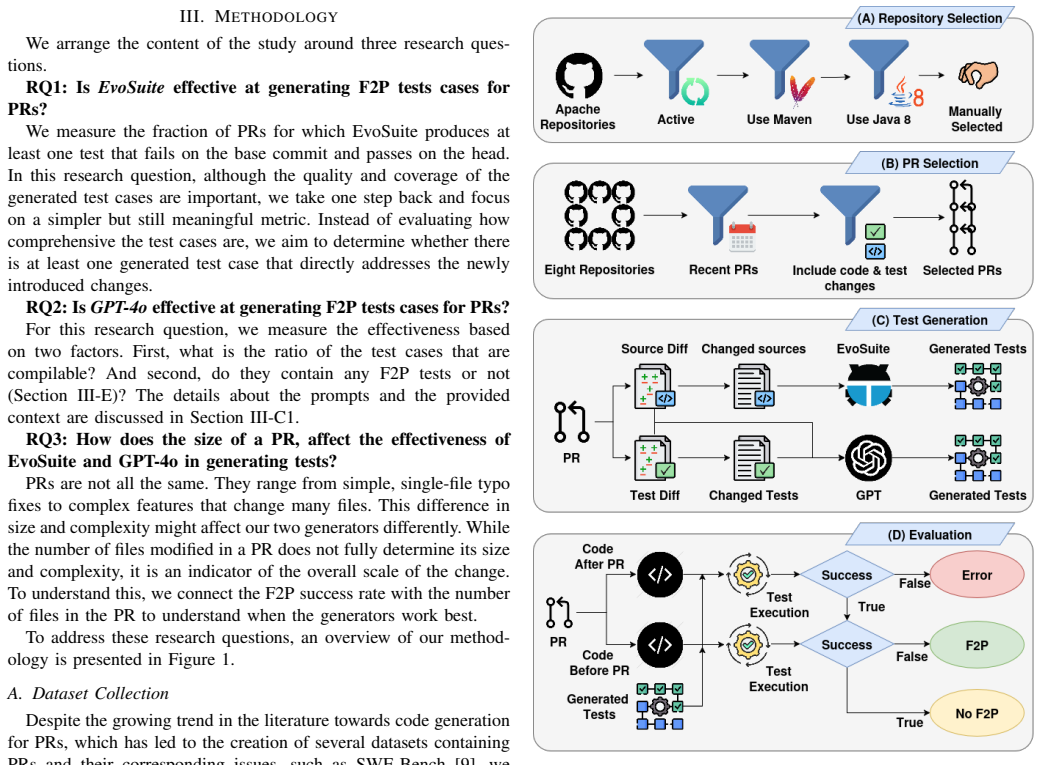
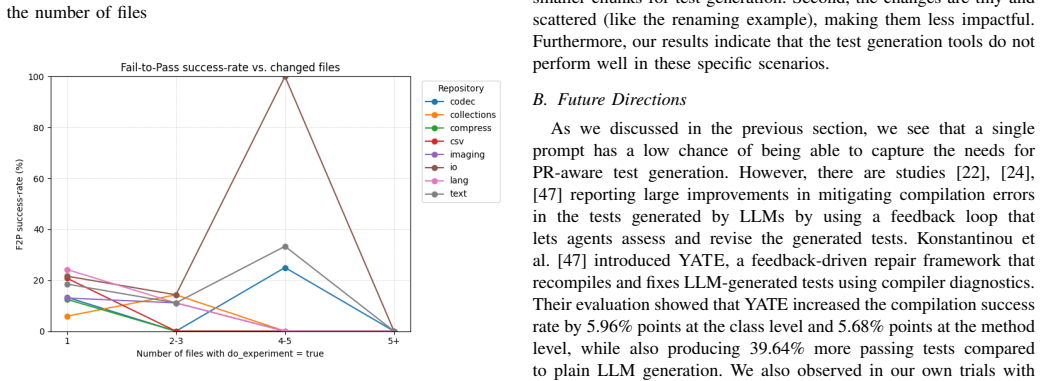
PR-Aware Automated Unit Test Generation: Challenges and Opportunities
Pith reviewed 2026-06-29 23:18 UTC · model grok-4.3
The pith
Current test generators succeed at capturing pull request changes for only a minority of cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The evaluation of EvoSuite and GPT-4o on a set of pull requests shows that EvoSuite produces at least one fail-to-pass test for 36 percent of the PRs while GPT-4o does so for 13 percent. Both tools fail to generate any such tests for 64 percent of the PRs, with GPT-4o additionally facing a 63 percent rate of compilation errors in its outputs.
