Diverge to Induce Prompting: Multi-Rationale Induction for Zero-Shot Reasoning
Pith reviewed 2026-05-21 14:21 UTC · model grok-4.3
The pith
DIP boosts zero-shot reasoning by generating multiple diverse rationales then inducing them into one superior plan.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DIP first prompts an LLM to generate multiple diverse high-level rationales for each question. Each rationale is then elaborated into a detailed, step-by-step draft plan. Finally, these draft plans are induced into a final plan. Experiments show that DIP outperforms single-strategy prompting on zero-shot reasoning tasks.
What carries the argument
Multi-rationale induction: the process of creating several high-level rationales, expanding each into a draft plan, and then combining the drafts into one final plan.
If this is right
- DIP raises accuracy on zero-shot reasoning benchmarks compared with single-strategy baselines.
- The method works without any resource-intensive sampling steps.
- The final induced plan is superior to any of the individual draft plans it is built from.
- The framework can be applied to a range of reasoning tasks by changing only the rationale-generation prompt.
Where Pith is reading between the lines
- The approach may reduce reliance on few-shot examples or task-specific fine-tuning for reasoning problems.
- It could be combined with self-consistency or other verification steps to produce still stronger results.
- Scalability to very long or multi-hop reasoning chains remains an open question that would require targeted tests.
- Similar diverge-then-induce steps might transfer to non-reasoning generation tasks such as planning or code synthesis.
Load-bearing premise
Large language models can reliably produce multiple diverse high-quality rationales whose elaborated plans can be merged into a plan that beats every individual plan.
What would settle it
Run DIP and single-strategy prompting on the same set of zero-shot reasoning benchmarks and find that DIP shows no accuracy gain or shows lower accuracy.
Figures













read the original abstract
To address the instability of unguided reasoning paths in standard Chain-of-Thought prompting, recent methods guide large language models (LLMs) by first eliciting a single reasoning strategy. However, relying on just one strategy for each question can still limit performance across diverse tasks. We propose Diverge-to-Induce Prompting (DIP), a framework that first prompts an LLM to generate multiple diverse high-level rationales for each question. Each rationale is then elaborated into a detailed, step-by-step draft plan. Finally, these draft plans are induced into a final plan. DIP enhances zero-shot reasoning accuracy without reliance on resource-intensive sampling. Experiments show that DIP outperforms single-strategy prompting, demonstrating the effectiveness of multi-plan induction for prompt-based reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Diverge-to-Induce Prompting (DIP) for zero-shot reasoning in LLMs. The approach first elicits multiple diverse high-level rationales per question, elaborates each into a detailed step-by-step draft plan, and finally induces these drafts into a single final plan. The central claim is that this multi-plan induction yields higher reasoning accuracy than single-strategy prompting baselines while avoiding the cost of sampling-based methods.
Significance. If the empirical gains are robust and the induction step is shown to be responsible, DIP would offer a lightweight prompt-engineering technique that exploits rationale diversity to improve over existing single-strategy zero-shot methods. This could be a useful addition to the prompting literature for tasks where sampling is undesirable.
major comments (2)
- [§4 Experiments] §4 (Experiments): The reported superiority of DIP over single-strategy prompting is not accompanied by an ablation that runs each elaborated draft plan in isolation (or selects the best by internal score) and compares its accuracy to the final induced plan. Without this control, it remains possible that observed gains derive from the initial divergence step, longer context, or the elaboration phase rather than the induction mechanism itself. This directly affects the load-bearing claim that multi-plan induction is the key differentiator.
- [§3 Method] §3 (Method): The induction step is described only at a high level; the exact prompt template used to synthesize the multiple draft plans into the final plan is not provided, nor is any analysis of how the LLM performs the synthesis (e.g., whether it is a single additional call or involves further iteration). This omission prevents assessment of whether the induction itself introduces new variability or simply averages the drafts.
minor comments (2)
- [Abstract] Abstract: The claim that DIP 'outperforms single-strategy prompting' would be strengthened by including at least one quantitative result (e.g., average accuracy lift) and naming the primary datasets or models used.
- [Throughout] Notation and terminology: The terms 'rationale', 'draft plan', and 'final plan' are used interchangeably in places; a short glossary or consistent usage throughout would improve readability.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive review. The comments highlight important aspects for strengthening the empirical validation and methodological transparency of Diverge-to-Induce Prompting (DIP). We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [§4 Experiments] §4 (Experiments): The reported superiority of DIP over single-strategy prompting is not accompanied by an ablation that runs each elaborated draft plan in isolation (or selects the best by internal score) and compares its accuracy to the final induced plan. Without this control, it remains possible that observed gains derive from the initial divergence step, longer context, or the elaboration phase rather than the induction mechanism itself. This directly affects the load-bearing claim that multi-plan induction is the key differentiator.
