When Models Disagree: Rethinking LLM Evaluation for Public Comment Analysis
Pith reviewed 2026-06-29 12:20 UTC · model grok-4.3
The pith
Disagreement among LLMs on the same public comments signals interpretive complexity that accuracy metrics alone cannot detect.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
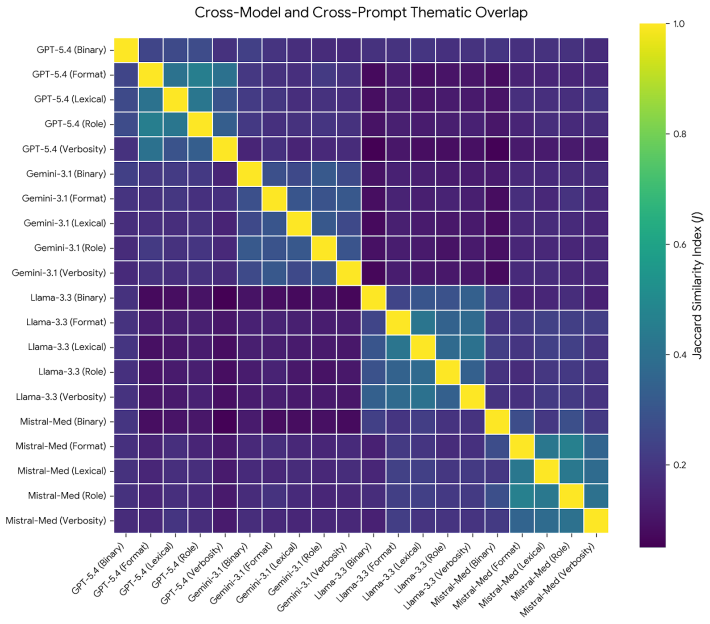
The paper establishes that multi-model disagreement functions as a diagnostic of interpretive complexity in public comment corpora, and that directing human attention to high-disagreement inputs via an Interpretive Audit Pipeline supplies a necessary complement to stance-accuracy evaluation against validated subsets.
What carries the argument
The Interpretive Audit Pipeline, which flags inputs for human review when multiple LLMs produce divergent thematic categorizations of the same comments.
If this is right
- Inter-model thematic divergence exceeds within-model variation from prompt changes.
- An expert rubric can suppress visible disagreement without resolving the underlying interpretive differences.
- Human annotators frequently introduce framings absent from the collective model output after reviewing model labels.
- Evaluation for interpretive coding tasks requires metrics that capture disagreement in addition to accuracy against ground truth.
Where Pith is reading between the lines
- Single-model deployments for comment analysis risk systematically under-representing arguments that only appear in alternative framings.
- The method could extend to other domains where LLMs perform interpretive coding of ambiguous text, such as legal document review or qualitative social science data.
- Agencies might need to maintain ensembles of models rather than optimize a single model to a fixed rubric.
Load-bearing premise
Observed differences between models on the same comments mainly reflect real ambiguity in the comments rather than model-specific training artifacts or prompt effects that lack substantive meaning.
What would settle it
A controlled study in which multiple human experts independently label the high-disagreement subset and show low inter-expert agreement rates comparable to the models would undermine the claim that model divergence tracks genuine interpretive complexity.
Figures
read the original abstract
Federal agencies are deploying large language models (LLMs) to categorize public comment corpora, where the model's organization of the record shapes what policymakers see and which arguments register. Standard evaluation, anchored on stance accuracy against a small validated set, cannot detect when different models produce materially different categorizations of the same public input. We propose an Interpretive Audit Pipeline that treats multi-model disagreement as diagnostic of interpretive complexity and directs human review toward genuinely ambiguous public input. Analyzing 1,260 public comments on a federal USDA docket across four LLMs, we find that inter-model thematic divergence exceeds within-model prompt variation, and that an expert rubric suppresses deep interpretive disagreement without resolving it. In a two-stage labeling study on a stratified 40-comment subsample, four LLMs and a human annotator labeled independently and then revised after seeing the others' labels. Revision behavior varied across labelers, and the human annotator's revisions frequently introduced framings absent from the ensemble's collective output. We argue disagreement-based evaluation is a necessary complement to accuracy metrics for LLM-assisted interpretive coding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard accuracy metrics against validated sets are insufficient for evaluating LLMs in interpretive coding of public comments, as different models can produce materially different categorizations of the same input. It proposes an Interpretive Audit Pipeline that treats multi-model disagreement as a diagnostic for interpretive complexity, directing human review accordingly. On 1,260 USDA docket comments analyzed with four LLMs, inter-model thematic divergence exceeds within-model prompt variation; an expert rubric suppresses but does not resolve deep disagreement. A two-stage labeling study on a stratified 40-comment subsample shows varying revision behaviors across LLMs and a human annotator, with the human frequently introducing framings absent from the ensemble. The authors conclude that disagreement-based evaluation is a necessary complement to accuracy metrics for LLM-assisted interpretive coding.
