ELASTIC: Efficiently Learning to Adaptively Scale Test-Time Compute for Generative Control Policies
Pith reviewed 2026-07-01 05:42 UTC · model grok-4.3
The pith
A meta-policy learns to allocate sequential and parallel test-time compute for generative robot policies to raise success at fixed budgets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
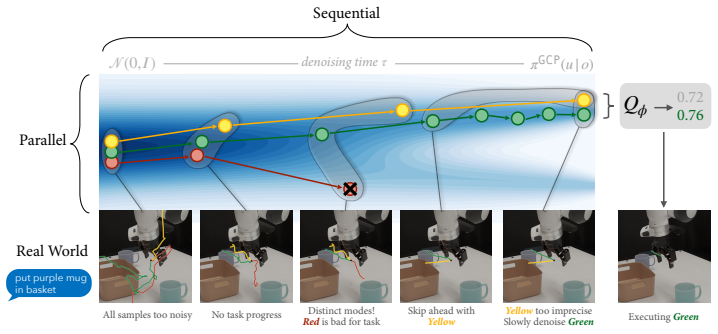
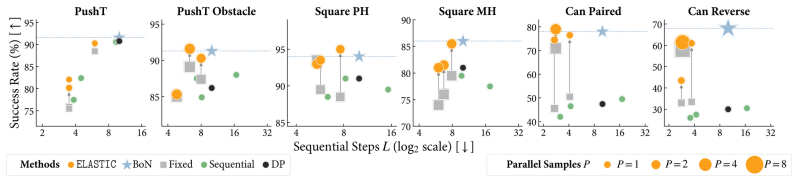
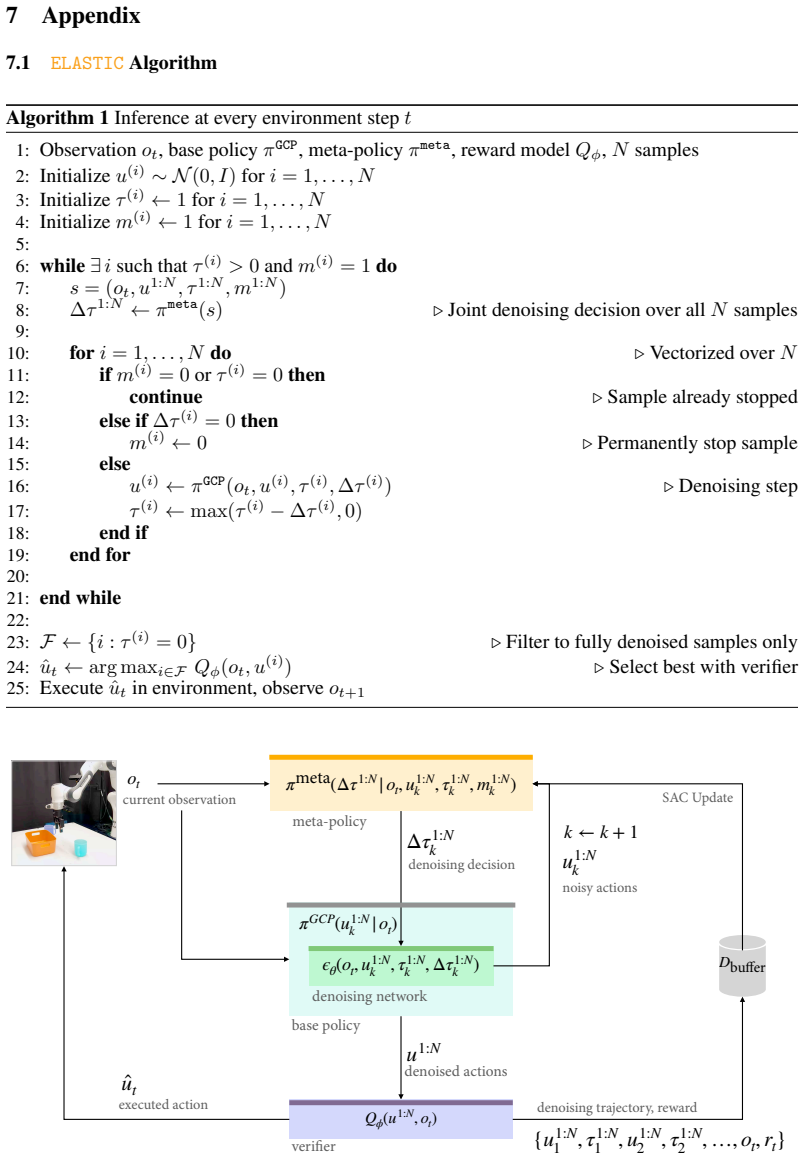
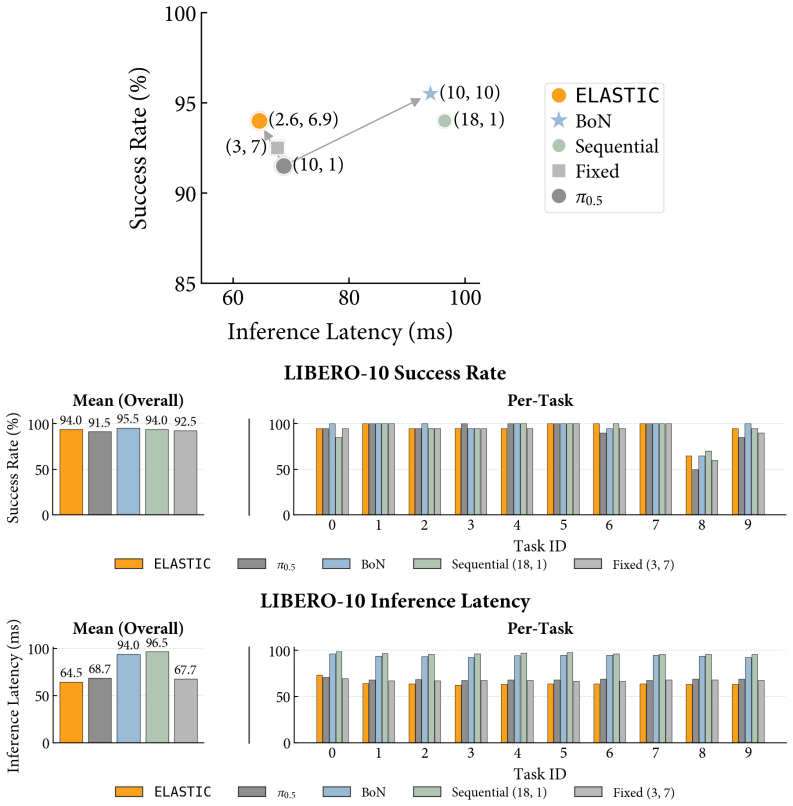
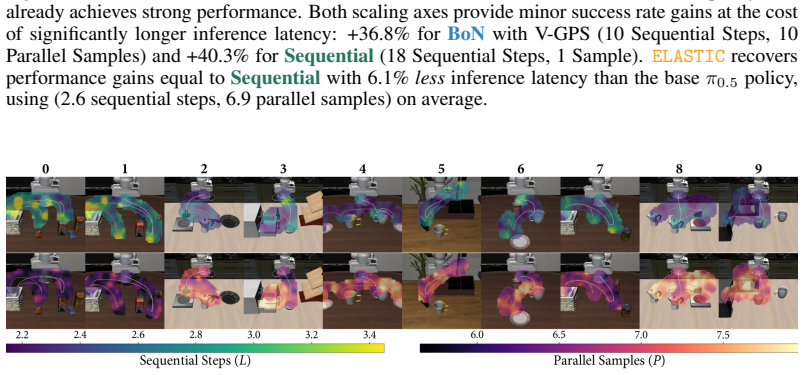
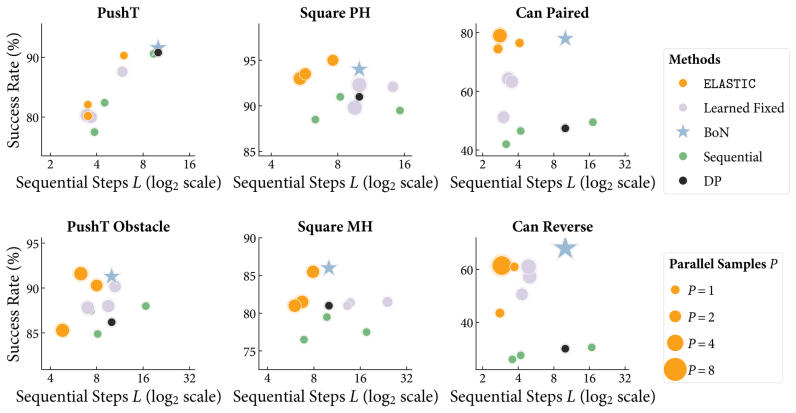
ELASTIC formulates compute allocation as a meta-Markov Decision Process in which a meta-policy interacts with a frozen pretrained robot policy and selects sequential steps and parallel samples at each denoising iteration to maximize task success while minimizing compute. Using reinforcement learning, this meta-policy learns adaptive compute schedules without access to the GCP's training data. Across simulated manipulation benchmarks with diffusion policies, ELASTIC Pareto-dominates fixed and single-axis scaling baselines at matched compute budgets. On real-world robot manipulation, ELASTIC matches best-of-10 success while reducing wall-clock latency by 34%.
What carries the argument
The meta-Markov Decision Process in which the meta-policy chooses sequential denoising steps and parallel action samples to interact with a frozen generative control policy.
If this is right
- Adaptive schedules Pareto-dominate fixed and single-axis scaling at matched compute budgets on simulated manipulation tasks.
