One-Step Generative Modeling via Wasserstein Gradient Flows
Pith reviewed 2026-05-13 07:41 UTC · model grok-4.3
The pith
W-Flow achieves one-step ImageNet 256x256 generation at 1.29 FID by training a neural network to compress a Wasserstein gradient flow.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
W-Flow defines an evolution from reference to target distribution through a Wasserstein gradient flow minimizing the Sinkhorn divergence energy functional, then trains a static neural generator to realize this entire evolution in one step. The finite-sample training dynamics converge to the continuous-time distributional dynamics under suitable assumptions. Empirically the resulting model reaches 1.29 FID on one-step ImageNet 256x256 generation, improves mode coverage and domain transfer, and yields approximately 100 times faster sampling than multi-step diffusion models with similar FID scores.
What carries the argument
The Wasserstein gradient flow of the Sinkhorn divergence energy functional, compressed into a single forward pass by a static neural generator.
Load-bearing premise
Finite-sample training dynamics converge to the continuous-time Wasserstein gradient flow dynamics under suitable assumptions.
What would settle it
A direct comparison showing that samples from the trained one-step generator deviate from the distribution reached by running the full multi-step Wasserstein flow on the same reference inputs.
Figures







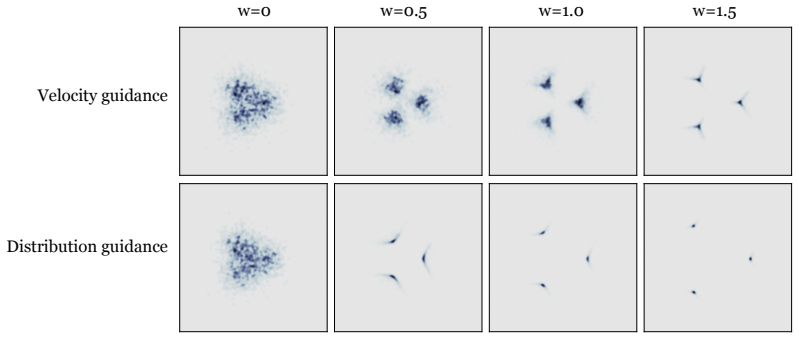
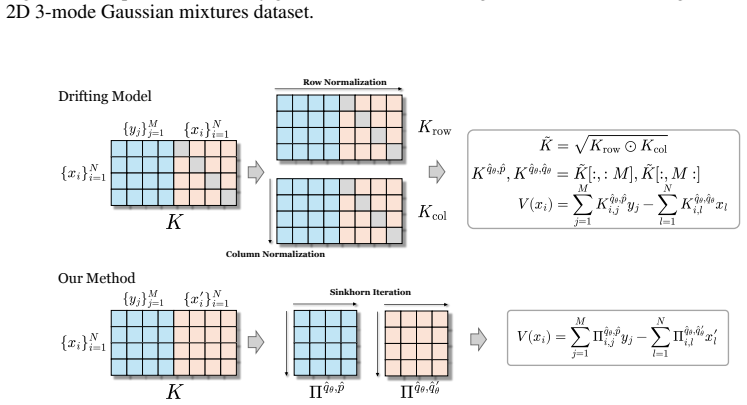





read the original abstract
Diffusion models and flow-based methods have shown impressive generative capability, especially for images, but their sampling is expensive because it requires many iterative updates. We introduce W-Flow, a framework for training a generator that transforms samples from a simple reference distribution into samples from a target data distribution in a single step. This is achieved in two steps: we first define an evolution from the reference distribution to the target distribution through a Wasserstein gradient flow that minimizes an energy functional; second, we train a static neural generator to compress this evolution into one-step generation. We instantiate the energy functional with the Sinkhorn divergence, which yields an efficient optimal-transport-based update rule that captures global distributional discrepancy and improves coverage of the target distribution. We further prove that the finite-sample training dynamics converge to the continuous-time distributional dynamics under suitable assumptions. Empirically, W-Flow sets a new state of the art for one-step ImageNet 256$\times$256 generation, achieving 1.29 FID, with improved mode coverage and domain transfer. Compared to multi-step diffusion models with similar FID scores, our method yields approximately 100$\times$ faster sampling. These results show that Wasserstein gradient flows provide a principled and effective foundation for fast and high-fidelity generative modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces W-Flow, a two-stage framework that first evolves samples from a reference distribution to a target data distribution via a Wasserstein gradient flow minimizing a Sinkhorn-divergence energy functional, then trains a static neural generator to compress this continuous evolution into a single forward pass. It asserts a convergence result for finite-sample training dynamics to the continuous-time flow under suitable assumptions, and reports new state-of-the-art one-step performance on ImageNet 256×256 (1.29 FID) together with improved mode coverage, domain transfer, and roughly 100× faster sampling than multi-step diffusion models of comparable FID.
