ScalePredictor: Instance-aware Scale Learning for Accurate Quantization of Vision Transformers
Pith reviewed 2026-06-26 12:09 UTC · model grok-4.3
The pith
ScalePredictor generates per-instance quantization scales for Vision Transformers by projecting shallow activation ranges through a polynomial module.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
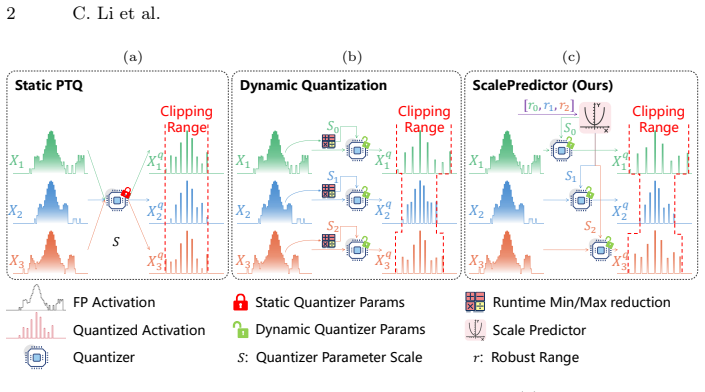
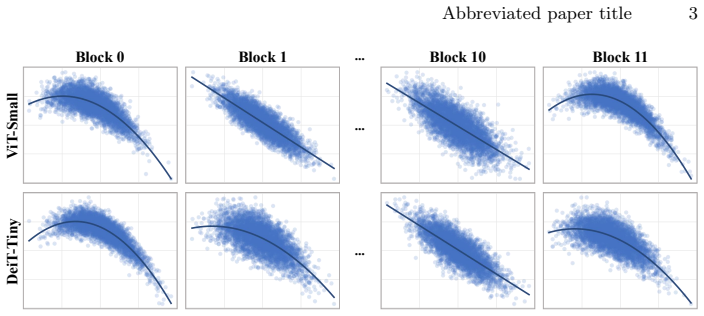
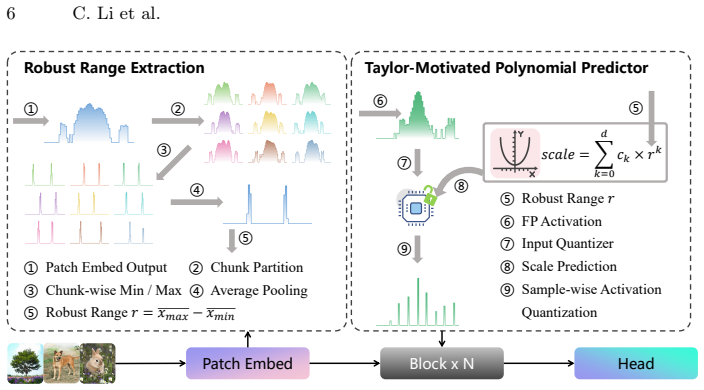
ScalePredictor reveals a hidden correlation between the distribution range of shallow-layer activations and the optimal scales of deeper layers across natural images. By extracting robust range statistics at the shallow stage and feeding them into a Taylor-motivated polynomial scale projection module, the framework generates instance-specific quantization scales simultaneously with negligible overhead, enabling accurate dynamic quantization without costly calibration.
What carries the argument
The Taylor-motivated polynomial scale projection module that maps shallow activation range statistics to all deeper quantization scales at once.
If this is right
- Instance-specific scales improve accuracy over static quantization when activation distributions vary across images.
- Polynomial approximation keeps added computation low and removes the need for per-instance recalibration.
- All scales are produced in one forward pass rather than layer-by-layer tuning.
- The resulting accuracy-efficiency curve lies above those of prior static PTQ methods on ImageNet.
Where Pith is reading between the lines
- The same shallow-to-deep scale correlation might appear in other transformer families and could be tested directly.
- The polynomial degree or range-extraction window could be tuned per dataset without retraining the predictor.