What carries the argument
The fail-to-pass (F2P) test, defined as a test that fails on the version of the code before the pull request change and passes on the version after the change.
If this is right
- EvoSuite outperforms GPT-4o at producing change-specific tests.
- Both approaches leave most pull requests without meaningful tests.
- Compilation errors severely limit the usefulness of LLM-generated tests.
- New methods tailored to incremental changes are needed.
Where Pith is reading between the lines
- Agentic approaches to code generation may overcome the current limitations.
- Extending the evaluation to additional programming languages or change types could test the generality of the findings.
- Alternative metrics for test usefulness might complement the F2P criterion.
Load-bearing premise
The collection of pull requests studied and the choice of fail-to-pass success as the key measure reflect the broader problem of generating tests for typical code changes.
What would settle it
A demonstration that a different generator produces fail-to-pass tests for a majority of the same pull requests would undermine the conclusion that current tools are largely ineffective.
Figures





read the original abstract
Automated test generation has a substantial body of work, yet most studies focus on generating tests for complete software units, such as classes, and rely on metrics such as code coverage for assessment. In contrast, modern software development primarily evolves through small, targeted changes introduced in pull requests (PRs). Despite this, the crucial task of generating tests specifically for these PRs has been overlooked, and the performance of state-of-the-art tools for this purpose remains unknown. This study evaluates two distinct approaches for PR-aware test generation: EvoSuite, a leading search-based tool, and GPT-4o, one of the widely used large language models (LLMs). To measure their effectiveness at validating PR-specific changes, we assess their ability to generate fail-to-pass (F2P) test cases, meaning tests that fail on the code before the change and pass on the code after the change. Our evaluation shows that EvoSuite outperformed GPT-4o, producing at least one F2P test for a significantly higher percentage of PRs (36 percent vs. 13 percent). The performance of GPT-4o was significantly hampered by a high rate of compilation errors (63 percent), whereas only 2 percent of EvoSuite's generated tests failed to run. Despite EvoSuite's relative success, our findings indicate that both tools are largely ineffective for this task, as they failed to generate any meaningful change-capturing tests for the large majority of the PRs (64 percent). Although both generators could not achieve a high F2P ratio in our evaluation, and EvoSuite outperformed GPT-4o, we believe that agentic code generation methods may have significant potential for this task. Ultimately, our work highlights a critical gap in tooling and calls for the development of high-performance test generators tailored to the incremental nature of modern software development.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates two tools—EvoSuite (search-based) and GPT-4o (LLM)—for PR-aware automated test generation. It measures success via the ability to produce fail-to-pass (F2P) tests that fail before a PR change and pass after. On an unspecified corpus of PRs, EvoSuite generates at least one F2P test for 36% of PRs while GPT-4o succeeds for 13%; both fail for 64% of PRs. The work concludes that current tools are largely ineffective for incremental PR changes, notes GPT-4o's high compilation error rate (63%), and suggests agentic methods as a promising direction for future PR-tailored generators.
Significance. If the evaluation design is sound, the concrete success rates provide direct empirical evidence of a tooling gap between whole-class test generation and the incremental changes typical of modern PR-driven development. The side-by-side comparison of a mature search-based tool against a current LLM, together with the F2P metric, offers a reproducible baseline that future work can build upon. The explicit call for PR-specific generators is a useful framing even if the absolute ineffectiveness numbers require clarification.
major comments (2)
- [Abstract / Evaluation] Abstract and Evaluation section: The central claim that both tools are 'largely ineffective' because they produce no F2P test for 64% of PRs is load-bearing on the premise that every selected PR modifies executable behavior in a way that an F2P test can capture. No breakdown of change types (behavioral modification vs. documentation, comments, configuration, or pure refactoring) or filtering criteria is reported, so it is impossible to determine what fraction of the 64% failures are expected rather than evidence of tool limitation.
