Bidirectional Random Projections
Pith reviewed 2026-06-27 11:41 UTC · model grok-4.3
The pith
Bidirectional random projections produce an OLS excess loss bound that improves over row-only projections when the row ratio n1/n is small.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
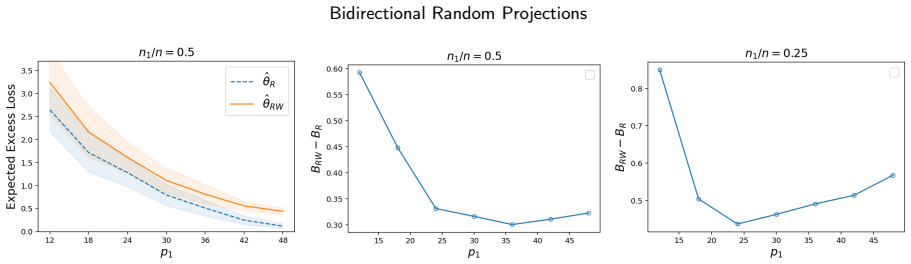
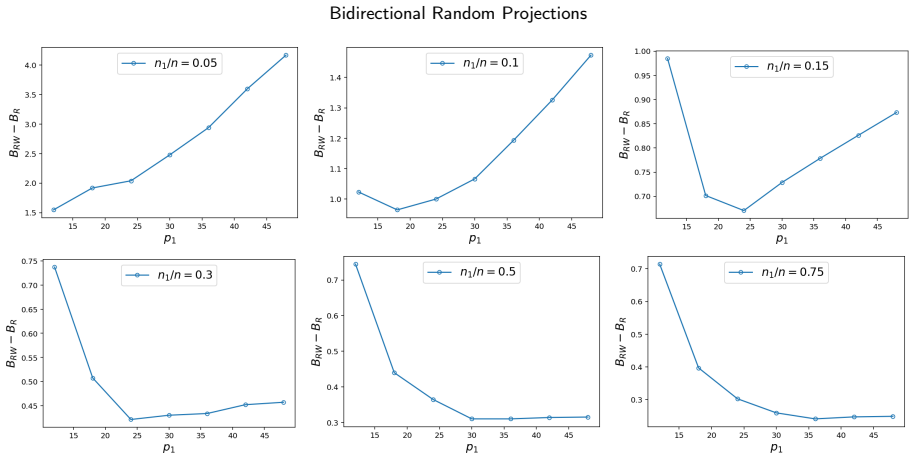
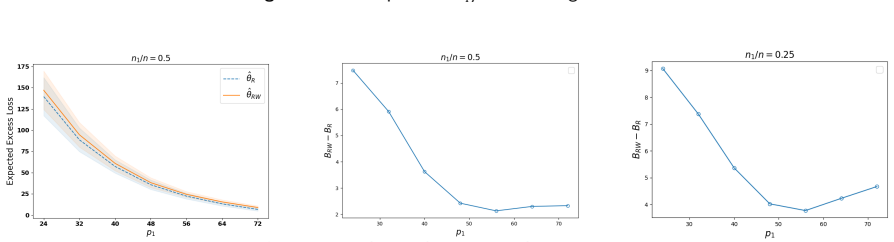
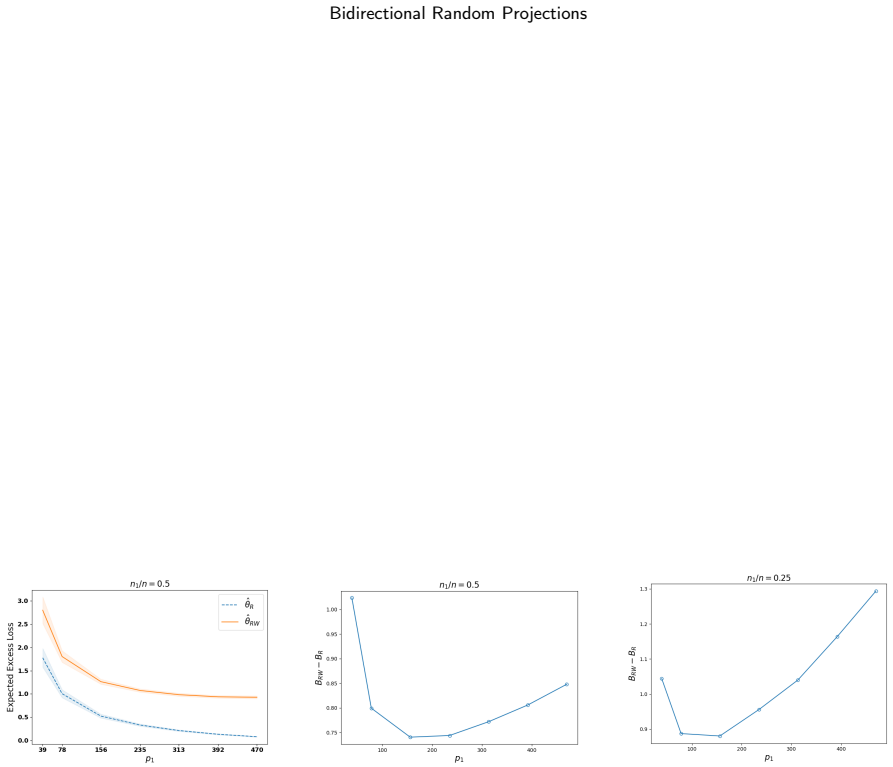
The paper establishes an expected excess loss bound for the OLS estimator built on the bidirectionally projected pair (W X R, W Y). Relative to the established bound for the row-projected estimator on (X R, Y), the new bound differs by a gap that is approximately O(p1 + C 1/p1), where C scales with n1/n and can be negative for small n1/n.
What carries the argument
The expected excess loss bound for the OLS estimator on the bidirectionally projected data (WXR, WY), obtained under fixed design with properly distributed random projections R and W.
If this is right
- The bidirectional approach can produce a strictly smaller expected excess loss bound than row-only projection when the ratio n1/n is sufficiently small.
- The gap expression implies an optimal choice of p1 that balances the linear and inverse terms for a given C.
- Numerical experiments on real-world data confirm that the theoretical gap behavior appears in practice.
Where Pith is reading between the lines
- The result suggests testing whether the same gap form appears when the projections are applied to other linear estimators such as ridge regression.
- It raises the question of whether an optimal p1 can be chosen in a data-driven way without knowing C in advance.
