Parallel Tempering Initial Sampling in Inference-Time Reward Alignment
Pith reviewed 2026-06-28 23:26 UTC · model grok-4.3
The pith
PATHS applies parallel tempering across reward-tempered chains to reach rare high-reward regions that standard priors miss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
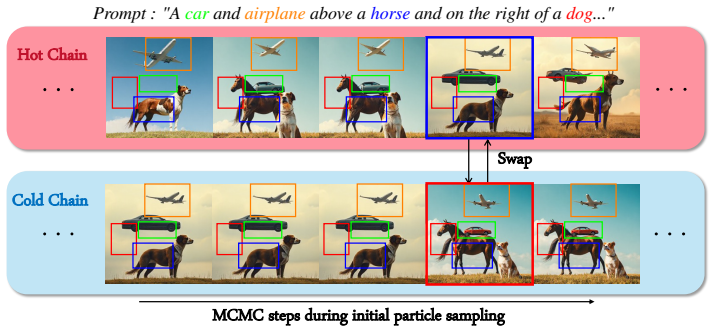
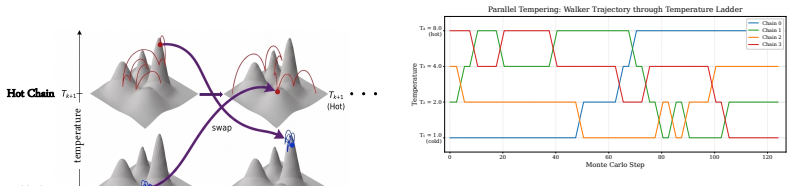
PATHS maintains a ladder of reward-tempered chains and periodically performs Metropolis swaps, enabling efficient exploration across flattened reward landscapes, thereby mitigating the mode-trapping issues. Our analysis reveals that this mechanism substantially enhances the finite-budget exploration of rare, high-reward regions that are typically challenging to sample.
What carries the argument
A ladder of reward-tempered sampling chains coupled by periodic Metropolis swaps.
Load-bearing premise
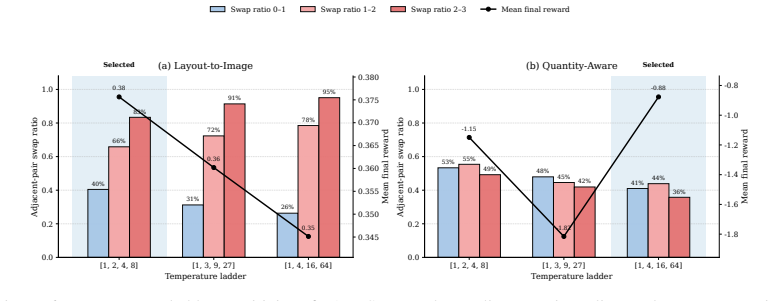
That the reward landscapes arising in layout-to-image and quantity-aware tasks are sufficiently multi-modal for parallel tempering swaps to provide meaningful exploration gains within practical computational budgets, and that the tempered chains remain stable enough to avoid introducing new failure modes.
What would settle it
An experiment on the same tasks and prompts showing that alignment quality does not improve when Metropolis swaps are disabled or when a single untempered chain is used instead of the ladder.
