A Multi-Domain Benchmark for Detecting AI-Generated Text-Rich Images from GPT-Image-2
Pith reviewed 2026-06-26 21:30 UTC · model grok-4.3
The pith
Existing detectors for AI-generated text-rich images perform inconsistently across domains and degrade sharply under JPEG compression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
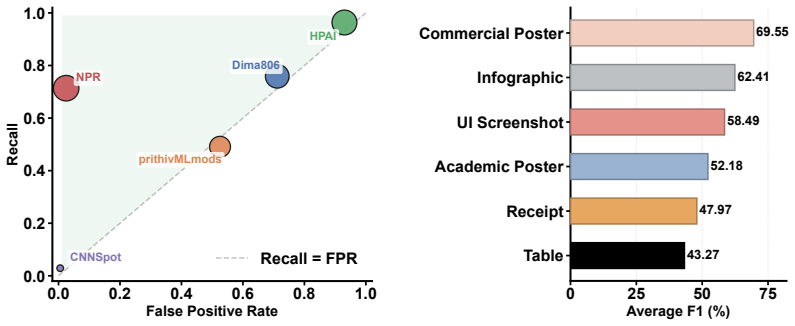
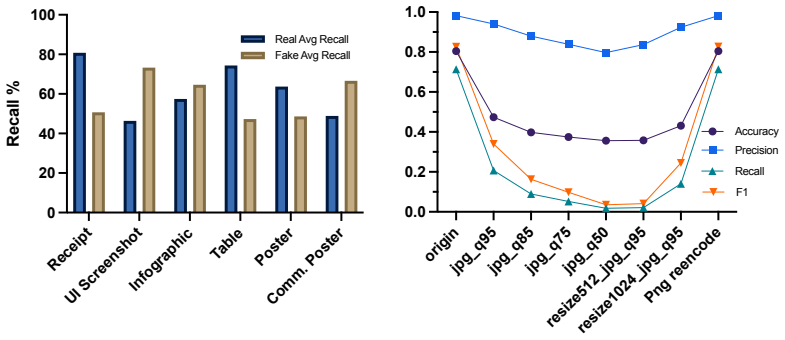
The paper establishes that detector performance on GPT-Image-2 text-rich images is highly domain-dependent, with methods succeeding in some categories but failing in others, and that even leading conventional detectors lose effectiveness under JPEG compression.
What carries the argument
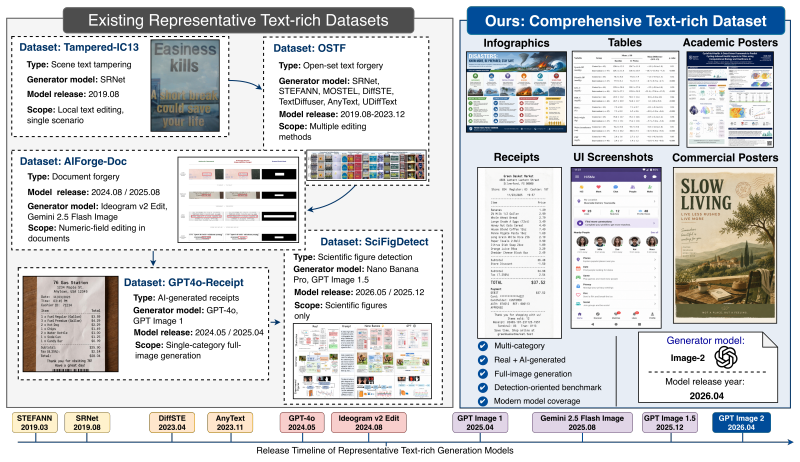
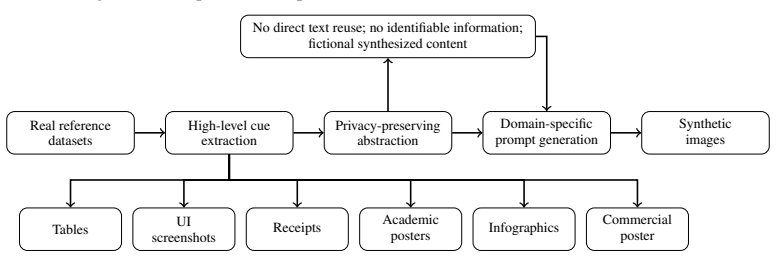
The multi-domain benchmark of 8602 images spanning commercial posters, infographics, academic posters, receipts, tables, and UI screenshots.