- The analysis may extend to streaming or online settings where both dimensions are reduced sequentially.
Load-bearing premise
The random projections R and W are properly distributed.
What would settle it
A numerical check on synthetic fixed-design data that computes the realized gap in excess loss for several values of p1 and n1/n and finds it deviates from the predicted O(p1 + C/p1) scaling when n1/n is small.
Figures
read the original abstract
This paper analyzes bidirectional random projections for ordinary least squares (OLS) regression under the fixed design setting. Let $(X,Y) \in \mathbb{R}^{n \times p} \times \mathbb{R}^n$ be a sample and $R \in \mathbb{R}^{n_1 \times n}, W \in \mathbb{R}^{p \times p_1}$ be two properly distributed random projections. We develop an expected excess loss bound for the OLS estimator built on $(WXR, WY)$. Compared to an established bound for OLS estimator built on $(XR, Y)$, the gap is approximately $O\left( p_1 + C \frac{1}{p_1} \right)$, where $C$ scales with $n_1/n$ and can be negative for small $n_1/n$. Its implications are confirmed by numerical results on real-world data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes bidirectional random projections for OLS regression in the fixed-design setting. With data (X, Y) and random projections R ∈ R^{n1×n}, W ∈ R^{p×p1} that are 'properly distributed,' it derives an expected excess-loss bound for the OLS estimator on the doubly projected data (WXR, WY). It then compares this bound to an established bound for the singly projected estimator on (XR, Y) and claims that the gap is approximately O(p1 + C/p1), where the constant C scales with the ratio n1/n and may be negative when n1/n is small. The claim is supported by numerical experiments on real data.