- The approach achieves equivalent success to best-of-10 sampling while cutting wall-clock latency by 34 percent on real robot manipulation.
- The meta-policy learns without access to the generative policy's training data or extra reward shaping.
Where Pith is reading between the lines
- The same meta-MDP framing could be applied to test-time scaling in other generative models such as language or image generators.
- Jointly optimizing the base policy and the meta-policy might yield further gains beyond the current frozen-base setting.
- State-dependent scaling may prove especially useful in tasks whose precision demands change sharply across phases.
Load-bearing premise
The reinforcement learning procedure lets the meta-policy discover useful compute schedules using only task success as the reward signal.
What would settle it
If a new manipulation task shows that the learned meta-policy needs strictly more total compute than the best fixed schedule to reach the same success rate, the central claim is falsified.
Figures


read the original abstract
Generative control policies (GCPs), such as diffusion policies and flow-based vision-language-action models, enable test-time scaling in robot control. Test-time compute can be allocated along two axes: sequential scaling, which increases denoising steps to refine actions, and parallel scaling, which samples multiple candidate actions to search across modes of the policy distribution. However, the optimal allocation of sequential and parallel compute is hard to know a priori as it is state-, task-, and policy-dependent. For example, early stages of a grasp may benefit from broader parallel exploration, while near-contact phases may require