Learning Higher-Order Structure from Incomplete Spatiotemporal Data: Multi-Scale Hypergraph Laplacians with Neural Refinement
Pith reviewed 2026-05-20 14:53 UTC · model grok-4.3
The pith
Multi-scale hypergraph Laplacians recover group-conservation patterns in incomplete spatiotemporal data that pairwise graphs cannot access.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
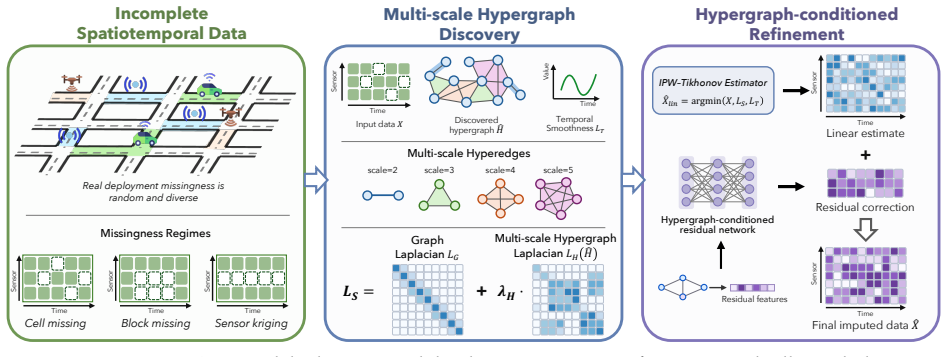
MSHL is a two-stage framework in which the discovery stage constructs a multi-scale hypergraph from complementary topology and residual-correlation evidence together with an observation-only selector that adapts to the supported interaction scale, while the refinement stage adds a small hypergraph-conditioned residual network that learns nonlinear corrections where informative residual features exist and defers to the linear estimate where they do not. The framework is shown to represent group-conservation patterns inaccessible to pairwise graph priors, to adapt to the best fixed scale up to a logarithmic factor, to transfer this advantage to held-out imputation error, and to admit a one-sid
What carries the argument
Multi-Scale Hypergraph Laplacians (MSHL), a two-stage discovery-plus-refinement framework that builds adaptive multi-scale hypergraphs from observed topology and residuals then applies safe neural corrections.
If this is right
- MSHL represents group-conservation patterns inaccessible to pairwise graph priors.
- The method adapts to the best fixed scale up to a logarithmic factor.
- The scale-adaptation advantage transfers directly to lower held-out imputation error.
- The refinement stage admits a one-sided guarantee that does not degrade the linear hypergraph estimate.
- On traffic networks the approach improves over pairwise baselines whenever higher-order structure is identifiable and otherwise matches within sampling noise.
Where Pith is reading between the lines
- Infrastructure monitoring systems could treat clusters of missing readings as direct signals for discovering group-level conservation laws rather than as isolated values to fill.
- The observation-only selector mechanism may reduce reliance on manual scale tuning when applying hypergraph models to other domains with incomplete observations.
- If higher-order structure proves unidentifiable on new data, the framework's fallback behavior ensures performance no worse than standard pairwise methods.
- The same discovery-plus-safe-refinement pattern could be tested on other spatiotemporal domains such as weather or traffic flow where missingness often occurs in contiguous blocks.
Load-bearing premise
The observation-only selector can reliably identify the appropriate interaction scale from topology and residual-correlation evidence in the presence of structured missingness without access to the missing values themselves.
What would settle it
A collection of spatiotemporal datasets with known higher-order group patterns where the observation-only selector repeatedly selects a scale that yields higher held-out imputation error than the optimal fixed scale, or where MSHL shows no improvement over pairwise-graph baselines under structured missingness beyond sampling noise.
