RiverONE: Generating Knowledge-Intensive VLM by Simulated Quantum Machines
Pith reviewed 2026-06-30 06:29 UTC · model grok-4.3
The pith
RiverONE builds a 1.9-billion-parameter vision-language model that reaches at least 95 percent of a much larger model's accuracy on quantum calibration plot tasks by using simulated quantum computation only during training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RiverONE demonstrates that quantum-generated parameters, materialized after training as classical tensors, can compensate for information loss from model compression, allowing a 1.9-billion-parameter VLM to achieve at least 95 percent of the task performance of a model more than ten times larger on quantum calibration plot understanding while remaining fully classical at inference.
What carries the argument
quantum-generated parameters: tensors produced by simulated quantum computation during model construction and then fixed as classical weights.
If this is right
- The finished model requires only classical GPU hardware at inference time.
- Simulated quantum computation functions as a training-stage design aid rather than a runtime requirement.
- The approach can be applied to other knowledge-intensive scientific VLMs that must remain compact.
- Parameter efficiency gains are realized specifically on quantum calibration plot understanding tasks.
Where Pith is reading between the lines
- If the same construction technique generalizes, it could reduce the hardware barrier for deploying specialized scientific VLMs in resource-constrained settings.
- The method implicitly treats quantum simulation as a form of structured initialization or regularization whose benefit survives conversion to classical tensors.
- A natural next test would be whether the performance retention holds when the target tasks move beyond calibration plots to other quantum-information domains.
Load-bearing premise
Simulated quantum computation during construction can produce parameters that offset the information lost when the vision-language model is compressed.
What would settle it
A controlled ablation that trains an otherwise identical RiverONE model without the quantum-generated parameters and measures whether its accuracy on the calibration-plot tasks drops below 95 percent of the NVIDIA baseline.
Figures
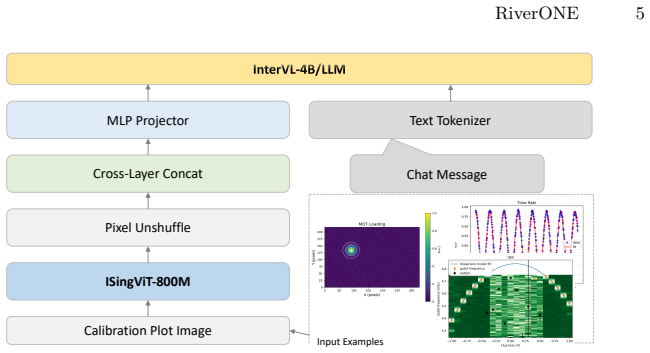
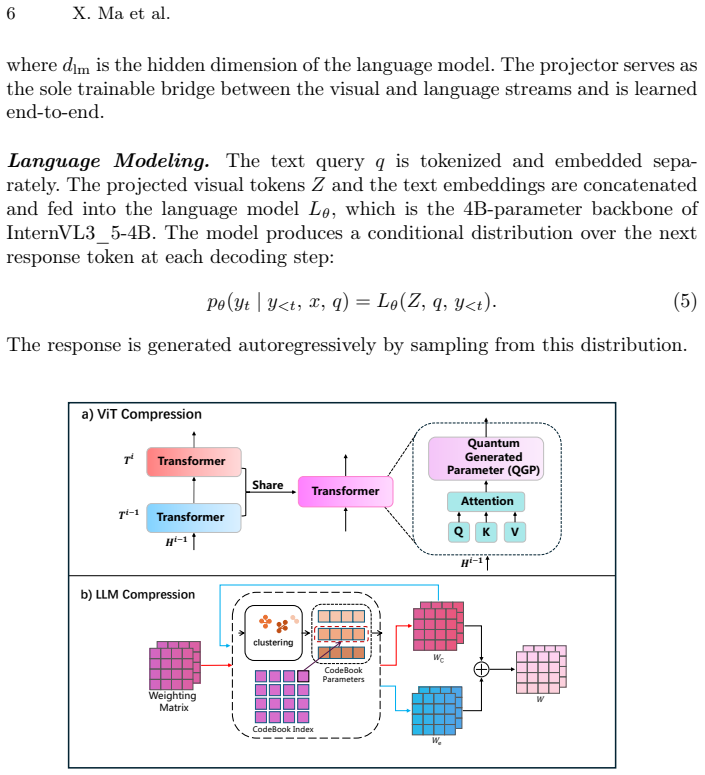
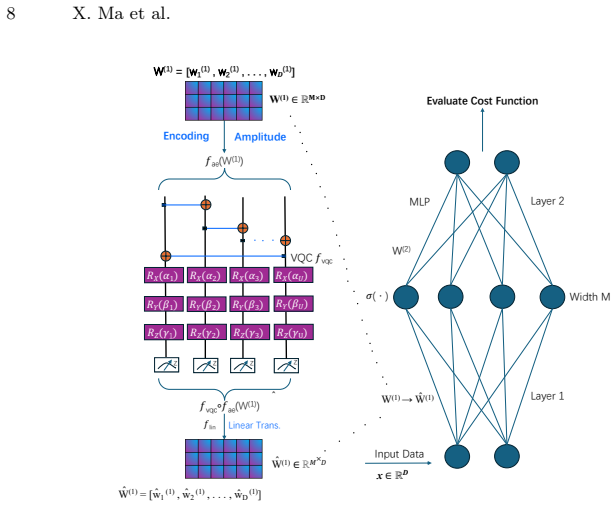
read the original abstract