more sequential refinement for precision. We present ELASTIC, an algorithm that learns state-dependent test-time compute schedules for GCPs. We formulate compute allocation as a meta-Markov Decision Process in which a meta-policy interacts with a frozen pretrained robot policy and selects sequential steps and parallel samples at each denoising iteration to maximize task success while minimizing compute. Using reinforcement learning, this meta-policy also learns adaptive compute schedules without access to the GCP's training data. Across simulated manipulation benchmarks with diffusion policies, ELASTIC Pareto-dominates fixed and single-axis scaling baselines at matched compute budgets. On real-world robot manipulation with the $\pi_{0.5}$ vision-language-action model, ELASTIC matches best-of-$10$ success while reducing wall-clock latency by 34%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ELASTIC, which formulates test-time compute allocation for generative control policies (diffusion policies and vision-language-action models) as a meta-Markov Decision Process. A meta-policy is trained via reinforcement learning on a frozen pretrained GCP to select state-dependent sequential denoising steps and parallel samples at each iteration, using only terminal task success as reward and without access to the GCP's original training data. The central empirical claim is that the resulting adaptive schedules Pareto-dominate fixed and single-axis scaling baselines on simulated manipulation tasks at matched compute budgets, and on real-robot manipulation with the π0.5 model they match best-of-10 success while cutting wall-clock latency by 34%.
