LiveStarPro: Proactive Streaming Video Understanding with Hierarchical Memory for Long-Horizon Streams
Pith reviewed 2026-06-27 01:10 UTC · model grok-4.3
The pith
LiveStarPro enables proactive understanding of long video streams using verification decoding, causal masks, and hierarchical memory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
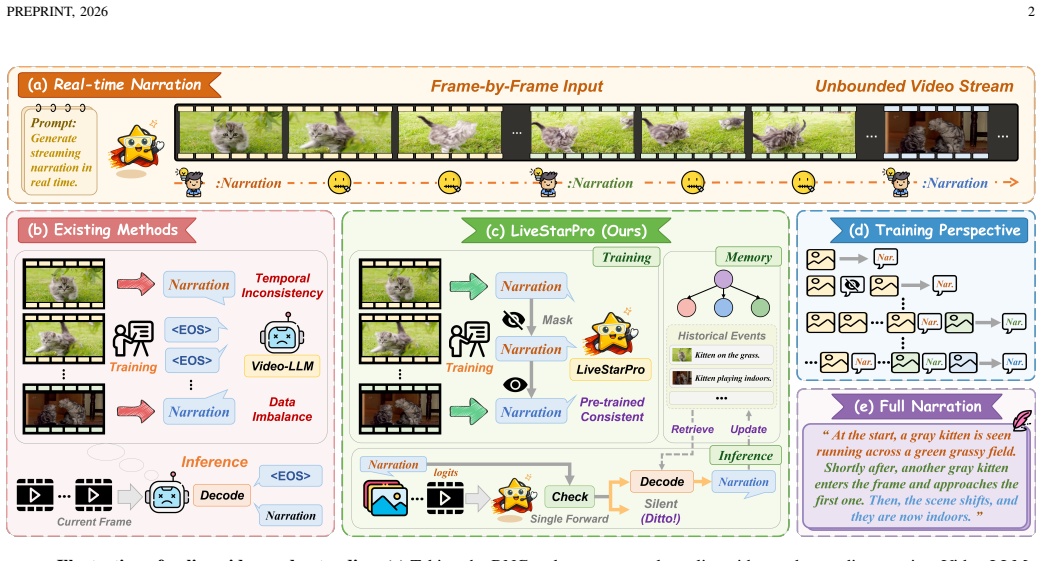
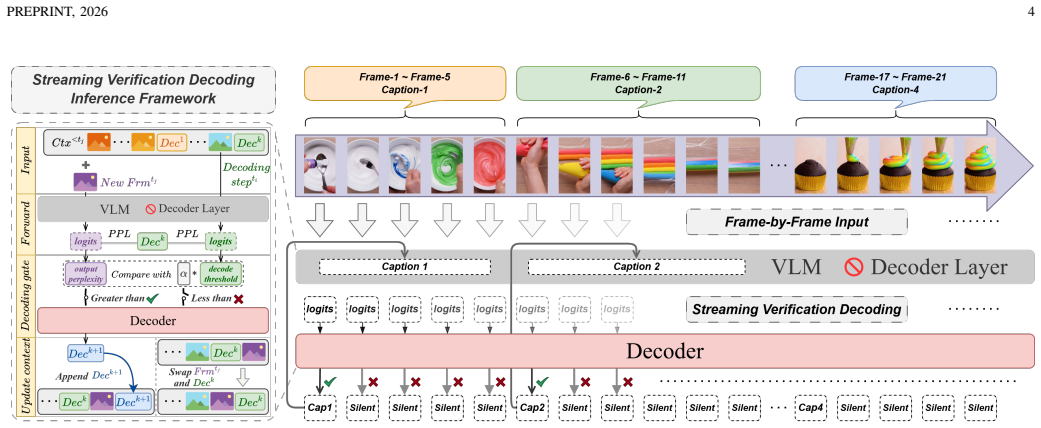
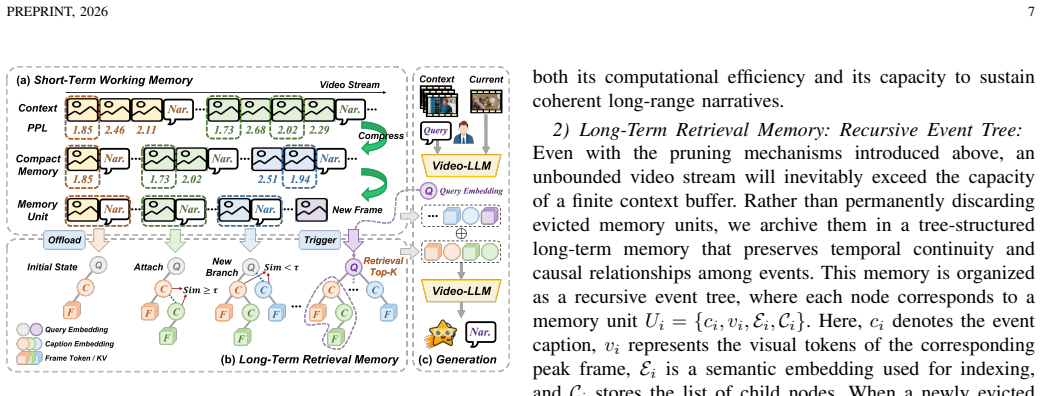
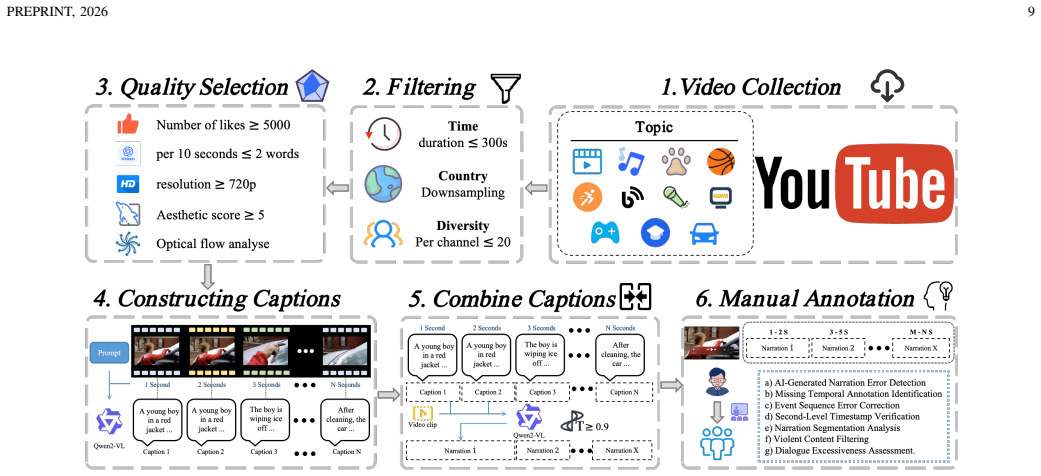
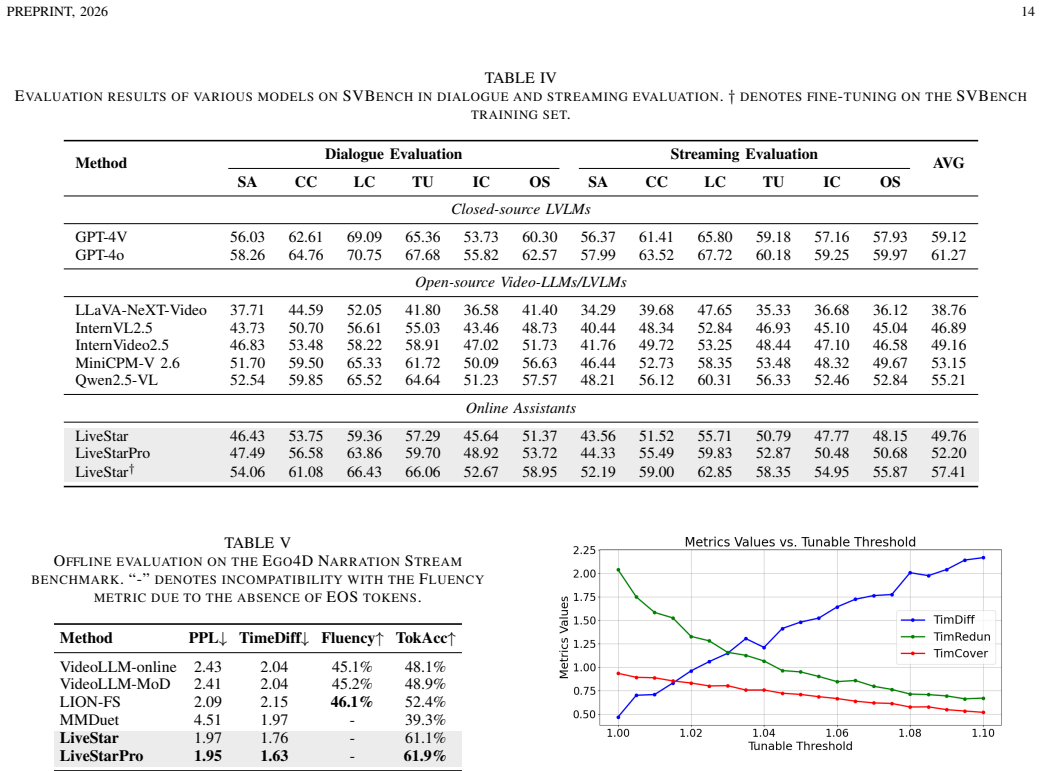
LiveStarPro is designed for proactive video understanding over long-horizon streams through Streaming Verification Decoding that identifies response timing via single-pass perplexity verification, Streaming Causal Attention Masks that enforce incremental alignment over variable-length streams, and Tree-Structured Hierarchical Memory that organizes evicted historical information into event chains for efficient retrieval from unbounded streams, as evaluated on the OmniStarPro benchmark.
What carries the argument
Tree-Structured Hierarchical Memory (TSHM), a recursive architecture that turns evicted history into event chains to allow retrieval from effectively unbounded video streams.
If this is right
- The model can determine appropriate response times through perplexity verification in a single pass without needing special silence tokens.
- Training with causal attention masks ensures proper video-language alignment even as streams vary in length.
- Historical information is organized into retrievable event chains, supporting memory over hour-scale streams.
- The streaming key-value cache provides a 1.58 times speedup in inference compared to the model without it.
- Performance gains include 28.9 percent better semantic correctness and 18.2 percent less timing error on the benchmark.
Where Pith is reading between the lines
- This design could be adapted for other continuous data streams such as audio or text conversations.
- Applications in live event analysis or security monitoring might see direct benefits from the proactive timing and long memory.
- Future tests could combine this memory structure with other large model architectures to check if the gains hold.
- The benchmark's coverage of diverse scenarios suggests it could serve as a standard for evaluating online video models.
Load-bearing premise
The three components work together to fix timing, alignment, and memory problems at the same time, and the new benchmark accurately represents real long video streams.
What would settle it
Running the system on continuous live video feeds where it shows no reduction in timing errors or loses semantic accuracy over time compared to existing approaches.
