Closing the Calibration Gap in Semantic Caching
Pith reviewed 2026-06-26 15:53 UTC · model grok-4.3
The pith
Model selection for semantic caching is a calibration problem rather than a ranking one.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The operational gap between offline and deployed quality in semantic caching decomposes into a recoverable calibration component and an irreducible structural component fixed by the dataset's positive rate; because the calibration component dominates and is governed by the training objective, model selection reduces to a calibration task rather than a ranking task.
What carries the argument
P-CHR AUC, which measures precision across cache utilization levels, and CRR, which quantifies retention of offline ranking quality at deployment, together with the decomposition of the offline-to-deployed gap into calibration and structural parts.
If this is right
- Models with the highest PR-AUC are frequently the worst performers once a fixed threshold is applied in operation.
- The size of the calibration gap depends on the training objective more than on the amount of training data.
- Post-hoc calibration recovers only part of the lost operational performance.
- Measuring the gap with cache-aware metrics is required before any attempt to close it.
Where Pith is reading between the lines
- Training objectives for embedding models used in caching should be redesigned to produce better probability estimates rather than pure ranking scores.
- Dataset construction that alters the positive rate could be used to reduce the irreducible structural component.
- The same calibration-versus-ranking distinction may apply to other threshold-based retrieval systems beyond semantic caching.
Load-bearing premise
The operational gap between offline and deployed quality can be cleanly split into a recoverable calibration component and an irreducible structural component fixed by the dataset's positive rate.
What would settle it
An experiment in which the model with the highest PR-AUC also achieves the highest deployed precision at a fixed threshold, or in which post-hoc calibration fully eliminates the observed gap on multiple datasets.
Figures
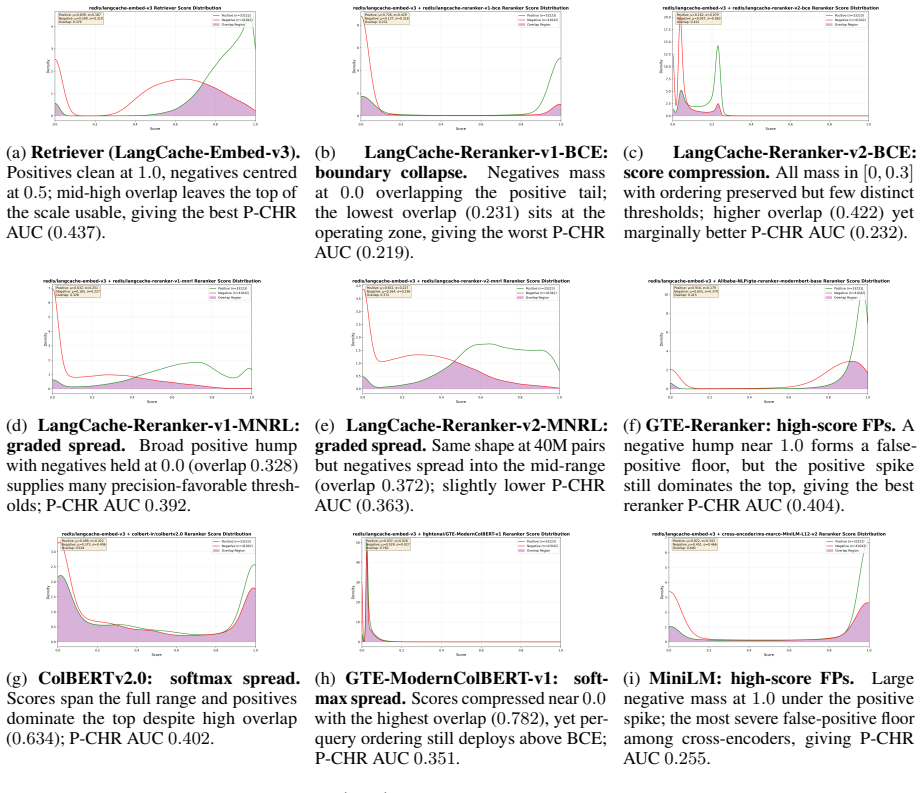
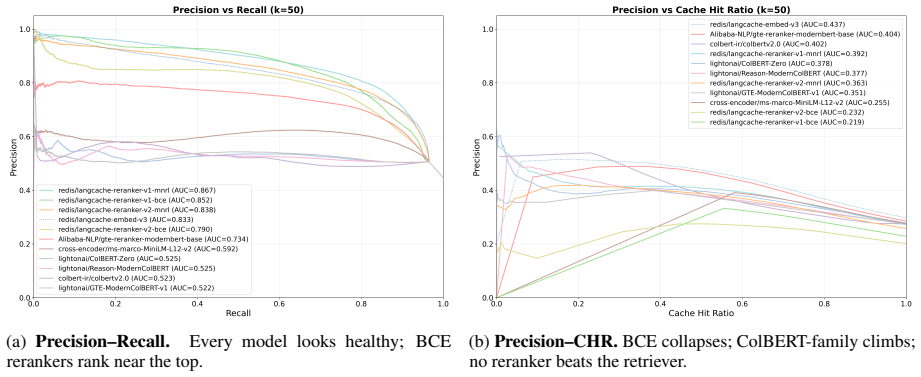
read the original abstract
Semantic caching cuts LLM inference costs by serving a cached response to semantically similar queries. Standard practice evaluates these systems using PR-AUC, a metric that only measures how well scores rank and ignores whether they are usable at a fixed threshold. We show this mismatch leads to systematically poor deployment choices, as models with the highest PR-AUC are often the worst in operation. We introduce Precision-Cache Hit Ratio (P-CHR) AUC, a cache-aware metric that measures precision across cache utilization levels, and Calibration Retention Rate (CRR), which captures