DramaDirector: Geometry-Guided Short Drama Generation
Pith reviewed 2026-06-26 01:55 UTC · model grok-4.3
The pith
DramaDirector retrieves depth and pose from real short-drama shots to guide multi-shot video generation from plots.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
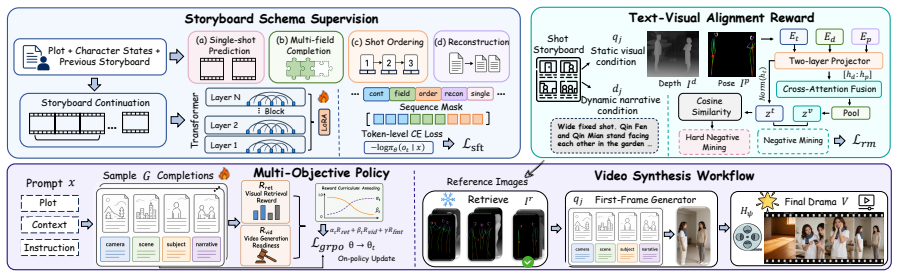
DramaDirector is a geometry-grounded framework that retrieves depth-pose references from real short-drama shots to guide first-frame generation and image-to-video synthesis, trained with schema-constrained SFT and GRPO under a text-visual alignment reward, leading to improved performance on faithfulness, consistency, and controllability over baselines.
What carries the argument
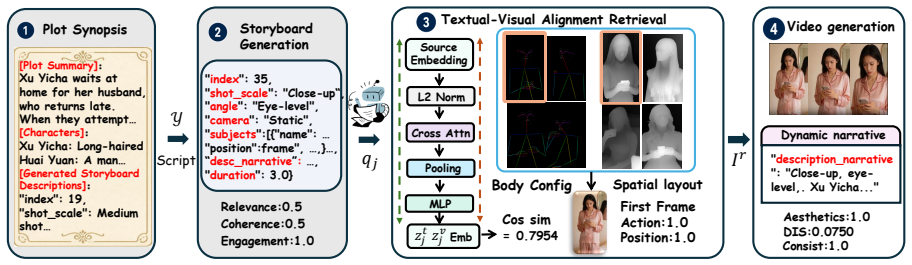
The retrieval of depth and pose references from a gallery of real short-drama shots indexed by depth and pose, used to guide generation while decoupling static visual and dynamic narrative conditions.
If this is right
- Short drama generation can achieve higher visual grounding by referencing real cinematography.
- Multi-agent and video generation baselines can be outperformed by incorporating geometric retrieval.
- Structured storyboards in benchmarks like DramaBoard enable better evaluation of narrative video generation.
Where Pith is reading between the lines
- Larger galleries of indexed shots could further improve reference matching for diverse plots.
- This retrieval method might apply to other domains requiring geometric consistency, such as animation or virtual production.
Load-bearing premise
That a gallery of real short-drama shots will contain sufficiently relevant depth and pose references for arbitrary new plots, allowing reliable transfer without mismatches.
What would settle it
Generating dramas for plots whose required camera geometries are absent from the real-shot gallery and observing whether generation quality degrades significantly compared to in-gallery cases.
Figures












read the original abstract
Short dramas, with their rapid shot rhythms, dialogue-driven focus shifts, and demanding cinematographic grounding, pose challenges that prompt-level or text-only video generation pipelines struggle to meet. We study plot-to-short-drama generation, where a global plot and local context are transformed into visually grounded multi-shot videos. We propose DramaDirector, a geometry-grounded framework that lets the planner borrow cinematographic geometry from a gallery of real short-drama shots indexed by depth and pose. DramaDirector decouples each shot into static visual and dynamic narrative conditions, trains the planner with schema-constrained SFT and GRPO under a learned text-visual alignment reward, and retrieves depth-pose references to guide first-frame generation and image-to-video synthesis. We also introduce DramaBoard, a benchmark built from 35 live-action dramas, 2.8K episodes, and 81K shots, with structured storyboards and multi-dimensional evaluation protocols. Experiments show that DramaDirector improves over representative multi-agent and video generation baselines on faithfulness, consistency, and controllability. Our code is released at: https://github.com/iLearn-Lab/DramaDirector
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DramaDirector, a geometry-grounded framework for plot-to-short-drama generation. It decouples each shot into static visual and dynamic narrative conditions, retrieves depth-pose references from a gallery of real short-drama shots (built from 35 dramas and 81K shots) to condition first-frame generation and I2V synthesis, trains a planner via schema-constrained SFT and GRPO with a learned text-visual alignment reward, and introduces the DramaBoard benchmark with structured storyboards and multi-dimensional evaluation. The central claim is that this yields improvements over representative multi-agent and video generation baselines on faithfulness, consistency, and controllability.
