FastPano3D: Feed-Forward Indoor Panoramic 3D Reconstruction from a Single Image
Pith reviewed 2026-06-30 06:24 UTC · model grok-4.3
The pith
A single panoramic image can produce a renderable 3D Gaussian scene model in seconds using only feed-forward processing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
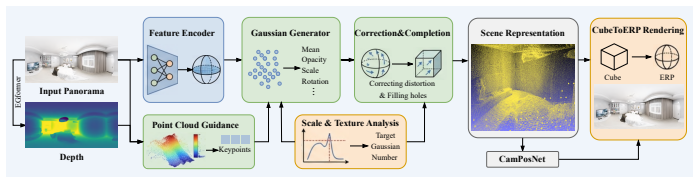
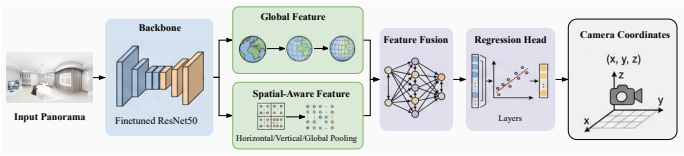
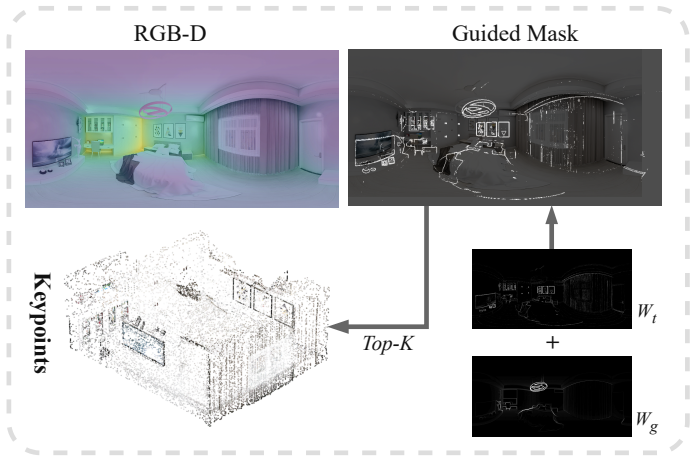
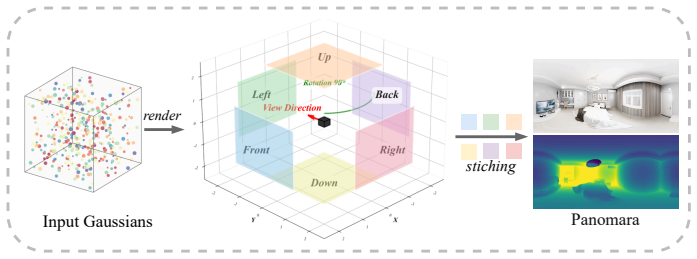
FastPano3D directly generates renderable 3D Gaussian representations from a single panoramic image by means of a lightweight feature encoder, adaptive Gaussian sampling, and a point-cloud-guided refinement strategy, achieving high-fidelity indoor scene reconstruction without test-time optimization.
What carries the argument
Lightweight feature encoder with adaptive Gaussian sampling and point-cloud-guided refinement that produces 3D Gaussians directly from one equirectangular image.
If this is right
- Indoor 3D models become available from ordinary single-shot panoramic captures without extra views or computation at inference.
- Deployment on resource-limited devices becomes practical because model size and run time are both reduced.
- Real-time or near-real-time 3D scene generation from live panoramic video feeds becomes feasible.
- Training data requirements for 3D reconstruction drop because only single panoramic images are needed at inference.
Where Pith is reading between the lines
- The same compensation strategy might allow feed-forward reconstruction from other wide-field or distorted sensors such as fisheye cameras.
- If the adaptive sampling proves robust, similar single-image pipelines could be tested on outdoor or dynamic scenes where multi-view capture is costly.
- The absence of test-time optimization opens the possibility of embedding the model inside graphics pipelines that expect immediate 3D output.
Load-bearing premise
The distortions and spatially varying feature densities of panoramic images can be corrected well enough by the lightweight encoder and adaptive sampling so that no multi-view data or scene-specific optimization is required.
What would settle it
Run the model on a panoramic image whose equirectangular distortion is artificially increased beyond the training distribution and measure whether rendering quality collapses relative to a multi-view baseline on the same scene.
