REViT: Roto-reflection Equivariant Convolutional Vision Transformer
Pith reviewed 2026-06-25 21:23 UTC · model grok-4.3
The pith
REViT equips vision transformers with discrete roto-reflection equivariance via convolutional attention and outperforms prior methods on image classification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
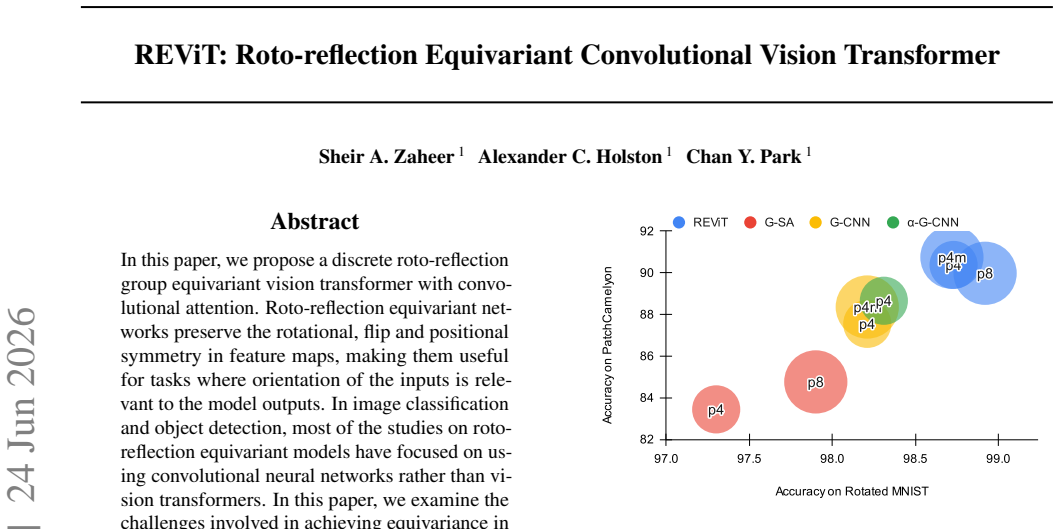
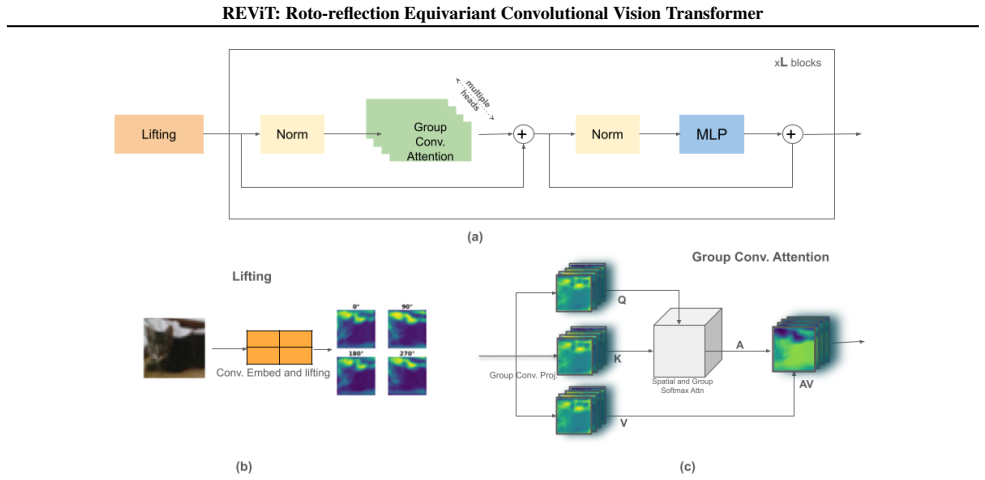
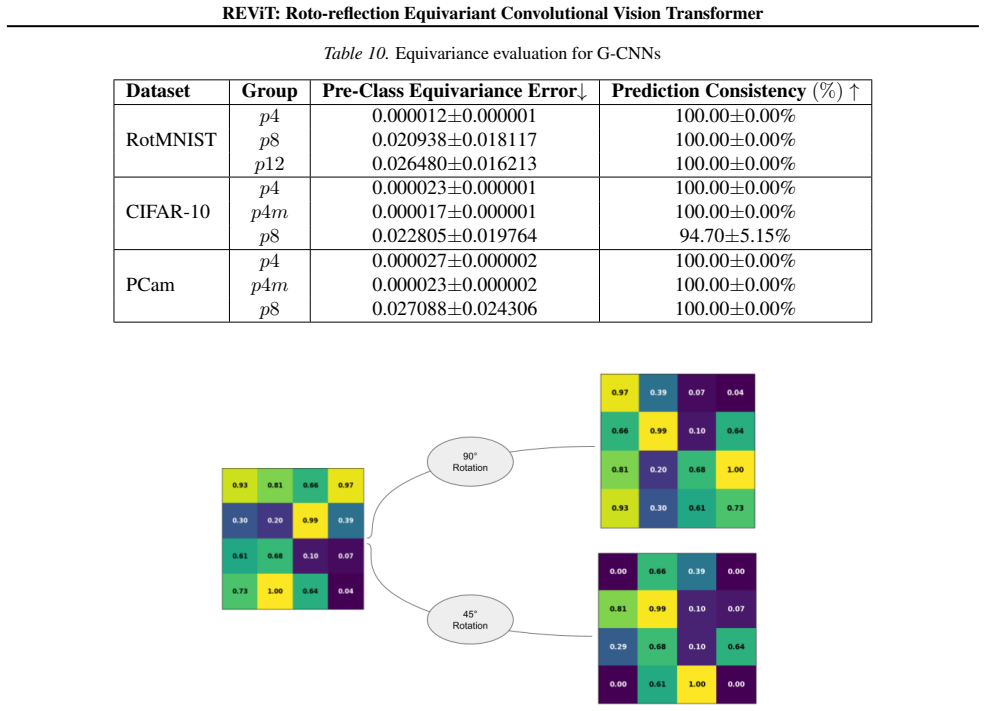
REViT achieves discrete roto-reflection group equivariance in a vision transformer by combining a discretized roto-reflection group with convolutional attention, preserving rotational, flip, and positional symmetry and delivering higher image classification accuracy than existing discrete roto-reflection equivariant networks.
What carries the argument
Discretized roto-reflection group combined with convolutional attention inside the transformer blocks.
If this is right
- Equivariance to rotations and reflections is maintained in feature maps for orientation-sensitive tasks.
- Vision transformers can incorporate discrete group equivariance without relying exclusively on convolutional layers.
- Performance improvements appear on image classification without additional dataset-specific tuning.
Where Pith is reading between the lines
- The same discretization approach could be applied to object detection where orientation symmetry matters.
- Training may require less rotation-based data augmentation when symmetries are built into the architecture.
- Similar discretization strategies might extend to other discrete symmetry groups beyond roto-reflections.
Load-bearing premise
The discretization of the roto-reflection group together with convolutional attention produces exact equivariance and measurable gains without hidden post-hoc adjustments or dataset-specific tuning.
What would settle it
A verification test in which the network outputs change under the group's transformations or classification accuracy fails to exceed that of baseline equivariant models on standard image datasets.
Figures

read the original abstract
In this paper, we propose a discrete roto-reflection group equivariant vision transformer with convolutional attention. Roto-reflection equivariant networks preserve the rotational, flip and positional symmetry in feature maps, making them useful for tasks where orientation of the inputs is relevant to the model outputs. In image classification and object detection, most of the studies on roto-reflection equivariant models have focused on using convolutional neural networks rather than vision transformers. In this paper, we examine the challenges involved in achieving equivariance in vision transformers, and we propose a simpler way to implement a discretized roto-reflection group equivariant vision transformer. The experimental results demonstrate that our approach outperforms the existing approaches for developing discrete roto-reflection group equivariant neural networks for image classification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes REViT, a vision transformer architecture that achieves discrete roto-reflection (dihedral group) equivariance by lifting features to the group, applying group convolutions, and incorporating convolutional attention within transformer blocks. It claims this yields exact equivariance to rotations and reflections while outperforming prior discrete roto-reflection equivariant networks on image classification.