Figures





read the original abstract
Sensor networks increasingly govern modern infrastructure, yet the data they lose are rarely missing in the uniform-random patterns assumed by standard imputation benchmarks. Loop detectors go offline during calibration, roadside cabinets silence clusters of nearby sensors, and newly installed instruments provide no history. Such failures create structured absences whose values are constrained by higher-order relations among groups of sensors, not merely by pairwise proximity. Existing low-rank and graph-based methods often miss this collective structure and can fail when missingness becomes coherent. We introduce Multi-Scale Hypergraph Laplacians (MSHL), a two-stage framework for learning higher-order structure from incomplete spatiotemporal observations. The Discovery stage builds a multi-scale hypergraph from complementary topology and residual-correlation evidence, with an observation-only selector that adapts to the supported interaction scale. The Refinement stage adds a small hypergraph-conditioned residual network that is safe by construction: it learns nonlinear corrections where informative residual features exist and defers to the linear estimate where they do not. We prove that MSHL represents group-conservation patterns inaccessible to pairwise graph priors, adapts to the best fixed scale up to a logarithmic factor, transfers this advantage to held-out imputation error, and admits a one-sided refinement guarantee. On two real traffic networks evaluated across scattered cell missingness, contiguous block outages, and whole-sensor blackouts at five rates, MSHL improves over a pairwise-graph baseline whenever higher-order structure is identifiable and otherwise matches it within sampling noise. The results point to a broader principle for reliable infrastructure learning: missing data should be treated not as isolated entries to fill, but as evidence of structure to discover.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Multi-Scale Hypergraph Laplacians (MSHL), a two-stage framework for imputing incomplete spatiotemporal sensor data under structured missingness. The Discovery stage constructs a multi-scale hypergraph from topology and residual correlations via an observation-only selector that adapts to the supported interaction scale. The Refinement stage adds a hypergraph-conditioned residual network that learns nonlinear corrections where informative and defers to the linear estimate otherwise. The manuscript claims proofs that MSHL represents group-conservation patterns inaccessible to pairwise graphs, adapts to the best fixed scale up to a logarithmic factor, transfers the advantage to held-out imputation error, and admits a one-sided refinement guarantee. Experiments on two traffic networks across scattered, contiguous-block, and whole-sensor missingness at five rates show improvements over pairwise baselines when higher-order structure is present.
Significance. If the selector reliability and theoretical guarantees hold, the work would offer a meaningful advance in handling coherent missingness in infrastructure sensor data by explicitly discovering and exploiting higher-order group structure rather than relying on pairwise graphs or low-rank assumptions. The safety-by-construction property of the residual network and the empirical robustness across multiple missingness patterns are potentially valuable if rigorously supported.
major comments (3)
- Abstract and Discovery stage: The adaptation-to-best-scale claim (up to logarithmic factor) and transfer to held-out imputation error rest on the observation-only selector reliably identifying the supported interaction scale from topology and residual correlations alone. No explicit robustness bound or argument is provided showing that residual correlations remain informative about true higher-order groups when missingness is coherent (contiguous blocks or whole-sensor blackouts), which could systematically distort observed residuals and undermine the claimed advantage over pairwise baselines.
- Theoretical claims section: The one-sided refinement guarantee and representation of group-conservation patterns appear to invoke external mathematical arguments rather than reducing directly to quantities fitted from the incomplete observations; this introduces a circularity risk for the central claim that MSHL is safe by construction and superior when higher-order structure exists.
- §4 (Experiments): The cross-missingness results report gains only when higher-order structure is identifiable, yet no ablation isolates the contribution of the multi-scale selector versus the residual network, making it difficult to confirm that the adaptation mechanism is the load-bearing driver of the reported improvements.
minor comments (2)
- Notation for the multi-scale levels and residual network hyperparameters should be introduced with explicit definitions in the main text rather than deferred to the appendix.
- Figure captions for the traffic network visualizations could clarify how the selected hyperedges align with the observed residual correlations under each missingness pattern.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below with clarifications, proposed additions, and revisions to the manuscript where appropriate.
read point-by-point responses
-
Referee: Abstract and Discovery stage: The adaptation-to-best-scale claim (up to logarithmic factor) and transfer to held-out imputation error rest on the observation-only selector reliably identifying the supported interaction scale from topology and residual correlations alone. No explicit robustness bound or argument is provided showing that residual correlations remain informative about true higher-order groups when missingness is coherent (contiguous blocks or whole-sensor blackouts), which could systematically distort observed residuals and undermine the claimed advantage over pairwise baselines.
