Drifting Preference Optimization for One-Step Generative Models
Pith reviewed 2026-06-28 15:18 UTC · model grok-4.3
The pith
DrPO aligns one-step text-to-image generators by synthesizing a dipole preference field from reward rankings alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
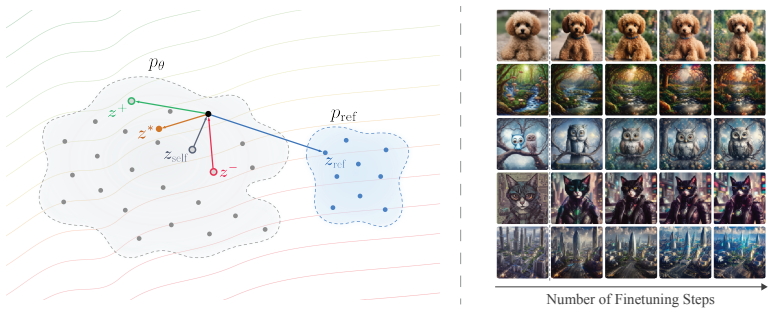
DrPO constructs a non-parametric dipole preference field from ranked samples together with a reference drift from the frozen base generator; the resulting feature-space direction is regressed onto the one-step model through a detached target, enabling preference alignment when the reward supplies only ranking information.
What carries the argument
The non-parametric dipole preference field plus reference drift, which supplies a stable feature-space update direction derived solely from reward rankings.
If this is right
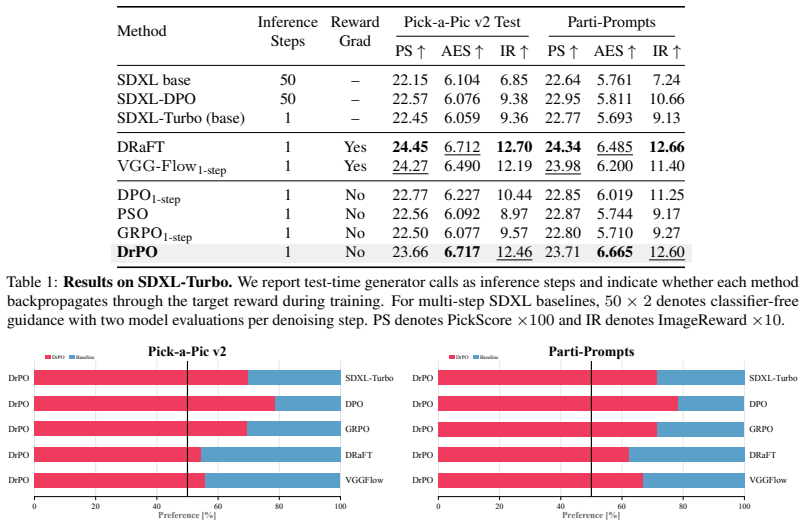
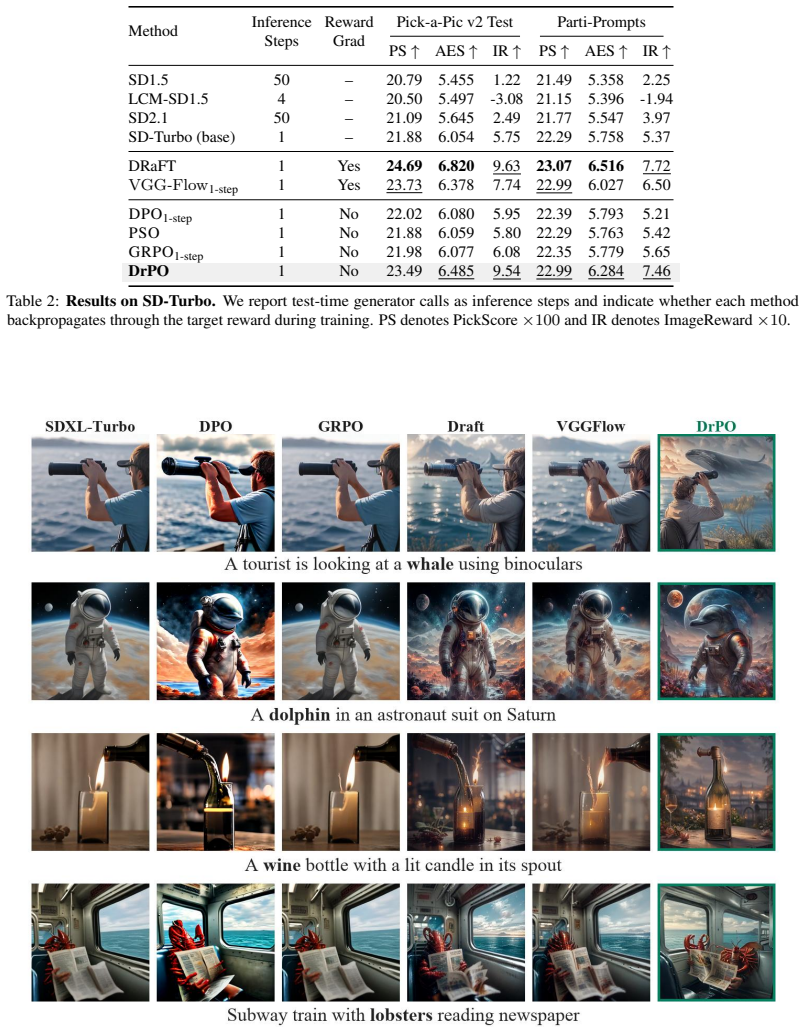
- Alignment metrics improve over reward-gradient-free one-step baselines on HPSv3 and GenEval.