- [Abstract] Abstract: The reported percentages (36% vs. 13% success, 64% overall failure, 63% GPT-4o compilation errors) are presented without accompanying dataset size, selection criteria, statistical tests, or baseline comparisons. This makes it difficult to assess whether the observed differences are robust or whether the PR corpus adequately represents the space of incremental changes across projects and languages.
minor comments (2)
- [Abstract] The abstract states that 'agentic code generation methods may have significant potential' without any supporting experiment or reference; this forward-looking claim could be moved to the conclusion or qualified as speculation.
- [Abstract] Notation for F2P is introduced without an explicit definition or example in the provided abstract text; a short formal definition would improve clarity for readers unfamiliar with the metric.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of our evaluation design. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: The central claim that both tools are 'largely ineffective' because they produce no F2P test for 64% of PRs is load-bearing on the premise that every selected PR modifies executable behavior in a way that an F2P test can capture. No breakdown of change types (behavioral modification vs. documentation, comments, configuration, or pure refactoring) or filtering criteria is reported, so it is impossible to determine what fraction of the 64% failures are expected rather than evidence of tool limitation.
Authors: We agree that an explicit breakdown of PR change types is necessary to strengthen the interpretation of the 64% failure rate. The current manuscript selects PRs involving code modifications from Java projects but does not classify them by type. In the revised version, we will add a classification of change types (behavioral modifications, refactoring, documentation, etc.) in the Evaluation section, along with F2P rates stratified by category and a clearer statement of the filtering criteria. This will clarify what portion of failures may be attributable to non-behavioral changes. revision: yes
-
Referee: [Abstract] Abstract: The reported percentages (36% vs. 13% success, 64% overall failure, 63% GPT-4o compilation errors) are presented without accompanying dataset size, selection criteria, statistical tests, or baseline comparisons. This makes it difficult to assess whether the observed differences are robust or whether the PR corpus adequately represents the space of incremental changes across projects and languages.
Authors: The Evaluation section provides the dataset size, selection criteria (PRs from multiple open-source Java repositories with compilable changes), and project details. To improve accessibility, we will revise the abstract to include the corpus size and a concise description of selection criteria. The study is exploratory and does not include formal statistical tests; we will add a clarifying sentence on this point. The direct comparison of EvoSuite and GPT-4o constitutes the primary baseline. These updates will be incorporated. revision: yes
Circularity Check
Empirical evaluation study with no derivations or self-referential reductions
full rationale
The paper is a direct empirical measurement of two tools (EvoSuite and GPT-4o) on an external corpus of PRs using the F2P metric. No equations, fitted parameters, ansatzes, uniqueness theorems, or self-citations appear in the abstract or framing. All reported percentages (36%, 13%, 64%, 63%, 2%) are raw counts from running the tools on the dataset, not reductions of any claimed derivation to its own inputs. The evaluation is therefore self-contained against external benchmarks and exhibits no circularity of the enumerated kinds.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Fail-to-pass tests are a valid and sufficient measure of a generator's ability to validate PR-specific changes.
- domain assumption The PRs studied are representative of typical incremental changes in open-source projects.
