Capability Conditioned Scaffolding for Professional Human LLM Collaboration
Pith reviewed 2026-05-19 15:02 UTC · model grok-4.3
The pith
Capability Conditioned Scaffolding partitions user expertise into strong, mixed, and weak domains to condition LLM interventions and reduce professional domain drift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Capability Conditioned Scaffolding is a typed framework that partitions expertise into strong, mixed, and weak domains and conditions intervention behavior on structured capability profiles. A pilot evaluation across multiple MMLU subsets and four LLM substrates shows consistent profile conditioned intervention behavior, including categorical inversion under profile swapping and selective activation in mixed domain risk zones.
What carries the argument
Capability Conditioned Scaffolding, the typed framework that partitions expertise into strong, mixed, and weak domains and conditions LLM intervention behavior on those profiles.
If this is right
- LLM intervention becomes selective rather than uniform across all domains.
- Profile swapping produces predictable reversal of intervention patterns.
- Safeguards activate primarily in mixed-domain risk zones.
- Collaboration reliability improves beyond what stylistic personalization alone achieves.
Where Pith is reading between the lines
- The same partitioning logic could be applied to track how a user's expertise changes over repeated sessions.
- High-stakes fields such as medicine or legal review might adopt profile-based scaffolding to limit unchecked AI reasoning.
- Future systems could combine this method with lightweight user tests that update profiles in real time.
Load-bearing premise
User expertise can be accurately and stably partitioned into strong, mixed, and weak domains in a way that allows reliable conditioning of LLM intervention behavior.
What would settle it
An experiment in which swapping the supplied capability profiles fails to produce categorical inversion in the LLM's intervention choices would falsify the claim of consistent profile-conditioned behavior.
Figures



read the original abstract
Large language model personalization typically adapts outputs to user preferences and style but does not account for differences in user evaluation capacity across domains of expertise. This limitation can encourage Professional Domain Drift, where users rely on AI generated reasoning in domains they cannot reliably evaluate. We introduce Capability Conditioned Scaffolding, a typed framework that partitions expertise into strong, mixed, and weak domains and conditions intervention behavior on structured capability profiles. A pilot evaluation across multiple MMLU subsets and four LLM substrates shows consistent profile conditioned intervention behavior, including categorical inversion under profile swapping and selective activation in mixed domain risk zones. These findings suggest that capability aware scaffolding can support more reliable professional human AI collaboration beyond stylistic personalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Capability Conditioned Scaffolding, a typed framework that partitions user expertise into strong, mixed, and weak domains and conditions LLM intervention behavior on structured capability profiles to mitigate Professional Domain Drift. A pilot evaluation across multiple MMLU subsets and four LLM substrates is reported to demonstrate consistent profile-conditioned intervention, including categorical inversion under profile swapping and selective activation in mixed-domain risk zones.
Significance. The core idea of moving beyond stylistic personalization to capability-aware scaffolding addresses a genuine gap in professional human-LLM collaboration. If the pilot findings are reproducible with validated partitions and transparent metrics, the framework could inform safer deployment practices; the cross-substrate consistency and inversion result are potentially falsifiable contributions worth further development.
major comments (2)
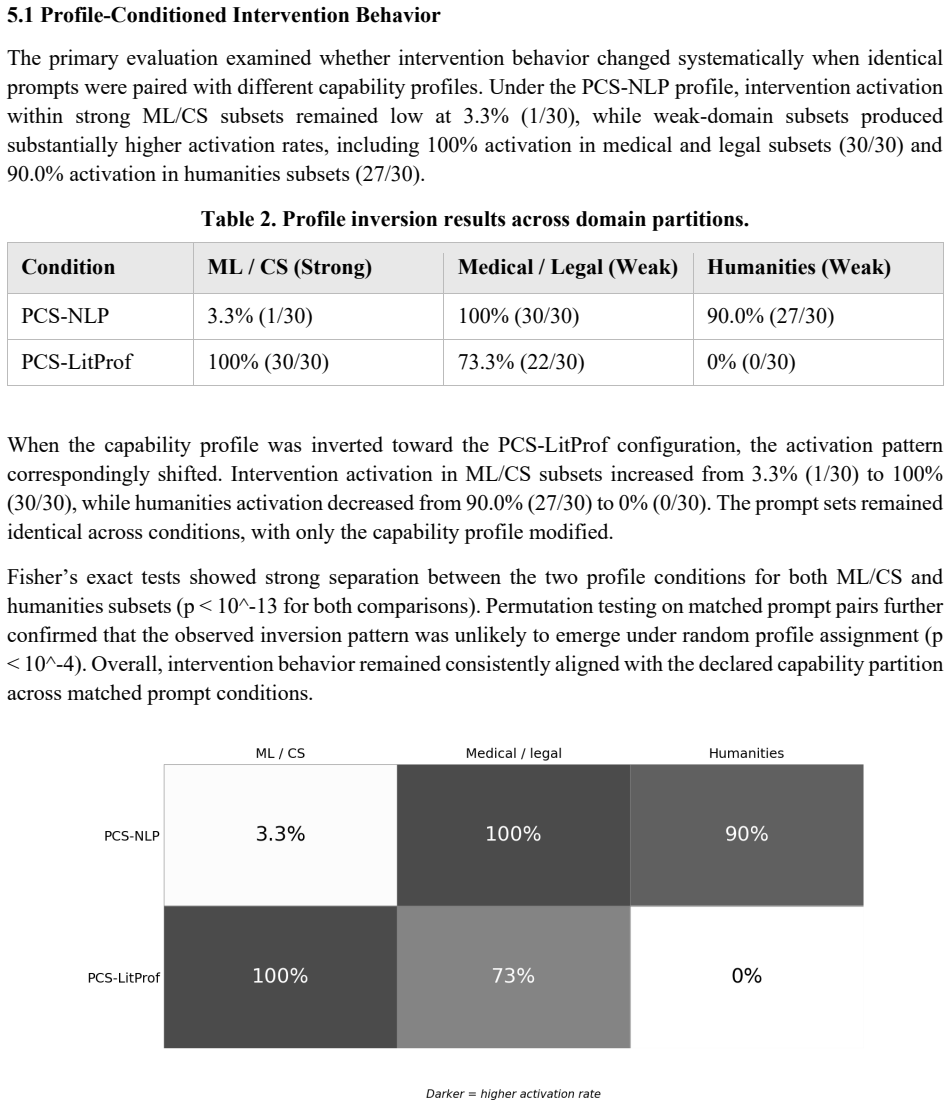
- [Pilot evaluation] Pilot evaluation section: the abstract and reported findings supply no information on how domains were partitioned into strong/mixed/weak profiles (performance thresholds, self-report, expert annotation, or LLM-derived), nor any reliability metric such as inter-rater agreement or correlation with held-out performance. This partition is load-bearing for the central claim of consistent profile-conditioned behavior and categorical inversion.
