When AUC Misleads: Polarization-Aware Evaluation of Deepfake Detectors under Domain Shift
Pith reviewed 2026-06-26 21:06 UTC · model grok-4.3
The pith
Cross-AUC evaluates deepfake detectors by averaging per-domain performance with polarization measured via Wasserstein distance between score distributions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
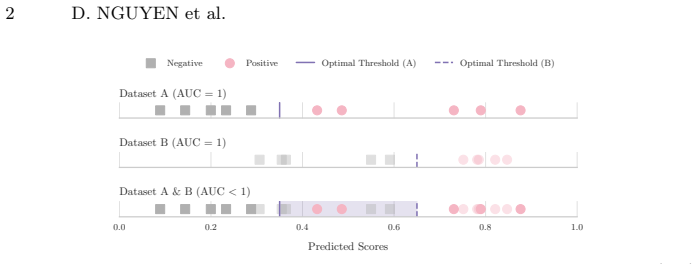
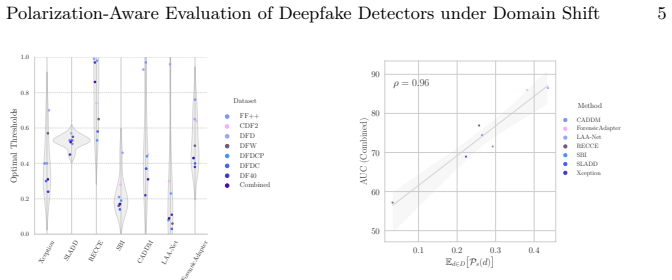
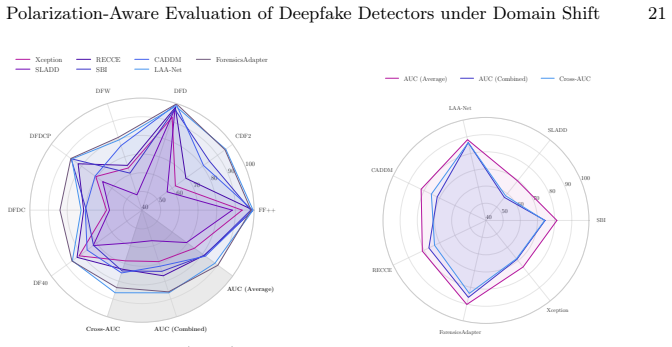
Cross-dataset AUC (Cross-AUC) averages per-domain AUCs with a measure of prediction polarization quantified by the Wasserstein Distance between class score distributions. This metric assesses generalization under domain shifts more realistically than separate AUCs and explains performance drops by showing whether low scores arise from reduced polarization.
What carries the argument
Cross-AUC, which combines per-domain AUCs with Wasserstein distance between class-conditional score distributions to quantify prediction polarization.
If this is right
- A single number now ranks detectors on their joint ability to keep high AUC and high polarization across domains.
- Performance drops can be attributed specifically to loss of polarization rather than to AUC alone.
- Evaluation protocols can move from reporting many separate AUC tables to one Cross-AUC value per detector.
- Detectors that preserve polarized score distributions across shifts receive higher robustness credit.
Where Pith is reading between the lines
- The same polarization term could be added to evaluation in other binary detection tasks that face domain shift.
- Training objectives might be extended to maximize both accuracy and the Wasserstein separation between classes.
- Re-ranking published detectors with Cross-AUC could change which methods are viewed as most generalizable.
Load-bearing premise
That weighting or combining per-domain AUCs with Wasserstein distance between class-conditional score distributions yields a more realistic and interpretable measure of robustness to domain shift than reporting separate AUCs.
What would settle it
A detector that ranks higher than competitors on Cross-AUC yet performs worse than them when deployed on a real mixture of the same domains.