Figures

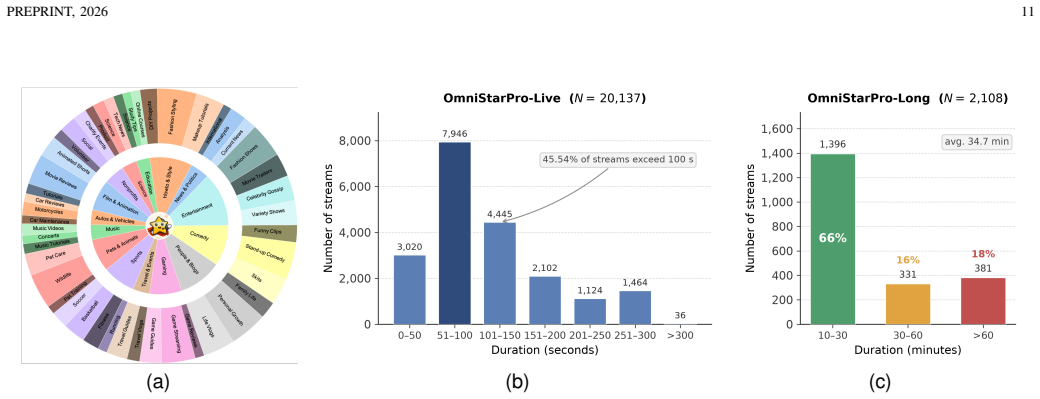
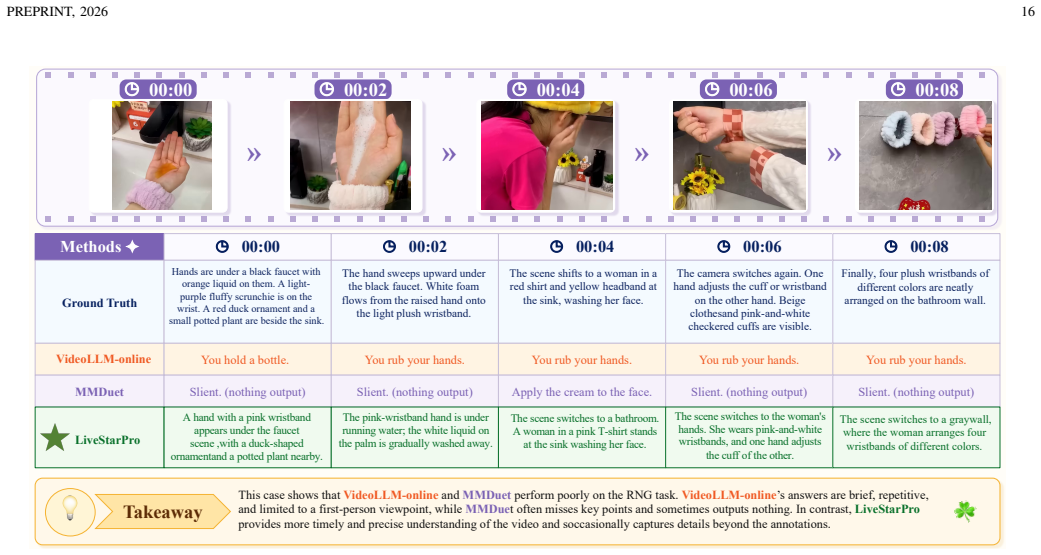
read the original abstract
Despite the remarkable progress of Video Large Language Models (Video-LLMs), current online architectures still struggle to simultaneously process continuous video streams, decide autonomously when to respond, and preserve long-horizon contextual memory. These obstacles undermine real-time responsiveness and cause severe forgetting throughout prolonged interactions. In this work, we introduce LiveStarPro, a live streaming assistant that is designed for proactive video understanding over long-horizon streams. The design of LiveStarPro rests on three complementary components. The first component is Streaming Verification Decoding (SVeD), an inference framework that identifies the appropriate response timing through single-pass perplexity verification, thereby eliminating the dependency on explicit silence tokens. The second component is Streaming Causal Attention Masks (SCAM), a training strategy that enforces incremental video-language alignment over variable-length streams. The third component is Tree-Structured Hierarchical Memory (TSHM), a recursive memory architecture that organizes evicted historical information into event chains and consequently enables efficient retrieval from effectively unbounded video streams. To facilitate a comprehensive evaluation under realistic online conditions, we further present OmniStarPro, a large-scale benchmark that spans 15 diverse real-world scenarios and that extends to hour-scale streams for the assessment of long-term recall. Extensive experiments demonstrate that LiveStarPro consistently surpasses existing methods, attaining a 28.9% improvement in semantic correctness and an 18.2% reduction in timing error, while its streaming key-value cache further yields a 1.58x inference speedup over the same model without caching. The model and the code are publicly available at https://github.com/sotayang/LiveStarPro.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LiveStarPro, a proactive streaming video understanding system for long-horizon streams. It consists of three components: Streaming Verification Decoding (SVeD) to determine response timing via single-pass perplexity verification without silence tokens; Streaming Causal Attention Masks (SCAM) as a training strategy for incremental video-language alignment; and Tree-Structured Hierarchical Memory (TSHM) to recursively organize evicted frames into event chains for efficient retrieval. The work also presents the OmniStarPro benchmark spanning 15 scenarios and hour-scale streams. Experiments report 28.9% gains in semantic correctness, 18.2% reduction in timing error, and 1.58x speedup from the streaming KV cache, with code and model released publicly.