Figures



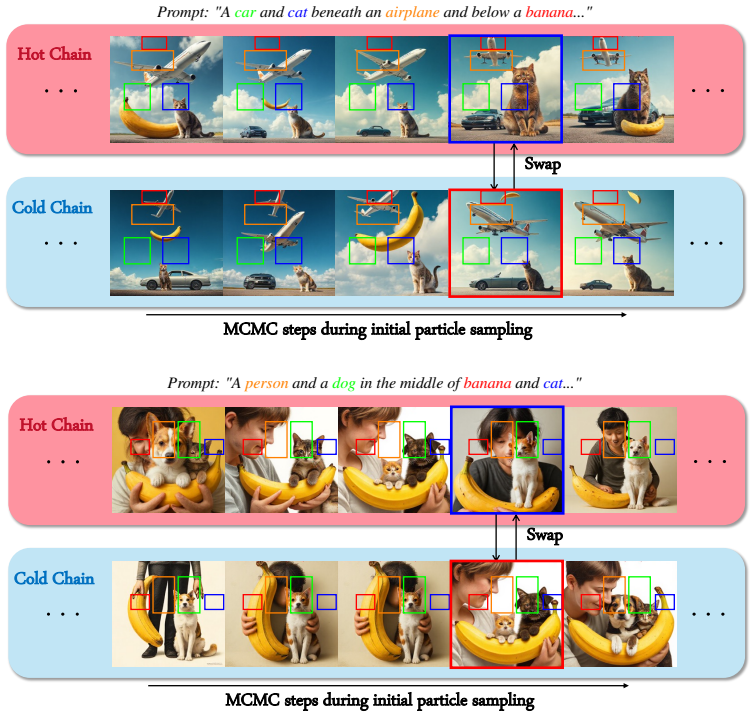
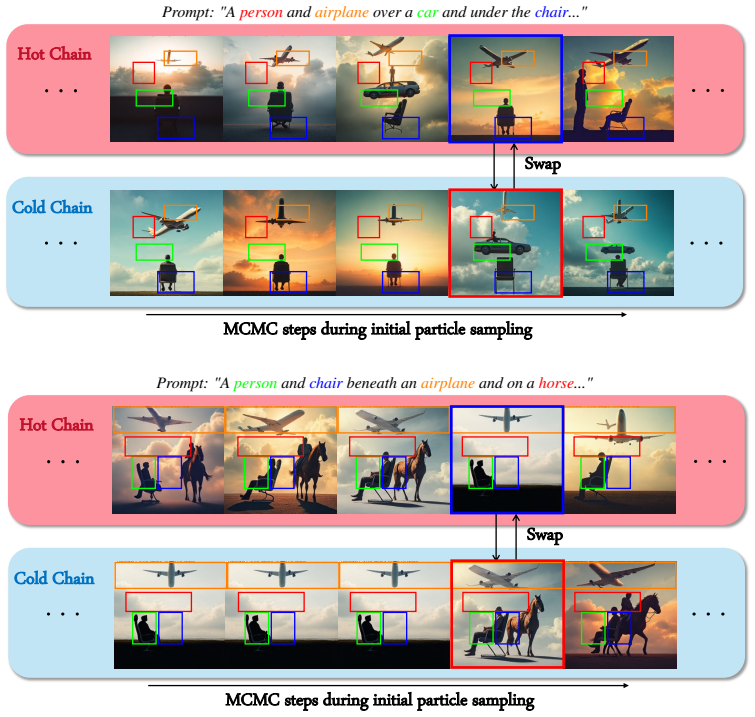


read the original abstract
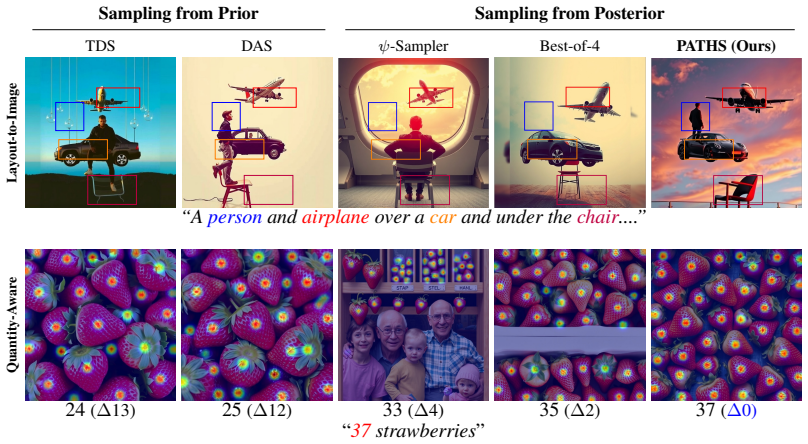
Inference-time reward alignment steers pretrained diffusion and flow-based generative models to satisfy user-specified rewards without retraining. Recently, Sequential Monte Carlo (SMC) has emerged as a powerful framework for this task by iteratively filtering and propagating multiple particles. However, we show that standard SMC-based methods often suffer from poor performance because they initialize particles from a standard prior, whereas high-reward regions in complex reward landscapes are extremely rare. Further, we show that even recent reward-aware initial sampling approaches remain vulnerable to getting trapped in local modes, as complex reward landscapes are often multi-modal. To overcome these limitations, we propose PATHS (PArallel Tempering for High-complexity reward Sampling), a novel initialization method that couples multiple sampling chains through parallel tempering. PATHS maintains a ladder of reward-tempered chains and periodically performs Metropolis swaps, enabling efficient exploration across flattened reward landscapes, thereby mitigating the mode-trapping issues. Our analysis reveals that this mechanism substantially enhances the finite-budget exploration of rare, high-reward regions that are typically challenging to sample. Experiments on layout-to-image and quantity-aware generation show that PATHS achieves consistent gains in alignment quality, particularly on complex prompts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PATHS (PArallel Tempering for High-complexity reward Sampling), an initialization method for Sequential Monte Carlo (SMC) in inference-time reward alignment of pretrained diffusion and flow models. It argues that initializing from the standard prior leads to poor performance because high-reward regions are rare in complex landscapes, and that even recent reward-aware initial sampling remains vulnerable to local mode trapping due to multi-modality. PATHS couples multiple chains via a ladder of reward-tempered distributions with periodic Metropolis swaps to improve exploration of rare high-reward regions. Experiments on layout-to-image and quantity-aware generation tasks report consistent gains in alignment quality.