Significance. If the architecture delivers exact equivariance (rather than approximate) and the reported gains are shown to stem from the symmetry properties, the work would usefully extend equivariant CNN techniques to the transformer setting, addressing a gap noted in the abstract where most roto-reflection equivariant models have been CNN-based.
major comments (1)
- [Section 3, Eqs. (4-6)] Section 3, Eqs. (4–6): the attention mechanism is defined via standard dot-product attention applied to the lifted features. No additional constraints or group-equivariant formulation is described that would ensure the attention weights themselves transform correctly under the full dihedral action (including reflections). Because the central claim requires exact equivariance, this omission is load-bearing; without a proof or explicit verification that attention preserves the group action, the model may only be partially equivariant.
Simulated Author's Rebuttal
We thank the referee for their careful review and for highlighting the need to substantiate the exact equivariance claim. We address the single major comment below and will incorporate the requested clarification in a revised manuscript.
read point-by-point responses
-
Referee: [Section 3, Eqs. (4-6)] Section 3, Eqs. (4–6): the attention mechanism is defined via standard dot-product attention applied to the lifted features. No additional constraints or group-equivariant formulation is described that would ensure the attention weights themselves transform correctly under the full dihedral action (including reflections). Because the central claim requires exact equivariance, this omission is load-bearing; without a proof or explicit verification that attention preserves the group action, the model may only be partially equivariant.
Authors: We agree that the current description in Section 3 relies on standard scaled dot-product attention applied after lifting the input to the dihedral group and that no separate group-equivariant formulation or proof is supplied for the attention weights under reflections. Because the central claim is exact roto-reflection equivariance, this point requires explicit treatment. In the revision we will add a short lemma (with proof) showing that the overall block remains equivariant: the group-lifted features transform as a regular representation, the convolutional projections that produce queries/keys/values are group convolutions (hence equivariant), and the subsequent softmax-normalized dot-product followed by the value projection preserves the group action because the same linear operations are applied uniformly across all group elements. If the proof reveals that reflections require an additional sign-flip or orientation-reversing adjustment in the attention, we will modify Eqs. (4–6) accordingly and report the change. We will also add a short empirical check (invariance of output under random dihedral transformations on a held-out set) to corroborate the algebraic argument. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The manuscript abstract and summary describe a proposed architecture for discrete roto-reflection equivariant vision transformers using convolutional attention, with an empirical claim of outperformance on image classification. No equations, self-citations, or derivation steps are visible that reduce a claimed prediction or uniqueness result to a fitted parameter or prior self-referential definition by construction. The central claim rests on experimental results rather than an internal tautology, and no load-bearing self-citation chain or ansatz smuggling is exhibited. This is the expected outcome when the paper's derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Redet: A rotation-equivariant detector for aerial object detection , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[2]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Learning RoI transformer for oriented object detection in aerial images , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[3]
, title =
Deng, Congyue and Litany, Or and Duan, Yueqi and Poulenard, Adrien and Tagliasacchi, Andrea and Guibas, Leonidas J. , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2021 , pages =
2021
-
[4]
arXiv preprint arXiv:2206.04176 , year=
Vn-transformer: Rotation-equivariant attention for vector neurons , author=. arXiv preprint arXiv:2206.04176 , year=
-
[5]