Significance. If the empirical gains and long-horizon claims hold under rigorous evaluation, the work would address key open problems in online Video-LLMs (autonomous response timing, incremental alignment, and scalable memory) with a concrete system and benchmark. The public code release is a clear strength for reproducibility and follow-on work.
major comments (1)
- [Abstract (TSHM description)] Abstract (TSHM description): the central claim that TSHM enables 'efficient retrieval from effectively unbounded video streams' is load-bearing for the long-horizon results (28.9% semantic gain), yet no scaling analysis, query complexity bounds, tree depth, eviction policy, or interaction with the streaming KV cache is provided. Without these, it remains possible that retrieval cost grows linearly with stream length on the hour-scale OmniStarPro streams, undermining the 'proactive streaming over long-horizon' contribution.
minor comments (1)
- [Abstract] The abstract states that 'the model and the code are publicly available at https://github.com/sotayang/LiveStarPro' but provides no commit hash, license, or reproducibility checklist; this should be expanded in the final version.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the TSHM description. We address the point below and will strengthen the manuscript with additional analysis.
read point-by-point responses
-
Referee: [Abstract (TSHM description)] Abstract (TSHM description): the central claim that TSHM enables 'efficient retrieval from effectively unbounded video streams' is load-bearing for the long-horizon results (28.9% semantic gain), yet no scaling analysis, query complexity bounds, tree depth, eviction policy, or interaction with the streaming KV cache is provided. Without these, it remains possible that retrieval cost grows linearly with stream length on the hour-scale OmniStarPro streams, undermining the 'proactive streaming over long-horizon' contribution.
Authors: We agree that the current version lacks explicit scaling analysis, complexity bounds, tree depth characterization, eviction policy details, and KV-cache interaction for TSHM. This is a valid observation. In the revision we will insert a dedicated subsection (likely in Section 3.3 or 4) that (i) derives the O(log N) query complexity arising from the recursive event-chain tree, (ii) reports observed tree depths on the hour-scale OmniStarPro streams (typically 4–6 levels), (iii) specifies the eviction policy based on event-chain importance scores, and (iv) explains how TSHM retrieval is fused with the streaming KV cache to avoid linear cost. These additions will directly support the long-horizon claims. revision: yes
Circularity Check
No circularity: descriptive system architecture with no derivations or self-referential fits
full rationale
The provided abstract and description contain no equations, derivations, fitted parameters presented as predictions, or self-citation chains that bear the central claims. The three components (SVeD, SCAM, TSHM) are introduced as design choices whose performance is evaluated empirically on the OmniStarPro benchmark; the reported gains (28.9% semantic correctness, 18.2% timing error reduction, 1.58x speedup) are external measurements rather than quantities forced by construction from the inputs. No load-bearing step reduces to a self-definition or renamed known result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Z. Chen, W. Wang, Y . Cao, Y . Liu, Z. Gao, E. Cui, J. Zhu, S. Ye, H. Tian, Z. Liuet al., “Expanding performance boundaries of open- source multimodal models with model, data, and test-time scaling,” arXiv preprint arXiv:2412.05271, 2024
Pith/arXiv arXiv 2024
-
[2]
Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution,
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Ge, Y . Fan, K. Dang, M. Du, X. Ren, R. Men, D. Liu, C. Zhou, J. Zhou, and J. Lin, “Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution,”arXiv preprint arXiv:2409.12191, 2024
Pith/arXiv arXiv 2024
-
[3]
Minicpm-v: A gpt-4v level mllm on your phone,
Y . Yao, T. Yu, A. Zhang, C. Wang, J. Cui, H. Zhu, T. Cai, H. Li, W. Zhao, Z. Heet al., “Minicpm-v: A gpt-4v level mllm on your phone,”arXiv preprint arXiv:2408.01800, 2024
Pith/arXiv arXiv 2024
-
[4]
P. Zhang, X. Dong, Y . Zang, Y . Cao, R. Qian, L. Chen, Q. Guo, H. Duan, B. Wang, L. Ouyanget al., “Internlm-xcomposer-2.5: A versatile large vision language model supporting long-contextual input and output,” arXiv preprint arXiv:2407.03320, 2024
Pith/arXiv arXiv 2024
-
[5]
Chatglm: A family of large language models from glm-130b to glm-4 all tools,
T. GLM, A. Zeng, B. Xu, B. Wang, C. Zhang, D. Yin, D. Zhang, D. Rojas, G. Feng, H. Zhaoet al., “Chatglm: A family of large language models from glm-130b to glm-4 all tools,”arXiv preprint arXiv:2406.12793, 2024
Pith/arXiv arXiv 2024
-
[6]
K. Ataallah, X. Shen, E. Abdelrahman, E. Sleiman, D. Zhu, J. Ding, and M. Elhoseiny, “Minigpt4-video: Advancing multimodal llms for video understanding with interleaved visual-textual tokens,”arXiv preprint arXiv:2404.03413, 2024
arXiv 2024
-
[7]
Video-chatgpt: Towards detailed video understanding via large vision and language models,
M. Maaz, H. Rasheed, S. Khan, and F. S. Khan, “Video-chatgpt: Towards detailed video understanding via large vision and language models,” arXiv preprint arXiv:2306.05424, 2023