Reference graph
Works this paper leans on
-
[1]
Evosuite: Automatic test suite generation for object-oriented software,
G. Fraser and A. Arcuri, “Evosuite: Automatic test suite generation for object-oriented software,” inProceedings of the 19th ACM SIGSOFT Symposium and the 13th European Conference on Foundations of Software Engineering (ESEC/FSE ’11), 2011, pp. 416–419
2011
-
[2]
Evosuite at the sbst 2017 tool competition,
G. Fraser, J. M. Rojas, J. Campos, and A. Arcuri, “Evosuite at the sbst 2017 tool competition,” in10th International Workshop on Search-Based Software Testing (SBST 2017) at ICSE, 2017, pp. 39–42
2017
-
[3]
Evosuite at the sbst 2018 tool competition,
G. Fraser, J. M. Rojas, and A. Arcuri, “Evosuite at the sbst 2018 tool competition,” inProceedings of the 11th International Workshop on Search-Based Software Testing (SBST 2018), 2018, pp. 41–47
2018
-
[4]
Do automatically generated unit tests find real faults? an empirical study of effectiveness and challenges,
S. Shamshiri, R. Just, J. M. Rojas, G. Fraser, P. McMinn, and A. Arcuri, “Do automatically generated unit tests find real faults? an empirical study of effectiveness and challenges,” inProceedings of the 30th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 2015, pp. 201–211
2015
-
[5]
Using relative lines of code to guide automated test gen- eration for python,
J. Holmes, I. Ahmed, C. Brindescu, R. Gopinath, H. Zhang, and A. Groce, “Using relative lines of code to guide automated test gen- eration for python,”ACM Transactions on Software Engineering and Methodology (TOSEM), vol. 29, no. 4, pp. 1–38, 2020
2020
-
[6]
Pull request decisions explained: An empirical overview,
X. Zhang, Y . Yu, G. Gousios, and A. Rastogi, “Pull request decisions explained: An empirical overview,”IEEE Transactions on Software Engineering, vol. 49, no. 2, pp. 849–871, 2023
2023
-
[7]
Engineering fundamentals playbook,
M. Corporation, “Engineering fundamentals playbook,” https://microsof t.github.io/code-with-engineering-playbook/, 2024, accessed: October 14, 2025
2024
-
[8]
Commit-aware mutation testing,
W. Ma, T. Laurent, M. Ojdani ´c, T. T. Chekam, A. Ventresque, and M. Pa- padakis, “Commit-aware mutation testing,” in2020 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, 2020, pp. 394–405
2020
-
[9]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan, “Swe-bench: Can language models resolve real-world github issues?”arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Issue2test: Generating reproducing test cases from issue reports,
N. Nashid, I. Bouzenia, M. Pradel, and A. Mesbah, “Issue2test: Generating reproducing test cases from issue reports,”arXiv preprint arXiv:2503.16320, 2025
-
[11]
When automated program repair meets regression testing—an extensive study on two million patches,
Y . Lou, J. Yang, S. Benton, D. Hao, L. Tan, Z. Chen, L. Zhang, and L. Zhang, “When automated program repair meets regression testing—an extensive study on two million patches,”ACM Trans. Softw. Eng. Methodol., vol. 33, no. 7, Sep. 2024. [Online]. Available: https://doi.org/10.1145/3672450
-
[12]
Lwdiff: an llm-assisted differential testing framework for webassembly runtimes,
S. Zhou, J. Wang, H. Ye, H. Zhou, C. Le Goues, and X. Luo, “Lwdiff: an llm-assisted differential testing framework for webassembly runtimes,” in2025 IEEE/ACM 47th International Conference on Software Engi- neering (ICSE). IEEE Computer Society, 2025, pp. 769–769
2025
-
[13]
Coverage-directed differential testing of jvm implementations,
Y . Chen, T. Su, C. Sun, Z. Su, and J. Zhao, “Coverage-directed differential testing of jvm implementations,” inproceedings of the 37th ACM SIGPLAN Conference on Programming Language Design and Implementation, 2016, pp. 85–99
2016
-
[14]
Regression testing minimization, selection and prioritization: a survey,
S. Yoo and M. Harman, “Regression testing minimization, selection and prioritization: a survey,”Software testing, verification and reliability, vol. 22, no. 2, pp. 67–120, 2012
2012
-
[15]
T-evos: A large-scale longitudinal study on ci test execution and failure,
A. R. Chen, T.-H. P. Chen, and S. Wang, “T-evos: A large-scale longitudinal study on ci test execution and failure,”IEEE Transactions on Software Engineering, vol. 49, no. 4, pp. 2352–2364, Apr. 2023
2023
-
[16]
Finerts: Fine-grained retrieval- augmented test selection,
Y . Liu, M. Gligoric, and P. Nie, “Finerts: Fine-grained retrieval- augmented test selection,” inProceedings of the 38th IEEE/ACM International Conference on Automated Software Engineering (ASE 2023). IEEE, 2023, pp. 129–141. [Online]. Available: https: //pengyunie.github.io/p/LiuETAL23FineRTS.pdf
2023
-
[17]
More precise regression test selection via reasoning about semantics-modifying changes,
Y . Liu, J. Zhang, P. Nie, M. Gligoric, and O. Legunsen, “More precise regression test selection via reasoning about semantics-modifying changes,” inProceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis, ser. ISSTA 2023. New York, NY , USA: Association for Computing Machinery, 2023, p. 664–676. [Online]. Available: h...