Authors: We agree that the current experimental design does not fully isolate the contribution of the induction mechanism. In the revised manuscript we will add the requested ablation: we will evaluate the zero-shot accuracy obtained by executing each elaborated draft plan in isolation, as well as a best-of-drafts baseline that selects the highest-scoring draft according to an internal self-consistency or likelihood metric. These results will be reported alongside the original DIP numbers in Section 4, allowing readers to assess whether the final induced plan yields gains beyond what is achievable from the divergence and elaboration stages alone. revision: yes
-
Referee: [§3 Method] §3 (Method): The induction step is described only at a high level; the exact prompt template used to synthesize the multiple draft plans into the final plan is not provided, nor is any analysis of how the LLM performs the synthesis (e.g., whether it is a single additional call or involves further iteration). This omission prevents assessment of whether the induction itself introduces new variability or simply averages the drafts.
Authors: We accept that the induction step requires a more precise description. In the revised version we will (1) reproduce the exact prompt template used for synthesizing the draft plans into the final plan in a new appendix, and (2) explicitly state that synthesis is performed with a single additional LLM call and does not involve iterative refinement. We will also add a short discussion of the variability that this synthesis step may introduce and how it differs from simple averaging or selection among the drafts. revision: yes
Circularity Check
No circularity: empirical prompting method with external validation
full rationale
The paper presents DIP as a prompting framework defined by explicit procedural steps (generate diverse rationales, elaborate plans, induce final plan) and evaluates it through experiments comparing accuracy to baselines. No equations, fitted parameters, or first-principles derivations appear in the provided text. The central claim rests on empirical outperformance rather than any self-referential reduction or self-citation chain that would make the result equivalent to its inputs by construction. This is a standard non-circular empirical contribution.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
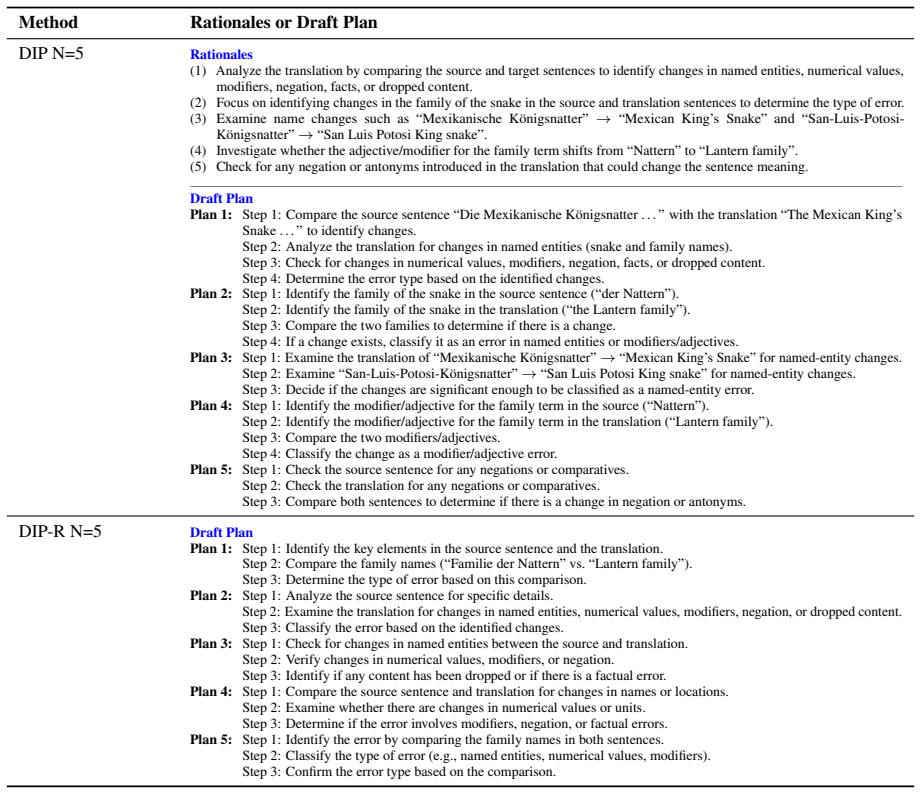
DIP comprises three main phases: (1) a Divergent Phase, where the model generates multiple high-level rationales and constructs a draft plan for each; (2) an inductive phase, which consolidates these draft plans into a final plan; and (3) an Inference Phase...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Vqa-induct: Instruction induction for visual question answering. InProceedings of the 34th ACM International Conference on Information and Knowl- edge Management, CIKM ’25, page 4659–4664, New York, NY , USA. Association for Computing Machin- ery. Po-Chun Chen, Sheng-Lun Wei, Hen-Hsen Huang, and Hsin-Hsi Chen. 2024. Induct-learn: Short phrase prompting wi...