Significance. If the findings hold, the work offers a concrete, scalable approach for identifying ambiguous public input in high-stakes regulatory contexts where model outputs influence which arguments reach policymakers. The use of a real federal docket, the 1,260-comment corpus, the stratified 40-comment subsample, and the explicit comparison of inter-model vs. within-model variation provide empirical grounding. The two-stage revision design yields observable differences in how humans and models respond to ensemble outputs. These elements strengthen the case for supplementing accuracy-based evaluation in interpretive tasks.
major comments (2)
- [Abstract (two-stage labeling study) and Results] The load-bearing assumption that inter-model thematic divergence primarily reflects genuine interpretive complexity in the comments (rather than stable model-specific differences in training corpora, alignment, or framing preferences) is not tested against an independent ambiguity metric. The two-stage labeling study on the 40-comment stratified subsample demonstrates that disagreement persists after rubric application and that humans introduce novel framings, but without correlating model disagreement to expert-rated ambiguity scores or inter-human agreement rates on the same comments, the diagnostic claim remains unverified.
- [Abstract and Methods] The directional finding that inter-model divergence exceeds within-model prompt variation on the full 1,260 comments lacks reported details on the exact disagreement metrics, prompt templates, statistical controls for multiple comparisons, or how thematic divergence was operationalized. This limits verifiability of the central empirical support for the Interpretive Audit Pipeline.
minor comments (2)
- [Abstract] The four LLMs are not named in the abstract; naming them (and providing prompt templates) in the main text would improve reproducibility.
- [Introduction] The manuscript introduces the term 'Interpretive Audit Pipeline' as a novel contribution; a brief comparison to related work on ensemble disagreement in NLP (e.g., uncertainty estimation or active learning) would clarify its distinctiveness.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, indicating planned revisions where appropriate. Our responses focus on strengthening the manuscript's claims and verifiability while remaining faithful to the study design and data collected.
read point-by-point responses
-
Referee: [Abstract (two-stage labeling study) and Results] The load-bearing assumption that inter-model thematic divergence primarily reflects genuine interpretive complexity in the comments (rather than stable model-specific differences in training corpora, alignment, or framing preferences) is not tested against an independent ambiguity metric. The two-stage labeling study on the 40-comment stratified subsample demonstrates that disagreement persists after rubric application and that humans introduce novel framings, but without correlating model disagreement to expert-rated ambiguity scores or inter-human agreement rates on the same comments, the diagnostic claim remains unverified.
Authors: We agree that correlating model disagreement with an independent ambiguity metric would strengthen the diagnostic interpretation. The two-stage study shows persistent disagreement post-rubric and that the human annotator introduces framings absent from the ensemble, which provides evidence against the divergence being purely model-specific bias. However, the study did not collect expert-rated ambiguity scores. In revision we will add a dedicated limitations paragraph explicitly noting this gap and recommending future validation against such metrics. We will also clarify that the pipeline is proposed as a practical complement that flags cases for human review rather than claiming to directly measure ambiguity. revision: partial
-
Referee: [Abstract and Methods] The directional finding that inter-model divergence exceeds within-model prompt variation on the full 1,260 comments lacks reported details on the exact disagreement metrics, prompt templates, statistical controls for multiple comparisons, or how thematic divergence was operationalized. This limits verifiability of the central empirical support for the Interpretive Audit Pipeline.