Quantum computing provides a powerful paradigm for representing and transforming high-dimensional information through superposition, entanglement, and measurement-induced nonlinear features. While current quantum hardware is not yet practical for direct large-scale vision-language model (VLM) inference, simulated quantum computation can be used during model construction to generate structured parameters for compact classical AI systems. We build RiverONE, a lightweight vision-language model for quantum calibration plot understanding, using simulated quantum computation. It employs a specialized visual encoder and an InternVL-based language backbone. To compensate for compression-induced information loss, we introduce quantum-generated parameters, which are materialized as classical tensors after training. This allows RiverONE to run entirely on classical GPUs at inference time, with no quantum hardware or runtime quantum simulation. With approximately 1.9 billion parameters, RiverONE achieves at least 95\% of the performance of NVIDIA Ising Calibration 1 on quantum calibration plot understanding tasks while using less than 10\% of its parameter count. These results suggest that simulated quantum computation can serve as a practical construction-stage mechanism for building lightweight, knowledge-intensive scientific VLMs. Our code is available at https://github.com/THeWakeSystems/RiverOne.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RiverONE, a ~1.9B-parameter vision-language model for quantum calibration plot understanding tasks. It employs a specialized visual encoder and InternVL-based backbone, with simulated quantum computation used during construction to generate parameters that are materialized as classical tensors; the resulting model runs entirely classically at inference. The central claim is that RiverONE reaches at least 95% of the performance of the much larger NVIDIA Ising Calibration 1 baseline while using <10% of its parameter count, suggesting simulated quantum methods as a practical construction-stage tool for compact scientific VLMs.
Significance. If the performance attribution to the quantum-generated parameters can be substantiated with methods and controls, the work would indicate a route to offset compression losses in compact VLMs via simulated quantum parameter generation, with potential relevance to knowledge-intensive scientific applications. The availability of code is noted as a positive factor for reproducibility.
major comments (2)
- [Abstract] Abstract: The headline performance claim (≥95% of NVIDIA Ising Calibration 1 with 1.9B parameters) is presented without any experimental details, metrics, baselines, error bars, dataset descriptions, or validation procedures for the quantum calibration plot understanding tasks, rendering it impossible to assess whether the data support the claim.