Pith/arXiv arXiv 2023
-
[8]
Videochat: Chat-centric video understanding,
K. Li, Y . He, Y . Wang, Y . Li, W. Wang, P. Luo, Y . Wang, L. Wang, and Y . Qiao, “Videochat: Chat-centric video understanding,”arXiv preprint arXiv:2305.06355, 2023
Pith/arXiv arXiv 2023
-
[9]
Vid2seq: Large-scale pretraining of a visual language model for dense video captioning,
A. Yang, A. Nagrani, P. H. Seo, A. Miech, J. Pont-Tuset, I. Laptev, J. Sivic, and C. Schmid, “Vid2seq: Large-scale pretraining of a visual language model for dense video captioning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 10 714–10 726
2023
-
[10]
Internvideo: General video foundation models via gen- erative and discriminative learning,
Y . Wang, K. Li, Y . Li, Y . He, B. Huang, Z. Zhao, H. Zhang, J. Xu, Y . Liu, Z. Wanget al., “Internvideo: General video foundation models via gen- erative and discriminative learning,”arXiv preprint arXiv:2212.03191, 2022
Pith/arXiv arXiv 2022
-
[11]
Videollama 2: Advancing spatial- temporal modeling and audio understanding in video-llms,
Z. Cheng, S. Leng, H. Zhang, Y . Xin, X. Li, G. Chen, Y . Zhu, W. Zhang, Z. Luo, D. Zhaoet al., “Videollama 2: Advancing spatial- temporal modeling and audio understanding in video-llms,”arXiv preprint arXiv:2406.07476, 2024
Pith/arXiv arXiv 2024
-
[12]
Oryx mllm: On- demand spatial-temporal understanding at arbitrary resolution,
Z. Liu, Y . Dong, Z. Liu, W. Hu, J. Lu, and Y . Rao, “Oryx mllm: On- demand spatial-temporal understanding at arbitrary resolution,”arXiv preprint arXiv:2409.12961, 2024
arXiv 2024
-
[13]
Timechat: A time-sensitive multimodal large language model for long video understanding,
S. Ren, L. Yao, S. Li, X. Sun, and L. Hou, “Timechat: A time-sensitive multimodal large language model for long video understanding,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 14 313–14 323
2024
-
[14]
Flash-vstream: Memory-based real-time understanding for long video streams,
H. Zhang, Y . Wang, Y . Tang, Y . Liu, J. Feng, J. Dai, and X. Jin, “Flash-vstream: Memory-based real-time understanding for long video streams,”arXiv preprint arXiv:2406.08085, 2024
arXiv 2024
-
[15]
Moviechat+: Question-aware sparse memory for long video question answering,
E. Song, W. Chai, T. Ye, J.-N. Hwang, X. Li, and G. Wang, “Moviechat+: Question-aware sparse memory for long video question answering,” arXiv preprint arXiv:2404.17176, 2024
arXiv 2024
-
[16]
Ma-lmm: Memory-augmented large multimodal model for long-term video understanding,
B. He, H. Li, Y . K. Jang, M. Jia, X. Cao, A. Shah, A. Shrivastava, and S.-N. Lim, “Ma-lmm: Memory-augmented large multimodal model for long-term video understanding,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 13 504–13 514
2024
-
[17]
Longllava: Scaling multi-modal llms to 1000 images efficiently via hybrid architecture,
X. Wang, D. Song, S. Chen, C. Zhang, and B. Wang, “Longllava: Scaling multi-modal llms to 1000 images efficiently via hybrid architecture,”
-
[18]
Available: https://arxiv.org/abs/2409.02889
[Online]. Available: https://arxiv.org/abs/2409.02889
-
[19]
Longvila: Scaling long-context visual language models for long videos,
F. Xue, Y . Chen, D. Li, Q. Hu, L. Zhu, X. Li, Y . Fang, H. Tang, S. Yang, Z. Liu, Y . He, H. Yin, P. Molchanov, J. Kautz, L. Fan, Y . Zhu, Y . Lu, and S. Han, “Longvila: Scaling long-context visual language models for long videos,”null, 2024
2024
-
[20]
Long context transfer from language to vision,
P. Zhang, K. Zhang, B. Li, G. Zeng, J. Yang, Y . Zhang, Z. Wang, H. Tan, C. Li, and Z. Liu, “Long context transfer from language to vision,”arXiv preprint arXiv:2406.16852, 2024
Pith/arXiv arXiv 2024
-
[21]
Videollm-online: Online video large language model for streaming video,
J. Chen, Z. Lv, S. Wu, K. Q. Lin, C. Song, D. Gao, J.-W. Liu, Z. Gao, D. Mao, and M. Z. Shou, “Videollm-online: Online video large language model for streaming video,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 18 407–18 418. PREPRINT, 2026 17
2024
-
[22]
Videollm-mod: Efficient video-language streaming with mixture-of-depths vision computation,
S. Wu, J. Chen, K. Q. Lin, Q. Wang, Y . Gao, Q. Xu, T. Xu, Y . Hu, E. Chen, and M. Z. Shou, “Videollm-mod: Efficient video-language streaming with mixture-of-depths vision computation,”Advances in Neural Information Processing Systems, vol. 37, pp. 109 922–109 947, 2024
2024
-
[23]
Lion-fs: Fast & slow video-language thinker as online video assistant,
W. Li, B. Hu, R. Shao, L. Shen, and L. Nie, “Lion-fs: Fast & slow video-language thinker as online video assistant,”arXiv preprint arXiv:2503.03663, 2025
arXiv 2025
-
[24]
Stream- mind: Unlocking full frame rate streaming video dialogue through event- gated cognition,
X. Ding, H. Wu, Y . Yang, S. Jiang, D. Bai, Z. Chen, and T. Cao, “Stream- mind: Unlocking full frame rate streaming video dialogue through event- gated cognition,”arXiv preprint arXiv:2503.06220, 2025
arXiv 2025
-
[25]
Y . Wang, X. Meng, Y . Wang, J. Liang, J. Wei, H. Zhang, and D. Zhao, “Videollm knows when to speak: Enhancing time-sensitive video com- prehension with video-text duet interaction format,”arXiv preprint arXiv:2411.17991, 2024
arXiv 2024
-
[26]
Streaming long video understanding with large language models,