Authors: We accept that the current Methods section is insufficiently detailed for full reproducibility and verifiability. In the revised manuscript we will expand the Methods and add an appendix containing: the precise disagreement metrics (including how thematic divergence was quantified), the complete prompt templates used for each model, the statistical procedures and any controls for multiple comparisons, and the operational definition of thematic divergence. These additions will directly support the central empirical claim. revision: yes
- Inter-human agreement rates cannot be computed or reported because the two-stage labeling study used only a single human annotator.
Circularity Check
No circularity: purely empirical comparisons with no derivations or self-referential definitions
full rationale
The paper reports direct empirical measurements of inter-model thematic divergence on 1,260 comments, within-model prompt variation, and revision behavior in a two-stage labeling study. No equations, fitted parameters, normalization choices, or uniqueness theorems appear in the provided text. The central claim that disagreement-based evaluation complements accuracy metrics rests on these observed differences rather than any reduction to inputs by construction. Self-citations, if present, are not load-bearing for the reported findings. This is the expected non-finding for an empirical methods paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Inter-model disagreement on thematic categorization of public comments primarily indicates genuine interpretive complexity rather than model-specific artifacts.
invented entities (1)
-
Interpretive Audit Pipeline
no independent evidence
Reference graph
Works this paper leans on
-
[1]
who is the right homeless client?
doi: 10.1145/3544548.3580645. 11 Naveena Karusala, Sohini Upadhyay, Rajesh Veeraraghavan, and Krzysztof Z Gajos. Understanding contestability on the margins: Implications for the design of algorithmic decision-making in public services. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems, pages 1–16, 2024. Andrei A Kirilenko, Sh...
-
[2]
do not support
Support/Oppose:Does the commenter support or oppose the rule? Read the ENTIRE comment first. “do not support” = Oppose. Output: Support, Oppose 2.Main Argument:What’s their central issue? (1–2 words) 3.Argument Expanded:Explain the argument in one sentence
-
[4]
comment_index
Confidence:How much textual support backs these categorizations? High = position is clear, Medium = some inference needed, Low = ambiguous or insufficient text. Confidence = evidence in text, not how certain you feel. You will receive multiple comments at once. OUTPUT FORMAT: Respond ONLY with a valid JSON array. No preamble, no explanation, no markdown. ...
-
[5]
do not support
Support/Oppose:Does the commenter support or oppose the rule? Read the ENTIRE comment first. “do not support” = Oppose. Output: Support, Oppose 2.Main Argument:What’s their primary concern? (1–2 words) 3.Argument Expanded:Explain the argument in one sentence
-
[6]
Check organization field first, then comment text
Submitter Type:Business, Nonprofit, Individual, Government, or Unknown. Check organization field first, then comment text
-
[7]
comment_index
Confidence:How much textual evidence supports these classifications? High = position is clear, Medium = some inference needed, Low = ambiguous or insufficient text. Confidence = evidence in text, not how certain you feel. You will receive multiple comments at once. OUTPUT FORMAT: Respond ONLY with a valid JSON array. No preamble, no explanation, no markdo...