Figures


read the original abstract
Recent advances in generative AI, such as diffusion models and face-swapping tools, have enabled the creation of highly realistic deepfakes, leading to real-world harms including financial fraud and non-consensual explicit content. In response, deepfake detection has become an active research area, with recent methods increasingly focusing on improving generalization to unseen manipulations. This is typically evaluated using the Area Under the ROC Curve (AUC) measured separately across multiple datasets. However, such an evaluation fails to reflect real-world scenarios where detectors face a mixture of data sources and varying artifact types. To address this limitation, we introduce a novel metric, Cross-dataset AUC (Cross-AUC) that averages per-domain AUCs with a measure of prediction polarization for taking into account the robustness to domain shift. The polarization extent is quantified by the Wasserstein Distance between class score distributions. Cross-AUC not only assesses the generalization capabilities of deepfake detectors under domain shifts more realistically, but it is also interpretable as it better explains the reason behind a drop in performance. Experiments performed on seven benchmark datasets demonstrate its practical relevance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that per-dataset AUC evaluation for deepfake detectors does not capture real-world mixed-domain scenarios, and proposes Cross-AUC as a new metric that averages per-domain AUCs together with a polarization term given by the Wasserstein distance between class-conditional score distributions; the authors claim this yields a more realistic assessment of generalization under domain shift and better explains performance drops, with supporting experiments on seven benchmark datasets.
Significance. If the central claim holds, Cross-AUC could supply a practically useful, interpretable alternative to separate AUC reporting for evaluating robustness to domain shift in deepfake detection, potentially improving model selection and diagnosis of failure modes.
major comments (2)
- [Metric definition] The definition of Cross-AUC (presumably in the section introducing the metric) combines per-domain AUCs with Wasserstein distance on score distributions, but supplies no derivation or comparative analysis showing why this particular aggregation (rather than, e.g., a simple mean, a min, or a variance-weighted combination) aligns with real-world mixed-domain performance.
- [Experiments] The experimental section claims that results on seven datasets demonstrate practical relevance, yet contains no direct comparison of Cross-AUC against detector performance on a held-out mixed-domain test set whose domain mixture matches the claimed real-world scenario; without this, it remains possible that Cross-AUC merely re-expresses information already present in the separate AUCs.
minor comments (1)
- [Metric definition] Notation for the polarization term and the exact weighting in the Cross-AUC formula should be stated explicitly with an equation number.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Metric definition] The definition of Cross-AUC (presumably in the section introducing the metric) combines per-domain AUCs with Wasserstein distance on score distributions, but supplies no derivation or comparative analysis showing why this particular aggregation (rather than, e.g., a simple mean, a min, or a variance-weighted combination) aligns with real-world mixed-domain performance.
Authors: We agree that a formal derivation and comparative analysis are missing and would strengthen the paper. The aggregation (average AUC plus Wasserstein polarization term) is motivated by the goal of rewarding both high per-domain accuracy and score separation under shift, as overlapping distributions indicate poor robustness in mixed settings. In revision we will add a subsection deriving the metric from the expected performance under a domain mixture model and include explicit comparisons to alternatives such as min-AUC and variance-weighted means. revision: yes
-
Referee: [Experiments] The experimental section claims that results on seven datasets demonstrate practical relevance, yet contains no direct comparison of Cross-AUC against detector performance on a held-out mixed-domain test set whose domain mixture matches the claimed real-world scenario; without this, it remains possible that Cross-AUC merely re-expresses information already present in the separate AUCs.
Authors: We acknowledge the absence of this direct validation. While the existing results on seven datasets illustrate that the polarization term explains performance variation beyond per-domain AUCs alone, a controlled comparison on constructed mixed-domain test sets is needed to confirm alignment with real-world behavior. We will add such experiments by forming held-out mixed test sets from the benchmarks and report the correlation between Cross-AUC and observed mixed-domain AUC. revision: yes
Circularity Check
Cross-AUC introduced as explicit definition from standard components; no reduction to inputs
full rationale
The paper defines Cross-AUC directly as the average of per-domain AUCs combined with a polarization term given by the Wasserstein distance between class-conditional score distributions. No derivation chain is presented that reduces this quantity to itself by construction, no parameters are fitted on a subset and then relabeled as predictions, and no self-citation or uniqueness theorem is invoked to justify the aggregation choice. The metric is therefore a new definitional proposal whose content is independent of its own outputs; experiments on seven datasets are offered as external validation rather than internal tautology. This matches the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Wasserstein distance between class score distributions quantifies prediction polarization relevant to domain-shift robustness.