Significance. If the reported results are reproducible, the work shows that RL on a meta-MDP can discover non-trivial adaptive compute schedules for GCPs that improve the efficiency-performance trade-off in robot manipulation without requiring access to the base policy's training distribution or shaped rewards.
major comments (1)
- [Methods (meta-MDP and RL procedure)] The meta-MDP formulation and RL procedure (described in the methods) receive only terminal binary success and interact solely with the frozen GCP. No mechanism is shown for how credit assignment across the denoising trajectory produces state-dependent schedules that outperform fixed baselines rather than collapsing to near-constant allocation; this is load-bearing for the Pareto-dominance claim.
minor comments (1)
- [Abstract] The abstract states concrete performance numbers (Pareto dominance, 34% latency reduction) but supplies no experimental protocol, reward definition, training curves, or statistical tests; these details should be summarized in the abstract or a dedicated experimental setup subsection for immediate assessability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment on the meta-MDP formulation, RL procedure, and credit assignment below.
read point-by-point responses
-
Referee: [Methods (meta-MDP and RL procedure)] The meta-MDP formulation and RL procedure (described in the methods) receive only terminal binary success and interact solely with the frozen GCP. No mechanism is shown for how credit assignment across the denoising trajectory produces state-dependent schedules that outperform fixed baselines rather than collapsing to near-constant allocation; this is load-bearing for the Pareto-dominance claim.
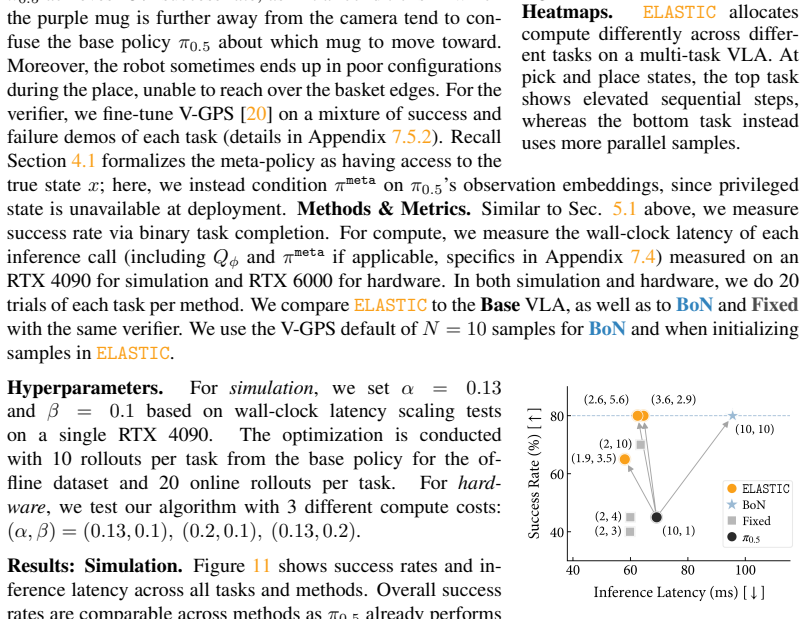
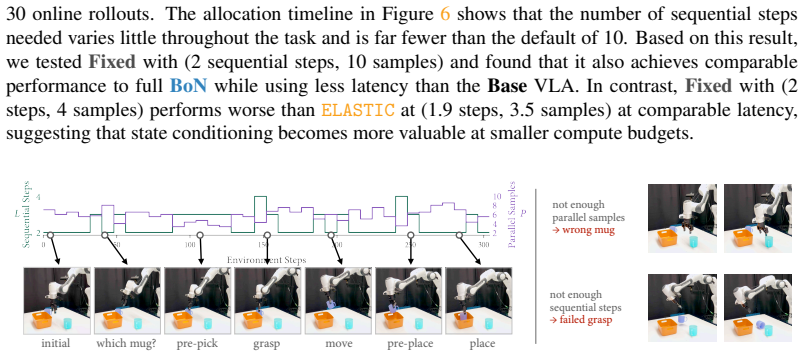
Authors: We agree that the manuscript would benefit from a clearer explanation of how credit assignment enables non-constant, state-dependent allocations. The meta-policy state includes the current robot observation and the denoising iteration index. The meta-policy is trained with PPO using generalized advantage estimation on trajectories that receive only terminal binary success; this propagates credit across the sequence of allocation decisions. Because the state representation conditions on both task progress and denoising stage, the learned policy can (and in our experiments does) vary sequential and parallel compute per state rather than collapsing to a fixed schedule. To make this explicit, we will revise the methods section to detail the state features, advantage estimator, and training hyperparameters, and we will add an analysis subsection with visualizations of per-state allocation decisions plus statistics on allocation variance across episodes and tasks. These additions will directly support the Pareto-dominance results. revision: yes
Circularity Check
No circularity; empirical RL procedure on frozen policy
full rationale