Significance. If the retrieval-based geometry guidance proves reliable, the work could offer a practical route to cinematographically grounded multi-shot video generation that goes beyond text-only conditioning. The open release of code and the introduction of a benchmark with explicit evaluation protocols are concrete strengths that support reproducibility and future comparisons in narrative video synthesis.
major comments (2)
- [Framework description and retrieval component] The central claim depends on the retrieval step (described in the framework overview) reliably surfacing geometrically compatible depth-pose references from the fixed 35-drama gallery for arbitrary new plots. No coverage statistics, retrieval success rates, similarity thresholds, or failure-mode analysis are supplied, so it is impossible to verify whether poor matches degrade the geometry guidance into noisy conditioning.
- [Abstract and Experiments section] The abstract states that experiments demonstrate improvements on faithfulness, consistency, and controllability, yet supplies no quantitative metrics, error bars, dataset splits, or ablation results on the retrieval component. This absence prevents assessment of whether the reported gains are attributable to the geometry guidance or to other factors.
minor comments (2)
- [Abstract] Acronyms such as SFT and GRPO are used without expansion on first appearance in the abstract and method description.
- [DramaBoard benchmark description] The benchmark construction details (2.8K episodes, 81K shots) would benefit from an explicit statement of how the 35 source dramas were selected to ensure diversity of plots and cinematographic styles.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate additional analysis and clarifications.
read point-by-point responses
-
Referee: [Framework description and retrieval component] The central claim depends on the retrieval step (described in the framework overview) reliably surfacing geometrically compatible depth-pose references from the fixed 35-drama gallery for arbitrary new plots. No coverage statistics, retrieval success rates, similarity thresholds, or failure-mode analysis are supplied, so it is impossible to verify whether poor matches degrade the geometry guidance into noisy conditioning.
Authors: We agree that quantitative characterization of the retrieval step is needed to substantiate its reliability. The revised manuscript will add coverage statistics over the 81K-shot gallery, retrieval success rates computed with explicit similarity thresholds on depth-pose features, and a failure-mode analysis that quantifies the impact of poor matches on downstream generation quality. revision: yes
-
Referee: [Abstract and Experiments section] The abstract states that experiments demonstrate improvements on faithfulness, consistency, and controllability, yet supplies no quantitative metrics, error bars, dataset splits, or ablation results on the retrieval component. This absence prevents assessment of whether the reported gains are attributable to the geometry guidance or to other factors.