2016
-
[8]
PROPOSED RULE:{{RULE_TEXT}} CODING RUBRIC - 17 CATEGORIES:
-
[9]
Support/Oppose: support Main Argument: Food access Definition: Mentions availability, accessibility (proximity/travel), affordability (price), accommodation (hours/payment types), and acceptability (attitudes) regarding healthy food
-
[10]
Support/Oppose: support Main Argument: Access to Healthy Food Definition: General belief that the SNAP retailer rule will increase access to healthy food
-
[11]
obesity epidemic
Support/Oppose: support Main Argument: relashionship between nutrition and health Definition: Mentions benefits of a healthy diet, consequences of unhealthy eating (chronic disease), and the U.S. obesity epidemic
-
[12]
Support/Oppose: support Main Argument: Nutrition Definition: Improved nutrition attributable to the SNAP retailer rule
-
[13]
Support/Oppose: support Main Argument: Health Definition: Improved health outcomes attributable to the SNAP retailer rule
-
[14]
Support/Oppose: support Main Argument: Time Definition: Comments regarding the time it takes to shop for, prepare, and cook healthy foods
-
[15]
Support/Oppose: support Main Argument: Access Associated with Intake Definition: Discussion on whether healthy food access is or is not associated with healthy food intake
-
[16]
Support/Oppose: oppose Main Argument: SNAP Retailer Rule Definitions Definition: Stores’ concerns about specific SNAP retailer rule definitions, including retail food stores, multiple food ingredients, and staple foods
-
[17]
Support/Oppose: oppose Main Argument: Reduced Food Access Definition: Concerns that stores will withdraw from SNAP or close, resulting in reduced food access
-
[18]
Support/Oppose: oppose Main Argument: Cost-Benefit Argument Definition: Claims the rule hurts businesses by increasing store costs, decreasing profits, and potentially reducing workforces
-
[19]
Support/Oppose: oppose Main Argument: Doubting Effectiveness of the rule Definition: Doubts that the rule will promote nutrition (e.g., lack of customer demand for healthy food means they won’t buy it). 17
-
[20]
Support/Oppose: oppose Main Argument: Space Concerns Definition: Lack of space in store to adhere to depth-of-stock requirements
-
[21]
Support/Oppose: oppose Main Argument: Perishability Definition: Concerns regarding how long items keep fresh (e.g., produce spoiling too quickly)
-
[22]
Support/Oppose: oppose Main Argument: Rule Ambiguity Definition: Claims that the SNAP retailer rule needs to be more clearly defined
-
[23]
Support/Oppose: oppose Main Argument: Free Market Definition: Belief that the government is interfering with free market principles of supply and demand
-
[24]
Support/Oppose: oppose Main Argument: Distribution and purchasing and infrastructure Definition: Lack of food distributors and purchasing infrastructure to order and stock staple food items
-
[25]
CLASSIFICATION TASK: For each comment, you will read the ENTIRE comment and provide 4 classifications:
Support/Oppose: oppose Main Argument: Equipment and Supplies Definition: Concerns about lack of adequate equipment and supplies, including coolers, refrigeration, and shelving. CLASSIFICATION TASK: For each comment, you will read the ENTIRE comment and provide 4 classifications:
-
[26]
Unknown" - Valid values:
**support_oppose** - Primary Goal: Match the comment’s core message to a Definition in the rubric above - If a match is found: Assign the corresponding support_oppose value from the matched category - Handling Multiple Matches: If a comment contains arguments aligning with multiple definitions, choose the definition that represents the PRIMARY or most emp...
-
[27]
Unknown": Assign a 1-2 word summary of the comment’s primary concern (e.g.,
**main_argument** - If you found a rubric match: Copy the EXACT main_argument text from the matched category above - If support_oppose is "Unknown": Assign a 1-2 word summary of the comment’s primary concern (e.g., "Cost", "Efficiency", "Clarity")
-
[28]
**submitter_type** (from comment data/text) - Choose ONE category from this definitive list: * Retail/Business * Nonprofit * Private Citizen * Government * Medical Field * Unknown (if organization field is empty AND comment text provides no clear indication) - Use the organization field FIRST; if empty, analyze the comment text - Look for: company names, ...
-
[29]
Unknown" IMPORTANT NOTES: - Read the ENTIRE comment before classifying -
**confidence** (your judgment of match quality) - Rate the quality of the match between the comment’s argument and the chosen Definition from the rubric: - High: The comment’s language and argument are highly similar to the rubric Definition. The comment is an unambiguous example of that argument. - Medium: There is a clear overlap or strong conceptual li...
2016
-
[30]
Look at your original label (your_blind_label) and the LLM union side by side
-
[31]
Decide what to do — fill the decision column with ONE of: Keep my label; Change to one shown above; Change to a different label
-
[32]
If you changed (either option 2 or 3), fill final_label with your new label and final_evidencewith one short quote anchoring it. 21
-
[33]
***Confidential Business Information Redacted***
Fill the justification column — one or two sentences on WHY you held or changed. This is the most analytically valuable part for us. Important: • If you keep your label, justification should explain why the LLM concepts didn’t change your reading. • If you change, justification should explain what shifted you. • Don’t feel pressure to change just because ...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.