The paper formulates compute allocation as a meta-MDP and trains a meta-policy via RL to maximize task success on a frozen GCP. Reported Pareto dominance and latency reductions are measured experimental outcomes across simulation and real-robot benchmarks, not quantities that reduce to fitted inputs or self-citations by construction. No equations, ansatzes, or uniqueness theorems are invoked that would make the success rates tautological; the approach remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion. InProceedings of Robotics: Science and Systems (RSS), 2023
2023
-
[2]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. Vuong, H. Walke...
-
[3]
URLhttps://proceedings.mlr.press/v305/black25a
PMLR, 27–30 Sep 2025. URLhttps://proceedings.mlr.press/v305/black25a. html
2025
-
[4]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. Openvla: An open-source vision-language-action model. In P. Agrawal, O. Kroemer, and W. Burgard, editors,Proceedings of The 8th Conference on Robot Lea...
2025
-
[5]
Ghosh, H
Octo Model Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, C. Xu, J. Luo, T. Kreiman, Y . Tan, L. Y . Chen, P. Sanketi, Q. Vuong, T. Xiao, D. Sadigh, C. Finn, and S. Levine. Octo: An open-source generalist robot policy. InProceedings of Robotics: Science and Systems, Delft, Netherlands, 2024
2024
-
[6]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models. InAd- vances in Neural Information Processing Systems, volume 33, page 6840–6851. Curran Associates, Inc., 2020. URLhttps://proceedings.neurips.cc/paper/2020/hash/ 4c5bcfec8584af0d967f1ab10179ca4b-Abstract.html
2020
-
[7]
J. Song, C. Meng, and S. Ermon. Denoising diffusion implicit models. InInternational Con- ference on Learning Representations, Oct. 2021. URLhttps://openreview.net/forum? id=St1giarCHLP
2021
-
[8]
Lipman, R
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. InInternational Conference on Learning Representations, 2023. URLhttps: //openreview.net/forum?id=PqvMRDCJT9t
2023
-
[9]
Brown, J
B. Brown, J. Juravsky, R. S. Ehrlich, R. Clark, Q. V . Le, C. Re, and A. Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling, 2025. URLhttps: //openreview.net/forum?id=0xUEBQV54B
2025
-
[10]
Prasad, K
A. Prasad, K. Lin, J. Wu, L. Zhou, and J. Bohg. Consistency policy: Accelerated visuomotor policies via consistency distillation. InRobotics: Science and Systems, 2024
2024
-
[11]
C. Lu, Y . Zhou, F. Bao, J. Chen, C. Li, and J. Zhu. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps. InAdvances in Neural Information Pro- cessing Systems, 2022. URLhttps://proceedings.neurips.cc/paper_files/paper/ 2022/hash/260a14acce2a89dad36adc8eefe7c59e-Abstract-Conference.html
2022
-
[12]
X. Hu, B. Liu, X. Liu, and Q. Liu. Adaflow: Imitation learning with variance- adaptive flow-based policies. InAdvances in Neural Information Processing Systems,
-
[13]
URLhttps://proceedings.neurips.cc/paper_files/paper/2024/hash/ fa9cfdb49f7de3dee54007f84c0745b1-Abstract-Conference.html. 10
2024
-
[14]
A. Trivedi, A. Li, M. Elnoor, Y . U. Ciftci, A. Singh, J. D’sa, S. Bae, D. Isele, T. Padir, and F. M. Tariq. Adaptive time step flow matching for autonomous driving motion planning, 2026. URLhttps://arxiv.org/abs/2602.10285
-
[15]
S.-A. Yu, F. Gao, Y . Wu, C. Yu, and Y . Wang. D3p: Dynamic denoising diffusion policy via reinforcement learning. (arXiv:2508.06804), Aug. 2025. doi:10.48550/arXiv.2508.06804. URLhttp://arxiv.org/abs/2508.06804. arXiv:2508.06804 [cs]