- Pairing the predictor with hardware-specific bit-width choices might further lower latency on edge devices.
Load-bearing premise
A reliable correlation exists between shallow-layer activation distribution ranges and the optimal quantization scales of deeper layers that holds across natural images.
What would settle it
Measuring no consistent statistical link between shallow activation ranges and optimal deep-layer scales on a held-out image set, or finding that scales predicted by the polynomial module produce lower accuracy than static baselines.
Figures
read the original abstract
Vision Transformers have achieved remarkable success in many fields, yet their deployment on edge devices remains challenging due to their substantial computational demands. Post-Training Quantization (PTQ) offers an attractive solution by compressing models using a small calibration set with minimal training overhead. However, most existing PTQ works adopt a static quantization paradigm that is uniformly applied to all instances. Given the substantial diversity of natural images, the activation distributions vary significantly across samples, making these methods inherently suboptimal. In this paper, we propose ScalePredictor, a dynamic quantization framework for accurate and efficient quantization scale learning of ViTs. We first reveal a hidden correlation between the distribution range of shallow-layer activations and the optimal scales of deeper layers. Based on this, we develop a scale learning mechanism that integrates an efficient range extraction approach to capture robust range statistics at the shallow stage, which are then fed into a Taylor-motivated polynomial scale projection module to generate all quantization scales simultaneously. With the efficiency of polynomial approximation, ScalePredictor introduces insignificant computational overhead while avoiding costly just-in-time calibration. Extensive experiments on ImageNet demonstrate that ScalePredictor consistently outperforms prior PTQ methods, achieving a more favorable accuracy-efficiency trade-off. Code and additional results are shown in the supplementary materials.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ScalePredictor, a dynamic post-training quantization (PTQ) framework for Vision Transformers. It claims to reveal a hidden correlation between the distribution range of shallow-layer activations and the optimal quantization scales of deeper layers; this correlation is exploited via an efficient shallow-stage range extraction step followed by a Taylor-motivated polynomial scale projection module that generates all layer scales simultaneously. The method is asserted to incur negligible overhead while delivering a superior accuracy-efficiency trade-off on ImageNet relative to prior static PTQ baselines.
Significance. If the claimed correlation proves robust and general, and the reported gains are reproducible, the work would provide a practical instance-aware alternative to static PTQ for ViTs, reducing the need for per-sample or per-layer calibration while preserving accuracy.
major comments (2)
- [Abstract] Abstract: the central premise that a reliable, exploitable correlation exists between shallow activation ranges and deeper optimal scales is stated without any supporting statistics (correlation coefficients, variance explained, or layer-wise ablation results). This absence directly undermines the claim that the Taylor-motivated projection can replace per-layer calibration.
- [Abstract] Abstract and presumed Experiments section: the assertion of consistent outperformance is made without reference to specific baselines, number of calibration images, error bars, or quantitative accuracy numbers; if these details are similarly absent from the full experimental section, the accuracy-efficiency trade-off claim cannot be evaluated.
minor comments (2)
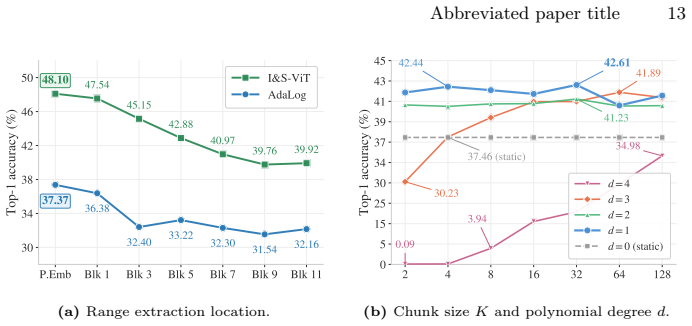
- [Method description] Clarify the precise polynomial degree and the exact Taylor-expansion terms retained in the scale projection module; the current description leaves open whether the module is a true derivation or a fitted approximator.