- [Pilot evaluation] Pilot evaluation section: no sample sizes, statistical tests, controls, or quantitative metrics for 'consistency' and 'inversion' are described, so the support for the positive pilot findings cannot be assessed from the supplied information.
minor comments (2)
- [Introduction] Define 'Professional Domain Drift' explicitly on first use and distinguish it from related concepts such as over-reliance or hallucination with citations.
- [Framework] Clarify the exact intervention rules (e.g., when scaffolding is activated or suppressed) with pseudocode or a table for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. The comments on the pilot evaluation section highlight important areas for clarification. We address each point below and will revise the manuscript accordingly to improve transparency and support for the reported findings.
read point-by-point responses
-
Referee: [Pilot evaluation] Pilot evaluation section: the abstract and reported findings supply no information on how domains were partitioned into strong/mixed/weak profiles (performance thresholds, self-report, expert annotation, or LLM-derived), nor any reliability metric such as inter-rater agreement or correlation with held-out performance. This partition is load-bearing for the central claim of consistent profile-conditioned behavior and categorical inversion.
Authors: We agree that the partitioning method is foundational to the claims of profile-conditioned intervention and categorical inversion. The current manuscript describes the profiles at a high level but does not specify the exact construction process or validation steps used for the MMLU subsets. In the revised version we will add a dedicated subsection detailing the partitioning criteria (including any performance thresholds or annotation procedures applied), and we will report reliability metrics such as correlation with held-out performance where available. This addition will allow readers to evaluate the reproducibility of the observed behaviors. revision: yes
-
Referee: [Pilot evaluation] Pilot evaluation section: no sample sizes, statistical tests, controls, or quantitative metrics for 'consistency' and 'inversion' are described, so the support for the positive pilot findings cannot be assessed from the supplied information.
Authors: We acknowledge that the pilot evaluation section currently omits explicit reporting of sample sizes, controls, and quantitative metrics for consistency and inversion. As the study is framed as a pilot, the emphasis was on demonstrating feasibility across substrates rather than formal statistical inference. We will revise the section to include the number of trials per profile and substrate, descriptive quantitative metrics (e.g., rates of profile-matched interventions and inversion frequency), and any experimental controls employed. We will present these descriptively without claiming statistical significance beyond what the data support. revision: yes
Circularity Check
No circularity: new framework with independent pilot evaluation
full rationale
The paper introduces Capability Conditioned Scaffolding as a novel typed framework that partitions expertise into strong/mixed/weak domains and conditions intervention on capability profiles. The pilot evaluation on MMLU subsets across four LLMs is presented as an external test showing profile-conditioned behaviors such as inversion on swap. No equations, self-citations, fitted parameters, or prior-author uniqueness theorems are invoked in the provided text. The central claims do not reduce to inputs by construction; the evaluation functions as an independent benchmark rather than a self-referential prediction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Users possess varying evaluation capacities across different domains of expertise that can be partitioned into strong, mixed, and weak categories.
invented entities (2)
-
Capability Conditioned Scaffolding
no independent evidence
-
Professional Domain Drift
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CCS partitions expertise into strong, mixed, and weak domains and conditions intervention behavior on structured capability profiles.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Introduction Large language models (LLMs) are increasingly used in professional environments to support writing, analysis, decision-making, and advisory work. Existing personalization approaches have primarily focused on adapting outputs to user preferences, interaction history, or stylistic characteristics through prompting, retrieval augmentation, and a...
work page 2020
-
[2]
Related Work 2.1 Personalization Without Capability Awareness Personalization in large language models (LLMs) has primarily focused on adapting outputs to user preferences, interaction history, or stylistic characteristics. Existing approaches include retrieval-augmented generation (Lewis et al., 2020), instruction alignment through reinforcement learning...
work page 2020
-
[3]
Conclusion Large language models are increasingly integrated into professional workflows that extend beyond information retrieval and text generation into analysis, judgment, and advisory support. Existing personalization approaches have substantially improved interaction fluency and contextual adaptation, but they generally do not account for differences...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1145/3449287 1988
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.