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR)
Bai, W., Liu, Y., Zhang, Z., Li, B., Hu, W.: Aunet: Learning relations between action units for face forgery detection. In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR). pp. 24709–24719 (June 2023)
2023
-
[2]
High- resolution image synthesis with latent diffusion models
Cao, J., Ma, C., Yao, T., Chen, S., Ding, S., Yang, X.: End-to-end reconstruction- classification learning for face forgery detection. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4103–4112 (2022).https: //doi.org/10.1109/CVPR52688.2022.00408
-
[3]
chief financial officer
Chen, H., Magramo, K.: Finance worker pays out $25 million after video call with deepfake "chief financial officer".https://edition.cnn.com/2024/02/04/asia/ deepfake-cfo-scam-hong-kong-intl-hnk/index.html(2024), [Online; accessed 4-February-2024]
2024
-
[4]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Chen, L., Zhang, Y., Song, Y., Liu, L., Wang, J.: Self-supervised learning of adver- sarial example: Towards good generalizations for deepfake detection. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 18710–18719 (June 2022)
2022
-
[5]
Advances in Neural Information Processing Systems35, 24597–24610 (2022)
Chen, L., Zhang, Y., Song, Y., Wang, J., Liu, L.: Ost: Improving generalization of deepfake detection via one-shot test-time training. Advances in Neural Information Processing Systems35, 24597–24610 (2022)
2022
-
[6]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Chollet, F.: Xception: Deep learning with depthwise separable convolutions. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1251–1258 (2017)
2017
-
[7]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Cui, X., Li, Y., Luo, A., Zhou, J., Dong, J.: Forensics adapter: Adapting clip for generalizable face forgery detection. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 19207–19217 (2025)
2025
-
[8]
Deepfakes: Faceswapdevs.https://github.com/deepfakes/faceswap(2019)
2019
-
[9]
RetinaFace: Single-stage Dense Face Localisation in the Wild
Deng, J., Guo, J., Zhou, Y., Yu, J., Kotsia, I., Zafeiriou, S.: Retinaface: Single-stage dense face localisation in the wild. CoRRabs/1905.00641(2019)
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[10]
The DeepFake Detection Challenge (DFDC) Dataset
Dolhansky, B., Bitton, J., Pflaum, B., Lu, J., Howes, R., Wang, M., Canton-Ferrer, C.: The deepfake detection challenge dataset. CoRRabs/2006.07397(2020), https://arxiv.org/abs/2006.07397
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[11]
CoRRabs/1910.08854(2019), http://arxiv.org/abs/1910.08854 16 D
Dolhansky, B., Howes, R., Pflaum, B., Baram, N., Canton-Ferrer, C.: The deep- fake detection challenge (DFDC) preview dataset. CoRRabs/1910.08854(2019), http://arxiv.org/abs/1910.08854 16 D. NGUYEN et al
-
[12]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Dong, S., Wang, J., Ji, R., Liang, J., Fan, H., Ge, Z.: Implicit identity leakage: The stumbling block to improving deepfake detection generalization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 3994–4004 (June 2023)
2023
-
[13]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Dong, X., Bao, J., Chen, D., Zhang, T., Zhang, W., Yu, N., Chen, D., Wen, F., Guo,B.:Protectingcelebritiesfromdeepfakewithidentityconsistencytransformer. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 9468–9478 (June 2022)
2022
-
[14]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[15]
html(2019)
Dufour, N., Gully, A.: Contributing data to deepfake detection research.https: //ai.googleblog.com/2019/09/contributing-data-to-deepfake-detection. html(2019)
2019
-
[16]
In: European conference on computer vision
Fu, B., Cao, Z., Long, M., Wang, J.: Learning to detect open classes for universal domain adaptation. In: European conference on computer vision. pp. 567–583. Springer (2020)
2020
-
[17]
Goodfellow, I.J., Shlens, J., Szegedy, C.: Explaining and harnessing adversarial examples (2015)
2015
-
[18]
IEEE Transactions on Knowledge and Data Engineering17(3), 299–310 (2005)
Huang, J., Ling, C.: Using auc and accuracy in evaluating learning algorithms. IEEE Transactions on Knowledge and Data Engineering17(3), 299–310 (2005). https://doi.org/10.1109/TKDE.2005.50
-
[19]
Kowalski, M.: Faceswap.https://github.com/MarekKowalski/FaceSwap(2018)
2018
-
[20]
In: Globerson, A., Mackey, L., Bel- grave, D., Fan, A., Paquet, U., Tomczak, J., Zhang, C
Kumagai, A., Iwata, T., Takahashi, H., Nishiyama, T., Fujiwara, Y.: Auc max- imization under positive distribution shift. In: Globerson, A., Mackey, L., Bel- grave, D., Fan, A., Paquet, U., Tomczak, J., Zhang, C. (eds.) Advances in Neu- ral Information Processing Systems. vol. 37, pp. 36071–36096. Curran Associates, Inc. (2024),https://proceedings.neurips...