- HPSv3 training computation falls by 3.51× because reward-model backpropagation is eliminated.
- Any black-box or non-differentiable reward can be used since it supplies only ranking.
- Inference cost remains one generator forward pass after training.
Where Pith is reading between the lines
- The same sample-based gradient synthesis might transfer to other deterministic generators beyond text-to-image.
- Offline variants could pre-compute dipole fields from existing ranked datasets without online sampling.
- The detached regression target may reduce sensitivity to reward scale compared with direct gradient methods.
Load-bearing premise
The dipole field synthesized from ranked samples and the reference drift together give a stable optimization signal for the deterministic one-step generator.
What would settle it
Run DrPO on SD-Turbo with a non-differentiable reward and measure whether alignment metrics rise above the reward-gradient-free baselines while training FLOPs drop by roughly 3.5× under matched effective batch size.
Figures







read the original abstract
One-step text-to-image generators are attractive for deployment because they generate an image with a single forward pass, but preference finetuning them remains difficult: standard alignment methods often rely on policy likelihoods, denoising trajectories, differentiable reward gradients, or test-time optimization. We propose Drifting Preference Optimization (DrPO), an online preference-finetuning method for deterministic one-step generators. For each prompt, DrPO samples candidates from the current generator, ranks them with a target reward, and uses high- and low-scoring samples to synthesize a feature-space update direction. The update is a non-parametric dipole preference field plus a reference drift estimated from the frozen base generator, and is optimized through a detached feature-space regression target. The target reward is used only for ranking, so DrPO can train with large, black-box, or non-differentiable rewards while inference remains a single generator call. We evaluate DrPO on SD-Turbo and SDXL-Turbo with multiple target rewards and benchmarks, including HPSv3 and GenEval. DrPO improves alignment over reward-gradient-free one-step preference baselines and reduces HPSv3 training computation by $3.51\times$ under the matched effective-batch setting by removing reward-model backpropagation. Initial offline experiments suggest that sample-based gradient synthesis can also be used beyond online reward ranking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Drifting Preference Optimization (DrPO), an online preference finetuning method for deterministic one-step text-to-image generators such as SD-Turbo and SDXL-Turbo. For each prompt, the method samples candidates from the current model, ranks them using a target reward model, constructs a non-parametric dipole preference field from high- and low-scoring samples together with a reference drift from the frozen base generator, and optimizes the generator via detached feature-space regression. The reward is used solely for ranking, enabling training with large, black-box, or non-differentiable rewards while keeping inference to a single forward pass. Experiments report improved alignment over reward-gradient-free baselines and a 3.51× reduction in HPSv3 training compute under matched effective-batch size by eliminating reward-model backpropagation; limited offline experiments are also mentioned.
Significance. If the central construction is shown to produce a reliable alignment signal, DrPO would offer a practical route to preference tuning of one-step generators without requiring differentiable rewards or backpropagation through the reward model. This would directly support the use of larger or non-differentiable reward functions and yield the reported computational savings. The approach also opens a direction for sample-based gradient synthesis that may extend beyond online ranking.
major comments (3)
- [Abstract] Abstract: the central claim that regression onto the synthesized non-parametric dipole preference field plus reference drift yields an effective update direction for reward maximization lacks any derivation or analysis showing monotonicity or even positive correlation with the true reward gradient in feature space. No equation or section establishes when the dipole direction could be orthogonal or anti-correlated with the reward signal.
