Do Large Language Models Always Tell The Same Stories?
Pith reviewed 2026-06-27 02:54 UTC · model grok-4.3
The pith
Large language models produce stories more similar to each other than human authors do.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
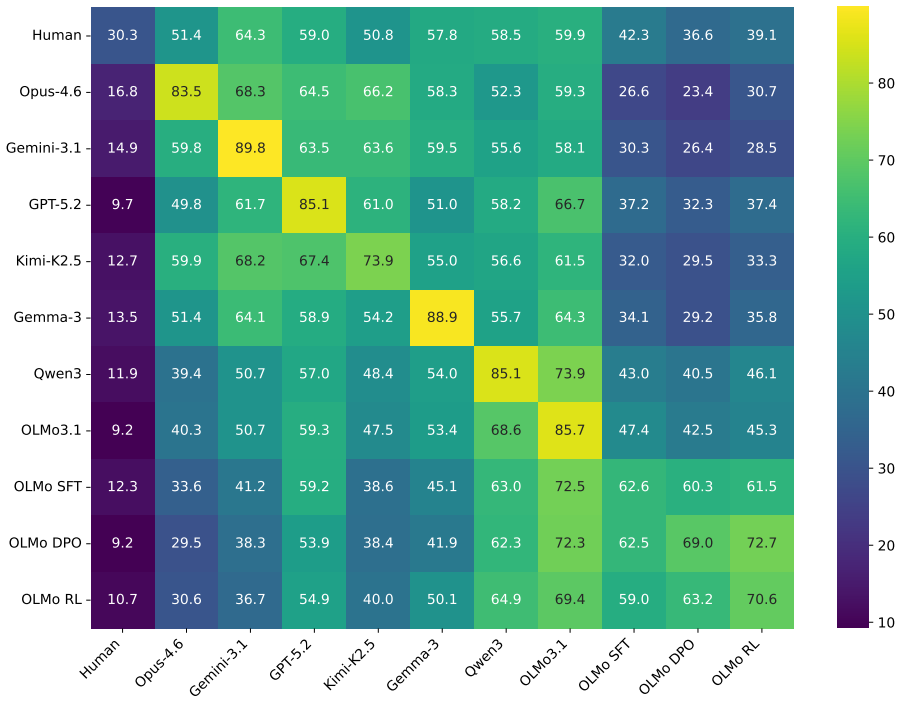
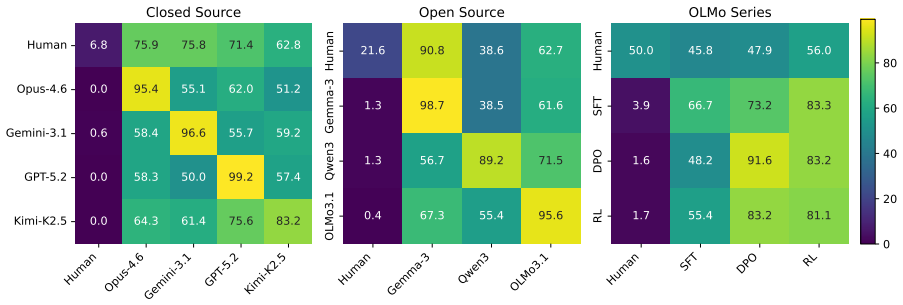
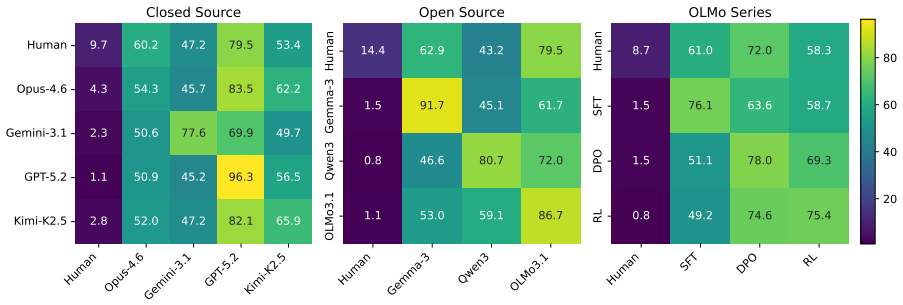
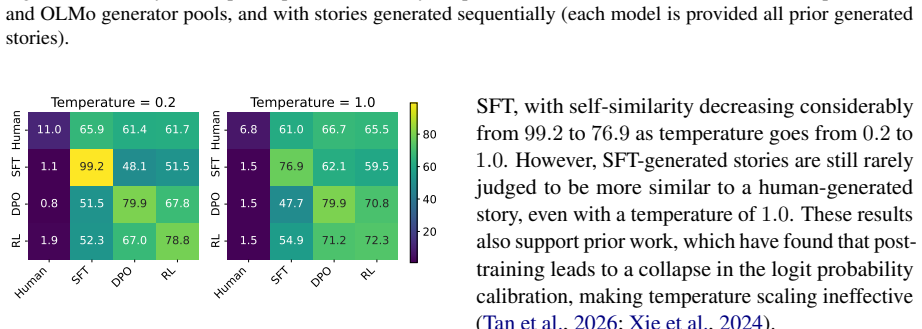
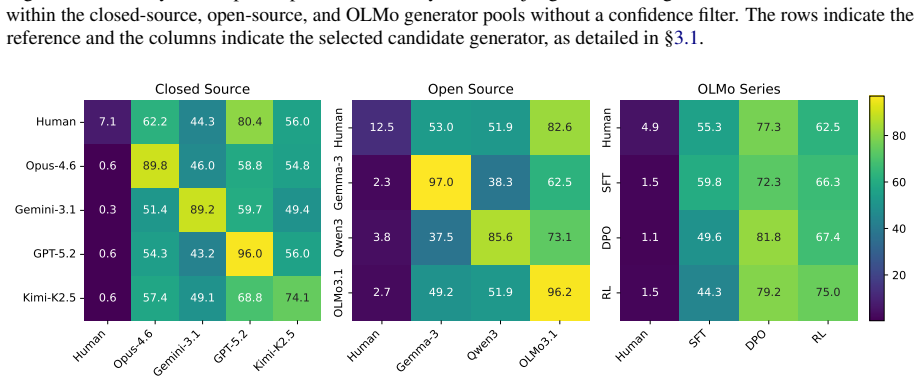
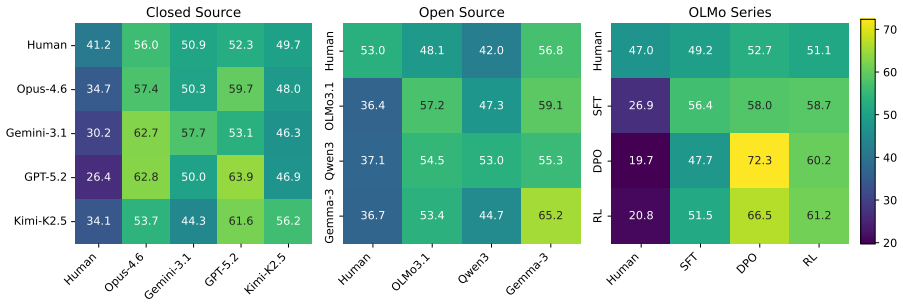
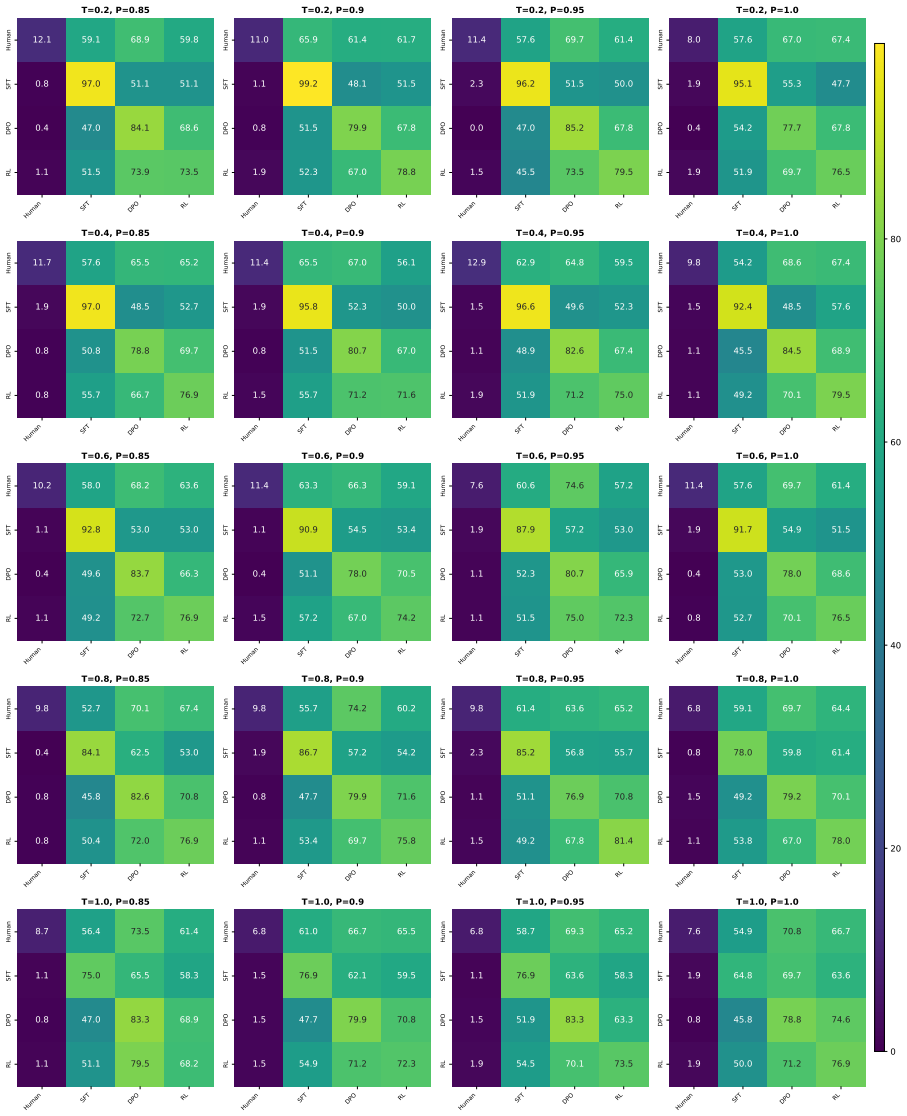
Using a contrastive framework and a dataset of human-written stories and prompts from r/WritingPrompts, the study collects narrative similarity judgments across 10 representative LLMs, utilizing both human evaluations and three different automatic annotation methods. The findings reveal a consistent trend: LLM-generated narratives are consistently more similar to each other than human-written stories are. Frontier models in particular converge on a mean generic narrative that approximates individual human stories but lacks the collective diversity of human authors. Common mitigation strategies, including negative prompting and temperature scaling, fail to meaningfully address this homogeneit
What carries the argument
Narrative similarity judgments collected from human raters and three automatic methods on stories generated from shared prompts.