arXiv preprint arXiv:2206.11990 , year=
Equiformer: Equivariant graph attention transformer for 3d atomistic graphs , author=. arXiv preprint arXiv:2206.11990 , year=
-
[6]
arXiv preprint arXiv:2306.12059 , year=
Equiformerv2: Improved equivariant transformer for scaling to higher-degree representations , author=. arXiv preprint arXiv:2306.12059 , year=
-
[7]
arXiv preprint arXiv:2310.08061 , year=
ETDock: A Novel Equivariant Transformer for Protein-Ligand Docking , author=. arXiv preprint arXiv:2310.08061 , year=
-
[8]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Equivariant point network for 3d point cloud analysis , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[9]
arXiv preprint arXiv:2010.02449 , year=
On the universality of rotation equivariant point cloud networks , author=. arXiv preprint arXiv:2010.02449 , year=
arXiv 2010
-
[10]
International conference on machine learning , pages=
Group equivariant convolutional networks , author=. International conference on machine learning , pages=. 2016 , organization=
2016
-
[11]
arXiv preprint arXiv:1803.02155 , year=
Self-attention with relative position representations , author=. arXiv preprint arXiv:1803.02155 , year=
-
[12]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Rethinking and improving relative position encoding for vision transformer , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[13]
International Conference on Learning Representations , year=
Group Equivariant Stand-Alone Self-Attention For Vision , author=. International Conference on Learning Representations , year=
-
[14]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[15]
The architecture of modern mathematics , pages=
A path to the epistemology of mathematics: Homotopy theory , author=. The architecture of modern mathematics , pages=. 2006 , publisher=
2006
-
[16]
Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions , year=
Wang, Wenhai and Xie, Enze and Li, Xiang and Fan, Deng-Ping and Song, Kaitao and Liang, Ding and Lu, Tong and Luo, Ping and Shao, Ling , booktitle=. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions , year=
-
[17]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Cvt: Introducing convolutions to vision transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[18]
2018 , eprint=
Roto-Translation Covariant Convolutional Networks for Medical Image Analysis , author=. 2018 , eprint=
2018
-
[19]
2020 , eprint=
Attentive Group Equivariant Convolutional Networks , author=. 2020 , eprint=
2020
-
[20]
2018 , eprint=
Rotation Equivariant CNNs for Digital Pathology , author=. 2018 , eprint=
2018
-
[21]
2017 , month =
Ehteshami Bejnordi, Babak and Veta, Mitko and Diest, Paul and Ginneken, Bram and Karssemeijer, Nico and Litjens, Geert and van der Laak, Jeroen and Hermsen, Meyke and Manson, Quirine and Balkenhol, Maschenka and Geessink, Oscar and Stathonikos, Nikolaos and van Dijk, Marcory and Bult, Peter and Beca, Francisco and Beck, Andrew and Wang, Dayong and Khosla,...
2017
-
[22]
Learning Multiple Layers of Features from Tiny Images , url =
Krizhevsky, Alex , biburl =. Learning Multiple Layers of Features from Tiny Images , url =
-
[23]
International Conference on Machine Learning , year=
An empirical evaluation of deep architectures on problems with many factors of variation , author=. International Conference on Machine Learning , year=
-
[24]
Learning rotation invariant convolutional filters for texture classification , url=
Marcos, Diego and Volpi, Michele and Tuia, Devis , year=. Learning rotation invariant convolutional filters for texture classification , url=. doi:10.1109/icpr.2016.7899932 , booktitle=
-
[25]
2022 , eprint=
What is an equivariant neural network? , author=. 2022 , eprint=
2022
-
[26]
Geometric deep learning: Going beyond euclidean data,
Bronstein, Michael M. and Bruna, Joan and LeCun, Yann and Szlam, Arthur and Vandergheynst, Pierre , year=. Geometric Deep Learning: Going beyond Euclidean data , volume=. IEEE Signal Processing Magazine , publisher=. doi:10.1109/msp.2017.2693418 , number=
-
[27]
Representations of Finite Groups
Fulton, William and Harris, Joe. Representations of Finite Groups. Representation Theory: A First Course. 2004. doi:10.1007/978-1-4612-0979-9_1
-
[28]
ImageNet: A large-scale hierarchical image database , year=
Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Kai Li and Li Fei-Fei , booktitle=. ImageNet: A large-scale hierarchical image database , year=