- [Abstract] Abstract and evaluation sections: quantitative gains are stated on named models and benchmarks, yet the text provides neither error bars nor an ablation isolating the contribution of the dipole construction versus the reference drift or the detached regression target. This leaves the source of the reported alignment improvement and the 3.51× compute reduction unverified.
- [Abstract] Abstract: the statement that DrPO 'reduces HPSv3 training computation by 3.51× under the matched effective-batch setting' requires an explicit definition of how effective batch size is computed once reward-model backpropagation is removed; without it the compute comparison cannot be reproduced or assessed for fairness.
minor comments (2)
- [Abstract] The abstract mentions 'initial offline experiments' but does not indicate whether these results appear in the main body, appendix, or are omitted; a pointer would improve clarity.
- [Abstract] Notation for the 'non-parametric dipole preference field' and 'reference drift' is introduced without an accompanying equation or pseudocode block; adding a compact definition would aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and describe the revisions we will make to address the concerns.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that regression onto the synthesized non-parametric dipole preference field plus reference drift yields an effective update direction for reward maximization lacks any derivation or analysis showing monotonicity or even positive correlation with the true reward gradient in feature space. No equation or section establishes when the dipole direction could be orthogonal or anti-correlated with the reward signal.
Authors: We agree that a formal analysis is missing from the current manuscript. The dipole construction is motivated by the geometric intuition that the vector between high- and low-reward samples in feature space approximates a direction of reward increase, stabilized by the base-model drift. In the revision we will add a dedicated analysis subsection deriving the expected inner product between the dipole direction and the true reward gradient under a linear reward assumption in feature space, and explicitly discuss conditions (e.g., non-linear reward or insufficient sample diversity) under which the direction could become orthogonal or anti-correlated. revision: yes
-
Referee: [Abstract] Abstract and evaluation sections: quantitative gains are stated on named models and benchmarks, yet the text provides neither error bars nor an ablation isolating the contribution of the dipole construction versus the reference drift or the detached regression target. This leaves the source of the reported alignment improvement and the 3.51× compute reduction unverified.
Authors: The current version indeed reports point estimates without error bars and does not contain ablations that isolate the dipole field, reference drift, and detached regression. We will revise the evaluation section to report means and standard deviations over at least three independent runs for all main metrics. We will also add a new ablation table that measures performance when each component (dipole, drift, detached target) is removed or replaced, thereby clarifying the source of both the alignment gains and the compute savings. revision: yes
-
Referee: [Abstract] Abstract: the statement that DrPO 'reduces HPSv3 training computation by 3.51× under the matched effective-batch setting' requires an explicit definition of how effective batch size is computed once reward-model backpropagation is removed; without it the compute comparison cannot be reproduced or assessed for fairness.
Authors: We acknowledge that the abstract statement is not self-contained. In the revised manuscript we will add a precise definition of effective batch size in the experimental setup (and cross-reference it from the abstract), specifying that it is computed from the number of generator forward passes per optimization step once reward-model backpropagation is eliminated, and we will show the arithmetic that yields the 3.51× factor under the matched setting. revision: yes
Circularity Check
No circularity; derivation self-contained via external sample ranking and frozen reference
full rationale
The abstract and description define DrPO explicitly as sampling from the current generator, ranking with an external target reward, synthesizing a non-parametric dipole field plus reference drift from the frozen base, and optimizing via detached feature-space regression. The reward is used solely for ranking and never back-propagated; no equation, parameter fit, or self-citation is shown that reduces the update direction or claimed gains to a quantity defined inside the paper by construction. The central construction therefore remains independent of its own outputs and is evaluated against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The target generator is deterministic and produces an image in a single forward pass.
