufmann, 2009
2009
-
[14]
Using hypotheses as a debugging aid,
A. Alaboudi and T. D. LaToza, “Using hypotheses as a debugging aid,” inProceedings of the 2020 IEEE Symposium on Visual Languages and Human-Centric Computing (VL/HCC), 2020
2020
-
[15]
pdb — the Python debugger,
Python Software Foundation, “pdb — the Python debugger,” https://docs.python.org/3/library/pdb.html, 2024
2024
-
[16]
Klear- agentforge: Forging agentic intelligence through posttraining scaling,
Q. Wang, H. Zhang, J. Fu, K. Fu, Y . Liu, T. Zhang, C. Sun, G. Jiang, J. Tang, X. Ji, Y . Yue, J. Zhang, F. Zhang, K. Gai, and G. Zhou, “Klear- agentforge: Forging agentic intelligence through posttraining scaling,” arXiv preprint arXiv:2511.05951, 2025
-
[17]
Swe-replay: Efficient test-time scaling for software engineering agents,
Y . Ding and L. Zhang, “Swe-replay: Efficient test-time scaling for software engineering agents,”arXiv preprint arXiv:2601.22129, 2026
-
[18]
M. S. Rashid, C. Bock, Y . Zhuang, A. Buchholz, T. Esler, S. Valentin, L. Franceschi, M. Wistuba, P. T. Sivaprasad, W. J. Kimet al., “Swe- polybench: A multi-language benchmark for repository level evaluation of coding agents,”arXiv preprint arXiv:2504.08703, 2025
-
[19]
GPT-5.4 thinking system card,
OpenAI, “GPT-5.4 thinking system card,” https://openai.com/index/gpt- 5-4-thinking-system-card/, 2026, published March 5, 2026
2026
-
[20]
Introducing GPT-5.4 mini and nano,
——, “Introducing GPT-5.4 mini and nano,” https://openai.com/index/introducing-gpt-5-4-mini-and-nano/, 2026
2026
-
[21]
Claude Sonnet 4.6 system card,
Anthropic, “Claude Sonnet 4.6 system card,” https://www.anthropic.com/claude-sonnet-4-6-system-card, 2026, published February 17, 2026
2026
-
[22]
Deepseek v4 technical documentation,
DeepSeek, “Deepseek v4 technical documentation,” https://fe- static.deepseek.com/chat/transparency/deepseek-V4-model-card-EN.pdf, 2026, published April 27, 2026
2026
-
[23]
Xiaomi MiMo-V2.5-Pro,
Xiaomi, “Xiaomi MiMo-V2.5-Pro,” https://mimo.xiaomi.com/mimo-v2- 5-pro/, 2026, released April 27, 2026
2026
-
[24]
Delve: A debugger for the Go programming language,
D. Parker and The Delve Contributors, “Delve: A debugger for the Go programming language,” https://github.com/go-delve/delve, 2014
2014
-
[25]
Large language models are few-shot testers: Exploring LLM-based general bug reproduction,
S. Kang, J. Yoon, and S. Yoo, “Large language models are few-shot testers: Exploring LLM-based general bug reproduction,” inProceedings of the 45th IEEE/ACM International Conference on Software Engineer- ing (ICSE), 2023, pp. 2312–2323
2023
-
[26]
Automatic generation of test cases based on bug reports: A feasibility study with large language models,
L. Plein, W. C. Ou ´edraogo, J. Klein, and T. F. Bissyand ´e, “Automatic generation of test cases based on bug reports: A feasibility study with large language models,” inProceedings of the 46th IEEE/ACM Inter- national Conference on Software Engineering: Companion Proceedings (ICSE-Companion), 2024, pp. 360–361
2024
-
[27]
SWT-Bench: Testing and validating real-world bug-fixes with code agents,
N. M ¨undler, M. N. M ¨uller, J. He, and M. Vechev, “SWT-Bench: Testing and validating real-world bug-fixes with code agents,” inAdvances in Neural Information Processing Systems 37 (NeurIPS), 2024
2024
-
[28]
TDD-Bench verified: Can LLMs generate tests for issues before they get resolved?