If this is right
- No single detector can be relied upon across all text-rich image categories.
- JPEG compression causes large accuracy drops even for the best conventional methods.
- Multimodal vision-language models show mixed results when applied to structured text formats.
- Detection methods need to incorporate awareness of textual semantics and layout organization.
Where Pith is reading between the lines
- Deployment in privacy-sensitive settings such as receipt or transaction verification would face particular risks from current detector weaknesses.
- The benchmark could be used to test whether text-recognition pipelines combined with forensic signals close the identified gaps.
- Extending the evaluation to additional post-processing operations beyond JPEG would clarify the practical robustness limits.
- Similar domain-dependence patterns may appear when testing detectors on text-rich images from generators other than GPT-Image-2.
Load-bearing premise
The 8602 generated images across the six categories and the five evaluated detectors are representative of real-world text-rich AI-generated content and available detection methods.
What would settle it
Applying the same five detectors to a fresh collection of text-rich images produced by a different generator and checking whether the patterns of domain dependence and JPEG sensitivity persist or disappear.
Figures


read the original abstract
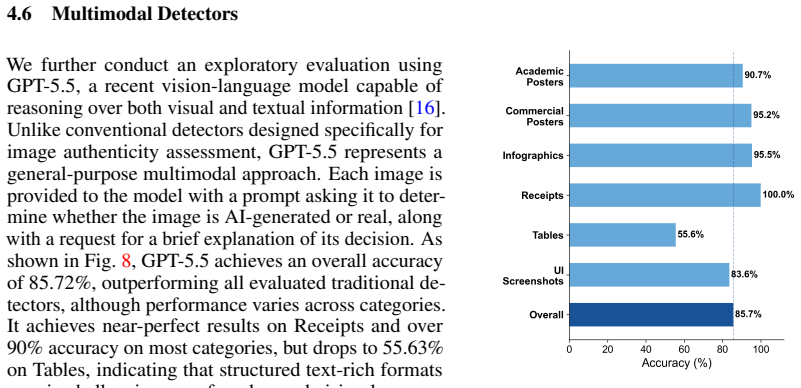
Text-rich images often contain privacy-sensitive, transactional, or decision-relevant information. As recent multimodal image generation models become increasingly capable of synthesizing realistic textual content and structured visual designs, detecting AI-generated text-rich images has become an important challenge for digital trust and content authenticity. Existing benchmarks, however, largely focus on object-centric images and provide limited coverage of scenarios where textual semantics and layout organization are central. In this paper, we introduce a multi-domain benchmark for detecting text-rich images generated by OpenAI's GPT Image 2. The benchmark contains 8,602 images across six representative categories: commercial posters, infographics, academic posters, receipts, tables, and UI screenshots. Using this benchmark, we evaluate five representative AI-generated image detectors in a zero-shot setting and analyze their overall, category-wise, and post-processing robustness. Our results show that detector performance is highly domain-dependent: methods that perform well in some categories often fail on others, and even the strongest conventional detector exhibits severe sensitivity to JPEG compression. We further conduct an exploratory evaluation with a multimodal vision-language model, revealing both its promise and its limitations on structured formats. These findings highlight the need for text- and layout-aware detection methods for modern AI-generated images. Our dataset is released at XXX.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a benchmark of 8602 text-rich images generated by GPT-Image-2 across six categories (commercial posters, infographics, academic posters, receipts, tables, UI screenshots). It evaluates five detectors zero-shot, reports domain-dependent performance and severe JPEG sensitivity even for the strongest detector, and includes an exploratory VLM evaluation to argue for text- and layout-aware detection methods.