Significance. If the empirical gains hold under scrutiny, the approach could meaningfully improve finite-budget exploration in SMC-based reward alignment for multi-modal reward landscapes, addressing a practical limitation in current inference-time methods.
minor comments (2)
- The abstract references 'our analysis' of the mechanism but provides no equations, pseudocode, or derivation details; the full manuscript should include a precise description of the tempering schedule, swap acceptance criterion, and how the ladder interacts with the SMC particle filter.
- No quantitative results, ablation studies, or baseline comparisons are visible in the provided abstract; the manuscript must report specific metrics, variance across runs, and controls for computational budget to substantiate the 'consistent gains' claim.
Simulated Author's Rebuttal
We thank the referee for their summary of our work on PATHS. The report lists no specific major comments, so we have no individual points to address. We remain available to provide further details, experiments, or clarifications should any concerns arise in a subsequent round.
Circularity Check
No significant circularity; new algorithmic proposal without load-bearing derivations
full rationale
The paper introduces PATHS as a novel initialization procedure coupling sampling chains via parallel tempering and Metropolis swaps for SMC-based reward alignment. The provided abstract and description contain no equations, fitted parameters, self-citations of uniqueness theorems, or ansatzes that reduce any claimed result to its own inputs by construction. The central claim is an empirical algorithmic enhancement whose validity rests on experimental testing rather than any self-referential derivation. This matches the default expectation of no circularity for method-proposal papers without mathematical reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Complex reward landscapes in the target tasks are often multi-modal, causing standard and recent initial sampling methods to become trapped in local modes.
Reference graph
Works this paper leans on
-
[1]
A noise is worth diffusion guidance
Donghoon Ahn, Jiwon Kang, Sanghyun Lee, Jaewon Min, Minjae Kim, Wooseok Jang, Hyoung- won Cho, Sayak Paul, SeonHwa Kim, Eunju Cha, et al. A noise is worth diffusion guidance. arXiv preprint arXiv:2412.03895, 2024
-
[2]
Stochastic interpolants: A unifying framework for flows and diffusions.Journal of Machine Learning Research, 26(209): 1–80, 2025
Michael Albergo, Nicholas M Boffi, and Eric Vanden-Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions.Journal of Machine Learning Research, 26(209): 1–80, 2025
2025
-
[3]
Universal guidance for diffusion models
Arpit Bansal, Hong-Min Chu, Avi Schwarzschild, Soumyadip Sengupta, Micah Goldblum, Jonas Geiping, and Tom Goldstein. Universal guidance for diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 843–852, 2023
2023
-
[4]
Training diffusion models with reinforcement learning
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforcement learning. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=YCWjhGrJFD
2024
-
[5]
Flux.1: High-quality image generation model, 2024
Black Forest Labs. Flux.1: High-quality image generation model, 2024. https://blackforestlabs.ai/
2024
-
[6]
The sample size required in importance sampling.The Annals of Applied Probability, 28(2):1099–1135, 2018
Sourav Chatterjee and Persi Diaconis. The sample size required in importance sampling.The Annals of Applied Probability, 28(2):1099–1135, 2018
2018
-
[7]
Diffusion posterior sampling for general noisy inverse problems.ICLR, 2023
Hyungjin Chung, Jeongsol Kim, Michael T Mccann, Marc L Klasky, and Jong Chul Ye. Diffusion posterior sampling for general noisy inverse problems.ICLR, 2023
2023
-
[8]