-
[18]
T-evos: A large-scale longitudinal study on ci test execution and failure,
A. Trautsch, P. Surendra, A. Gusarova, M. Fischer, S. Apel, A. van Hoorn, and L. Grunske, “T-evos: A large-scale longitudinal study on ci test execution and failure,”IEEE Transactions on Software Engineering, vol. 49, no. 4, pp. 1945–1967, April 2023
1945
-
[19]
Randoop: feedback-directed random testing for java,
C. Pacheco and M. D. Ernst, “Randoop: feedback-directed random testing for java,” inCompanion to the 22nd ACM SIGPLAN conference on Object-oriented programming systems and applications companion, 2007, pp. 815–816
2007
-
[20]
S. Panichella, A. Gambi, F. Zampetti, and V . Riccio, “Sbst tool competition 2021,” inProceedings of the IEEE/ACM 43rd International Conference on Software Engineering Workshops (SBST@ICSE 2021). IEEE/ACM, 2021, pp. 419–430. [Online]. Available: https://doi.org/10 .1109/ICSE-Companion.2021.00101
-
[21]
Empirical comparison between conven- tional and ai-based automated unit test generation tools in java,
M. Gkikopouli and B. Bataa, “Empirical comparison between conven- tional and ai-based automated unit test generation tools in java,” 2023
2023
-
[22]
Testforge: Feedback-driven, agentic test suite generation,
K. Jain and C. L. Goues, “Testforge: Feedback-driven, agentic test suite generation,”arXiv preprint arXiv:2503.14713, 2025
-
[23]
Openhands: An open platform for AI software developers as generalist agents,
X. Wang, B. Li, Y . Song, F. F. Xu, X. Tang, M. Zhuge, J. Pan, Y . Song, B. Li, J. Singh, H. H. Tran, F. Li, R. Ma, M. Zheng, B. Qian, Y . Shao, N. Muennighoff, Y . Zhang, B. Hui, J. Lin, R. Brennan, H. Peng, H. Ji, and G. Neubig, “Openhands: An open platform for AI software developers as generalist agents,” inThe Thirteenth International Conference on Le...
2025
-
[24]
Test wars: A com- parative study of sbst, symbolic execution, and llm-based approaches to unit test generation,
A. Abdullin, P. Derakhshanfar, and A. Panichella, “Test wars: A com- parative study of sbst, symbolic execution, and llm-based approaches to unit test generation,” in2025 IEEE Conference on Software Testing, Verification and Validation (ICST). IEEE, 2025, pp. 221–232
2025
-
[25]
X. Wang, M. Prabhu, D. Narayanan, S. Yao, H. Chen, S. Narayan, M. Zhang, X. Li, and D. Chen, “Multi-SWE-Bench: A Multi-Language Benchmark for Evaluating Large Language Models on Software Maintenance Tasks,”arXiv preprint arXiv:2407.05530, 2024. [Online]. Available: https://arxiv.org/abs/2407.05530
-
[26]
Defects4j: A database of existing faults to enable controlled testing studies for java programs,
R. Just, D. Jalali, and M. D. Ernst, “Defects4j: A database of existing faults to enable controlled testing studies for java programs,” inPro- ceedings of the 2014 international symposium on software testing and analysis, 2014, pp. 437–440
2014
-
[27]
Feedback-directed random test generation,
C. Pacheco, S. K. Lahiri, M. D. Ernst, and T. Ball, “Feedback-directed random test generation,” inProceedings of the 29th International Con- ference on Software Engineering (ICSE ’07). IEEE, 2007, pp. 75–84
2007
-
[28]
How do automatically generated unit tests influence software main- tenance?