Significance. A well-scoped benchmark on text-rich AI images would be useful given the privacy and authenticity stakes, and the empirical finding of domain dependence plus compression fragility is a concrete observation worth documenting. The single-generator design, however, caps the result at model-specific insights rather than a general statement about AI-generated text-rich images.
major comments (2)
- [Abstract] Abstract and title: the work is framed as addressing detection of 'AI-generated text-rich images' broadly and the need for text/layout-aware methods for 'modern AI-generated images,' yet the entire benchmark and all evaluations use only GPT-Image-2 generations. Without cross-generator controls, the reported domain dependence and JPEG sensitivity could be artifacts of GPT-Image-2-specific text rendering rather than intrinsic properties of the domain.
- [Abstract] The central empirical claim (domain-dependent detector performance) rests on 8602 images from one generator whose text, font, and layout artifacts may differ systematically from those of Stable Diffusion, Midjourney, or other models on which the five evaluated detectors were presumably trained. This generator mismatch is load-bearing for the generalizability conclusion.
minor comments (1)
- [Abstract] The dataset release URL is listed as 'XXX'; replace with the actual link before publication.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of precise scoping. Our work is explicitly focused on GPT-Image-2 as indicated by the title; we will revise the abstract and add a limitations discussion to eliminate any broader framing that could imply generalizability across generators.
read point-by-point responses
-
Referee: [Abstract] Abstract and title: the work is framed as addressing detection of 'AI-generated text-rich images' broadly and the need for text/layout-aware methods for 'modern AI-generated images,' yet the entire benchmark and all evaluations use only GPT-Image-2 generations. Without cross-generator controls, the reported domain dependence and JPEG sensitivity could be artifacts of GPT-Image-2-specific text rendering rather than intrinsic properties of the domain.
Authors: The title explicitly names GPT-Image-2, and the benchmark construction and all experiments are confined to this generator. The abstract's closing reference to 'modern AI-generated images' is motivational rather than a claim of tested generality. We will revise the abstract to state that findings on domain dependence and JPEG sensitivity apply to GPT-Image-2 generations and will add an explicit limitations paragraph noting that cross-generator validation remains future work. revision: partial
-
Referee: [Abstract] The central empirical claim (domain-dependent detector performance) rests on 8602 images from one generator whose text, font, and layout artifacts may differ systematically from those of Stable Diffusion, Midjourney, or other models on which the five evaluated detectors were presumably trained. This generator mismatch is load-bearing for the generalizability conclusion.
Authors: The central claim is domain dependence within the GPT-Image-2 benchmark, not a universal property of all AI text rendering. Because the detectors were evaluated zero-shot, any training mismatch is already implicit; we do not assert that the same patterns would hold for other generators. We will strengthen the limitations section to state that results are model-specific and that extending the benchmark to additional generators would be required for broader conclusions. revision: partial
Circularity Check
No circularity: purely empirical benchmark with no derivations or predictions
full rationale
The paper creates and evaluates a benchmark dataset of 8602 GPT-Image-2 images across six categories, testing five detectors in zero-shot mode. No equations, fitted parameters, predictions, or derivation chains appear. All reported results (domain-dependent performance, JPEG sensitivity) are direct empirical measurements on the released images. No self-citations are load-bearing for any central claim, and the work is self-contained as an empirical contribution without reducing any result to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Present and future generalization of synthetic image detectors