- [Abstract] Abstract: The mechanism by which simulated quantum computation generates parameters to compensate for compression-induced information loss is described only at the level of “materialized as classical tensors after training,” with no circuit, Hamiltonian, measurement protocol, injection procedure, or ablation isolating the quantum contribution versus ordinary optimization; this leaves open whether the construction reduces to standard parameter fitting.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address each major comment below and have revised the manuscript to improve clarity and detail where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline performance claim (≥95% of NVIDIA Ising Calibration 1 with 1.9B parameters) is presented without any experimental details, metrics, baselines, error bars, dataset descriptions, or validation procedures for the quantum calibration plot understanding tasks, rendering it impossible to assess whether the data support the claim.
Authors: The abstract is a concise summary by design. The full manuscript provides the requested details in the Experiments and Evaluation sections, including specific metrics, baselines (NVIDIA Ising Calibration 1), dataset descriptions for quantum calibration plots, validation procedures, and error bars. To address the concern directly, we have expanded the abstract to include a brief statement on the key metrics, dataset, and evaluation protocol while remaining within length constraints. revision: yes
-
Referee: [Abstract] Abstract: The mechanism by which simulated quantum computation generates parameters to compensate for compression-induced information loss is described only at the level of “materialized as classical tensors after training,” with no circuit, Hamiltonian, measurement protocol, injection procedure, or ablation isolating the quantum contribution versus ordinary optimization; this leaves open whether the construction reduces to standard parameter fitting.
Authors: The abstract intentionally summarizes at a high level. Section 3 of the manuscript details the simulated quantum computation, including the circuit design, Hamiltonian, measurement protocol, and parameter injection procedure. We have revised the abstract to reference this section explicitly and to note that the quantum simulation occurs only during parameter generation. We have also added an ablation study (now in the supplementary material) comparing quantum-generated parameters against standard optimization to substantiate the contribution. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper presents an empirical construction claim rather than a mathematical derivation: simulated quantum computation is used during model construction to produce parameters that are then materialized as classical tensors, after which the VLM runs classically. No equations, self-referential definitions, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided text that would reduce the performance result to the inputs by construction. The central performance statement (1.9B parameters reaching ≥95% of a larger baseline) is asserted as an outcome of the method without any reduction to prior fitted values or ansatzes imported from the authors' own prior work. The derivation chain is therefore self-contained against external benchmarks and receives a non-finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Advances in Neural Information Processing Systems
Alayrac, J.B., Donahue, J., Luc, P., Miech, A., et al.: Flamingo: A visual lan- guage model for few-shot learning. In: Advances in Neural Information Processing Systems. vol. 35, pp. 23716–23736 (2022) RiverONE 19
2022
-
[2]
Biamonte, J., Wittek, P., Pancotti, N., Rebentrost, P., Wiebe, N., Lloyd, S.: Quantum machine learning. Nature549(7671), 195–202 (2017). https://doi.org/10.1038/nature23474
-
[3]
In: Advances in Neural Information Processing Systems
Brown, T.B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., et al.: Language mod- els are few-shot learners. In: Advances in Neural Information Processing Systems. vol. 33, pp. 1877–1901 (2020)