Authors: We appreciate this observation. The manuscript demonstrates empirical robustness of the selector across contiguous-block and whole-sensor missingness patterns in the traffic datasets, where topology provides a stable anchor and residuals are computed only on observed entries. However, we acknowledge that an explicit robustness argument or bound under coherent missingness is not derived in the current version. In revision we will add a dedicated paragraph in the Discovery stage section that (i) formalizes the conditions under which observed residuals preserve higher-order correlation structure and (ii) includes a short synthetic-data analysis with controlled coherent missingness to illustrate when the selector remains reliable. This addition will make the adaptation claim more rigorously supported without altering the core proofs. revision: partial
-
Referee: Theoretical claims section: The one-sided refinement guarantee and representation of group-conservation patterns appear to invoke external mathematical arguments rather than reducing directly to quantities fitted from the incomplete observations; this introduces a circularity risk for the central claim that MSHL is safe by construction and superior when higher-order structure exists.
Authors: We thank the referee for flagging the potential circularity. The proofs are intended to start from the observed residuals and the hypergraph constructed solely from those observations; the group-conservation representation and one-sided guarantee are shown to hold with respect to the linear estimator that would be obtained from the same incomplete data. To eliminate any ambiguity we will revise the theoretical claims section to include a self-contained proof outline that explicitly begins from the observation model and the quantities estimated from incomplete data, thereby removing reliance on external arguments and clarifying the safety-by-construction property. revision: yes
-
Referee: §4 (Experiments): The cross-missingness results report gains only when higher-order structure is identifiable, yet no ablation isolates the contribution of the multi-scale selector versus the residual network, making it difficult to confirm that the adaptation mechanism is the load-bearing driver of the reported improvements.
Authors: We agree that an ablation isolating the selector from the refinement network would strengthen the experimental section. In the revised manuscript we will add an ablation study that reports imputation error for (a) the linear baseline, (b) fixed-scale hypergraph without selector, (c) multi-scale selector without refinement, and (d) full MSHL, across all three missingness patterns and rates. This will directly quantify the contribution of the adaptation mechanism. revision: yes
Circularity Check
No significant circularity; derivation relies on independent mathematical arguments
full rationale
The paper's central claims rest on stated proofs that MSHL represents group-conservation patterns inaccessible to pairwise priors, adapts to best scale up to a logarithmic factor, transfers advantage to held-out imputation error, and admits a one-sided refinement guarantee. These are presented as external mathematical results rather than reductions to fitted quantities or self-citations. The Discovery stage's observation-only selector constructs the hypergraph from topology and residual correlations on observed data, but no equation or step equates the selector output directly to the target imputation error by construction. The Refinement stage is described as safe by construction with deferral to linear estimates. No load-bearing self-citation chain or ansatz smuggling is evident that would force the results to the inputs. The method is self-contained against external benchmarks and falsifiable via the reported experiments on real traffic networks.
Axiom & Free-Parameter Ledger
free parameters (2)
- multi-scale levels
- residual network hyperparameters
axioms (2)
- domain assumption Higher-order group relations exist in the sensor data and are identifiable from observed topology and residual correlations
- ad hoc to paper The observation-only selector can choose the supported interaction scale without access to missing entries
invented entities (2)
-
Multi-Scale Hypergraph Laplacian