2024
-
[21]
Adversarial Machine Learning at Scale
Kurakin, A., Goodfellow, I.J., Bengio, S.: Adversarial machine learning at scale. ArXivabs/1611.01236(2016),https://api.semanticscholar.org/CorpusID: 9059612
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[22]
Proceedings ofthe2023ACMConferenceonFairness,Accountability,andTransparency(2023), https://api.semanticscholar.org/CorpusID:258960540
Kwegyir-Aggrey,K.,Gerchick,M.,Mohan,M.,Horowitz,A.,Venkatasubramanian, S.: The misuse of auc: What high impact risk assessment gets wrong. Proceedings ofthe2023ACMConferenceonFairness,Accountability,andTransparency(2023), https://api.semanticscholar.org/CorpusID:258960540
2023
-
[23]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2020)
Li,L.,Bao,J.,Zhang,T.,Yang,H.,Chen,D.,Wen,F.,Guo,B.:Facex-rayformore general face forgery detection. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2020)
2020
-
[24]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2020)
Li, Y., Yang, X., Sun, P., Qi, H., Lyu, S.: Celeb-df: A large-scale challenging dataset for deepfake forensics. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2020)
2020
-
[25]
2024 IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR) pp
Lin, L., He, X., Ju, Y., Wang, X., Ding, F., Hu, S.: Preserving fairness gener- alization in deepfake detection. 2024 IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR) pp. 16815–16825 (2024),https://api. semanticscholar.org/CorpusID:268031845
2024
-
[26]
Nguyen, D., Astrid, M., Ghorbel, E., Aouada, D.: Fakeformer: Efficient vulnerability-driven transformers for generalisable deepfake detection. arXiv preprint arXiv:2410.21964 (2024) Polarization-Aware Evaluation of Deepfake Detectors under Domain Shift 17
-
[27]
Nguyen, D., Astrid, M., Kacem, A., Ghorbel, E., Aouada, D.: Vulnerability-aware spatio-temporallearningforgeneralizabledeepfakevideodetection.In:Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 10786–10796 (2025)
2025
-
[28]
Nguyen, D., Mejri, N., Singh, I.P., Kuleshova, P., Astrid, M., Kacem, A., Ghorbel, E., Aouada, D.: Laa-net: Localized artifact attention network for quality-agnostic andgeneralizabledeepfakedetection.In:ProceedingsoftheIEEE/CVFConference on Computer Vision and Pattern Recognition (CVPR). pp. 17395–17405 (June 2024)
2024
-
[29]
In: International Confer- ence on Machine Learning (2021),https://api.semanticscholar.org/CorpusID: 231591445
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning trans- ferable visual models from natural language supervision. In: International Confer- ence on Machine Learning (2021),https://api.semanticscholar.org/CorpusID: 231591445
2021
-
[30]
Reuters: South korea to criminalize watching or possessing sexually explicit deep- fakes.https://edition.cnn.com/2024/09/26/asia/south- korea- deepfake- bill-passed-intl-hnk/index.html(2024), [Online; accessed 26-September-2024]
2024
-
[31]
In: International Con- ference on Computer Vision (ICCV) (2019)
Rössler, A., Cozzolino, D., Verdoliva, L., Riess, C., Thies, J., Nießner, M.: Face- Forensics++: Learning to detect manipulated facial images. In: International Con- ference on Computer Vision (ICCV) (2019)
2019
-
[32]
In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion
Shiohara, K., Yamasaki, T.: Detecting deepfakes with self-blended images. In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion. pp. 18720–18729 (2022)
2022
-
[33]
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
Tan, M., Le, Q.V.: Efficientnet: Rethinking model scaling for convolutional neural networks. CoRRabs/1905.11946(2019),http://arxiv.org/abs/1905.11946
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[34]
Deferred Neural Rendering: Image Synthesis using Neural Textures
Thies, J., Zollhöfer, M., Nießner, M.: Deferred neural rendering: Image synthesis using neural textures. CoRRabs/1904.12356(2019),http://arxiv.org/abs/ 1904.12356
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[35]
CoRRabs/2007.14808 (2020),https://arxiv.org/abs/2007.14808
Thies, J., Zollhöfer, M., Stamminger, M., Theobalt, C., Nießner, M.: Face2face: Real-time face capture and reenactment of RGB videos. CoRRabs/2007.14808 (2020),https://arxiv.org/abs/2007.14808
-
[36]
Partial AUC Maximization via Nonlinear Scoring Functions
Ueda, N., Fujino, A.: Partial auc maximization via nonlinear scoring functions. arXiv preprint arXiv:1806.04838 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[37]
Advances in Neural Information Processing Systems37, 29387–29434 (2024)
Yan, Z., Yao, T., Chen, S., Zhao, Y., Fu, X., Zhu, J., Luo, D., Wang, C., Ding, S., Wu, Y., et al.: Df40: Toward next-generation deepfake detection. Advances in Neural Information Processing Systems37, 29387–29434 (2024)
2024
-
[38]
arXiv preprint arXiv:2408.17065 (2024)
Yan, Z., Zhao, Y., Chen, S., Guo, M., Fu, X., Yao, T., Ding, S., Yuan, L.: Gen- eralizing deepfake video detection with plug-and-play: Video-level blending and spatiotemporal adapter tuning. arXiv preprint arXiv:2408.17065 (2024)
-
[39]
Advances in Neural Information Pro- cessing Systems36, 31428–31449 (2023)
Zhang, K., Mo, L., Chen, W., Sun, H., Su, Y.: Magicbrush: A manually annotated dataset for instruction-guided image editing. Advances in Neural Information Pro- cessing Systems36, 31428–31449 (2023)
2023
-
[40]
ArXivabs/1912.11188(2019),https://api.semanticscholar.org/CorpusID: 209460718
Zhang, X., Wang, Q., Zhang, J., Zhong, Z.: Adversarial autoaugment. ArXivabs/1912.11188(2019),https://api.semanticscholar.org/CorpusID: 209460718
-
[41]
In: ICCV 2021 (2021),https://www.amazon.science/ publications/learning-self-consistency-for-deepfake-detection
Zhao, E., Xu, X., Xu, M., Ding, H., Xiong, Y., Xia, W.: Learning self-consistency for deepfake detection. In: ICCV 2021 (2021),https://www.amazon.science/ publications/learning-self-consistency-for-deepfake-detection
2021
-
[42]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhao, H., Zhou, W., Chen, D., Wei, T., Zhang, W., Yu, N.: Multi-attentional deepfake detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 2185–2194 (2021) 18 D. NGUYEN et al
2021
-
[43]
Zi, B., Chang, M., Chen, J., Ma, X., Jiang, Y.G.: Wilddeepfake: A challenging real- world dataset for deepfake detection. Proceedings of the 28th ACM International Conference on Multimedia (2020) Polarization-Aware Evaluation of Deepfake Detectors under Domain Shift 19 6 Appendix Our technical appendix is organized as follows. Section 6.1 presents addi- t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.