-
[2]
Chain of thought prompting elicits reasoning in large language models.ArXiv, abs/2201.11903. Colin White, Samuel Dooley, Manley Roberts, Arka Pal, Benjamin Feuer, Siddhartha Jain, Ravid Shwartz-Ziv, Neel Jain, Khalid Saifullah, Sreemanti Dey, Shubh- Agrawal, Sandeep Singh Sandha, Siddartha Venkat Naidu, Chinmay Hegde, Yann LeCun, Tom Gold- stein, Willie N...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Language models as inductive reasoners. ArXiv, abs/2212.10923. Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of thoughts: deliberate prob- lem solving with large language models. InPro- ceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red...
-
[4]
A clear and detailed <task_instructions> block that contains: - **Task Content:** A definition of the task’s purpose along with the required activities. - **Input Format:** Detailed descriptions of the accepted data types, their formats, and instructions for processing these inputs
-
[5]
A comprehensive <reasoning_framework> block that includes high-level reasoning steps which generalize the approach to solving similar tasks. Ensure that these steps are concise, actionable, and that they support deriving an answer that strictly conforms to the provided answer format. Present your final output strictly in the following format: <task_instru...
-
[6]
Based on the `reasoning_framework`, provide a step-by-step chain of thought that answers the question. Present your chain of thought in the following format: <chain_of_thought> [Your step-by-step chain of thought here] </chain_of_thought>
-
[7]
Based on your `chain_of_thought`, provide the final answer according to the rules specified in the `output_format` section. If unsure and "Output Format" is option, guess the closest option. Present your final answer in the following format: <final_answer> [Your final answer here] </final_answer> **Note** - Do not use programming or code to solve this que...
-
[9]
Based on yourchain_of_thought, provide the final answer according to the rules specified in theoutput_formatsection. If unsure and "Output Format" is option, guess the closest option. Present your final answer in the following format: <final_answer> [Your final answer here] </final_answer> Note: - Do not use programming or code to solve this question. - I...
-
[10]
<chain_of_thought> [Your step-by-step chain of thought here] </chain_of_thought>
Based on thereasoning_framework, provide a step-by-step chain of thought that answers the question. <chain_of_thought> [Your step-by-step chain of thought here] </chain_of_thought>
-
[11]
Based on yourchain_of_thought, provide the final answer according to the rules specified in theoutput_formatsection. If unsure and "Output Format" is option, guess the closest option. Present your final answer in the following format: <final_answer> [Your final answer here] </final_answer> NoteDo not use programming or code to solve this question. Questio...
-
[12]
Based on thereasoning_framework, provide a step-by-step chain of thought that answers the question. Present your chain of thought in the following format: <chain_of_thought> [Your step-by-step chain of thought here] </chain_of_thought>
-
[13]
Based on yourchain_of_thought, provide the final answer according to the rules specified in theoutput_formatsection. If unsure and "Output Format" is option, guess the closest option. Present your final answer in the following format: <final_answer> [Your final answer here] </final_answer> Note - Do not use programming or code to solve this question. - It...
-
[15]
Based on yourchain_of_thought, provide the final answer according to the rules specified in theoutput_formatsection. If unsure and "Output Format" is option, guess the closest option. Present your final answer in the following format: <final_answer> [Your final answer here] </final_answer> Question <question> The following translations from German to Engl...
-
[16]
<strategy> [Your strategy here] </strategy>
Carefully consider the problem and generate the strategic knowledge that would best guide the problem-solving process. <strategy> [Your strategy here] </strategy>
-
[17]
<chain_of_thought> [Your step-by-step chain of thought here] </chain_of_thought>
Provide a step-by-step chain of thought that answers the question. <chain_of_thought> [Your step-by-step chain of thought here] </chain_of_thought>
-
[18]
Based on yourchain_of_thought, provide the final answer according to the rules specified in theoutput_formatsection. If unsure and "Output Format" is option, guess the closest option. Present your final answer in the following format: <final_answer> [Your final answer here] </final_answer> NoteDo not use programming or code to solve this question. Questio...
-
[19]
First, carefully consider the question and propose a clear reasoning framework to guide your thinking. <reasoning_framework> Step 1: [First high-level reasoning step] Step 2: [Second high-level reasoning step] Step 3: [Third high-level reasoning step] [Add additional steps if necessary] </reasoning_framework>
-
[20]
Next, use the framework you’ve outlined to explain your reasoning step-by-step. <chain_of_thought>
-
[21]
[Explanation aligned with Step 1]
-
[22]
[Explanation aligned with Step 2]
-
[23]
[Explanation aligned with Step 3] [Continue as necessary] </chain_of_thought>
-
[24]
Based on yourchain_of_thought, provide the final answer according to the rules specified in theoutput_formatsection. If unsure and "Output Format" is option, guess the closest option. Present your final answer in the following format: <final_answer> [Your final answer here] </final_answer> Note:Do not use programming or code to solve this question. Questi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.