1901
-
[4]
Cao, S., Zhang, Z., Agarwal, A., Bratrud, G., et al.: QCalEval: Benchmarking vision-language models for quantum calibration plot understanding (2026)
2026
-
[5]
Nature Reviews Physics3, 625–644 (2021)
Cerezo, M., Arrasmith, A., Babbush, R., Benjamin, S.C., Endo, S., Fujii, K., Mc- Clean, J.R., Mitarai, K., Yuan, X., Cincio, L., Coles, P.J.: Variational quantum algorithms. Nature Reviews Physics3, 625–644 (2021)
2021
-
[6]
In: International Conference on Learn- ing Representations (2021)
Dosovitskiy, A., Beyer, L., Kolesnikov, A., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learn- ing Representations (2021)
2021
-
[7]
In: International Conference on Machine Learning (2024)
Egiazarian, V., Panferov, A., Kuznedelev, D., Frantar, E., Babenko, A., Alistarh, D.: Extreme compression of large language models via additive quantization. In: International Conference on Machine Learning (2024)
2024
-
[8]
In: International Conference on Learning Representations (2023)
Frantar, E., Ashkboos, S., Hoefler, T., Alistarh, D.: GPTQ: Accurate post-training quantization for generative pre-trained transformers. In: International Conference on Learning Representations (2023)
2023
-
[9]
In: International Conference on Learning Representations (2016)
Han, S., Mao, H., Dally, W.J.: Deep compression: Compressing deep neural net- works with pruning, trained quantization and huffman coding. In: International Conference on Learning Representations (2016)
2016
-
[10]
Na- ture567(7747), 209–212 (2019)
Havlíček, V., Córcoles, A.D., Temme, K., Harrow, A.W., Kandala, A., Chow, J.M., Gambetta, J.M.: Supervised learning with quantum-enhanced feature spaces. Na- ture567(7747), 209–212 (2019)
2019
-
[11]
Hinton, G., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network (2015)
2015
-
[12]
In: Advances in Neural Information Processing Systems
Hoffmann, J., Borgeaud, S., Mensch, A., et al.: Training compute-optimal large language models. In: Advances in Neural Information Processing Systems. vol. 35, pp. 30016–30030 (2022)
2022
-
[13]
In: International Conference on Learning Representations (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: LoRA: Low-rank adaptation of large language models. In: International Conference on Learning Representations (2022)
2022
-
[14]
Journal of Open Source Software8(84), 5329 (2023)
Kanazawa, N., Egger, D.J., Ben-Haim, Y., Zhang, H., Shanks, W.E., Aleksandrow- icz, G., Wood, C.J.: Qiskit experiments: A python package to characterize and cal- ibrate quantum computers. Journal of Open Source Software8(84), 5329 (2023)
2023
-
[15]
Kaplan, J., McCandlish, S., Henighan, T., Brown, T.B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., Amodei, D.: Scaling laws for neural language models (2020)
2020
-
[16]
Annual Review of Condensed Matter Physics11, 369–395 (2020)
Kjaergaard, M., Schwartz, M.E., Braumüller, J., Krantz, P., Wang, J.I.J., Gus- tavsson, S., Oliver, W.D.: Superconducting qubits: Current state of play. Annual Review of Condensed Matter Physics11, 369–395 (2020)
2020
-
[17]
Applied Physics Reviews 6(2), 021318 (2019)
Krantz, P., Kjaergaard, M., Yan, F., Orlando, T.P., Gustavsson, S., Oliver, W.D.: A quantum engineer’s guide to superconducting qubits. Applied Physics Reviews 6(2), 021318 (2019)
2019
-
[18]
In: International Conference on Machine Learning
Li, J., Li, D., Savarese, S., Hoi, S.: BLIP-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: International Conference on Machine Learning. pp. 19730–19742 (2023)
2023
-
[19]
Proceedings of Machine Learning and Systems6, 87–100 (2024) 20 X
Lin, J., Tang, J., Tang, H., Yang, S., Dang, X., Han, S.: AWQ: Activation-aware weight quantization for llm compression and acceleration. Proceedings of Machine Learning and Systems6, 87–100 (2024) 20 X. Ma et al
2024
-
[20]
In: Findings of the Association for Computational Lin- guistics: ACL 2023