Kevin Clark, Paul Vicol, Kevin Swersky, and David J. Fleet. Directly fine-tuning diffusion models on differentiable rewards. InThe Twelfth International Conference on Learning Repre- sentations, 2024. URLhttps://openreview.net/forum?id=1vmSEVL19f
2024
-
[9]
Mcmc methods for functions: modifying old algorithms to make them faster.Statistical Science, 28(3):424–446, 2013
Simon L Cotter, Gareth O Roberts, Andrew M Stuart, and David White. Mcmc methods for functions: modifying old algorithms to make them faster.Statistical Science, 28(3):424–446, 2013
2013
-
[10]
Diffusion models beat gans on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. In NeurIPS, 2021
2021
-
[11]
Parallel tempering: Theory, applications, and new perspec- tives.Physical Chemistry Chemical Physics, 7(23):3910–3916, 2005
David J Earl and Michael W Deem. Parallel tempering: Theory, applications, and new perspec- tives.Physical Chemistry Chemical Physics, 7(23):3910–3916, 2005
2005
-
[12]
Tweedie’s formula and selection bias.Journal of the American Statistical Association, 106(496):1602–1614, 2011
Bradley Efron. Tweedie’s formula and selection bias.Journal of the American Statistical Association, 106(496):1602–1614, 2011
2011
-
[13]
Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models.Advances in Neural Information Processing Systems, 36:79858–79885, 2023
Ying Fan, Olivia Watkins, Yuqing Du, Hao Liu, Moonkyung Ryu, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, Kangwook Lee, and Kimin Lee. Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models.Advances in Neural Information Processing Systems, 36:79858–79885, 2023
2023
-
[14]
Layoutgpt: Compositional visual planning and generation with large language models
Weixi Feng et al. Layoutgpt: Compositional visual planning and generation with large language models. InNeurIPS, 2024
2024
-
[15]
Scaling laws for reward model overoptimization
Leo Gao, John Schulman, and Jacob Hilton. Scaling laws for reward model overoptimization. InInternational Conference on Machine Learning, pages 10835–10866. PMLR, 2023
2023
-
[16]
Markov chain monte carlo maximum likelihood.Computing Science and Statistics, 1991
Charles J Geyer. Markov chain monte carlo maximum likelihood.Computing Science and Statistics, 1991
1991
-
[17]
Crepe: Controlling diffusion with replica exchange
Jiajun He, Paul Jeha, Peter Potaptchik, Leo Zhang, José Miguel Hernández-Lobato, Yuanqi Du, Saifuddin Syed, and Francisco Vargas. Crepe: Controlling diffusion with replica exchange. arXiv preprint arXiv:2509.23265, 2025
-
[18]
Zico Kolter, Ruslan Salakhutdinov, and Stefano Ermon
Yutong He, Naoki Murata, Chieh-Hsin Lai, Yuhta Takida, Toshimitsu Uesaka, Dongjun Kim, Wei-Hsiang Liao, Yuki Mitsufuji, J Zico Kolter, Ruslan Salakhutdinov, et al. Manifold preserv- ing guided diffusion.arXiv preprint arXiv:2311.16424, 2023. 10
-
[19]
Denoising diffusion probabilistic models.NeurIPS, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.NeurIPS, 2020
2020
-
[20]
Salience detr: Enhancing detection transformer with hierarchical salience filtering refinement
Xiuquan Hou, Meiqin Liu, Senlin Zhang, Ping Wei, and Badong Chen. Salience detr: Enhancing detection transformer with hierarchical salience filtering refinement. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17574–17583, 2024
2024
-
[21]
Jaihoon Kim, Taehoon Yoon, Jisung Hwang, and Minhyuk Sung. Inference-time scaling for flow models via stochastic generation and rollover budget forcing.arXiv preprint arXiv:2503.19385, 2025
-
[22]
Test-time alignment of diffusion models without reward over-optimization
Sunwoo Kim, Minkyu Kim, and Dongmin Park. Test-time alignment of diffusion models without reward over-optimization. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=vi3DjUhFVm
2025
-
[23]
Aligning Text-to-Image Models using Human Feedback
Kimin Lee, Hao Liu, Moonkyung Ryu, Olivia Watkins, Yuqing Du, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, and Shixiang Shane Gu. Aligning text-to-image models using human feedback.arXiv preprint arXiv:2302.12192, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Evaluating text-to-visual generation with image-to-text generation