-
[29]
2023 , eprint=
The Surprising Effectiveness of Equivariant Models in Domains with Latent Symmetry , author=. 2023 , eprint=
2023
-
[30]
2021 , eprint=
Equivariant message passing for the prediction of tensorial properties and molecular spectra , author=. 2021 , eprint=
2021
-
[31]
Rotation Equivariant Vector Field Networks , url=
Marcos, Diego and Volpi, Michele and Komodakis, Nikos and Tuia, Devis , year=. Rotation Equivariant Vector Field Networks , url=. doi:10.1109/iccv.2017.540 , booktitle=
-
[32]
2018 , eprint=
Tensor field networks: Rotation- and translation-equivariant neural networks for 3D point clouds , author=. 2018 , eprint=
2018
-
[33]
International Conference on Learning Representations , year=
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. International Conference on Learning Representations , year=
-
[34]
Rethinking and Improving Relative Position Encoding for Vision Transformer , year=
Wu, Kan and Peng, Houwen and Chen, Minghao and Fu, Jianlong and Chao, Hongyang , booktitle=. Rethinking and Improving Relative Position Encoding for Vision Transformer , year=
-
[35]
R eal F ormer: Transformer Likes Residual Attention
He, Ruining and Ravula, Anirudh and Kanagal, Bhargav and Ainslie, Joshua. R eal F ormer: Transformer Likes Residual Attention. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. 2021. doi:10.18653/v1/2021.findings-acl.81
-
[36]
Zhao, Linfeng and Li, Hongyu and Padr, Takn and Jiang, Huaizu and Wong, Lawson L.S. , year=. E(2)-Equivariant Graph Planning for Navigation , volume=. IEEE Robotics and Automation Letters , publisher=. doi:10.1109/lra.2024.3360011 , number=
-
[37]
2023 , eprint=
Integrating Symmetry into Differentiable Planning with Steerable Convolutions , author=. 2023 , eprint=
2023
-
[38]
2020 , editor =
Bogatskiy, Alexander and Anderson, Brandon and Offermann, Jan and Roussi, Marwah and Miller, David and Kondor, Risi , booktitle =. 2020 , editor =
2020
-
[39]
2016 , eprint=
Permutation-equivariant neural networks applied to dynamics prediction , author=. 2016 , eprint=
2016
-
[40]
2021 , school=
Equivariant convolutional networks , author=. 2021 , school=
2021
-
[41]
arXiv preprint arXiv:2010.10952 , year=
A wigner-eckart theorem for group equivariant convolution kernels , author=. arXiv preprint arXiv:2010.10952 , year=
arXiv 2010
-
[42]
IEEE transactions on pattern analysis and machine intelligence , volume=
A survey on vision transformer , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2022 , publisher=
2022
-
[43]
ACM computing surveys (CSUR) , volume=
Transformers in vision: A survey , author=. ACM computing surveys (CSUR) , volume=. 2022 , publisher=
2022
-
[44]
Advances in neural information processing systems , volume=
Se (3)-transformers: 3d roto-translation equivariant attention networks , author=. Advances in neural information processing systems , volume=
-
[45]
International conference on machine learning , pages=
E (n) equivariant graph neural networks , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[46]
2018 IEEE Winter Conference on Applications of Computer Vision (WACV) , pages=
A rotationally-invariant convolution module by feature map back-rotation , author=. 2018 IEEE Winter Conference on Applications of Computer Vision (WACV) , pages=. 2018 , organization=
2018
-
[47]
IEEE Transactions on Image Processing , year=
Rotational Convolution: Rethinking Convolution for Downside Fisheye Images , author=. IEEE Transactions on Image Processing , year=
-
[48]
2024 , eprint=
Beyond Euclid: An Illustrated Guide to Modern Machine Learning with Geometric, Topological, and Algebraic Structures , author=. 2024 , eprint=
2024
-
[49]
2020 , eprint=
Roto-Translation Equivariant Convolutional Networks: Application to Histopathology Image Analysis , author=. 2020 , eprint=
2020
-
[50]
CNNs on surfaces using rotation-equivariant features , volume=
Wiersma, Ruben and Eisemann, Elmar and Hildebrandt, Klaus , year=. CNNs on surfaces using rotation-equivariant features , volume=. ACM Transactions on Graphics , publisher=. doi:10.1145/3386569.3392437 , number=
-
[51]
Yufei Xu and Qiming Zhang and Jing Zhang and Dacheng Tao , booktitle=. Vi. 2021 , url=
2021
-
[52]
A comparative study between vision transformers and CNNs in digital pathology , doi =