If this is right
- LLM outputs cluster more tightly than human stories do across the tested models.
- Frontier models converge toward a single generic narrative rather than matching human variety.
- Negative prompting and temperature scaling leave the observed homogeneity largely unchanged.
- The pattern holds when similarity is measured by both people and automatic methods.
Where Pith is reading between the lines
- Repeated use of the same model for creative tasks may yield less variety than commissioning multiple human writers.
- The convergence could stem from training objectives that reward responses close to an average of the training data.
- Similar homogeneity might appear in other open-ended generation tasks such as dialogue or world-building.
Load-bearing premise
The chosen similarity judgments measure meaningful differences in story content and style rather than only surface features.
What would settle it
A model that produces story sets whose pairwise similarities are lower than those among human stories on the same prompts would contradict the central finding.
Figures








read the original abstract
Recent advances in large language models (LLMs) have enabled the generation of high-quality prose, yet the question of whether these models are capable of generating diverse outputs remains contested. In this work, we investigate the diversity of LLM-generated stories through the framework of narrative similarity. Using a contrastive framework and a dataset of human-written stories and prompts from r/WritingPrompts, we collect narrative similarity judgments across 10 representative LLMs, utilizing both human evaluations and three different automatic annotation methods. Our findings reveal a consistent trend: LLM-generated narratives are consistently more similar to each other than human-written stories are. We demonstrate that frontier models in particular converge on a ``mean'' generic narrative that approximates individual human stories but lacks the collective diversity of human authors. Finally, we show that common mitigation strategies, including negative prompting and temperature scaling, fail to meaningfully address this homogeneity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLM-generated narratives are consistently more similar to each other than human-written stories, based on a contrastive framework using r/WritingPrompts data. It collects narrative similarity judgments from human evaluators and three automatic methods across 10 LLMs, concluding that frontier models converge on a 'mean' generic narrative approximating individual human stories but lacking collective human diversity, and that mitigation strategies like negative prompting and temperature scaling do not resolve the homogeneity.