no independent evidence
-
Hypergraph-conditioned residual network
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Multi-scale aggregation... w_s = 1 / binom(s,2) ... scale-invariant weighting (Lemma 1)
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 5 (Oracle scale adaptation)... Lepski-style per-scale complexity penalty
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Berihun Fekade, Taras Maksymyuk, Maryan Kyryk, and Minho Jo. Probabilistic recovery of incomplete sensed data in iot.IEEE Internet of Things Journal, 5(4):2282–2292, 2017
work page 2017
-
[2]
Xinyu Chen, Zhaocheng He, and Jiawei Wang. Spatial-temporal traffic speed patterns discovery and incompletedatarecoveryviasvd-combinedtensordecomposition.TransportationresearchpartC:emerging technologies, 86:59–77, 2018
work page 2018
-
[3]
Reliable sensor deployment for network traffic surveillance
Xiaopeng Li and Yanfeng Ouyang. Reliable sensor deployment for network traffic surveillance. Transportation research part B: methodological, 45(1):218–231, 2011
work page 2011
-
[4]
Mostafa Salari, Lina Kattan, William HK Lam, HP Lo, and Mohammad Ansari Esfeh. Optimization of traffic sensor location for complete link flow observability in traffic network considering sensor failure. Transportation Research Part B: Methodological, 121:216–251, 2019
work page 2019
-
[5]
Higher-order interactions shape collective human behaviour
Federico Battiston, Valerio Capraro, Fariba Karimi, Sune Lehmann, Andrea Bamberg Migliano, Onkar Sadekar, Angel Sánchez, and Matjaž Perc. Higher-order interactions shape collective human behaviour. Nature Human Behaviour, pages 1–17, 2025
work page 2025
-
[6]
Higher-order organization of complex networks
Austin R Benson, David F Gleich, and Jure Leskovec. Higher-order organization of complex networks. Science, 353(6295):163–166, 2016
work page 2016
-
[7]
Representing higher-order dependencies in networks.Science advances, 2(5):e1600028, 2016
Jian Xu, Thanuka L Wickramarathne, and Nitesh V Chawla. Representing higher-order dependencies in networks.Science advances, 2(5):e1600028, 2016
work page 2016
-
[8]
Xiao Jiang, Zean Tian, and Kenli Li. A graph-based approach for missing sensor data imputation.IEEE Sensors Journal, 21(20):23133–23144, 2021
work page 2021
-
[9]
Xinyu Chen, Zhanhong Cheng, HanQin Cai, Nicolas Saunier, and Lijun Sun. Laplacian convolutional representation for traffic time series imputation.IEEE Transactions on Knowledge and Data Engineering, 36(11):6490–6502, 2024
work page 2024
-
[10]
The physics of higher-order interactions in complex systems.Nature physics, 17(10):1093–1098, 2021
Federico Battiston, Enrico Amico, Alain Barrat, Ginestra Bianconi, Guilherme Ferraz de Arruda, Benedetta Franceschiello, Iacopo Iacopini, Sonia Kéfi, Vito Latora, Yamir Moreno, et al. The physics of higher-order interactions in complex systems.Nature physics, 17(10):1093–1098, 2021
work page 2021
-
[11]
Iacopo Iacopini, Márton Karsai, and Alain Barrat. The temporal dynamics of group interactions in higher-order social networks.Nature Communications, 15(1):7391, 2024
work page 2024
-
[12]
Knowledge Is Not Static: Order-Aware Hypergraph RAG for Language Models
Keshu Wu, Chenchen Kuai, Zihao Li, Jiwan Jiang, Shiyu Shen, Shian Wang, Chan-Wei Hu, Zhengzhong Tu, and Yang Zhou. Knowledge is not static: Order-aware hypergraph rag for language models.arXiv preprint arXiv:2604.12185, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
A Arun Prakash and Karthik K Srinivasan. Finding the most reliable strategy on stochastic and time- dependent transportation networks: A hypergraph based formulation.Networks and Spatial Economics, 17(3):809–840, 2017. 21
work page 2017
-
[14]
Howmuchandwhendoweneedhigher-order information in hypergraphs? a case study on hyperedge prediction
Se-eunYoon,HyungseokSong,KijungShin,andYungYi. Howmuchandwhendoweneedhigher-order information in hypergraphs? a case study on hyperedge prediction. InProceedings of the web conference 2020, pages 2627–2633, 2020
work page 2020
-
[15]
Equivariant hypergraph diffusion neural operators
Peihao Wang, Shenghao Yang, Yunyu Liu, Zhangyang Wang, and Pan Li. Equivariant hypergraph diffusion neural operators. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[16]