Deininger, Luca and Stimpel, Bernhard and Yuce, Anil and Abbasi-Sureshjani, Samaneh and Schönenberger, Simon and Ocampo, Paolo and Korski, Konstanty and Gaire, Fabien , year =. A comparative study between vision transformers and CNNs in digital pathology , doi =
-
[53]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
3D Equivariant Pose Regression via Direct Wigner-D Harmonics Prediction , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[54]
2022 , eprint=
Self-Supervised Equivariant Learning for Oriented Keypoint Detection , author=. 2022 , eprint=
2022
-
[55]
International Conference on Learning Representations , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations , year=
-
[56]
Dan Hendrycks and Kevin Gimpel , title =. CoRR , volume =. 2016 , url =. 1606.08415 , timestamp =
Pith/arXiv arXiv 2016
-
[57]
International conference on machine learning , pages=
On the generalization of equivariance and convolution in neural networks to the action of compact groups , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[58]
Advances in neural information processing systems , volume=
A general theory of equivariant cnns on homogeneous spaces , author=. Advances in neural information processing systems , volume=
-
[59]
International conference on machine learning , pages=
Generalizing convolutional neural networks for equivariance to lie groups on arbitrary continuous data , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[60]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Harmonic networks: Deep translation and rotation equivariance , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[61]
Cohen and Mario Geiger and Jonas Köhler and Max Welling , booktitle=
Taco S. Cohen and Mario Geiger and Jonas Köhler and Max Welling , booktitle=. Spherical. 2018 , url=
2018
-
[62]
International Conference on Learning Representations , year=
Polar Transformer Networks , author=. International Conference on Learning Representations , year=
-
[63]
Proceedings of the european conference on computer vision (ECCV) , pages=
Learning so (3) equivariant representations with spherical cnns , author=. Proceedings of the european conference on computer vision (ECCV) , pages=
-
[64]
Nature communications , volume=
E (3)-equivariant graph neural networks for data-efficient and accurate interatomic potentials , author=. Nature communications , volume=. 2022 , publisher=
2022
-
[65]
International conference on Machine learning , pages=
Gauge equivariant convolutional networks and the icosahedral CNN , author=. International conference on Machine learning , pages=. 2019 , organization=
2019
-
[66]
Learning Multiple Layers of Features from Tiny Images , journal =
Krizhevsky, Alex , year =. Learning Multiple Layers of Features from Tiny Images , journal =
-
[67]
Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education
Clancey, William J. Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education. Proceedings of the Eighth International Joint Conference on Artificial Intelligence (IJCAI-83)
-
[68]
Classification Problem Solving
Clancey, William J. Classification Problem Solving. Proceedings of the Fourth National Conference on Artificial Intelligence
-
[69]
, title =
Robinson, Arthur L. , title =. 1980 , doi =. https://science.sciencemag.org/content/208/4447/1019.full.pdf , journal =
1980
-
[70]
New Ways to Make Microcircuits Smaller---Duplicate Entry
Robinson, Arthur L. New Ways to Make Microcircuits Smaller---Duplicate Entry. Science
-
[71]
Clancey and Glenn Rennels , abstract =
Diane Warner Hasling and William J. Clancey and Glenn Rennels , abstract =. Strategic explanations for a diagnostic consultation system , journal =. 1984 , issn =. doi:https://doi.org/10.1016/S0020-7373(84)80003-6 , url =
-
[72]
and Rennels, Glenn R
Hasling, Diane Warner and Clancey, William J. and Rennels, Glenn R. and Test, Thomas. Strategic Explanations in Consultation---Duplicate. The International Journal of Man-Machine Studies
-
[73]
Poligon: A System for Parallel Problem Solving
Rice, James. Poligon: A System for Parallel Problem Solving
-
[74]
Transfer of Rule-Based Expertise through a Tutorial Dialogue
Clancey, William J. Transfer of Rule-Based Expertise through a Tutorial Dialogue
-
[75]
The Engineering of Qualitative Models
Clancey, William J. The Engineering of Qualitative Models
-
[76]
2017 , eprint=
Attention Is All You Need , author=. 2017 , eprint=
2017
-
[77]
Pluto: The 'Other' Red Planet
NASA. Pluto: The 'Other' Red Planet
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.