Significance. If the central empirical claim holds after rigorous validation, the result would highlight a meaningful limitation in current LLMs for creative generation tasks, indicating reduced narrative diversity relative to human authors. The use of both human judgments and multiple automatic methods, along with the contrastive setup on real prompt data, provides a reasonable empirical foundation, though the absence of reported validation details limits immediate assessment of robustness.
major comments (2)
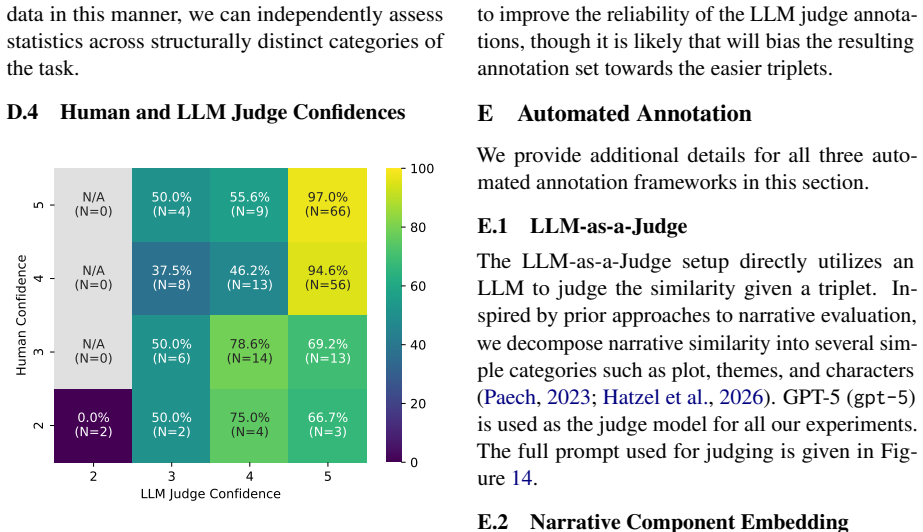
- [Abstract] Abstract/Methods: No details are given on dataset size, prompt construction from r/WritingPrompts, inter-annotator agreement for human evaluations, or how the three automatic annotation methods were validated against human judgments. These elements are load-bearing for the central claim that similarity measures demonstrate LLM homogeneity, as the reader's assessment notes soundness at 3.0 due to this omission.
- [Methods] Methods/Results: The contrastive framework does not isolate the risk that automatic methods (e.g., embeddings or LLM judges) may rate LLM outputs as more similar due to training data overlap rather than true differences in plot, character arcs, or event sequences. This directly affects the validity of the 'mean generic narrative' conclusion, as noted in the stress-test concern.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below and plan to make revisions accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract/Methods: No details are given on dataset size, prompt construction from r/WritingPrompts, inter-annotator agreement for human evaluations, or how the three automatic annotation methods were validated against human judgments. These elements are load-bearing for the central claim that similarity measures demonstrate LLM homogeneity, as the reader's assessment notes soundness at 3.0 due to this omission.
Authors: We acknowledge the omission of these details in the current manuscript. Upon revision, we will include comprehensive information on the dataset size and prompt construction process from r/WritingPrompts. We will also report inter-annotator agreement for the human evaluations and provide validation results for the automatic methods against human judgments to substantiate the reliability of our similarity measures. revision: yes
-
Referee: [Methods] Methods/Results: The contrastive framework does not isolate the risk that automatic methods (e.g., embeddings or LLM judges) may rate LLM outputs as more similar due to training data overlap rather than true differences in plot, character arcs, or event sequences. This directly affects the validity of the 'mean generic narrative' conclusion, as noted in the stress-test concern.