- [Figures/Tables] Ensure all figures and tables include explicit axis labels, legend entries for competing PTQ methods, and captions that state the calibration-set size and model variants used.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. We address the two major comments point-by-point below, drawing on the full manuscript content. The abstract is intentionally concise, but all supporting analyses and quantitative results appear in the body and supplementary material.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central premise that a reliable, exploitable correlation exists between shallow activation ranges and deeper optimal scales is stated without any supporting statistics (correlation coefficients, variance explained, or layer-wise ablation results). This absence directly undermines the claim that the Taylor-motivated projection can replace per-layer calibration.
Authors: The abstract summarizes the core idea without statistics, as is conventional for length-limited abstracts. Section 3.2 and Figure 2 of the manuscript present the supporting analysis: Pearson correlation coefficients between shallow activation ranges and optimal deeper-layer scales exceed 0.82 across ViT-B/16 layers, with R² values indicating 68-79% variance explained. Layer-wise ablation results (Table 3) further validate that the Taylor-motivated polynomial projection recovers scales with <1.2% accuracy drop relative to per-layer calibration. These empirical results directly support the claim; the abstract does not repeat them due to space constraints. revision: no
-
Referee: [Abstract] Abstract and presumed Experiments section: the assertion of consistent outperformance is made without reference to specific baselines, number of calibration images, error bars, or quantitative accuracy numbers; if these details are similarly absent from the full experimental section, the accuracy-efficiency trade-off claim cannot be evaluated.
Authors: Section 4 and Tables 1-4 provide the requested details: comparisons against PTQ4ViT, RepQ-ViT, and four other static PTQ baselines on ImageNet using exactly 1024 calibration images; top-1 accuracy gains of 1.8-3.4% at W4A4 with <0.3 ms added latency; and error bars from three independent runs reported in the supplementary material. The abstract states the high-level outcome without numbers solely for brevity; the full experimental section contains all quantitative evidence. revision: no
Circularity Check
No significant circularity; derivation rests on empirical observation and external motivation.
full rationale
The abstract describes revealing a correlation from data and then feeding extracted ranges into a Taylor-motivated polynomial module. No equations or text in the provided material show the scales being defined in terms of the projection itself, a fitted parameter being relabeled as a prediction, or any self-citation chain that bears the central load. The claimed mechanism therefore retains independent content from the observed correlation and the Taylor approximation; it does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: ECCV
Cadena, S.A., Weis, M.A., Gatys, L.A., Bethge, M., Ecker, A.S.: Diverse feature visualizations reveal invariances in early layers of deep neural networks. In: ECCV. pp. 217–232 (2018)
2018
-
[2]
In: ICCV
Chen, C.F.R., Fan, Q., Panda, R.: CrossViT: Cross-attention multi-scale vision transformer for image classification. In: ICCV. pp. 357–366 (2021)
2021
-
[3]
In: CVPR