how much offline ranking quality survives at deployment. We decompose the operational gap between offline and deployed quality into a recoverable calibration component and an irreducible structural component fixed by the dataset's positive rate. Our experiments show that the calibration gap is governed by the training objective rather than data scale, and post-hoc calibration only partially closes it. Ultimately, model selection for semantic caching is a calibration problem, not a ranking one, and measuring it is the first step to closing the gap.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that PR-AUC is mismatched to semantic caching deployment because it ignores fixed-threshold usability, leading to suboptimal model choices. It introduces P-CHR AUC (precision across cache utilization) and CRR (retention of offline ranking quality at deployment), decomposes the offline-deployed gap into a recoverable calibration term plus an irreducible structural term fixed by the dataset positive rate, and reports experiments showing the calibration gap is governed by training objective rather than data scale, with post-hoc calibration only partially closing it. The central conclusion is that model selection for semantic caching is a calibration problem, not a ranking one.
Significance. If the decomposition, new metrics, and experimental findings on training objectives hold with proper validation, the work would usefully shift evaluation practice in semantic caching and LLM serving from pure ranking metrics toward calibration-aware ones, addressing a practical deployment gap in cost-sensitive applications.
major comments (1)
- [Abstract] Abstract: The manuscript asserts experimental findings that 'the calibration gap is governed by the training objective rather than data scale' and that 'post-hoc calibration only partially closes it,' yet supplies no methods, datasets, models, hyperparameters, error bars, statistical tests, or verification details. This absence renders the central empirical claims unevaluable and load-bearing for the recommendation that model selection is a calibration problem.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for clearer experimental grounding in support of our central claims. The full manuscript contains the requested details in the Experiments and Results sections; we address the abstract-specific concern below and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The manuscript asserts experimental findings that 'the calibration gap is governed by the training objective rather than data scale' and that 'post-hoc calibration only partially closes it,' yet supplies no methods, datasets, models, hyperparameters, error bars, statistical tests, or verification details. This absence renders the central empirical claims unevaluable and load-bearing for the recommendation that model selection is a calibration problem.