Keshu Wu, Yang Zhou, Haotian Shi, Dominique Lord, Bin Ran, and Xinyue Ye. Hypergraph-based motion generation with multi-modal interaction relational reasoning.Transportation Research Part C: Emerging Technologies, 180:105349, 2025
work page 2025
-
[17]
KeshuWu,ZihaoLi,SixuLi,XinyueYe,DominiqueLord,andYangZhou. Ai2-activesafety: Ai-enabled interaction-aware active safety analysis with vehicle dynamics.arXiv preprint arXiv:2505.00322, 2025
-
[18]
Pulak Purkait, Tat-Jun Chin, Alireza Sadri, and David Suter. Clustering with hypergraphs: the case for large hyperedges.IEEE transactions on pattern analysis and machine intelligence, 39(9):1697–1711, 2016
work page 2016
-
[19]
Mingxia Liu, Yue Gao, Pew-Thian Yap, and Dinggang Shen. Multi-hypergraph learning for incomplete multimodality data.IEEE journal of biomedical and health informatics, 22(4):1197–1208, 2017
work page 2017
-
[20]
Karelia Pena-Pena, Lucas Taipe, Fuli Wang, Daniel L. Lau, and Gonzalo R. Arce. Learning hypergraphs tensor representations from data via t-hgsp.IEEE Transactions on Signal and Information Processing over Networks, 10:17–31, 2024
work page 2024
-
[21]
A survey on hypergraph representation learning.ACM Comput
Alessia Antelmi, Gennaro Cordasco, Mirko Polato, Vittorio Scarano, Carmine Spagnuolo, and Dingqi Yang. A survey on hypergraph representation learning.ACM Comput. Surv., 56(1), August 2023
work page 2023
-
[22]
Diffusion convolutional recurrent neural network: Data-driven traffic forecasting
Yaguang Li, Rose Yu, Cyrus Shahabi, and Yan Liu. Diffusion convolutional recurrent neural network: Data-driven traffic forecasting. InInternational Conference on Learning Representations (ICLR ’18), 2018
work page 2018
-
[23]
Ji Liu, Przemyslaw Musialski, Peter Wonka, and Jieping Ye. Tensor completion for estimating missing values in visual data.IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(1):208–220, 2013
work page 2013
-
[24]
Bayesian temporal factorization for multidimensional time series prediction
Xinyu Chen and Lijun Sun. Bayesian temporal factorization for multidimensional time series prediction. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(9):4659–4673, 2022
work page 2022
-
[25]
Xinyu Chen, Mengying Lei, Nicolas Saunier, and Lijun Sun. Low-rank autoregressive tensor completion for spatiotemporal traffic data imputation.IEEE Transactions on Intelligent Transportation Systems, 23(8):12301–12310, 2022
work page 2022
-
[26]
Xinyu Chen, Jinming Yang, and Lijun Sun. A nonconvex low-rank tensor completion model for spatiotemporal traffic data imputation.Transportation Research Part C: Emerging Technologies, 117:102673, 2020
work page 2020
-
[27]
Tong Nie, Guoyang Qin, Yunpeng Wang, and Jian Sun. Correlating sparse sensing for large-scale traffic speed estimation: A laplacian-enhanced low-rank tensor kriging approach.Transportation Research Part C: Emerging Technologies, 152:104190, 2023
work page 2023
-
[28]
Andrea Cini, Ivan Marisca, and Cesare Alippi. Filling the g_ap_s: Multivariate time series imputation by graph neural networks.arXiv preprint arXiv:2108.00298, 2021
-
[29]
Yuankai Wu, Dingyi Zhuang, Aurelie Labbe, and Lijun Sun. Inductive graph neural networks for spatiotemporal kriging.Proceedings of the AAAI Conference on Artificial Intelligence, 35(5):4478–4485, May 2021
work page 2021
-
[30]
Brits: Bidirectional recurrent imputation for time series
Wei Cao, Dong Wang, Jian Li, Hao Zhou, Lei Li, and Yitan Li. Brits: Bidirectional recurrent imputation for time series. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018
work page 2018
-
[31]
Wenjie Du, David Côté, and Yan Liu. Saits: Self-attention-based imputation for time series.Expert Systems with Applications, 219:119619, 2023
work page 2023
-
[32]
Csdi: Conditional score-based diffusion models for probabilistic time series imputation
Yusuke Tashiro, Jiaming Song, Yang Song, and Stefano Ermon. Csdi: Conditional score-based diffusion models for probabilistic time series imputation. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, volume 34, pages 24804–24816. Curran Associates, Inc., 2021
work page 2021
-
[33]
Pristi: A conditional diffusion framework for spatiotemporal imputation
Mingzhe Liu, Han Huang, Hao Feng, Leilei Sun, Bowen Du, and Yanjie Fu. Pristi: A conditional diffusion framework for spatiotemporal imputation. In2023 IEEE 39th International Conference on Data Engineering (ICDE), pages 1927–1939, 2023. 22