R. Qian, X. Dong, P. Zhang, Y . Zang, S. Ding, D. Lin, and J. Wang, “Streaming long video understanding with large language models,”Ad- vances in Neural Information Processing Systems, vol. 37, pp. 119 336– 119 360, 2024
2024
-
[27]
Streaming dense video captioning,
X. Zhou, A. Arnab, S. Buch, S. Yan, A. Myers, X. Xiong, A. Nagrani, and C. Schmid, “Streaming dense video captioning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 18 243–18 252
2024
-
[28]
Streaming video understanding and multi-round interaction with memory-enhanced knowledge,
H. Xiong, Z. Yang, J. Yu, Y . Zhuge, L. Zhang, J. Zhu, and H. Lu, “Streaming video understanding and multi-round interaction with memory-enhanced knowledge,”arXiv preprint arXiv:2501.13468, 2025
arXiv 2025
-
[29]
Ego4d: Around the world in 3,000 hours of egocentric video,
K. Grauman, A. Westbury, E. Byrne, Z. Chavis, A. Furnari, R. Girdhar, J. Hamburger, H. Jiang, M. Liu, X. Liuet al., “Ego4d: Around the world in 3,000 hours of egocentric video,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 18 995–19 012
2022
-
[30]
Soccernet: A scalable dataset for action spotting in soccer videos,
S. Giancola, M. Amine, T. Dghaily, and B. Ghanem, “Soccernet: A scalable dataset for action spotting in soccer videos,” inProceedings of the IEEE conference on computer vision and pattern recognition workshops, 2018, pp. 1711–1721
2018
-
[31]
Svbench: A benchmark with temporal multi-turn dialogues for streaming video understanding,
Z. Yang, Y . Hu, Z. Du, D. Xue, S. Qian, J. Wu, F. Yang, W. Dong, and C. Xu, “Svbench: A benchmark with temporal multi-turn dialogues for streaming video understanding,”arXiv preprint arXiv:2502.10810, 2025
arXiv 2025
-
[32]
Ovo-bench: How far is your video- llms from real-world online video understanding?
Y . Li, J. Niu, Z. Miao, C. Ge, Y . Zhou, Q. He, X. Dong, H. Duan, S. Ding, R. Qianet al., “Ovo-bench: How far is your video- llms from real-world online video understanding?”arXiv preprint arXiv:2501.05510, 2025
arXiv 2025
-
[33]
Livestar: Live streaming assistant for real-world online video understanding,
Z. Yang, K. Zhang, Y . Hu, B. Wang, S. Qian, B. Wen, F. Yang, T. Gao, W. Dong, and C. Xu, “Livestar: Live streaming assistant for real-world online video understanding,”Advances in Neural Information Processing Systems, vol. 38, pp. 31 266–31 304, 2026
2026
-
[34]
Llama 2: Open foundation and fine-tuned chat models,
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosaleet al., “Llama 2: Open foundation and fine-tuned chat models,”arXiv preprint arXiv:2307.09288, 2023
Pith/arXiv arXiv 2023
-
[35]
Gemini: a family of highly capable multimodal models,
G. Team, R. Anil, S. Borgeaud, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, K. Millicanet al., “Gemini: a family of highly capable multimodal models,”arXiv preprint arXiv:2312.11805, 2023
Pith/arXiv arXiv 2023
-
[36]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[37]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Rayet al., “Training language models to follow instructions with human feedback,”Advances in neural information processing systems, vol. 35, pp. 27 730–27 744, 2022
2022
-
[38]
Improving language understanding by generative pre-training,
A. Radford, K. Narasimhan, T. Salimans, I. Sutskeveret al., “Improving language understanding by generative pre-training,”Unknown, 2018
2018
-
[39]
Video dataflywheel: Resolving the impossible data trinity in video-language understanding,
X. Wang, J. Wu, Z. Lin, F. Zhang, D. Zhang, and L. Nie, “Video dataflywheel: Resolving the impossible data trinity in video-language understanding,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[40]
Object-centric rep- resentation learning for video scene understanding,
Y . Zhou, H. Zhang, S.-I. Park, B. Yoo, and X. Qi, “Object-centric rep- resentation learning for video scene understanding,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 12, pp. 8410– 8423, 2024
2024
-
[41]
Sharegpt4video: Improving video understanding and generation with better captions,
L. Chen, X. Wei, J. Li, X. Dong, P. Zhang, Y . Zang, Z. Chen, H. Duan, Z. Tang, L. Yuanet al., “Sharegpt4video: Improving video understanding and generation with better captions,”Advances in Neural Information Processing Systems, vol. 37, pp. 19 472–19 495, 2024
2024
-
[42]
Pllava: Parameter-free llava extension from images to videos for video dense captioning,
L. Xu, Y . Zhao, D. Zhou, Z. Lin, S. K. Ng, and J. Feng, “Pllava: Parameter-free llava extension from images to videos for video dense captioning,”arXiv preprint arXiv:2404.16994, 2024
Pith/arXiv arXiv 2024
-
[43]
Video recap: Recursive captioning of hour-long videos,
M. M. Islam, N. Ho, X. Yang, T. Nagarajan, L. Torresani, and G. Bertasius, “Video recap: Recursive captioning of hour-long videos,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 18 198–18 208
2024
-
[44]
Large language models are temporal and causal reasoners for video question answering,
D. Ko, J. S. Lee, W. Kang, B. Roh, and H. J. Kim, “Large language models are temporal and causal reasoners for video question answering,” arXiv preprint arXiv:2310.15747, 2023
arXiv 2023
-
[45]
Mvbench: A comprehensive multi-modal video understanding benchmark,