Figures





read the original abstract
Recent advances in 3D scene reconstruction have highlighted the intricate trade-offs among rendering quality, inference efficiency, and data dependency. To address the challenge of rapidly reconstructing detailed 3D indoor scenes from minimal input, we introduce FastPano3D, an end-to-end framework that directly generates renderable 3D Gaussian representations from a single panoramic image. Unlike perspective-based methods, panoramic images inherently suffer from equirectangular projection distortions and spatially non-uniform feature distributions, making direct feed-forward Gaussian generation particularly challenging. In contrast to existing Gaussian Splatting based methods that rely on multi-view supervision or per-scene optimization, FastPano3D employs a lightweight feature encoder, adaptive Gaussian sampling, and a point-cloud-guided refinement strategy to achieve efficient and accurate scene generation without any test-time optimization. Our approach reconstructs high-fidelity 3D scenes within seconds, achieving up to 156 times faster inference than prior state-of-the-art methods such as Pano2Room, while using only half the parameters. Extensive experiments demonstrate that FastPano3D delivers rendering quality comparable to NeRF- and 3DGS-based reconstructions, establishing a new benchmark for rapid, single-view 3D scene inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FastPano3D, an end-to-end feed-forward framework that generates renderable 3D Gaussian representations directly from a single equirectangular panoramic image for indoor scenes. It employs a lightweight feature encoder, adaptive Gaussian sampling, and point-cloud-guided refinement to handle projection distortions and non-uniform features without multi-view supervision or test-time optimization, claiming up to 156x faster inference than Pano2Room (with half the parameters) and rendering quality comparable to NeRF- and 3DGS-based methods.
Significance. If the quantitative claims hold, the work would be significant for enabling practical, rapid single-view panoramic 3D reconstruction, substantially improving inference speed over optimization-heavy baselines while maintaining competitive fidelity. This could support real-time applications in AR/VR and robotics; the engineering focus on panoramic-specific challenges via adaptive sampling represents a useful incremental advance.
minor comments (2)
- [Abstract] Abstract: the claim of 'extensive experiments' and specific performance numbers (156x speedup, half the parameters, comparable quality) is stated without any supporting metrics, dataset names, error bars, or ablation results in the provided text; this weakens immediate verifiability of the central performance claims even though the method description itself is internally consistent.
- [Method (inferred from abstract)] The description of the adaptive Gaussian sampling strategy would benefit from an explicit equation or pseudocode showing how sampling density is adjusted for equirectangular distortion; without it, the compensation mechanism remains somewhat opaque.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work and the recommendation of minor revision. The provided referee report contains no specific major comments to address.
Circularity Check
No significant circularity in derivation chain
full rationale
The manuscript describes an end-to-end neural architecture (lightweight encoder + adaptive sampling + refinement) whose performance claims rest on empirical benchmarks rather than any closed-form derivation or self-referential definition. No equations appear that equate a claimed output to a fitted input by construction, and no load-bearing self-citations or uniqueness theorems are invoked. The central engineering claim therefore remains independent of its own fitted parameters.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A single panoramic image contains sufficient geometric information for high-fidelity 3D reconstruction when processed by the described encoder and sampler.
Reference graph
Works this paper leans on
-
[1]
Mildenhall, P
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, R. Ng, NeRF: Representing scenes as neural radiance fields for view synthesis, in: Eur. Conf. Comput. Vis., 2020, pp. 405–421
2020
-
[2]
Kerbl, G
B. Kerbl, G. Kopanas, T. Leimkühler, G. Drettakis, 3D Gaussian splatting for real-time radiance field rendering, ACM Trans. Graph. 42 (4) (2023) 1–14. 17
2023
- [3]
-
[4]
P. Guo, Y . Zhao, J. Hu, Pano2room: Novel view synthesis from a single indoor panorama, in: SIGGRAPH Asia 2024 Conference Papers, 2024, pp. 1–12
2024
-
[5]
Szymanowicz, C