Pablo Bernabeu-Pérez, Enrique Lopez-Cuena, and Dario Garcia-Gasulla. Present and future generalization of synthetic image detectors. InJoint European Conference on Machine Learning and Knowledge Discovery in Databases, pages 3–20. Springer, 2025
2025
-
[2]
Textdiffuser: Diffusion models as text painters
Jingye Chen, Yupan Huang, Tengchao Lv, Lei Cui, Qifeng Chen, and Furu Wei. Textdiffuser: Diffusion models as text painters. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 9353–9387. Curran Associates, Inc., 2023
2023
-
[3]
Raising the bar of ai-generated image detection with clip, 2024
Davide Cozzolino, Giovanni Poggi, Riccardo Corvi, Matthias Nießner, and Luisa Verdoliva. Raising the bar of ai-generated image detection with clip, 2024. URL https://arxiv.org/ abs/2312.00195
-
[4]
Practical analyses of how common social media platforms and photo storage services handle uploaded images
Duc-Tien Dang-Nguyen, Vegard Velle Sjøen, Dinh-Hai Le, Thien-Phu Dao, Anh-Duy Tran, and Minh-Triet Tran. Practical analyses of how common social media platforms and photo storage services handle uploaded images. InInternational conference on multimedia modeling, pages 164–176. Springer, 2023
2023
-
[5]
ai_vs_real_image_detection
dima806. ai_vs_real_image_detection. Hugging Face model repository, 2024. Available at: https://huggingface.co/dima806/ai_vs_real_image_detection
2024
-
[6]
Deep learning based visually rich document content understanding: A survey.Artificial Intelligence Review, 2026
Yihao Ding, Soyeon Caren Han, Jean Lee, and Eduard Hovy. Deep learning based visually rich document content understanding: A survey.Artificial Intelligence Review, 2026. 11
2026
-
[7]
Pei Fu, Tongkun Guan, Zining Wang, Zhentao Guo, Chen Duan, Hao Sun, Boming Chen, Qianyi Jiang, Jiayao Ma, Kai Zhou, et al. Multimodal large language models for text-rich image understanding: A comprehensive review.Findings of the Association for Computational Linguistics: ACL 2025, pages 19941–19958, 2025
2025
-
[8]
Using facebook for image steganography
Jason Hiney, Tejas Dakve, Krzysztof Szczypiorski, and Kris Gaj. Using facebook for image steganography. In2015 10th international conference on availability, reliability and security, pages 442–447. IEEE, 2015
2015
-
[9]
Wildfake: A large-scale challenging dataset for ai-generated images detection, 2024
Yan Hong and Jianfu Zhang. Wildfake: A large-scale challenging dataset for ai-generated images detection, 2024. URLhttps://arxiv.org/abs/2402.11843
-
[10]
SuSy: Spatial-Based Synthetic Image Detection and Recognition Model
HPAI-BSC. SuSy: Spatial-Based Synthetic Image Detection and Recognition Model. Hugging Face model repository, 2024. Available at:https://huggingface.co/HPAI-BSC/SuSy
2024
-
[11]
Scifigdetect: A benchmark for ai-generated scientific figure detection, 2026
You Hu, Chenzhuo Zhao, Changfa Mo, Haotian Liu, and Xiaobai Li. Scifigdetect: A benchmark for ai-generated scientific figure detection, 2026. URL https://arxiv.org/abs/2604. 08211
2026
-
[12]
Icdar2019 competition on scanned receipt ocr and information extraction
Zheng Huang, Kai Chen, Jianhua He, Xiang Bai, Dimosthenis Karatzas, Shijian Lu, and CV Jawahar. Icdar2019 competition on scanned receipt ocr and information extraction. In2019 International Conference on Document Analysis and Recognition (ICDAR), pages 1516–1520. IEEE, 2019
2019
-
[13]
Enrico: A dataset for topic modeling of mobile ui designs
Luis A Leiva, Asutosh Hota, and Antti Oulasvirta. Enrico: A dataset for topic modeling of mobile ui designs. In22nd International Conference on Human-Computer Interaction with Mobile Devices and Services, pages 1–4, 2020
2020
-
[14]
Minesh Mathew, Viraj Bagal, Rubèn Tito, Dimosthenis Karatzas, Ernest Valveny, and C.V . Jawahar. Infographicvqa. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 1697–1706, January 2022
2022
-
[15]
Utkarsh Ojha, Yuheng Li, and Yong Jae Lee. Towards universal fake image detectors that generalize across generative models, 2024. URLhttps://arxiv.org/abs/2302.10174
-
[16]