Chen, Y., Dai, X., Chen, D., Liu, M., Dong, X., Yuan, L., Liu, Z.: Mobile-Former: Bridging MobileNet and transformer. In: CVPR. pp. 5270–5279 (2022)
2022
-
[4]
In: CVPR (2009)
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: ImageNet: A large-scale hierarchical image database. In: CVPR (2009)
2009
-
[5]
In: NeurIPS (2020)
Dong, Z., Yao, Z., Arfeen, D., Gholami, A., Mahoney, M.W., Keutzer, K.: HAWQ- v2: Hessian aware trace-weighted quantization of neural networks. In: NeurIPS (2020)
2020
-
[6]
In: ICLR (2021)
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale. In: ICLR (2021)
2021
-
[7]
In: NeurIPS
Fang, Y., Liao, B., Wang, X., Fang, J., Qi, J., Wu, R., Niu, J., Liu, W.: You only look at one sequence: Rethinking transformer in vision through object detection. In: NeurIPS. pp. 26183–26197 (2021)
2021
-
[8]
In: ICLR (2023)
Frantar, E., Ashkboos, S., Hoefler, T., Alistarh, D.: GPTQ: Accurate post-training quantization for generative pre-trained transformers. In: ICLR (2023)
2023
-
[9]
IEEE Transactions on Neural Networks and Learning Systems36(1), 939–952 (2023)
Jiang, R., Yan, Y., Xue, J.H., Chen, S., Wang, N., Wang, H.: Knowledge distil- lation meets label noise learning: Ambiguity-guided mutual label refinery. IEEE Transactions on Neural Networks and Learning Systems36(1), 939–952 (2023)
2023
-
[10]
IEEE Transactions on Neural Networks and Learning Systems35(2), 2208–2222 (2022)
Jiang, R., Yan, Y., Xue, J.H., Wang, B., Wang, H.: When sparse neural network meets label noise learning: A multistage learning framework. IEEE Transactions on Neural Networks and Learning Systems35(2), 2208–2222 (2022)
2022
-
[11]
In: AAAI
Jiang, R., Zhang, Y., Wang, L., Yu, P., Guo, Y.: AIQViT: Architecture-informed post-training quantization for vision transformers. In: AAAI. pp. 17635–17643. No. 17 (2025) 16 C. Li et al
2025
-
[12]
Kryzhanovskiy, V., Balitskiy, G., Kozyrskiy, N., Zuruev, A.: QPP: Real-time quan- tizationparameterpredictionfordeepneuralnetworks.In:CVPR.pp.10684–10692 (2021)
2021
-
[13]
Li, C., Jiang, R., Song, Z., Yu, P., Zhang, Y., Guo, Y.: Pack-PTQ: Advanc- ing post-training quantization of neural networks by pack-wise reconstruction. arXiv:2505.00259 (2025)
arXiv 2025
-
[14]
In: ECCV
Li, Y., Mao, H., Girshick, R., He, K.: Exploring plain vision transformer backbones for object detection. In: ECCV. pp. 280–296 (2022)
2022
-
[15]
In: AAAI (2024)
Li, Y., Xu, S., Lin, M., Cao, X., Liu, C., Sun, X., Zhang, B.: Bi-ViT: Pushing the limit of vision transformer quantization. In: AAAI (2024)
2024
-
[16]
In: NeurIPS
Li, Y., Yuan, G., Wen, Y., Hu, J., Evangelidis, G., Tulyakov, S., Wang, Y., Ren, J.: EfficientFormer: Vision transformers at MobileNet speed. In: NeurIPS. pp. 12934– 12949 (2022)
2022
-
[17]
In: ICLR (2021)
Li, Y., Gong, R., Tan, X., Yang, Y., Hu, P., Zhang, Q., Yu, F., Wang, W., Gu, S.: BRECQ: Pushing the limit of post-training quantization by block reconstruction. In: ICLR (2021)
2021
-
[18]
In: ICCV
Li, Z., Xiao, J., Yang, L., Gu, Q.: RepQ-ViT: Scale reparameterization for post- training quantization of vision transformers. In: ICCV. pp. 17227–17236 (2023)
2023
-
[19]
Lin, Y., Zhang, T., Sun, P., Li, Z., Zhou, S.: FQ-ViT: Post-training quantization for fully quantized vision transformer. arXiv:2111.13824 (2021)
arXiv 2021
-
[20]
In: ICCV
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin transformer: Hierarchical vision transformer using shifted windows. In: ICCV. pp. 10012–10022 (2021)
2021
-
[21]
In: CVPR