S. Szymanowicz, C. Rupprecht, A. Vedaldi, Splatter image: Ultra-fast single- view 3D reconstruction, in: IEEE Conf. Comput. Vis. Pattern Recog., 2024, pp. 10208–10217
2024
-
[6]
Charatan, S
D. Charatan, S. L. Li, A. Tagliasacchi, V . Sitzmann, pixelSplat: 3D Gaussian splats from image pairs for scalable generalizable 3D reconstruction, in: IEEE Conf. Comput. Vis. Pattern Recog., 2024, pp. 19457–19467
2024
-
[7]
Tatarchenko, A
M. Tatarchenko, A. Dosovitskiy, T. Brox, Multi-view 3D models from single images with a convolutional network, in: Eur. Conf. Comput. Vis., 2016, pp. 322–337
2016
-
[8]
H. Xie, H. Yao, X. Sun, S. Zhou, S. Zhang, Pix2vox: Context-aware 3D recon- struction from single and multi-view images, in: Int. Conf. Comput. Vis., 2019, pp. 2690–2698
2019
-
[9]
Wiles, G
O. Wiles, G. Gkioxari, R. Szeliski, J. Johnson, SynSin: End-to-end view synthesis from a single image, in: IEEE Conf. Comput. Vis. Pattern Recog., 2020, pp. 7467–7477
2020
-
[10]
Ranftl, K
R. Ranftl, K. Lasinger, D. Hafner, K. Schindler, V . Koltun, Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset trans- fer, IEEE Trans. Pattern Anal. Mach. Intell. 44 (3) (2022) 1623–1637
2022
-
[11]
Ranftl, A
R. Ranftl, A. Bochkovskiy, V . Koltun, Vision transformers for dense prediction, in: Int. Conf. Comput. Vis., 2021, pp. 12179–12188
2021
-
[12]
Godard, O
C. Godard, O. Mac Aodha, G. J. Brostow, Unsupervised monocular depth esti- mation with left-right consistency, in: IEEE Conf. Comput. Vis. Pattern Recog., 2017, pp. 270–279
2017
-
[13]
Godard, O
C. Godard, O. Mac Aodha, M. Firman, G. J. Brostow, Digging into self- supervised monocular depth estimation, in: Int. Conf. Comput. Vis., 2019, pp. 3828–3838
2019
-
[14]
Z. Chen, C. Wang, Y .-C. Guo, S.-H. Zhang, StructNeRF: Neural radiance fields for indoor scenes with structural hints, IEEE Trans. Pattern Anal. Mach. Intell. 45 (12) (2023) 15694–15705.doi:10.1109/TPAMI.2023.3305295
-
[15]
C. Zhao, X. Huang, K. Yang, X. Wang, Q. Wang, Generalizable 3D Gaussian splatting for novel view synthesis, Pattern Recognition 161 (2025) 111271.doi: 10.1016/j.patcog.2024.111271
-
[16]
J. Xu, B. Stenger, T. Kerola, T. Tung, Pano2CAD: Room layout from a single panorama image (2016).arXiv:1609.09270. 18
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[17]
C. Zou, A. Colburn, Q. Shan, D. Hoiem, LayoutNet: Reconstructing the 3D room layout from a single RGB image, in: IEEE Conf. Comput. Vis. Pattern Recog., 2018, pp. 2051–2059
2018
-
[18]
Sun, C.-W
C. Sun, C.-W. Hsiao, M. Sun, H.-T. Chen, HorizonNet: Learning room layout with 1D representation and pano stretch data augmentation, in: IEEE Conf. Com- put. Vis. Pattern Recog., 2019, pp. 1047–1056
2019
-
[19]
Zhang, S
Y . Zhang, S. Song, P. Tan, J. Xiao, PanoContext: A whole-room 3D context model for panoramic scene understanding, in: Eur. Conf. Comput. Vis., 2014, pp. 668–686
2014
-
[20]
Wang, Y .-H
F.-E. Wang, Y .-H. Yeh, M. Sun, W.-C. Chiu, Y .-H. Tsai, BiFuse: Monocular 360 depth estimation via bi-projection fusion, in: IEEE Conf. Comput. Vis. Pattern Recog., 2020, pp. 459–468
2020
-
[21]
Zioulis, A
N. Zioulis, A. Karakottas, D. Zarpalas, P. Daras, OmniDepth: Dense depth esti- mation for indoors spherical panoramas, in: Eur. Conf. Comput. Vis., 2018, pp. 448–465
2018
-
[22]
G. Wang, P. Wang, Z. Chen, W. Wang, C. C. Loy, Z. Liu, PERF: Panoramic neural radiance field from a single panorama, IEEE Trans. Pattern Anal. Mach. Intell. 46 (10) (2024) 6905–6918.doi:10.1109/TPAMI.2024.3387307
- [23]
- [24]
- [25]
- [26]
- [27]
-
[28]
Y . Ma, D. Zhan, Z. Jin, FastScene: Text-driven fast 3D indoor scene generation via panoramic Gaussian splatting, in: Proc. Thirty-Third Int. Joint Conf. Artificial Intelligence (IJCAI-24), 2024, pp. 1173–1181.doi:10.24963/ijcai.2024/ 130
- [29]
- [30]
-
[31]
I. Yun, C. Shin, H. Lee, H.-J. Lee, C. E. Rhee, EGformer: Equirectangular geometry-biased transformer for 360 depth estimation, in: Int. Conf. Comput. Vis., 2023, pp. 3738–3748
2023
-
[32]
Zheng, J
J. Zheng, J. Zhang, J. Li, R. Tang, S. Gao, Z. Zhou, Structured3D: A large photo- realistic dataset for structured 3D modeling, in: Eur. Conf. Comput. Vis., 2020, pp. 519–535
2020
-
[33]
K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in: IEEE Conf. Comput. Vis. Pattern Recog., 2016, pp. 770–778
2016
-
[34]
J. L. Schönberger, J.-M. Frahm, Structure-from-motion revisited, in: IEEE Conf. Comput. Vis. Pattern Recog., 2016, pp. 4104–4113
2016
- [35]
-
[36]
The Replica Dataset: A Digital Replica of Indoor Spaces
J. Straub, T. Whelan, L. Ma, et al., The Replica dataset: A digital replica of indoor spaces (2019).arXiv:1906.05797
work page internal anchor Pith review Pith/arXiv arXiv 2019
- [37]
- [38]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.