Introducing ChatGPT Images 2.0, 2026
OpenAI. Introducing ChatGPT Images 2.0, 2026. URL https://openai.com/index/ introducing-chatgpt-images-2-0/. Accessed: 2026-05-25
2026
-
[17]
Sdxl: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis. In B. Kim, Y . Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y . Sun, editors, International Conference on Learning Representations, volume 2024, pages 1862–1874, 2024
2024
-
[18]
deepfake-detector-model-v1
PrithivMLmods. deepfake-detector-model-v1. Hugging Face model repository, 2025. Available at:https://huggingface.co/prithivMLmods/deepfake-detector-model-v1
2025
-
[19]
Revisiting tampered scene text detection in the era of generative ai
Chenfan Qu, Yiwu Zhong, Fengjun Guo, and Lianwen Jin. Revisiting tampered scene text detection in the era of generative ai. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 694–702, 2025
2025
-
[20]
Mitigating dataset bias in image captioning through clip confounder-free captioning network
Md Awsafur Rahman, Bishmoy Paul, Najibul Haque Sarker, Zaber Ibn Abdul Hakim, and Shaikh Anowarul Fattah. Artifact: A large-scale dataset with artificial and factual images for generalizable and robust synthetic image detection. In2023 IEEE International Conference on Image Processing (ICIP), pages 2200–2204, 2023. doi: 10.1109/ICIP49359.2023.10222083
-
[21]
Postersum: A multimodal benchmark for scientific poster summarization
Rohit Saxena, Pasquale Minervini, and Frank Keller. Postersum: A multimodal benchmark for scientific poster summarization. InProceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics, pages 1828–1844, 2025
2025
-
[22]
Rethink- ing the up-sampling operations in cnn-based generative network for generalizable deepfake detection
Chuangchuang Tan, Yao Zhao, Shikui Wei, Guanghua Gu, Ping Liu, and Yunchao Wei. Rethink- ing the up-sampling operations in cnn-based generative network for generalizable deepfake detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recogni- tion, pages 28130–28139, 2024. 12
2024
-
[23]
Sheng-Yu Wang, Oliver Wang, Richard Zhang, Andrew Owens, and Alexei A. Efros. Cnn- generated images are surprisingly easy to spot... for now. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020
2020
-
[24]
Detecting tampered scene text in the wild
Yuxin Wang, Hongtao Xie, Mengting Xing, Jing Wang, Shenggao Zhu, and Yongdong Zhang. Detecting tampered scene text in the wild. In Shai Avidan, Gabriel Brostow, Moustapha Cissé, Giovanni Maria Farinella, and Tal Hassner, editors,Computer Vision – ECCV 2022, pages 215–232, Cham, 2022. Springer Nature Switzerland. ISBN 978-3-031-19815-1
2022
-
[25]
Dire for diffusion-generated image detection, 2023
Zhendong Wang, Jianmin Bao, Wengang Zhou, Weilun Wang, Hezhen Hu, Hong Chen, and Houqiang Li. Dire for diffusion-generated image detection, 2023. URL https://arxiv.org/ abs/2303.09295
-
[26]
Aiforge-doc: A benchmark for detecting ai-forged tampering in financial and form documents, 2026
Jiaqi Wu, Yuchen Zhou, Muduo Xu, Zisheng Liang, Simiao Ren, Jiayu Xue, Meige Yang, Siying Chen, and Jingheng Huan. Aiforge-doc: A benchmark for detecting ai-forged tampering in financial and form documents, 2026. URLhttps://arxiv.org/abs/2602.20569
-
[27]
Gpt4o-receipt: A dataset and human study for ai-generated document forensics, 2026
Yan Zhang, Simiao Ren, Ankit Raj, En Wei, Dennis Ng, Alex Shen, Jiayu Xue, Yuxin Zhang, and Evelyn Marotta. Gpt4o-receipt: A dataset and human study for ai-generated document forensics, 2026. URLhttps://arxiv.org/abs/2603.11442
-
[28]
Image-based table recognition: data, model, and evaluation
Xu Zhong, Elaheh ShafieiBavani, and Antonio Jimeno Yepes. Image-based table recognition: data, model, and evaluation. InEuropean conference on computer vision, pages 564–580. Springer, 2020
2020
-
[29]
Genimage: A million-scale benchmark for detecting ai-generated image
Mingjian Zhu, Hanting Chen, Qiangyu YAN, Xudong Huang, Guanyu Lin, Wei Li, Zhijun Tu, Hailin Hu, Jie Hu, and Yunhe Wang. Genimage: A million-scale benchmark for detecting ai-generated image. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 77771–77782. Curra...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.