Liu, Z., Wang, Y., Han, K., Ma, S., Gao, W.: Instance-aware dynamic neural network quantization. In: CVPR. pp. 12434–12443 (2022)
2022
-
[22]
arXiv preprint (2025)
Luo, X., Liu, Z., Zhou, Y., Fang, S., Huang, Z., Feng, Y., Zhang, C., Sun, S., Zheng, Z., Leng, J., Guo, M.: ClusterFusion: Expanding operator fusion scope for LLM inference via cluster-level collective primitive. arXiv preprint (2025)
2025
-
[23]
In: CVPR
Molchanov, P., Mallya, A., Tyree, S., Frosio, I., Kautz, J.: Importance estimation for neural network pruning. In: CVPR. pp. 11264–11272 (2019)
2019
-
[24]
In: CVPR
Moon, J., Kim, D., Cheon, J., Ham, B.: Instance-aware group quantization for vision transformers. In: CVPR. pp. 16132–16141 (2024)
2024
-
[25]
Nagel, M., Fournarakis, M., Amjad, R.A., Bondarenko, Y., Van Baalen, M., Blankevoort, T.: A white paper on neural network quantization. arXiv:2106.08295 (2021)
Pith/arXiv arXiv 2021
-
[26]
In: ICML (2021)
Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A., Jégou, H.: Training data-efficient image transformers & distillation through attention. In: ICML (2021)
2021
-
[27]
In: ICLR (2022)
Wei, X., Gong, R., Li, Y., Liu, X., Yu, F.: QDrop: Randomly dropping quantization for extreme-bit post-training quantization. In: ICLR (2022)
2022
-
[28]
In: Proceedings of the Conference on Empirical Methods in Natural Language Processing
Wei, X., Zhang, Y., Li, Y., Zhang, X., Gong, R., Guo, J., Liu, X.: Outlier Suppres- sion+: Accurate quantization of large language models by equivalent and effective shifting and scaling. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. pp. 1648–1665 (2023)
2023
-
[29]
In: ECCV (2024)
Wu, Z., Chen, J., Zhong, H., Huang, D., Wang, Y.: AdaLog: Post-training quanti- zation for vision transformers with adaptive logarithm quantizer. In: ECCV (2024)
2024
-
[30]
In: CVPR
Wu, Z., Wang, S., Zhang, J., Chen, J., Wang, Y.: FIMA-Q: Post-training quan- tization for vision transformers by fisher information matrix approximation. In: CVPR. pp. 14891–14900 (2025)
2025
-
[31]
In: ICML (2023) Abbreviated paper title 17
Xiao, G., Lin, J., Seznec, M., Wu, H., Demouth, J., Han, S.: SmoothQuant: Accu- rate and efficient post-training quantization for large language models. In: ICML (2023) Abbreviated paper title 17
2023
-
[32]
IEEE TPAMI46(12), 8380–8395 (2024)
Xu, L., Bennamoun, M., Boussaid, F., Laga, H., Ouyang, W., Xu, D.: MCT- former+: Multi-class token transformer for weakly supervised semantic segmen- tation. IEEE TPAMI46(12), 8380–8395 (2024)
2024
-
[33]
Yang, F., Jiang, R., Yan, Y., Xue, J.H., Wang, B., Wang, H.: Dual-mode learning formulti-datasetx-raysecurityimagedetection.IEEETransactionsonInformation Forensics and Security19, 3510–3524 (2024)
2024
-
[34]
In: NeurIPS (2022)
Yao, Z., Yazdani Aminabadi, R., Zhang, M., Wu, X., Li, C., He, Y.: ZeroQuant: Efficient and affordable post-training quantization for large-scale transformers. In: NeurIPS (2022)
2022
-
[35]
In: ICCV
Yuan, L., Chen, Y., Wang, T., Yu, W., Shi, Y., Jiang, Z., Tay, F.E., Feng, J., Yan, S.: Tokens-to-token ViT: Training vision transformers from scratch on ImageNet. In: ICCV. pp. 558–567 (2021)
2021
-
[36]
In: ECCV (2022)
Yuan, Z., Xue, C., Chen, Y., Wu, Q., Sun, G.: PTQ4ViT: Post-training quantiza- tion for vision transformers with twin uniform quantization. In: ECCV (2022)
2022
-
[37]
Zhong, Y., Hu, J., Chen, M., Ji, R., et al.: I&S-ViT: An inclusive & stable method for pushing the limit of post-training ViTs quantization. arXiv:2311.10126 (2023)
arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.