Authors: The abstract is a concise summary; the full manuscript supplies the requested information in Section 4 (Experimental Setup) and Section 5 (Results). Section 4 details the datasets (multiple semantic similarity benchmarks with known positive rates), models (embedding models trained under different objectives), hyperparameters, and evaluation protocol. Section 5 reports results with error bars across multiple runs and includes statistical comparisons. We agree the abstract could better signal the experimental basis and will revise it to include a brief clause on the datasets, models, and training objectives compared. revision: yes
Circularity Check
No significant circularity; metrics and decomposition are definitional and empirically tested
full rationale
The paper defines P-CHR AUC and CRR as new operational metrics distinct from PR-AUC, then decomposes the offline-to-deployed gap into a calibration term (recoverable) and a structural term (fixed by positive rate). These are presented as explicit definitions and experimental findings rather than derivations that reduce by construction to fitted parameters or prior self-citations. No equations equate a 'prediction' to its own inputs, and the claim that model selection is a calibration problem rests on observable differences in training objectives versus data scale, which are externally falsifiable. The argument is self-contained against benchmarks with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AI and HPC applications on leadership computing platforms: Performance and scalability studies,
Gill, Waris and Elidrisi, Mohamed and Kalapatapu, Pallavi and Ahmed, Ammar and Anwar, Ali and Gulzar, Muhammad Ali , year=. MeanCache: User-Centric Semantic Caching for LLM Web Services , url=. doi:10.1109/ipdps64566.2025.00117 , booktitle=
-
[2]
2025 , eprint=
Advancing Semantic Caching for LLMs with Domain-Specific Embeddings and Synthetic Data , author=. 2025 , eprint=
2025
-
[3]
2025 , eprint=
Category-Aware Semantic Caching for Heterogeneous LLM Workloads , author=. 2025 , eprint=
2025
-
[4]
Proceedings of the Sixth European Workshop on Machine Learning and Systems , pages =
Singh, Asmit Kumar and Wang, Haozhe and Attaluri, Laxmi Naga Santosh and Chiam, Tak and Zhu, Weihua , title =. Proceedings of the Sixth European Workshop on Machine Learning and Systems , pages =. 2026 , isbn =. doi:10.1145/3805621.3807627 , abstract =
-
[5]
2024 , eprint=
GPT Semantic Cache: Reducing LLM Costs and Latency via Semantic Embedding Caching , author=. 2024 , eprint=
2024
-
[6]
2026 , eprint=
Semantic Caching for Low-Cost LLM Serving: From Offline Learning to Online Adaptation , author=. 2026 , eprint=
2026
-
[7]
Yan, Jianxin and Ni, Wangze and Chen, Lei and Lin, Xuemin and Cheng, Peng and Qin, Zhan and Ren, Kui , title =. Proc. VLDB Endow. , month = aug, pages =. 2025 , issue_date =. doi:10.14778/3750601.3750679 , abstract =
-
[8]
2026 , eprint=
From Exact Hits to Close Enough: Semantic Caching for LLM Embeddings , author=. 2026 , eprint=
2026
-
[9]
, booktitle=
Yinglian Xie and O'Hallaron, D. , booktitle=. Locality in search engine queries and its implications for caching , year=
-
[10]
2023 , eprint=
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers , author=. 2023 , eprint=
2023
-
[11]
Proceedings of the 12th International Conference on World Wide Web , pages =
Lempel, Ronny and Moran, Shlomo , title =. Proceedings of the 12th International Conference on World Wide Web , pages =. 2003 , isbn =. doi:10.1145/775152.775156 , abstract =
-
[12]
Markatos, E.P , title =. Comput. Commun. , month = feb, pages =. 2001 , issue_date =. doi:10.1016/S0140-3664(00)00308-X , abstract =
-
[13]
Bang, Fu. GPTC ache: An Open-Source Semantic Cache for LLM Applications Enabling Faster Answers and Cost Savings. Proceedings of the 3rd Workshop for Natural Language Processing Open Source Software (NLP-OSS 2023). 2023. doi:10.18653/v1/2023.nlposs-1.24
-
[14]
Sentence- BERT : Sentence Embeddings using S iamese BERT -Networks