Authors: We appreciate this point about potential confounds in automatic similarity measures. Our study relies on human judgments as the gold standard, which are unaffected by training data overlap. The automatic methods were validated to align with human judgments, and the homogeneity trend holds across both. In the revised paper, we will add a discussion of this limitation and its implications for interpreting the automatic results, while emphasizing that the core findings are robust due to the human evaluation component. revision: partial
Circularity Check
No circularity: empirical observations from collected judgments
full rationale
The paper reports an empirical study collecting narrative similarity judgments (human plus three automatic methods) on LLM vs. human stories from r/WritingPrompts. No derivation chain, first-principles result, or prediction is claimed; the central finding is a direct statistical observation from the gathered data. No self-definitional relations, fitted inputs presented as predictions, or load-bearing self-citations appear in the abstract or described framework. The work is self-contained as an empirical measurement exercise.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
SemEval-2026 Task 4: Narrative Story Similarity and Narrative Representation Learning
Narrative Similarity – Annotation Guidelines. Hans Ole Hatzel, Ekaterina Artemova, Haimo Paul Stiemer, Evelyn Gius, and Chris Biemann. 2026. SemEval-2026 Task 4: Narrative Story Similarity and Narrative Representation Learning.Preprint, arXiv:2604.21782. Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. 2020. The Curious Case of Neural Text D...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
LLMs generate kitsch.arXiv preprint arXiv:2604.25929. Jinhyuk Lee, Feiyang Chen, Sahil Dua, Daniel Cer, Madhuri Shanbhogue, Iftekhar Naim, Gus- tavo Hernández Ábrego, Zhe Li, Kaifeng Chen, Hen- rique Schechter Vera, Xiaoqi Ren, Shanfeng Zhang, Daniel Salz, Michael Boratko, Jay Han, Blair Chen, Shuo Huang, Vikram Rao, Paul Suganthan, and 28 others. 2025. G...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Beyond Divergent Creativity: A Human-Based Evaluation of Creativity in Large Language Models. InFindings of the Association for Computational Linguistics: EACL 2026, pages 2639–2660, Rabat, Morocco. Association for Computational Linguistics. Surabhi S. Nath, Guiomar del Cuvillo y Schršder, and Claire Stevenson. 2025. Pencils to Pixels: A Sys- tematic Stud...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Avoidance Decoding for Diverse Multi-Branch Story Generation. InProceedings of the 2025 Con- ference on Empirical Methods in Natural Language Processing, pages 7489–7505, Suzhou, China. Asso- ciation for Computational Linguistics. Arkadiy Saakyan, Najoung Kim, Smaranda Muresan, and Tuhin Chakrabarty. 2026. Death of the Novel(ty): Beyond n-Gram Novelty as ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
A Survey on LLMs for Story Generation. In Findings of the Association for Computational Lin- guistics: EMNLP 2025, pages 13954–13966, Suzhou, China. Association for Computational Linguistics. 10 Yufei Tian, Tenghao Huang, Miri Liu, Derek Jiang, Alexander Spangher, Muhao Chen, Jonathan May, and Nanyun Peng. 2024a. Are Large Language Mod- els Capable of Gen...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Read theReference Storycarefully, noting its key narrative elements
-
[7]
ReadStory AandStory Bcompletely
-
[8]
Compare each candidate’s narrative structure to the reference
-
[9]
Select which story (A or B) is more narratively similar
-
[10]
faithful, loyal man
Rate your confidence (1-5) in this choice. Narrative Similarity The narrative similarity of stories can be broken down into three core aspects: (1) the abstract themes of the story, (2) the course of action, and (3) the story outcomes. At one extreme, this means that the story deals with the same themes and tells the same order of events with an identical...
-
[11]
On the week-long journey from Europe to the Americas, the crew members get into a heated conflict about the best ration packages
Overall abstract theme: Describe in brief the central ideas, core motifs and defining constellation of problems. For example, in both these stories: A: "On the week-long journey from Europe to the Americas, the crew members get into a heated conflict about the best ration packages." B: "The flight to Mars is long. After several weeks, the astronauts becom...
-
[12]
After the ship capsizes and Alice barely makes it out alive, she starts living life to the fullest with a new-found perspective about how precious life is
Course of action/events: Describe in brief the sequence of events that actually hap- pens in the story. For example, in the following stories: A: "After the ship capsizes and Alice barely makes it out alive, she starts living life to the fullest with a new-found perspective about how precious life is." Events: Alice’s ship capsizes. Alice barely makes it ...
-
[13]
Anna loses her purse. She retraces her steps but cannot find it. Dan finds it and helpfully returns it to her
The outcomes: Describe in brief the final ending or outcomes of the story. For exam- ple, in the following stories: A: "Anna loses her purse. She retraces her steps but cannot find it. Dan finds it and helpfully returns it to her." Outcome: Someone finds a lost item and returns to owner. B: "Brian lost his backpack. He was terrified because there were imp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.