Authors: The experiments section already reports quantitative metrics, dataset construction details, and baseline comparisons; however, we acknowledge the absence of retrieval-specific ablations and the lack of numeric results in the abstract. We will revise the abstract to include key quantitative improvements with error bars and add explicit ablation studies isolating the retrieval component in the experiments section. revision: yes
Circularity Check
No circularity: empirical framework with external benchmark and released code
full rationale
The paper presents an applied system (DramaDirector) that retrieves depth-pose references from a fixed gallery of 81K shots drawn from 35 dramas, trains a planner via schema-constrained SFT + GRPO with a learned reward, and evaluates on the introduced DramaBoard benchmark. No equations, fitted parameters renamed as predictions, or derivation chains appear in the provided text. Claims of improved faithfulness/consistency/controllability rest on experimental comparison against baselines rather than any self-referential reduction. The gallery construction, retrieval mechanism, and benchmark are described as independent artifacts; the code release further supports external verification. This matches the default case of a self-contained empirical contribution with no load-bearing self-citation or definitional circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Comfymind: Toward general-purpose generation via tree-based planning and reactive feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
arXiv preprint arXiv:2603.28767 , year=
Gen-searcher: Reinforcing agentic search for image generation , author=. arXiv preprint arXiv:2603.28767 , year=
-
[3]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Vita: An efficient video-to-text algorithm using vlm for rag-based video analysis system , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[4]
International Conference on Learning Representations , volume=
T2v-turbo-v2: Enhancing video model post-training through data, reward, and conditional guidance design , author=. International Conference on Learning Representations , volume=
-
[7]
Proceedings of the 29th International Conference on Computational Linguistics , pages=
Of human criteria and automatic metrics: A benchmark of the evaluation of story generation , author=. Proceedings of the 29th International Conference on Computational Linguistics , pages=
-
[8]
arXiv preprint arXiv:2510.12323 , year=
Rag-anything: All-in-one rag framework , author=. arXiv preprint arXiv:2510.12323 , year=
-
[9]
arXiv preprint arXiv:2508.07597 , year=
ShoulderShot: Generating Over-the-Shoulder Dialogue Videos , author=. arXiv preprint arXiv:2508.07597 , year=
-
[10]
arXiv preprint arXiv:2504.02436 , year=
Skyreels-a2: Compose anything in video diffusion trans formers , author=. arXiv preprint arXiv:2504.02436 , year=
-
[11]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Dreamrunner: Fine-grained compositional story-to-video generation with retrieval-augmented motion adaptation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[12]
Proceedings of the computer vision and pattern recognition conference , pages=
Comfybench: Benchmarking llm-based agents in comfyui for autonomously designing collaborative ai systems , author=. Proceedings of the computer vision and pattern recognition conference , pages=
-
[13]
2026 , howpublished =
Wan2.6 , author =. 2026 , howpublished =
2026
-
[14]
2026 , howpublished =
Vidu Q3 Turbo , author =. 2026 , howpublished =
2026
-
[15]
2026 , howpublished =
Nano Banana 2: Gemini AI Image Generator and Photo Editor , author =. 2026 , howpublished =
2026
-
[16]
2026 , howpublished =
Seedream 5.0 Lite , author =. 2026 , howpublished =
2026
-
[17]
2026 , howpublished =
Multimodal Embedding API Reference , author =. 2026 , howpublished =
2026
-
[18]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Genmac: compositional text-to-video generation with multi-agent collaboration , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[20]
arXiv preprint arXiv:2511.08521 , year=
UniVA: Universal Video Agent towards Open-Source Next-Generation Video Generalist , author=. arXiv preprint arXiv:2511.08521 , year=
-
[21]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Videoauteur: Towards long narrative video generation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[22]