work page 1927
-
[34]
Learningtoreconstructmissingdatafromspatiotemporal graphs with sparse observations
IvanMarisca,AndreaCini,andCesareAlippi. Learningtoreconstructmissingdatafromspatiotemporal graphs with sparse observations. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems, volume 35, pages 32069–32082. Curran Associates, Inc., 2022
work page 2022
-
[35]
Rie Ando and Tong Zhang. Learning on graph with laplacian regularization.Advances in neural information processing systems, 19, 2006
work page 2006
-
[36]
Ming Yin, Junbin Gao, and Zhouchen Lin. Laplacian regularized low-rank representation and its applications.IEEE transactions on pattern analysis and machine intelligence, 38(3):504–517, 2015
work page 2015
-
[37]
Learning with hypergraphs: Clustering, classification, and embedding
Dengyong Zhou, Jiayuan Huang, and Bernhard Schölkopf. Learning with hypergraphs: Clustering, classification, and embedding. In B. Schölkopf, J. Platt, and T. Hoffman, editors,Advances in Neural Information Processing Systems, volume 19. MIT Press, 2006
work page 2006
-
[38]
Yifan Feng, Haoxuan You, Zizhao Zhang, Rongrong Ji, and Yue Gao. Hypergraph neural networks. Proceedings of the AAAI Conference on Artificial Intelligence, 33(01):3558–3565, Jul. 2019
work page 2019
-
[39]
Hypergcn: A new method for training graph convolutional networks on hypergraphs
Naganand Yadati, Madhav Nimishakavi, Prateek Yadav, Vikram Nitin, Anand Louis, and Partha Talukdar. Hypergcn: A new method for training graph convolutional networks on hypergraphs. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 32. Curran Associates, I...
work page 2019
-
[40]
Hypergraphconvolutionandhypergraphattention.Pattern Recognition, 110:107637, 2021
SongBai,FeihuZhang,andPhilipH.S.Torr. Hypergraphconvolutionandhypergraphattention.Pattern Recognition, 110:107637, 2021
work page 2021
-
[41]
Youareallset: Amultisetfunctionframework for hypergraph neural networks
EliChien,ChaoPan,JianhaoPeng,andOlgicaMilenkovic. Youareallset: Amultisetfunctionframework for hypergraph neural networks. InInternational Conference on Learning Representations, 2022
work page 2022
-
[42]
Ziyue Li, Nurettin Dorukhan Sergin, Hao Yan, Chen Zhang, and Fugee Tsung. Tensor completion for weakly-dependentdataongraphformetropassengerflowprediction.ProceedingsoftheAAAIConference on Artificial Intelligence, 34(04):4804–4810, Apr. 2020
work page 2020
-
[43]
OV Lepskii. On a problem of adaptive estimation in gaussian white noise.Theory of Probability & Its Applications, 35(3):454–466, 1991
work page 1991
-
[44]
A. B. Tsybakov.Introduction to Nonparametric Estimation. Springer, 2009
work page 2009
-
[45]
Jerome H Friedman. Greedy function approximation: a gradient boosting machine.Annals of statistics, pages 1189–1232, 2001
work page 2001
-
[46]
Deepresiduallearningforimagerecognition
KaimingHe,XiangyuZhang,ShaoqingRen,andJianSun. Deepresiduallearningforimagerecognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016
work page 2016
-
[47]
Liqiao Xia, Yongshi Liang, Pai Zheng, and Xiao Huang. Residual-hypergraph convolution network: A model-based and data-driven integrated approach for fault diagnosis in complex equipment.IEEE Transactions on Instrumentation and Measurement, 72:1–11, 2023
work page 2023
-
[48]
Residual enhanced multi-hypergraph neural network
Jing Huang, Xiaolin Huang, and Jie Yang. Residual enhanced multi-hypergraph neural network. In 2021 IEEE International Conference on Image Processing (ICIP), pages 3657–3661, 2021
work page 2021
-
[49]
Spectrally-normalized margin bounds for neural networks
Peter Bartlett, Dylan J Foster, and Matus J Telgarsky. Spectrally-normalized margin bounds for neural networks. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017
work page 2017
-
[50]
Cambridge university press, 2018
RomanVershynin.High-dimensionalprobability: Anintroductionwithapplicationsindatascience,volume47. Cambridge university press, 2018. 23 Appendix Theappendixisorganizedasfollows. AppendixAprovidesanotationstableforquickreference. AppendixB contains the IPW lemma and the hypergraph Dirichlet identity. Appendix C gives proofs of all theorems and lemmas in the...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.