Significance. If the gap analysis holds under explicit distributional assumptions on R and W, the result would indicate that adding a second projection dimension p1 can sometimes reduce excess loss relative to unidirectional projection, with the improvement controlled by the sample-size ratio n1/n. This would be a modest but concrete contribution to the literature on sketched least squares, particularly if the O(1/p1) term and the sign of C can be made rigorous.
major comments (1)
- [Abstract / main bound derivation] Abstract and main derivation: the central gap claim O(p1 + C/p1) with C allowed to change sign rests entirely on the unstated moment calculations for the quadratic forms involving the projected Gram matrices. The only hypothesis supplied is that R and W are 'properly distributed'; without an explicit entry-wise law, variance scaling, or independence structure, neither the 1/p1 term nor the dependence of C on n1/n can be verified. This assumption is load-bearing for both the excess-loss bound and the comparison.
minor comments (1)
- [Numerical results] The numerical experiments on real-world data are mentioned but no details are given on the choice of p1, n1, or how the excess loss is estimated; adding a small table or figure caption would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful review and for identifying the need to make the distributional assumptions explicit. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract / main bound derivation] Abstract and main derivation: the central gap claim O(p1 + C/p1) with C allowed to change sign rests entirely on the unstated moment calculations for the quadratic forms involving the projected Gram matrices. The only hypothesis supplied is that R and W are 'properly distributed'; without an explicit entry-wise law, variance scaling, or independence structure, neither the 1/p1 term nor the dependence of C on n1/n can be verified. This assumption is load-bearing for both the excess-loss bound and the comparison.
Authors: We agree that the current phrasing 'properly distributed' is insufficient to support the claimed moment calculations and the sign behavior of C. In the revised manuscript we will replace this with explicit assumptions: the entries of R and W are i.i.d. sub-Gaussian with mean zero and variance scaled to 1/n and 1/p respectively, together with the required independence between R and W. We will also insert the intermediate moment bounds on the quadratic forms (E[||W X R||^2] and the cross terms) that yield the O(p1) and O(C/p1) contributions, making the dependence of C on n1/n transparent. These additions will be placed immediately after the statement of the excess-loss bound. revision: yes
Circularity Check
No circularity: bound extends external established result under explicit distributional assumption
full rationale
The derivation claims an expected excess loss bound for OLS on (WXR, WY) by extending an established external bound for OLS on (XR, Y). The gap expression O(p1 + C/p1) is presented as following from the difference under the stated assumption that R and W are properly distributed. No quoted step shows a prediction reducing to a fitted parameter defined inside the paper, a self-citation chain supplying the uniqueness or ansatz, or any self-definitional equivalence. The assumption is load-bearing but external and falsifiable; the comparison target is described as established and independent. The numerical confirmation on real data is post-hoc validation, not part of the derivation. The chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Random projections R and W are properly distributed
Reference graph
Works this paper leans on
-
[1]
Artificial intelligence and statistics , pages=
New bounds on compressive linear least squares regression , author=. Artificial intelligence and statistics , pages=. 2014 , organization=
2014
-
[2]
Limit of the smallest eigenvalue of a large dimensional sample covariance matrix , author=. Ann. Probab , volume=. 1993 , publisher=
1993
-
[3]
2002 , publisher=
A distribution-free theory of nonparametric regression , author=. 2002 , publisher=
2002
-
[4]
Advances in neural information processing systems , volume=
Compressed least-squares regression , author=. Advances in neural information processing systems , volume=
-
[5]
Artificial Intelligence and Statistics , pages=
Compressed least squares regression revisited , author=. Artificial Intelligence and Statistics , pages=. 2017 , organization=
2017
-
[6]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Compressed least-squares regression on sparse spaces , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[7]
, author=
Introduction to the non-asymptotic analysis of random matrices. , author=
-
[8]
Advances in Neural Information Processing Systems , volume=
Compressed regression , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
IEEE Transactions on Information Theory , volume=
Distributed sketching for randomized optimization: Exact characterization, concentration, and lower bounds , author=. IEEE Transactions on Information Theory , volume=. 2023 , publisher=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.