-
[16]
Setlur, N
A. Setlur, N. Rajaraman, S. Levine, and A. Kumar. Scaling test-time compute without verifi- cation or RL is suboptimal. InF orty-second International Conference on Machine Learning,
-
[17]
URLhttps://openreview.net/forum?id=beeNgQEfe2
-
[18]
N. Ma, S. Tong, H. Jia, H. Hu, Y .-C. Su, M. Zhang, X. Yang, Y . Li, T. Jaakkola, X. Jia, and S. Xie. Scaling inference time compute for diffusion models. InIEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR), pages 2523–2534, 2025. URLhttps://openaccess.thecvf.com/content/CVPR2025/html/Ma_Scaling_ Inference_Time_Compute_for_Diffusion_...
2025
-
[19]
Damani, I
M. Damani, I. Shenfeld, A. Peng, A. Bobu, and J. Andreas. Learning how hard to think: Input-adaptive allocation of lm computation. InInternational Conference on Learning Repre- sentations, 2025. URLhttps://openreview.net/forum?id=6qUUgw9bAZ
2025
-
[20]
J. Qi, X. Ye, H. Tang, Z. Zhu, and E. Choi. Learning to reason across parallel samples for llm reasoning. (arXiv:2506.09014), Oct. 2025. doi:10.48550/arXiv.2506.09014. URLhttp: //arxiv.org/abs/2506.09014. arXiv:2506.09014 [cs]
-
[21]
J. Kwok, C. Agia, R. Sinha, M. Foutter, S. Li, I. Stoica, A. Mirhoseini, and M. Pavone. Robomonkey: Scaling test-time sampling and verification for vision-language-action models. (arXiv:2506.17811), 2025. doi:10.48550/arXiv.2506.17811. URLhttp://arxiv.org/abs/ 2506.17811. arXiv:2506.17811 [cs]
-
[22]
A. K. Jain, V . Mohta, S. Kim, A. Bhardwaj, J. Ren, Y . Feng, S. Choudhury, and G. Swamy. A smooth sea never made a skilled SAILOR: Robust imitation via learning to search. InAdvances in Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum? id=qN5hmLkBtC
2025
-
[23]
Nakamoto, O
M. Nakamoto, O. Mees, A. Kumar, and S. Levine. Steering your generalists: Improving robotic foundation models via value guidance.Conference on Robot Learning (CoRL), 2024
2024
-
[24]
Y . Wu, R. Tian, G. Swamy, and A. Bajcsy. From foresight to forethought: Vlm-in-the-loop policy steering via latent alignment. InProceedings of Robotics: Science and Systems, 2025. URLhttps://roboticsproceedings.org/rss21/p076.html
2025
-
[25]
Y . Wu, A. Li, T. Hermans, F. Ramos, A. Bajcsy, and C. P ´erez-D’Arpino. Do what you say: Steering vision-language-action models via runtime reasoning-action alignment verification. 2026 IEEE International Conference on Robotics & Automation (ICRA), 2026
2026
-
[26]
P. Dong, A. Swerdlow, D. Sadigh, and C. Finn. Faster: Value-guided sampling for fast rl, 2026. URLhttps://arxiv.org/abs/2604.19730
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
R. Manvi, J. Hong, T. Seyde, M. Labonne, M. Lechner, and S. Levine. Zero-overhead intro- spection for adaptive test-time compute. (arXiv:2512.01457), Dec. 2025. doi:10.48550/arXiv. 2512.01457. URLhttp://arxiv.org/abs/2512.01457. arXiv:2512.01457 [cs]
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[28]
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. Score- based generative modeling through stochastic differential equations. InInternational Con- ference on Learning Representations, Oct. 2021. URLhttps://openreview.net/forum? id=PxTIG12RRHS. 11