invented entities (1)
-
non-parametric dipole preference field
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:1707.06347 , year =
Proximal Policy Optimization Algorithms , author =. arXiv preprint arXiv:1707.06347 , year =
-
[2]
NeurIPS , year =
Learning to Summarize with Human Feedback , author =. NeurIPS , year =
-
[3]
NeurIPS , year =
Training Language Models to Follow Instructions with Human Feedback , author =. NeurIPS , year =
-
[4]
Constitutional
Bai, Yuntao and Kadavath, Saurav and Kundu, Sandipan and Askell, Amanda and Kernion, Jackson and Jones, Andy and Chen, Anna and Goldie, Anna and Mirhoseini, Azalia and McKinnon, Cameron and others , journal =. Constitutional
-
[5]
NeurIPS , year =
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author =. NeurIPS , year =
-
[6]
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Bi, Xiao and Zhang, Haowei and Zhang, Mingchuan and Li, Y. K. and Wu, Y. and Guo, Daya , journal =
-
[7]
Transactions on Machine Learning Research , year =
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation , author =. Transactions on Machine Learning Research , year =
-
[8]
CVPR , year =
High-Resolution Image Synthesis with Latent Diffusion Models , author =. CVPR , year =
-
[9]
ICLR , year =
Podell, Dustin and English, Zion and Lacey, Kyle and Blattmann, Andreas and Dockhorn, Tim and M. ICLR , year =
-
[10]
arXiv preprint arXiv:2310.04378 , year =
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference , author =. arXiv preprint arXiv:2310.04378 , year =
-
[11]
ECCV , year =
Adversarial Diffusion Distillation , author =. ECCV , year =
-
[12]
CVPR , year =
Diffusion Model Alignment Using Direct Preference Optimization , author =. CVPR , year =
-
[13]
ICLR , year =
Directly Fine-Tuning Diffusion Models on Differentiable Rewards , author =. ICLR , year =
-
[14]
Eyring, Luca and Karthik, Shyamgopal and Roth, Karsten and Dosovitskiy, Alexey and Akata, Zeynep , booktitle =
-
[15]
arXiv preprint arXiv:2404.00879 , year =
Model-Agnostic Human Preference Inversion in Diffusion Models , author =. arXiv preprint arXiv:2404.00879 , year =
-
[16]
CVPR , year =
Aesthetic Post-Training Diffusion Models from Generic Preferences with Step-by-step Preference Optimization , author =. CVPR , year =
-
[17]
CVPR , year =
Curriculum Direct Preference Optimization for Diffusion and Consistency Models , author =. CVPR , year =
-
[18]
ICLR , year =
Tuning Timestep-Distilled Diffusion Model Using Pairwise Sample Optimization , author =. ICLR , year =
-
[19]
Luo, Weijian , journal =
-
[20]
ICML , year =
David and Goliath: Small One-step Model Beats Large Diffusion with Score Post-training , author =. ICML , year =
-
[21]
ICCV , year =
Adding Additional Control to One-Step Diffusion with Joint Distribution Matching , author =. ICCV , year =
-
[22]
NeurIPS , year =
Reward-Instruct: A Reward-Centric Approach to Fast Photo-Realistic Image Generation , author =. NeurIPS , year =
-
[23]
ICLR , year =
Scaling Group Inference for Diverse and High-Quality Generation , author =. ICLR , year =
-
[24]
arXiv preprint arXiv:2602.18799 , year =
Rethinking Preference Alignment for Diffusion Models with Classifier-Free Guidance , author =. arXiv preprint arXiv:2602.18799 , year =
-
[25]
arXiv preprint arXiv:2602.04770 , year =
Generative Modeling via Drifting , author =. arXiv preprint arXiv:2602.04770 , year =
-
[26]
arXiv preprint arXiv:2602.20463 , year =
A Long-Short Flow-Map Perspective for Drifting Models , author =. arXiv preprint arXiv:2602.20463 , year =
-
[27]
arXiv preprint arXiv:2603.07514 , year =
A Unified View of Drifting and Score-Based Models , author =. arXiv preprint arXiv:2603.07514 , year =
-
[28]
arXiv preprint arXiv:2603.09936 , year =
Generative Drifting is Secretly Score Matching: a Spectral and Variational Perspective , author =. arXiv preprint arXiv:2603.09936 , year =
-
[29]
Gradient Flow Drifting: Generative Modeling via
Cao, Jiarui and Wei, Zixuan and Liu, Yuxin , journal =. Gradient Flow Drifting: Generative Modeling via
-
[30]
arXiv preprint arXiv:2603.12366 , year =
Sinkhorn-Drifting Generative Models , author =. arXiv preprint arXiv:2603.12366 , year =
-
[31]
arXiv preprint arXiv:2604.06333 , year =
Drifting Fields are not Conservative , author =. arXiv preprint arXiv:2604.06333 , year =
-
[32]
Attraction, Repulsion, and Friction: Introducing
Kazanskii, Arkadii and Petrova, Tatiana and Bagrianskii, Konstantin and Puzikov, Aleksandr and State, Radu , journal =. Attraction, Repulsion, and Friction: Introducing
-
[33]