Zhiqiu Lin, Deepak Pathak, Baiqi Li, Jiayao Li, Xide Xia, Graham Neubig, Pengchuan Zhang, and Deva Ramanan. Evaluating text-to-visual generation with image-to-text generation. In European Conference on Computer Vision, pages 366–384. Springer, 2024
2024
-
[25]
Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le
Yaron Lipman, Ricky T.Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling.ICLR, 2023
2023
-
[26]
Flow-GRPO: Training Flow Matching Models via Online RL
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via online rl.arXiv preprint arXiv:2505.05470, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuropean conference on computer vision, pages 38–55. Springer, 2024
2024
-
[28]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
Inference-Time Scaling for Diffusion Models beyond Scaling Denoising Steps
Nanye Ma, Shangyuan Tong, Haolin Jia, Hexiang Hu, Yu-Chuan Su, Mingda Zhang, Xuan Yang, Yandong Li, Tommi Jaakkola, Xuhui Jia, et al. Inference-time scaling for diffusion models beyond scaling denoising steps.arXiv preprint arXiv:2501.09732, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Mihir Prabhudesai, Anirudh Goyal, Deepak Pathak, and Katerina Fragkiadaki. Aligning text- to-image diffusion models with reward backpropagation.arXiv preprint arXiv:2310.03739, 2023
-
[31]
The incomplete beta function law for parallel tempering sampling of classical canonical systems.The Journal of Chemical Physics, 120(9):4119–4128, 2004
Cristian Predescu, Mihaela Predescu, and Cristian V Ciobanu. The incomplete beta function law for parallel tempering sampling of classical canonical systems.The Journal of Chemical Physics, 120(9):4119–4128, 2004
2004
-
[32]
arXiv preprint arXiv:2407.14041 (2024)
Zipeng Qi, Lichen Bai, Haoyi Xiong, and Zeke Xie. Not all noises are created equally: Diffusion noise selection and optimization.arXiv preprint arXiv:2407.14041, 2024
-
[33]
T2icount: Enhancing cross-modal understanding for zero-shot counting
Yifei Qian, Zhongliang Guo, Bowen Deng, Chun Tong Lei, Shuai Zhao, Chun Pong Lau, Xiaopeng Hong, and Michael P Pound. T2icount: Enhancing cross-modal understanding for zero-shot counting. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 25336–25345, 2025
2025
-
[34]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[35]
LAION aesthetic predictor
Christoph Schuhmann. LAION aesthetic predictor. https://laion.ai/blog/ laion-aesthetics/, 2022. Accessed: 2024-09-29. 11
2022
-
[36]
A general framework for inference-time scaling and steering of diffusion models
Raghav Singhal, Zachary Horvitz, Ryan Teehan, Mengye Ren, Zhou Yu, Kathleen McKeown, and Rajesh Ranganath. A general framework for inference-time scaling and steering of diffusion models.arXiv preprint arXiv:2501.06848, 2025
-
[37]
Feynman-kac correctors in diffu- sion: Annealing, guidance, and product of experts
Marta Skreta, Tara Akhound-Sadegh, Viktor Ohanesian, Roberto Bondesan, Alán Aspuru- Guzik, Arnaud Doucet, Rob Brekelmans, Alexander Tong, and Kirill Neklyudov. Feynman- kac correctors in diffusion: Annealing, guidance, and product of experts.arXiv preprint arXiv:2503.02819, 2025
-
[38]
Deep unsuper- vised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsuper- vised learning using nonequilibrium thermodynamics. InInternational conference on machine learning, pages 2256–2265. pmlr, 2015
2015
-
[39]
Score-based generative modeling through stochastic differential equations.ICLR, 2021
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.ICLR, 2021
2021
-
[40]
Replica monte carlo simulation of spin-glasses
Robert H Swendsen and Jian-Sheng Wang. Replica monte carlo simulation of spin-glasses. Physical Review Letters, 57(21):2607, 1986
1986
-
[41]
Tseng, Tommaso Biancalani, and Sergey Levine