S. Shamshiri, J. M. Rojas, J. P. Galeotti, N. Walkinshaw, and G. Fraser, “How do automatically generated unit tests influence software main- tenance?” in2018 IEEE 11th International Conference on Software Testing, Verification and Validation (ICST). IEEE, 2018, pp. 250–261
2018
-
[29]
Automatic test case generation: What if test code quality matters?
F. Palomba, A. Panichella, A. Zaidman, R. Oliveto, and A. D. Lucia, “Automatic test case generation: What if test code quality matters?” inProceedings of the 25th International Symposium on Software Testing and Analysis (ISSTA 2016). New York, NY , USA: Association for Computing Machinery, 2016, pp. 130–141. [Online]. Available: https://doi.org/10.1145/29...
-
[30]
Toward granular search-based automatic unit test case generation,
F. Pecorelli, G. Grano, F. Palomba, and A. De Lucia, “Toward granular search-based automatic unit test case generation,”Empirical Software Engineering, vol. 29, no. 71, 2024. [Online]. Available: https://doi.org/10.1007/s10664-024-10451-x
-
[31]
An empirical study of unit test gen- eration with large language models,
L. Yang, C. Yang, S. Gao, W. Wang, B. Wang, Q. Zhu, X. Chu, J. Zhou, G. Liang, Q. Wang, and J. Chen, “An empirical study of unit test gen- eration with large language models,”arXiv preprint arXiv:2406.18181, 2024
-
[32]
Testspark: Intellij idea’s ultimate test generation companion,
A. Sapozhnikov, M. Olsthoorn, A. Panichella, V . Kovalenko, and P. Derakhshanfar, “Testspark: Intellij idea’s ultimate test generation companion,” inProceedings of the 2024 ACM/IEEE 46th International Conference on Software Engineering: Companion Proceedings (ICSE Companion 2024), 2024, pp. 30–34
2024
-
[33]
No more manual tests? evaluating and improving chatgpt for unit test generation,
Z. Yuan, Y . Lou, M. Liu, S. Ding, K. Wang, Y . Chen, and X. Peng, “No more manual tests? evaluating and improving chatgpt for unit test generation,”arXiv preprint arXiv:2305.04207, 2023
-
[34]
Critical Code Guided Directed Greybox Fuzzing for Commits,
Y . Xiang, X. Zhang, P. Liu, S. Ji, X. Xiao, H. Liang, J. Xu, and W. Wang, “Critical Code Guided Directed Greybox Fuzzing for Commits,”Pro- ceedings of the 33rd USENIX Security Symposium, 2024
2024
-
[35]
Can LLM Generate Regression Tests for Software Commits?
J. Liu, S. Lee, E. Losiouk, and M. Böhme, “Can LLM Generate Regression Tests for Software Commits?” arXiv preprint arXiv:2501.11086, 2025. [Online]. Available: https://arxiv.org/abs/2501.11086
-
[36]
X. Hu, Z. Liu, X. Xia, Z. Liu, T. Xu, and X. Yang, “Identify and update test cases when production code changes: A transformer- based approach,” inProceedings of the 38th IEEE/ACM International Conference on Automated Software Engineering, ser. ASE ’23. IEEE Press, 2024, p. 1111–1122. [Online]. Available: https://doi.org/10.1109/ ASE56229.2023.00165
-
[37]
SWE-smith: Scaling Data for Software Engineering Agents
J. Yang, K. Lieret, C. E. Jimenez, A. Wettig, K. Khandpur, Y . Zhang, B. Hui, O. Press, L. Schmidt, and D. Yang, “Swe-smith: Scaling data for software engineering agents,” 2025. [Online]. Available: https://arxiv.org/abs/2504.21798
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Swe-bench-java: A github issue resolving benchmark for java,
D. Zan, Z. Huang, A. Yu, S. Lin, Y . Shi, W. Liu, D. Chen, Z. Qi, H. Yu, L. Yuet al., “Swe-bench-java: A github issue resolving benchmark for java,”arXiv preprint arXiv:2408.14354, 2024
-
[39]
(2025) Welcome to The Apache Software Foundation
The Apache Software Foundation. (2025) Welcome to The Apache Software Foundation. Accessed 27 August 2025. [Online]. Available: https://www.apache.org/
2025
-
[40]
Apache maven,
——, “Apache maven,” https://maven.apache.org/, 2025, version 3.9.9, accessed 2025-10-14
2025
-
[41]
(2021) Differential / regression test generation (evosuiter)
EvoSuite Project. (2021) Differential / regression test generation (evosuiter). Tutorial page. [Online]. Available: https://www.evosuite.org /evosuiter/
2021
-
[42]
Evosuite 1.1.0 does not recongnize -regressionsuite parameter
leofernandesmo, “Evosuite 1.1.0 does not recongnize -regressionsuite parameter.” https://github.com/EvoSuite/evosuite/issues/353, 4 2021, issue #353 inEvoSuite/evosuiteon GitHub
2021
-
[43]
Gpt-4o system card,
OpenAI, “Gpt-4o system card,” 8 2024, model system card. [Online]. Available: https://cdn.openai.com/gpt-4o-system-card.pdf
2024
-
[44]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. H. Chi, Q. V . Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,” inProceedings of the 36th International Conference on Neural Information Processing Systems (NeurIPS 2022), ser. NeurIPS ’22. Red Hook, NY , USA: Curran Associates Inc., 2022. [Online]. Av...