Heusel, Martin and Ramsauer, Hubert and Unterthiner, Thomas and Nessler, Bernhard and Hochreiter, Sepp , booktitle =
-
[34]
Schuhmann, Christoph , year =
-
[35]
NeurIPS , year =
Pick-a-Pic: An Open Dataset of User Preferences for Text-to-Image Generation , author =. NeurIPS , year =
-
[36]
Xu, Jiazheng and Liu, Xiao and Wu, Yuchen and Tong, Yuxuan and Li, Qinkai and Ding, Ming and Tang, Jie and Dong, Yuxiao , booktitle =
-
[37]
arXiv preprint arXiv:2306.09341 , year =
Human Preference Score v2: A Solid Benchmark for Evaluating Human Preferences of Text-to-Image Synthesis , author =. arXiv preprint arXiv:2306.09341 , year =
-
[38]
Ghosh, Dhruba and Hajishirzi, Hannaneh and Schmidt, Ludwig , booktitle =
-
[39]
Ma, Yuhang and Wu, Xiaoshi and Sun, Keqiang and Li, Hongsheng , booktitle =
-
[40]
ICML , year =
Learning Transferable Visual Models From Natural Language Supervision , author =. ICML , year =
-
[41]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =
-
[42]
Transactions on Machine Learning Research , year =
Oquab, Maxime and Darcet, Timoth. Transactions on Machine Learning Research , year =
-
[43]
arXiv preprint arXiv:2512.05116 , year =
Value Gradient Guidance for Flow Matching Alignment , author =. arXiv preprint arXiv:2512.05116 , year =
-
[44]
arXiv preprint arXiv:2207.12598 , year =
Classifier-free diffusion guidance , author =. arXiv preprint arXiv:2207.12598 , year =
-
[45]
CVPR , year =
Masked autoencoders are scalable vision learners , author =. CVPR , year =
-
[46]
arXiv preprint arXiv:2505.13447 , year =
Mean flows for one-step generative modeling , author =. arXiv preprint arXiv:2505.13447 , year =
-
[47]
ICML , year =
Stylegan-t: Unlocking the power of gans for fast large-scale text-to-image synthesis , author =. ICML , year =
-
[48]
CVPR , year =
One-step diffusion with distribution matching distillation , author =. CVPR , year =
-
[49]
ICML , year =
Consistency Models , author =. ICML , year =
-
[50]
arXiv preprint arXiv:2011.13456 , year =
Score-based generative modeling through stochastic differential equations , author =. arXiv preprint arXiv:2011.13456 , year =
Pith/arXiv arXiv 2011
-
[51]
NeurIPS , year =
Denoising diffusion probabilistic models , author =. NeurIPS , year =
-
[52]
arXiv preprint arXiv:2511.13649 , year =
Distribution matching distillation meets reinforcement learning , author =. arXiv preprint arXiv:2511.13649 , year =
-
[53]
arXiv preprint arXiv:2604.19009 , year =
Guiding Distribution Matching Distillation with Gradient-Based Reinforcement Learning , author =. arXiv preprint arXiv:2604.19009 , year =
-
[54]
CVPR , year =
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric , author =. CVPR , year =
-
[55]
arXiv preprint arXiv:2410.11081 , year =
Simplifying, stabilizing and scaling continuous-time consistency models , author =. arXiv preprint arXiv:2410.11081 , year =
-
[56]
NeurIPS , year =
Improved distribution matching distillation for fast image synthesis , author =. NeurIPS , year =
-
[57]
CVPR , year =
Swiftbrush: One-step text-to-image diffusion model with variational score distillation , author =. CVPR , year =
-
[58]
ICML , year =
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor , author =. ICML , year =
-
[59]
arXiv preprint arXiv:2511.21631 , year =
-
[60]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages =
TIFA: Accurate and Interpretable Text-to-Image Faithfulness Evaluation with Question Answering , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages =
-
[61]
arXiv preprint arXiv:2404.01291 , year =
Evaluating Text-to-Visual Generation with Image-to-Text Generation , author =. arXiv preprint arXiv:2404.01291 , year =
-
[62]
2024 , doi =
Ku, Max and Jiang, Dongfu and Wei, Cong and Yue, Xiang and Chen, Wenhu , booktitle =. 2024 , doi =
2024
-
[63]
Findings of the Association for Computational Linguistics: ACL 2024 , pages =
Prometheus-Vision: Vision-Language Model as a Judge for Fine-Grained Evaluation , author =. Findings of the Association for Computational Linguistics: ACL 2024 , pages =. 2024 , doi =
2024
-
[64]
Advances in Neural Information Processing Systems , volume =
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , author =. Advances in Neural Information Processing Systems , volume =
-
[65]
Judging the Judges: A Systematic Study of Position Bias in
Shi, Lin and Ma, Chiyu and Liang, Wenhua and Diao, Xingjian and Ma, Weicheng and Vosoughi, Soroush , booktitle =. Judging the Judges: A Systematic Study of Position Bias in. 2025 , doi =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.