Reimers, Nils and Gurevych, Iryna. Sentence- BERT : Sentence Embeddings using S iamese BERT -Networks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1410
-
[15]
URL https: //aclanthology.org/2025.acl-long.127/
Warner, Benjamin and Chaffin, Antoine and Clavi. Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.127
-
[16]
2017 , howpublished =
Iyer, Shankar and Dandekar, Nikhil and Csernai, Kornel , title =. 2017 , howpublished =
2017
-
[17]
and Brockett, Chris
Dolan, William B. and Brockett, Chris. Automatically Constructing a Corpus of Sentential Paraphrases. Proceedings of the Third International Workshop on Paraphrasing ( IWP 2005). 2005
2005
-
[18]
PAWS : Paraphrase Adversaries from Word Scrambling
Zhang, Yuan and Baldridge, Jason and He, Luheng. PAWS : Paraphrase Adversaries from Word Scrambling. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v1/N19-1131
-
[19]
S em E val-2017 Task 1: Semantic Textual Similarity Multilingual and Crosslingual Focused Evaluation
Cer, Daniel and Diab, Mona and Agirre, Eneko and Lopez-Gazpio, I \ n igo and Specia, Lucia. S em E val-2017 Task 1: Semantic Textual Similarity Multilingual and Crosslingual Focused Evaluation. Proceedings of the 11th International Workshop on Semantic Evaluation ( S em E val-2017). 2017. doi:10.18653/v1/S17-2001
-
[20]
A SICK cure for the evaluation of compositional distributional semantic models
Marelli, Marco and Menini, Stefano and Baroni, Marco and Bentivogli, Luisa and Bernardi, Raffaella and Zamparelli, Roberto. A SICK cure for the evaluation of compositional distributional semantic models. Proceedings of the Ninth International Conference on Language Resources and Evaluation ( LREC '14). 2014
2014
-
[21]
He, Yun and Wang, Zhuoer and Zhang, Yin and Huang, Ruihong and Caverlee, James. PARADE : A N ew D ataset for P araphrase I dentification R equiring C omputer S cience D omain K nowledge. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.611
-
[22]
Wieting, John and Gimpel, Kevin. P ara NMT -50 M : Pushing the Limits of Paraphrastic Sentence Embeddings with Millions of Machine Translations. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018. doi:10.18653/v1/P18-1042
-
[23]
Edward and Rudinger, Rachel and Post, Matt and Van Durme, Benjamin , title =
Hu, J. Edward and Rudinger, Rachel and Post, Matt and Van Durme, Benjamin , title =. Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence and Thirty-First Innovative Applications of Artificial Intelligence Conference and Ninth AAAI Symposium on Educational Advances in Artificial Intelligence , articleno =. 2019 , isbn =. doi:10.1609/...
-
[24]
Dense Passage Retrieval for Open-Domain Question Answering
Karpukhin, Vladimir and Oguz, Barlas and Min, Sewon and Lewis, Patrick and Wu, Ledell and Edunov, Sergey and Chen, Danqi and Yih, Wen-tau. Dense Passage Retrieval for Open-Domain Question Answering. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.550
-
[25]
The Eleventh International Conference on Learning Representations , year=
When and Why Vision-Language Models Behave like Bags-Of-Words, and What to Do About It? , author=. The Eleventh International Conference on Learning Representations , year=
-
[26]
Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
SugarCrepe: Fixing Hackable Benchmarks for Vision-Language Compositionality , author=. Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[27]
2020 , eprint=
Passage Re-ranking with BERT , author=. 2020 , eprint=
2020
-
[28]
Khattab, Omar and Zaharia, Matei , title =. Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2020 , isbn =. doi:10.1145/3397271.3401075 , abstract =
-
[29]
C ol BERT v2: Effective and Efficient Retrieval via Lightweight Late Interaction
Santhanam, Keshav and Khattab, Omar and Saad-Falcon, Jon and Potts, Christopher and Zaharia, Matei. C ol BERT v2: Effective and Efficient Retrieval via Lightweight Late Interaction. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2022. doi:10.18653/v1/2022.naac...