K. Li, Y . Wang, Y . He, Y . Li, Y . Wang, Y . Liu, Z. Wang, J. Xu, G. Chen, P. Luoet al., “Mvbench: A comprehensive multi-modal video understanding benchmark,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 22 195–22 206
2024
-
[46]
Videogpt+: Integrating image and video encoders for enhanced video understanding,
M. Maaz, H. Rasheed, S. Khan, and F. Khan, “Videogpt+: Integrating image and video encoders for enhanced video understanding,”arXiv preprint arXiv:2406.09418, 2024
arXiv 2024
-
[47]
Learning to answer visual questions from web videos,
A. Yang, A. Miech, J. Sivic, I. Laptev, and C. Schmid, “Learning to answer visual questions from web videos,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 5, pp. 3202–3218, 2025
2025
-
[48]
Transformer-empowered invariant grounding for video question answering,
Y . Li, X. Wang, J. Xiao, W. Ji, and T.-S. Chua, “Transformer-empowered invariant grounding for video question answering,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 11, pp. 9510– 9522, 2025
2025
-
[49]
Intentqa: Intent question answering in videos by cognitive context reasoning,
J. Li, P. Wei, W. Han, S.-C. Zhu, and L. Fan, “Intentqa: Intent question answering in videos by cognitive context reasoning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–18, 2026
2026
-
[50]
Vtg-llm: Integrating timestamp knowledge into video llms for enhanced video temporal grounding,
Y . Guo, J. Liu, M. Li, D. Cheng, X. Tang, D. Sui, Q. Liu, X. Chen, and K. Zhao, “Vtg-llm: Integrating timestamp knowledge into video llms for enhanced video temporal grounding,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 3, 2025, pp. 3302– 3310
2025
-
[51]
Vtg-gpt: Tuning-free zero- shot video temporal grounding with gpt,
Y . Xu, Y . Sun, Z. Xie, B. Zhai, and S. Du, “Vtg-gpt: Tuning-free zero- shot video temporal grounding with gpt,”Applied Sciences, vol. 14, no. 5, p. 1894, 2024
2024
-
[52]
Hawkeye: Training video-text llms for grounding text in videos,
Y . Wang, X. Meng, J. Liang, Y . Wang, Q. Liu, and D. Zhao, “Hawkeye: Training video-text llms for grounding text in videos,”arXiv preprint arXiv:2403.10228, 2024
arXiv 2024
-
[53]
Llava-next: A strong zero-shot video understanding model,
Y . Zhang, B. Li, h. Liu, Y . j. Lee, L. Gui, D. Fu, J. Feng, Z. Liu, and C. Li, “Llava-next: A strong zero-shot video understanding model,” April 2024. [Online]. Available: https://llava-vl.github.io/blog/2024-04- 30-llava-next-video/
2024
-
[54]
Video-llava: Learning united visual representation by alignment before projection,
B. Lin, B. Zhu, Y . Ye, M. Ning, P. Jin, and L. Yuan, “Video-llava: Learning united visual representation by alignment before projection,” arXiv preprint arXiv:2311.10122, 2023
Pith/arXiv arXiv 2023
-
[55]
Vila: On pre-training for visual language models,
J. Lin, H. Yin, W. Ping, P. Molchanov, M. Shoeybi, and S. Han, “Vila: On pre-training for visual language models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 26 689–26 699
2024
-
[56]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context,
M. Reid, N. Savinov, D. Teplyashin, D. Lepikhin, T. Lillicrap, J.-b. Alayrac, R. Soricut, A. Lazaridou, O. Firat, J. Schrittwieseret al., “Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context,”arXiv preprint arXiv:2403.05530, 2024
Pith/arXiv arXiv 2024
-
[57]
Valor: Vision-audio-language omni-perception pretraining model and dataset,
J. Liu, S. Chen, X. He, L. Guo, X. Zhu, W. Wang, and J. Tang, “Valor: Vision-audio-language omni-perception pretraining model and dataset,”IEEE Transactions on Pattern Analysis and Machine Intelli- gence, vol. 47, no. 2, pp. 708–724, 2025
2025
-
[58]
Cap4video++: Enhancing video understanding with auxiliary captions,
W. Wu, X. Wang, H. Luo, J. Wang, Y . Yang, and W. Ouyang, “Cap4video++: Enhancing video understanding with auxiliary captions,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 7, pp. 5223–5237, 2025
2025
-
[59]
Hierarchical banzhaf interaction for general video-language representation learning,
P. Jin, H. Li, L. Yuan, S. Yan, and J. Chen, “Hierarchical banzhaf interaction for general video-language representation learning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 3, pp. 2125–2139, 2025
2025
-
[60]
Video dataflywheel: Resolving the impossible data trinity in video-language understanding,
X. Wang, J. Wu, Z. Lin, F. Zhang, D. Zhang, and L. Nie, “Video dataflywheel: Resolving the impossible data trinity in video-language understanding,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 4, pp. 2912–2923, 2025
2025
-
[61]
J. Gao, Y . Lian, Z. Zhou, Y . Fu, and B. Wang, “Livechat: A large- scale personalized dialogue dataset automatically constructed from live streaming,”arXiv preprint arXiv:2306.08401, 2023
arXiv 2023
-
[62]
Don’t pause: Streaming video-language synchrony for online video understanding,
Z. Yang, K. Zhang, S. Qian, W. Dong, and C. Xu, “Don’t pause: Streaming video-language synchrony for online video understanding,” arXiv preprint arXiv:2606.06991, 2026
Pith/arXiv arXiv 2026
-
[63]
Querystream: Advancing streaming video understanding with query-aware pruning PREPRINT, 2026 18 and proactive response,
K. Zhang, Z. Yang, B. Wang, S. Qian, and C. Xu, “Querystream: Advancing streaming video understanding with query-aware pruning PREPRINT, 2026 18 and proactive response,” inThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[64]