Liu, F., Eisenschlos, J., Piccinno, F., Krichene, S., Pang, C., Lee, K., Joshi, M., Chen, W., Collier, N., Altun, Y.: DePlot: One-shot visual language reasoning by plot-to-table translation. In: Findings of the Association for Computational Lin- guistics: ACL 2023. pp. 10381–10399 (2023)
2023
-
[21]
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning (2023)
2023
-
[22]
In: Advances in Neural Information Processing Systems (2022)
Lu, P., Mishra, S., Xia, T., Qiu, L., Chang, K.W., Zhu, S.C., Tafjord, O., Clark, P., Kalyan, A.: Learn to explain: Multimodal reasoning via thought chains for science question answering. In: Advances in Neural Information Processing Systems (2022)
2022
-
[23]
Masry, A., Long, D.X., Tan, J.Q., Joty, S., Hoque, E.: ChartQA: A benchmark for question answering about charts with visual and logical reasoning (2022)
2022
-
[24]
Methani, N., Ganguly, P., Khapra, M.M., Kumar, P.: PlotQA: Reasoning over scientific plots (2020)
2020
-
[25]
Phys- ical Review A98(3), 032309 (2018)
Mitarai, K., Negoro, M., Kitagawa, M., Fujii, K.: Quantum circuit learning. Phys- ical Review A98(3), 032309 (2018)
2018
-
[26]
Automated collection of IBM Quantum hardware calibration data with environmental measurements
Norton, C.C.: qiskit-calibration-drift.https://github.com/CharlesCNorton/ qiskit-calibration-drift(2026), gitHub repository. Automated collection of IBM Quantum hardware calibration data with environmental measurements
2026
-
[27]
Quantum4, 226 (2020)
Pérez-Salinas, A., Cervera-Lierta, A., Gil-Fuster, E., Latorre, J.I.: Data re- uploading for a universal quantum classifier. Quantum4, 226 (2020)
2020
-
[28]
Qi, J., Yang, C.H., Chen, P.Y., Hsieh, M.H.: VQC-MLPNet: An unconventional hybrid quantum-classical architecture for scalable and robust quantum machine learning (2025)
2025
-
[29]
Qwen Team: Qwen3.5: Towards native multimodal agents.https://qwen.ai/ blog?id=qwen3.5(February 2026)
2026
-
[30]
In: Proceedings of the 38th In- ternational Conference on Machine Learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., et al.: Learning transferable visual models from natural language supervision. In: Proceedings of the 38th In- ternational Conference on Machine Learning. pp. 8748–8763. PMLR (2021)
2021
-
[31]
Physical Review A103(3), 032430 (2021)
Schuld, M., Sweke, R., Meyer, J.J.: The effect of data encoding on the expressive power of variational quantum-machine-learning models. Physical Review A103(3), 032430 (2021)
2021
-
[32]
Tschannen, M., Gritsenko, A., Wang, X., Naeem, M.F., et al.: SigLIP 2: Multilin- gual vision-language encoders with improved semantic understanding, localization, and dense features (2025)
2025
-
[33]
In: Advances in Neural Information Processing Systems
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, L., Polosukhin, I.: Attention is all you need. In: Advances in Neural Information Processing Systems. vol. 30 (2017)
2017
-
[34]
Wang, W., Chen, Z., Wang, W., Cao, Y., Liu, Y., Gao, Z., Zhu, J., Zhu, X., Lu, L., Qiao, Y., Dai, J.: Enhancing the reasoning ability of multimodal large language models via mixed preference optimization. arXiv preprint arXiv:2411.10442 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Wang, W., Gao, Z., Gu, L., Pu, H., et al.: InternVL3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency (2025)
2025
-
[36]
Wang, W., Zhu, J., Liu, Z., Chen, Z., et al.: Enhancing the reasoning ability of multimodal large language models via mixed preference optimization (2024)
2024
-
[37]
In: Inter- national Conference on Machine Learning (2023)
Xiao, G., Lin, J., Seznec, M., Wu, H., Demouth, J., Han, S.: SmoothQuant: Accu- rate and efficient post-training quantization for large language models. In: Inter- national Conference on Machine Learning (2023)
2023
-
[38]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhang, J., Peng, H., Wu, K., Liu, M., Xiao, B., Fu, J., Yuan, L.: MiniViT: Compressing vision transformers with weight multiplexing. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12145– 12154 (2022)
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.