-
[30]
2023 , eprint=
Towards General Text Embeddings with Multi-stage Contrastive Learning , author=. 2023 , eprint=
2023
-
[31]
Is CLIP Ideal? No
Kang, Raphi and Song, Yue and Gkioxari, Gerogia and Perona, Pietro , booktitle=. Is CLIP Ideal? No. Can We Fix It? Yes! , year=
-
[32]
Companion Proceedings of the ACM Web Conference 2024 , pages =
Steck, Harald and Ekanadham, Chaitanya and Kallus, Nathan , title =. Companion Proceedings of the ACM Web Conference 2024 , pages =. 2024 , isbn =. doi:10.1145/3589335.3651526 , abstract =
-
[33]
Ethayarajh, Kawin. How Contextual are Contextualized Word Representations? C omparing the Geometry of BERT , ELM o, and GPT -2 Embeddings. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1006
-
[34]
Zhang, Xin and Zhang, Yanzhao and Long, Dingkun and Xie, Wen and Dai, Ziqi and Tang, Jialong and Lin, Huan and Yang, Baosong and Xie, Pengjun and Huang, Fei and Zhang, Meishan and Li, Wenjie and Zhang, Min. mGTE : Generalized Long-Context Text Representation and Reranking Models for Multilingual Text Retrieval. Proceedings of the 2024 Conference on Empiri...
-
[35]
Billion-Scale Similarity Search with GPUs , year=
Johnson, Jeff and Douze, Matthijs and Jégou, Hervé , journal=. Billion-Scale Similarity Search with GPUs , year=
-
[36]
Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom
Malkov, Yu A. and Yashunin, D. A. , title =. IEEE Trans. Pattern Anal. Mach. Intell. , month = apr, pages =. 2020 , issue_date =. doi:10.1109/TPAMI.2018.2889473 , abstract =
-
[37]
and Kim, Yoon and Ghassemi, Marzyeh , booktitle=
Alhamoud, Kumail and Alshammari, Shaden and Tian, Yonglong and Li, Guohao and Torr, Philip H.S. and Kim, Yoon and Ghassemi, Marzyeh , booktitle=. Vision-Language Models Do Not Understand Negation , year=
-
[38]
, title =
Guo, Chuan and Pleiss, Geoff and Sun, Yu and Weinberger, Kilian Q. , title =. Proceedings of the 34th International Conference on Machine Learning - Volume 70 , pages =. 2017 , publisher =
2017
-
[39]
S em E val-2015 Task 1: Paraphrase and Semantic Similarity in T witter ( PIT )
Xu, Wei and Callison-Burch, Chris and Dolan, Bill. S em E val-2015 Task 1: Paraphrase and Semantic Similarity in T witter ( PIT ). Proceedings of the 9th International Workshop on Semantic Evaluation ( S em E val 2015). 2015. doi:10.18653/v1/S15-2001
-
[40]
Improving Paraphrase Detection with the Adversarial Paraphrasing Task
Nighojkar, Animesh and Licato, John. Improving Paraphrase Detection with the Adversarial Paraphrasing Task. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021. doi:10.18653/v1/2021.acl-long.552
-
[41]
Open Subtitles Paraphrase Corpus for Six Languages
Creutz, Mathias. Open Subtitles Paraphrase Corpus for Six Languages. Proceedings of the Eleventh International Conference on Language Resources and Evaluation ( LREC 2018). 2018
2018
-
[42]
T a P a C o: A Corpus of Sentential Paraphrases for 73 Languages
Scherrer, Yves. T a P a C o: A Corpus of Sentential Paraphrases for 73 Languages. Proceedings of the Twelfth Language Resources and Evaluation Conference. 2020
2020
-
[43]
Super- N atural I nstructions: Generalization via Declarative Instructions on 1600+ NLP Tasks
Wang, Yizhong and Mishra, Swaroop and Alipoormolabashi, Pegah and Kordi, Yeganeh and Mirzaei, Amirreza and Naik, Atharva and Ashok, Arjun and Dhanasekaran, Arut Selvan and Arunkumar, Anjana and Stap, David and Pathak, Eshaan and Karamanolakis, Giannis and Lai, Haizhi and Purohit, Ishan and Mondal, Ishani and Anderson, Jacob and Kuznia, Kirby and Doshi, Kr...