B. Zhu, B. Lin, M. Ning, Y . Yan, J. Cui, H. Wang, Y . Pang, W. Jiang, J. Zhang, Z. Liet al., “Languagebind: Extending video-language pre- training to n-modality by language-based semantic alignment,”arXiv preprint arXiv:2310.01852, 2023
Pith/arXiv arXiv 2023
-
[65]
Egoschema: A diagnostic benchmark for very long-form video language understanding,
K. Mangalam, R. Akshulakov, J. Maliket al., “Egoschema: A diagnostic benchmark for very long-form video language understanding,”Advances in Neural Information Processing Systems, vol. 36, 2024
2024
-
[66]
Activitynet- qa: A dataset for understanding complex web videos via question answering,
Z. Yu, D. Xu, J. Yu, T. Yu, Z. Zhao, Y . Zhuang, and D. Tao, “Activitynet- qa: A dataset for understanding complex web videos via question answering,” inProceedings of the AAAI Conference on Artificial In- telligence, vol. 33, no. 01, 2019, pp. 9127–9134
2019
-
[67]
Hero: Hier- archical encoder for video+ language omni-representation pre-training,
L. Li, Y .-C. Chen, Y . Cheng, Z. Gan, L. Yu, and J. Liu, “Hero: Hier- archical encoder for video+ language omni-representation pre-training,” arXiv preprint arXiv:2005.00200, 2020
arXiv 2005
-
[68]
Per- ception test: A diagnostic benchmark for multimodal video models,
V . Patraucean, L. Smaira, A. Gupta, A. Recasens, L. Markeeva, D. Ba- narse, S. Koppula, M. Malinowski, Y . Yang, C. Doerschet al., “Per- ception test: A diagnostic benchmark for multimodal video models,” Advances in Neural Information Processing Systems, vol. 36, 2024
2024
-
[69]
Social- iq: A question answering benchmark for artificial social intelligence,
A. Zadeh, M. Chan, P. P. Liang, E. Tong, and L.-P. Morency, “Social- iq: A question answering benchmark for artificial social intelligence,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 8807–8817
2019
-
[70]
Video question answering via gradually refined attention over appearance and motion,
D. Xu, Z. Zhao, J. Xiao, F. Wu, H. Zhang, X. He, and Y . Zhuang, “Video question answering via gradually refined attention over appearance and motion,” inProceedings of the 25th ACM international conference on Multimedia, 2017, pp. 1645–1653
2017
-
[71]
Tvqa: Localized, compo- sitional video question answering,
J. Lei, L. Yu, M. Bansal, and T. L. Berg, “Tvqa: Localized, compo- sitional video question answering,”arXiv preprint arXiv:1809.01696, 2018
Pith/arXiv arXiv 2018
-
[72]
Next-qa: Next phase of question-answering to explaining temporal actions,
J. Xiao, X. Shang, A. Yao, and T.-S. Chua, “Next-qa: Next phase of question-answering to explaining temporal actions,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 9777–9786
2021
-
[73]
Moviechat: From dense token to sparse memory for long video understanding,
E. Song, W. Chai, G. Wang, Y . Zhang, H. Zhou, F. Wu, H. Chi, X. Guo, T. Ye, Y . Zhanget al., “Moviechat: From dense token to sparse memory for long video understanding,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 18 221–18 232
2024
-
[74]
Lvbench: An extreme long video understanding benchmark,
W. Wang, Z. He, W. Hong, Y . Cheng, X. Zhang, J. Qi, S. Huang, B. Xu, Y . Dong, M. Dinget al., “Lvbench: An extreme long video understanding benchmark,”arXiv preprint arXiv:2406.08035, 2024
Pith/arXiv arXiv 2024
-
[75]
Tgif-qa: Toward spatio- temporal reasoning in visual question answering,
Y . Jang, Y . Song, Y . Yu, Y . Kim, and G. Kim, “Tgif-qa: Toward spatio- temporal reasoning in visual question answering,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2758–2766
2017
-
[76]
Moviechat+: Question-aware sparse memory for long video question answering,
E. Song, W. Chai, T. Ye, J.-N. Hwang, X. Li, and G. Wang, “Moviechat+: Question-aware sparse memory for long video question answering,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 48, no. 1, pp. 374–389, 2026
2026
-
[77]
Momentor++: Advancing video large language models with fine-grained long video reasoning,
J. Li, M. Gao, X. He, S. Tang, W.-S. Zheng, J. Xiao, M. Wang, T.-S. Chua, and Y . Zhuang, “Momentor++: Advancing video large language models with fine-grained long video reasoning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 48, no. 6, pp. 6208– 6224, 2026
2026
-
[78]
Selongvlm: Empowering long video language models with self-corrective clip selection,
K. Zhang, Z. Yang, M. Han, Y . Zhuge, H. Hao, C. Li, Z. Li, and X. Chang, “Selongvlm: Empowering long video language models with self-corrective clip selection,”IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–16, 2026
2026
-
[79]
Ego-r1: Agentic chain-of-tool-thought for ultra- long egocentric video reasoning,
S. Tian, R. Wang, H. Guo, P. Wu, Y . Dong, X. Wang, J. Yang, H. Zhang, H. Zhu, and Z. Liu, “Ego-r1: Agentic chain-of-tool-thought for ultra- long egocentric video reasoning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–16, 2026
2026
-
[80]
Hier-egopack: Hierarchical egocentric video understanding with diverse task perspectives,
S. A. Peirone, F. Pistilli, A. Alliegro, T. Tommasi, and G. Averta, “Hier-egopack: Hierarchical egocentric video understanding with diverse task perspectives,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 48, no. 2, pp. 1917–1931, 2026
1917
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.