arXiv preprint arXiv:2410.05779 , volume=
Lightrag: Simple and fast retrieval-augmented generation , author=. arXiv preprint arXiv:2410.05779 , volume=
-
[23]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Patho-AgenticRAG: towards multimodal agentic retrieval-augmented generation for pathology VLMs via reinforcement learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[24]
Tongyi-Embedding-Vision: Multimodal Embedding API , year =
-
[25]
arXiv preprint arXiv:2311.15127 , year =
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets , author =. arXiv preprint arXiv:2311.15127 , year =
-
[26]
arXiv preprint arXiv:2410.13720 , year =
Movie Gen: A Cast of Media Foundation Models , author =. arXiv preprint arXiv:2410.13720 , year =
-
[27]
arXiv preprint arXiv:2311.04145 , year =
I2VGen-XL: High-Quality Image-to-Video Synthesis via Cascaded Diffusion Models , author =. arXiv preprint arXiv:2311.04145 , year =
-
[28]
arXiv preprint arXiv:2209.14958 , year =
Co-Writing Screenplays and Theatre Scripts with Language Models: An Evaluation by Industry Professionals , author =. arXiv preprint arXiv:2209.14958 , year =
-
[29]
arXiv preprint arXiv:2309.15091 , year =
VideoDirectorGPT: Consistent Multi-scene Video Generation via LLM-Guided Planning , author =. arXiv preprint arXiv:2309.15091 , year =
-
[30]
arXiv preprint arXiv:2411.04925 , year =
StoryAgent: Customized Storytelling Video Generation via Multi-Agent Collaboration , author =. arXiv preprint arXiv:2411.04925 , year =
-
[31]
arXiv preprint arXiv:2503.05242 , year =
MM-StoryAgent: Immersive Narrated Storybook Video Generation with a Multi-Agent Paradigm across Text, Image and Audio , author =. arXiv preprint arXiv:2503.05242 , year =
-
[32]
arXiv preprint arXiv:2408.09333 , year =
SkyScript-100M: 1,000,000,000 Pairs of Scripts and Shooting Scripts for Short Drama , author =. arXiv preprint arXiv:2408.09333 , year =
-
[33]
arXiv preprint arXiv:2602.21818 , year =
SkyReels-V4: Multi-modal Video-Audio Generation, Inpainting and Editing model , author =. arXiv preprint arXiv:2602.21818 , year =
-
[34]
arXiv preprint arXiv:2412.20725 , year =
Dialogue Director: Bridging the Gap in Dialogue Visualization for Multimodal Storytelling , author =. arXiv preprint arXiv:2412.20725 , year =
-
[35]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
ShotAdapter: Text-to-Multi-Shot Video Generation with Diffusion Models , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[36]
arXiv preprint arXiv:2302.05543 , year =
Adding Conditional Control to Text-to-Image Diffusion Models , author =. arXiv preprint arXiv:2302.05543 , year =
-
[37]
arXiv preprint arXiv:2311.16933 , year =
SparseCtrl: Adding Sparse Controls to Text-to-Video Diffusion Models , author =. arXiv preprint arXiv:2311.16933 , year =
-
[38]
arXiv preprint arXiv:2309.00398 , year =
VideoGen: A Reference-Guided Latent Diffusion Approach for High Definition Text-to-Video Generation , author =. arXiv preprint arXiv:2309.00398 , year =
-
[39]
arXiv preprint arXiv:2310.12190 , year =
DynamiCrafter: Animating Open-domain Images with Video Diffusion Priors , author =. arXiv preprint arXiv:2310.12190 , year =
-
[40]
arXiv preprint arXiv:2404.02101 , year =
CameraCtrl: Enabling Camera Control for Text-to-Video Generation , author =. arXiv preprint arXiv:2404.02101 , year =
-
[41]
arXiv preprint arXiv:2410.15957 , year =
CamI2V: Camera-Controlled Image-to-Video Diffusion Model , author =. arXiv preprint arXiv:2410.15957 , year =
-
[42]
Proceedings of the IEEE/CVF International Conference on Computer Vision , year =
RealCam-I2V: Real-World Image-to-Video Generation with Interactive Complex Camera Control , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision , year =
-
[43]
arXiv preprint arXiv:2501.12948 , year =
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author =. arXiv preprint arXiv:2501.12948 , year =
-
[44]
arXiv preprint arXiv:2503.06749 , year =
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models , author =. arXiv preprint arXiv:2503.06749 , year =
-
[45]
arXiv preprint arXiv:2501.09099 , year=
Drama llama: An llm-powered storylets framework for authorable responsiveness in interactive narrative , author=. arXiv preprint arXiv:2501.09099 , year=
-
[46]
arXiv preprint arXiv:2506.18899 , year=