Masatoshi Uehara, Yulai Zhao, Kevin Black, Ehsan Hajiramezanali, Gabriele Scalia, Nathaniel Lee Diamant, Alex M Tseng, Tommaso Biancalani, and Sergey Levine. Fine- tuning of continuous-time diffusion models as entropy-regularized control.arXiv preprint arXiv:2402.15194, 2024
-
[42]
Masatoshi Uehara, Yulai Zhao, Chenyu Wang, Xiner Li, Aviv Regev, Sergey Levine, and Tom- maso Biancalani. Inference-time alignment in diffusion models with reward-guided generation: Tutorial and review.arXiv preprint arXiv:2501.09685, 2025
-
[43]
Diffusion model alignment using direct preference optimization
Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik. Diffusion model alignment using direct preference optimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8228–8238, 2024
2024
-
[44]
Trippe, Christian A Naesseth, John Patrick Cunningham, and David Blei
Luhuan Wu, Brian L. Trippe, Christian A Naesseth, John Patrick Cunningham, and David Blei. Practical and asymptotically exact conditional sampling in diffusion models. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview. net/forum?id=eWKqr1zcRv
2023
-
[45]
Human preference score: Better aligning text-to-image models with human preference
Xiaoshi Wu, Keqiang Sun, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score: Better aligning text-to-image models with human preference. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2096–2105, 2023
2096
-
[46]
Imagereward: Learning and evaluating human preferences for text-to-image generation
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems, 36:15903–15935, 2023
2023
-
[47]
Good seed makes a good crop: Discovering secret seeds in text-to-image diffusion models
Katherine Xu, Lingzhi Zhang, and Jianbo Shi. Good seed makes a good crop: Discovering secret seeds in text-to-image diffusion models. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 3024–3034. IEEE, 2025
2025
-
[48]
DanceGRPO: Unleashing GRPO on Visual Generation
Zeyue Xue, Jie Wu, Yu Gao, Fangyuan Kong, Lingting Zhu, Mengzhao Chen, Zhiheng Liu, Wei Liu, Qiushan Guo, Weilin Huang, et al. Dancegrpo: Unleashing grpo on visual generation. arXiv preprint arXiv:2505.07818, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Using human feedback to fine-tune diffusion models without any reward model
Kai Yang, Jian Tao, Jiafei Lyu, Chunjiang Ge, Jiaxin Chen, Weihan Shen, Xiaolong Zhu, and Xiu Li. Using human feedback to fine-tune diffusion models without any reward model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8941–8951, 2024
2024
-
[50]
Taehoon Yoon, Yunhong Min, Kyeongmin Yeo, and Minhyuk Sung. Psi-sampler: Initial particle sampling for smc-based inference-time reward alignment in score models.arXiv preprint arXiv:2506.01320, 2025. 12
-
[51]
Freedom: Training-free energy-guided conditional diffusion model.ICCV, 2023
Jiwen Yu, Yinhuai Wang, Chen Zhao, Bernard Ghanem, and Jian Zhang. Freedom: Training-free energy-guided conditional diffusion model.ICCV, 2023
2023
-
[52]
DiffusionNFT: Online Diffusion Reinforcement with Forward Process
Kaiwen Zheng, Huayu Chen, Haotian Ye, Haoxiang Wang, Qinsheng Zhang, Kai Jiang, Hang Su, Stefano Ermon, Jun Zhu, and Ming-Yu Liu. Diffusionnft: Online diffusion reinforcement with forward process.arXiv preprint arXiv:2509.16117, 2025. 13 A Temperature-Scaled pCNL Transition We describe the within-temperature pCNL transition used in PATHS and show how the ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
A person and an airplane over a car and under the chair
The chains use the same total initialization budget as PATHS, and collected samples are pooled and thinned before being passed to the SMC stage. Best-of-4 uses four independent pCNL chains with the same per-chain budget as PATHS, but all chains use the same temperature T= 1 . After burn-in and thinning, each chain is scored by the average reward of its co...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.