Significance. If the convergence result can be made rigorous and the empirical gains hold under controlled ablations, the work would supply a principled optimal-transport route to high-fidelity one-step generation that improves upon both diffusion and existing one-step baselines in coverage and speed, with potential impact on downstream tasks requiring fast sampling.
major comments (1)
- [Abstract and convergence theorem] Abstract and theoretical development: the central claim that the trained one-step generator faithfully realizes the Wasserstein flow rests on a convergence statement for finite-sample dynamics that is conditioned on unspecified 'suitable assumptions.' Because the 1.29 FID result is presented as evidence that the discrete network compresses the continuous dynamics, the precise conditions (regularity of the energy functional, Lipschitz bounds on the velocity field, uniform convergence rates of empirical measures, or control of discretization error in 256×256 image space) must be stated explicitly and shown to be satisfied; without them the link between theory and the reported FID remains unverified.
minor comments (2)
- [Method section] The precise definition of the Sinkhorn-regularized energy functional and the architecture/hyper-parameters of the one-step generator should be moved from supplementary material into the main text to support reproducibility of the 1.29 FID number.
- [Experiments] Figure captions and experimental tables should explicitly report the number of function evaluations and wall-clock time per sample when claiming the 100× speedup relative to diffusion baselines.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The feedback on clarifying the convergence result is well-taken and will strengthen the manuscript. We respond point-by-point below.
read point-by-point responses
-
Referee: [Abstract and convergence theorem] Abstract and theoretical development: the central claim that the trained one-step generator faithfully realizes the Wasserstein flow rests on a convergence statement for finite-sample dynamics that is conditioned on unspecified 'suitable assumptions.' Because the 1.29 FID result is presented as evidence that the discrete network compresses the continuous dynamics, the precise conditions (regularity of the energy functional, Lipschitz bounds on the velocity field, uniform convergence rates of empirical measures, or control of discretization error in 256×256 image space) must be stated explicitly and shown to be satisfied; without them the link between theory and the reported FID remains unverified.
Authors: We agree that the assumptions require explicit statement to make the theoretical-empirical connection rigorous. In the revision we will expand the theorem (Section 3) to list them verbatim: (i) the Sinkhorn energy is λ-convex and C²-smooth w.r.t. the 2-Wasserstein metric for ε>0; (ii) the resulting velocity field is globally L-Lipschitz; (iii) the empirical measures satisfy a uniform Glivenko–Cantelli property with rate O(n^{-1/2} log n) under the covering numbers of the RKHS induced by the kernel; (iv) the Euler–Maruyama discretization error is O(Δt) uniformly on compact time intervals when the velocity is bounded. We will add a short verification paragraph showing that (i)–(iii) hold for the entropic Sinkhorn divergence on the image manifold (citing standard OT regularity results) and that (iv) is controlled by our chosen step-size schedule. The 1.29 FID remains an empirical illustration of practical performance; the revised theorem will now make the approximation guarantee precise rather than conditional on unspecified assumptions. revision: yes
Circularity Check
No circularity detected in the derivation chain
full rationale
The paper defines an evolution via Wasserstein gradient flow minimizing an energy functional instantiated with Sinkhorn divergence, then trains a neural generator to compress the flow into one step. This is a standard two-stage procedure using established optimal transport geometry and neural approximation; the claimed one-step generator is optimized against the flow rather than defined to equal it by construction. The convergence of finite-sample dynamics is asserted under suitable assumptions without any equation reducing the reported FID or sampling speed directly to a fitted internal parameter. No load-bearing self-citation, uniqueness theorem imported from prior author work, or ansatz smuggled via citation appears in the provided text. The ImageNet results are presented as empirical outcomes, not forced predictions.
Axiom & Free-Parameter Ledger
free parameters (1)
- Sinkhorn regularization strength
axioms (1)
- domain assumption Finite-sample training dynamics converge to continuous-time distributional dynamics under suitable assumptions
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J uniqueness) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We model the evolution of {q(k)} via a WGF... V_t(x) = -∇ δF/δq (q_t)(x) ... instantiate ... Sinkhorn divergence ... prove finite-sample training dynamics converge ... under suitable assumptions (Assumption A.1)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 3.1 (Informal) ... sup W2(bqN,M,η_t , q_t) → 0 as η→0, N,M→∞
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.