Filmaster: Bridging cinematic principles and generative ai for automated film generation , author=. arXiv preprint arXiv:2506.18899 , year=
-
[47]
Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems , pages=
Audience in the loop: Viewer feedback-driven content creation in micro-drama production on social media , author=. Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems , pages=
2026
-
[48]
arXiv preprint arXiv:2603.02681 , year =
VisionCreator: A Native Visual-Generation Agentic Model with Understanding, Thinking, Planning and Creation , author =. arXiv preprint arXiv:2603.02681 , year =
-
[49]
arXiv preprint arXiv:2603.08812 , year =
VisionCreator-R1: A Reflection-Enhanced Native Visual-Generation Agentic Model , author =. arXiv preprint arXiv:2603.08812 , year =
-
[50]
arXiv preprint arXiv:2505.24073 , year =
mRAG: Elucidating the Design Space of Multi-modal Retrieval-Augmented Generation , author =. arXiv preprint arXiv:2505.24073 , year =
-
[51]
arXiv preprint arXiv:2602.09609 , year =
Tele-Omni: a Unified Multimodal Framework for Video Generation and Editing , author =. arXiv preprint arXiv:2602.09609 , year =
-
[52]
arXiv preprint arXiv:2604.09195 , year =
Camera Artist: A Multi-Agent Framework for Cinematic Language Storytelling Video Generation , author =. arXiv preprint arXiv:2604.09195 , year =
-
[53]
Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
A Survey on LLMs for Story Generation , author=. Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
2025
-
[54]
arXiv preprint arXiv:2507.18634 , year =
Captain Cinema: Towards Short Movie Generation , author =. arXiv preprint arXiv:2507.18634 , year =
-
[55]
arXiv preprint arXiv:2510.23163 , year =
Beyond Direct Generation: A Decomposed Approach to Well-Crafted Screenwriting with LLMs , author =. arXiv preprint arXiv:2510.23163 , year =
-
[56]
International Conference on Learning Representations , year =
VADER: Video Diffusion Alignment via Reward Gradients , author =. International Conference on Learning Representations , year =
-
[57]
arXiv preprint arXiv:2512.12372 , year =
STAGE: Storyboard-Anchored Generation for Cinematic Multi-shot Narrative , author =. arXiv preprint arXiv:2512.12372 , year =
-
[58]
arXiv preprint arXiv:2604.03315 , year =
StoryBlender: Inter-Shot Consistent and Editable 3D Storyboard with Spatial-temporal Dynamics , author =. arXiv preprint arXiv:2604.03315 , year =
-
[59]
arXiv preprint arXiv:2512.07802 , year =
OneStory: Coherent Multi-Shot Video Generation with Adaptive Memory , author =. arXiv preprint arXiv:2512.07802 , year =
-
[61]
IEEE/CVF International Conference on Computer Vision (ICCV) , year=
VideoAuteur: Towards long narrative video generation , author=. IEEE/CVF International Conference on Computer Vision (ICCV) , year=
-
[62]
arXiv preprint arXiv:2507.00001 , year=
Long Context Tuning for multi-shot video generation , author=. arXiv preprint arXiv:2507.00001 , year=
-
[63]
arXiv preprint arXiv:2503.07314 , year=
MovieBench: Hierarchical annotations for movie generation , author=. arXiv preprint arXiv:2503.07314 , year=
-
[64]
International Conference on Learning Representations (ICLR) 2025 , year=
MovieDreamer: Hierarchical Generation for Coherent Long Visual Sequences , author=. International Conference on Learning Representations (ICLR) 2025 , year=
2025
-
[65]
arXiv preprint arXiv:2512.19539 , year=
StoryMem: Memory-Augmented Video Storytelling , author=. arXiv preprint arXiv:2512.19539 , year=
-
[66]
arXiv preprint arXiv:2506.01908 , year=
Reinforcement Learning Tuning for VideoLLMs: Reward Design and Data Efficiency , author=. arXiv preprint arXiv:2506.01908 , year=
-
[67]
arXiv preprint arXiv:2505.23990 , year=
Multi-RAG: A Multimodal Retrieval-Augmented Generation System for Adaptive Video Understanding , author=. arXiv preprint arXiv:2505.23990 , year=
-
[68]
arXiv preprint arXiv:2604.05418 , year=
VideoStir: Understanding Long Videos via Spatio-Temporally Structured and Intent-Aware RAG , author=. arXiv preprint arXiv:2604.05418 , year=
-
[69]
NeurIPS 2025 , year=
EchoShot: Multi-Shot Portrait Video Generation , author=. NeurIPS 2025 , year=
2025
-
[70]
arXiv preprint arXiv:2406.09414 , year=
Depth Anything V2 , author=. arXiv preprint arXiv:2406.09414 , year=
-
[71]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Effective Whole-Body Pose Estimation with Two-Stages Distillation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.