-
[44]
2020 , howpublished =
Davis Yoshida and Kevin Gimpel , title =. 2020 , howpublished =
2020
-
[45]
2023 , howpublished =
Vladimir Vorobev and Maxim Kuznetsov , title =. 2023 , howpublished =
2023
-
[46]
Edward and Singh, Abhinav and Holzenberger, Nils and Post, Matt and Van Durme, Benjamin
Hu, J. Edward and Singh, Abhinav and Holzenberger, Nils and Post, Matt and Van Durme, Benjamin. Large-Scale, Diverse, Paraphrastic Bitexts via Sampling and Clustering. Proceedings of the 23rd Conference on Computational Natural Language Learning (CoNLL). 2019. doi:10.18653/v1/K19-1005
-
[47]
2023 , howpublished =
Xu, Weijie , title =. 2023 , howpublished =
2023
-
[48]
, biburl =
Platt, John C. , biburl =. Probabilistic Outputs for Support Vector Machines and Comparisons to Regularized Likelihood Methods , username =. Advances in Large Margin Classifiers , citeseerurl =
-
[49]
Schroedinger ' s Threshold: When the AUC Doesn ' t Predict Accuracy
Opitz, Juri. Schroedinger ' s Threshold: When the AUC Doesn ' t Predict Accuracy. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 2024
2024
-
[50]
The Fourteenth International Conference on Learning Representations , year=
vCache: Verified Semantic Prompt Caching , author=. The Fourteenth International Conference on Learning Representations , year=
-
[51]
Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =
Wang, Wenhui and Wei, Furu and Dong, Li and Bao, Hangbo and Yang, Nan and Zhou, Ming , title =. Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =. 2020 , isbn =
2020
-
[52]
ArcFace: Additive Angular Margin Loss for Deep Face Recognition , year=
Deng, Jiankang and Guo, Jia and Xue, Niannan and Zafeiriou, Stefanos , booktitle=. ArcFace: Additive Angular Margin Loss for Deep Face Recognition , year=
-
[53]
Xiao, Shitao and Liu, Zheng and Zhang, Peitian and Muennighoff, Niklas and Lian, Defu and Nie, Jian-Yun , title =. Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2024 , isbn =. doi:10.1145/3626772.3657878 , abstract =
-
[54]
2024 , eprint=
Text Embeddings by Weakly-Supervised Contrastive Pre-training , author=. 2024 , eprint=
2024
-
[55]
2024 , eprint=
Jina Embeddings 2: 8192-Token General-Purpose Text Embeddings for Long Documents , author=. 2024 , eprint=
2024
-
[56]
Transactions on Machine Learning Research , issn=
Nomic Embed: Training a Reproducible Long Context Text Embedder , author=. Transactions on Machine Learning Research , issn=. 2025 , url=
2025
-
[57]
Second Conference on Language Modeling , year=
Arctic-Embed 2.0: Multilingual Retrieval Without Compromise , author=. Second Conference on Language Modeling , year=
-
[58]
2025 , howpublished =
Chaffin, Antoine , title =. 2025 , howpublished =
2025
-
[59]
2026 , eprint=
ColBERT-Zero: To Pre-train Or Not To Pre-train ColBERT models , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.