2022
-
[45]
(2025) Maven surefire plugin
Apache Maven Project. (2025) Maven surefire plugin. Official documentation. [Online]. Available: https://maven.apache.org/surefire/ maven-surefire-plugin/
2025
-
[46]
Com- bining multiple coverage criteria in search-based unit test generation,
J. M. Rojas, J. Campos, M. Vivanti, G. Fraser, and A. Arcuri, “Com- bining multiple coverage criteria in search-based unit test generation,” inInternational Symposium on Search Based Software Engineering. Springer, 2015, pp. 93–108
2015
-
[47]
Yate: The role of test repair in llm-based unit test generation,
M. Konstantinou, R. Degiovanni, J. M. Zhang, M. Harman, and M. Papadakis, “Yate: The role of test repair in llm-based unit test generation,” 2025. [Online]. Available: https://arxiv.org/abs/2507.18316
-
[48]
TestEval: Benchmarking large language models for test case generation,
W. Wang, C. Yang, Z. Wang, Y . Huang, Z. Chu, D. Song, L. Zhang, A. R. Chen, and L. Ma, “TestEval: Benchmarking large language models for test case generation,” inFindings of the Association for Computational Linguistics: NAACL 2025, L. Chiruzzo, A. Ritter, and L. Wang, Eds. Albuquerque, New Mexico: Association for Computational Linguistics, Apr. 2025, pp...
2025
-
[49]
Advancing code coverage: Incorporating program analysis with large language models,
C. Yang, J. Chen, B. Lin, Z. Wang, and J. Zhou, “Advancing code coverage: Incorporating program analysis with large language models,”ACM Transactions on Software Engineering and Methodology (TOSEM), vol. 1, no. 1, pp. 1–31, Jan. 2025. [Online]. Available: https://doi.org/10.1145/3748505
-
[50]
SWE-Agent: Agentic software engineering with tool use,
Z. Li, R. Bommasani, D. Chen, and P. Liang, “SWE-Agent: Agentic software engineering with tool use,” inProc. 2024 Conf. Empirical Meth- ods in Natural Language Processing (EMNLP 2024), 2024, available at https://github.com/princeton-nlp/SWE-agent
2024
-
[51]
(2025) Cline: Autonomous coding agent for VS Code
Cline Development Team. (2025) Cline: Autonomous coding agent for VS Code. Accessed: Oct. 12, 2025. [Online]. Available: https://marketplace.visualstudio.com/items?itemName=clinebcl.cline
2025
-
[52]
(2025) Cursor: The ai code editor
Cursor AI. (2025) Cursor: The ai code editor. Accessed: Oct. 12, 2025. [Online]. Available: https://www.cursor.com
2025
-
[53]
(2025) Windsurf: Multi-agent coding and large-scale software workflows
Windsurf AI. (2025) Windsurf: Multi-agent coding and large-scale software workflows. Accessed: Oct. 12, 2025. [Online]. Available: https://windsurf.ai
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.