T. Ahmed, M. Hirzel, R. Pan, A. Shinnar, and S. Sinha, “TDD-Bench verified: Can LLMs generate tests for issues before they get resolved?” arXiv, 2024
2024
-
[29]
Otter: Generating tests from issues to validate SWE patches,
T. Ahmed, J. Ganhotra, R. Pan, A. Shinnar, S. Sinha, and M. Hirzel, “Otter: Generating tests from issues to validate SWE patches,” in Proceedings of the 42nd International Conference on Machine Learning (ICML), vol. 267, 2025, pp. 752–771
2025
-
[30]
Eet: Experience-driven early termination for cost-efficient software engineering agents,
Y . Guo, Y . Xiao, J. M. Zhang, M. Harman, Y . Lou, Y . Liu, and Z. Chen, “Eet: Experience-driven early termination for cost-efficient software engineering agents,” inFindings of the Association for Computational Linguistics (ACL), 2026
2026
-
[31]
OpenHands: An open platform for AI software developers as generalist agents,
X. Wang, B. Li, Y . Song, F. F. Xu, X. Tang, M. Zhuge, J. Pan, Y . Song, B. Li, J. Singh, H. H. Tran, F. Li, R. Ma, M. Zheng, B. Qian, Y . Shao, N. Muennighoff, Y . Zhang, B. Hui, J. Lin, R. Brennan, H. Peng, H. Ji, and G. Neubig, “OpenHands: An open platform for AI software developers as generalist agents,” inThe Thirteenth International Conference on Le...
2025
-
[32]
AutoCodeRover: Autonomous program improvement,
Y . Zhang, H. Ruan, Z. Fan, and A. Roychoudhury, “AutoCodeRover: Autonomous program improvement,” inProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA), 2024, pp. 1592–1604
2024
-
[33]
MAGIS: LLM-based multi-agent framework for GitHub issue resolution,
W. Tao, Y . Zhou, Y . Wang, W. Zhang, H. Zhang, and Y . Cheng, “MAGIS: LLM-based multi-agent framework for GitHub issue resolution,” in Advances in Neural Information Processing Systems 37 (NeurIPS), 2024
2024
-
[34]
Diversity empowers intelligence: Integrating expertise of software engineering agents,
K. Zhang, W. Yao, Z. Liu, Y . Feng, Z. Liu, R. Murthy, T. Lan, L. Li, R. Lou, J. Xu, B. Pang, Y . Zhou, S. Heinecke, S. Savarese, H. Wang, and C. Xiong, “Diversity empowers intelligence: Integrating expertise of software engineering agents,” inThe Thirteenth International Con- ference on Learning Representations (ICLR), 2025
2025
-
[35]
Trae agent: An LLM-based agent for software engineering with test-time scaling,
P. Gao, Z. Tian, X. Meng, X. Wang, R. Hu, Y . Xiao, Y . Liu, Z. Zhang, J. Chen, C. Gao, Y . Lin, Y . Xiong, C. Peng, and X. Liu, “Trae agent: An LLM-based agent for software engineering with test-time scaling,” arXiv, 2025. 11
2025
-
[36]
CodeMonkeys: Scaling test-time compute for software engineering,
R. Ehrlich, B. Brown, J. Juravsky, R. Clark, C. R ´e, and A. Mirhoseini, “CodeMonkeys: Scaling test-time compute for software engineering,” arXiv, 2025
2025
-
[37]
S*: Test time scaling for code generation,
D. Li, S. Cao, C. Cao, X. Li, S. Tan, K. Keutzer, J. Xing, J. E. Gonzalez, and I. Stoica, “S*: Test time scaling for code generation,” inFindings of the Association for Computational Linguistics: EMNLP, 2025, pp. 15 964–15 978. 12
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.