2021
-
[29]
A. Z. Ren, J. Lidard, L. L. Ankile, A. Simeonov, P. Agrawal, A. Majumdar, B. Burchfiel, H. Dai, and M. Simchowitz. Diffusion policy policy optimization. InInternational Con- ference on Learning Representations, 2025. URLhttps://openreview.net/forum?id= YPR0X7dCXn
2025
-
[30]
A. Y . Ng, D. Harada, and S. J. Russell. Policy invariance under reward transformations: Theory and application to reward shaping. InProceedings of the Sixteenth International Conference on Machine Learning (ICML), pages 278–287, 1999. URLhttps://dl.acm.org/doi/10. 5555/645528.657613
-
[31]
Haarnoja, A
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine. Soft actor-critic: Off-policy maximum en- tropy deep reinforcement learning with a stochastic actor. In J. Dy and A. Krause, editors, Proceedings of the 35th International Conference on Machine Learning, volume 80 ofPro- ceedings of Machine Learning Research, pages 1861–1870. PMLR, 10–15 Jul 2018. URL https:...
2018
-
[32]
Perez, F
E. Perez, F. Strub, H. de Vries, V . Dumoulin, and A. C. Courville. Film: Visual reasoning with a general conditioning layer. InAAAI, 2018
2018
-
[33]
Y . Song, Y . Zhou, A. Sekhari, D. Bagnell, A. Krishnamurthy, and W. Sun. Hybrid RL: Us- ing both offline and online data can make RL efficient. InThe Eleventh International Con- ference on Learning Representations, 2023. URLhttps://openreview.net/forum?id= yyBis80iUuU
2023
-
[34]
Mandlekar, D
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Mart´ın-Mart´ın. What matters in learning from offline human demonstrations for robot manipulation. InProceedings of the 5th Conference on Robot Learning, volume 164 ofProceedings of Machine Learning Research, pages 1678–1690. PMLR, 2022. URL https:/...
2022
-
[35]
B. Liu, Y . Zhu, C. Gao, Y . Feng, qiang liu, Y . Zhu, and P. Stone. LIBERO: Benchmark- ing knowledge transfer for lifelong robot learning. InThirty-seventh Conference on Neu- ral Information Processing Systems Datasets and Benchmarks Track, 2023. URLhttps: //openreview.net/forum?id=xzEtNSuDJk
2023
-
[36]
Liang, Y
A. Liang, Y . Korkmaz, J. Zhang, M. Hwang, A. Anwar, S. Kaushik, A. Shah, A. S. Huang, L. Zettlemoyer, D. Fox, Y . Xiang, A. Li, A. Bobu, A. Gupta, S. Tu, E. Biyik, and J. Zhang. Robometer: Scaling general-purpose robotic reward models via trajectory comparisons. In Robotics: Science and Systems 2026, 2026
2026
-
[37]
Y . J. Ma, J. Hejna, C. Fu, D. Shah, J. Liang, Z. Xu, S. Kirmani, P. Xu, D. Driess, T. Xiao, O. Bastani, D. Jayaraman, W. Yu, T. Zhang, D. Sadigh, and F. Xia. Vision language models are in-context value learners. InThe Thirteenth International Conference on Learning Repre- sentations, 2025. URLhttps://openreview.net/forum?id=friHAl5ofG
2025
- [38]
-
[39]
H. Tan, S. Chen, Y . Xu, Z. Wang, Y . Ji, C. Chi, Y . Lyu, Z. Zhao, X. Chen, P. Co, et al. Robo- dopamine: General process reward modeling for high-precision robotic manipulation.arXiv preprint arXiv:2512.23703, 2025. 12 7 Appendix 7.1ELASTICAlgorithm Algorithm 1Inference at every environment stept 1:Observationo t, base policyπ GCP, meta-policyπ meta, re...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.