TokenMizer: Graph-Structured Session Memory for Long-Horizon LLM Context Management
Pith reviewed 2026-06-28 01:32 UTC · model grok-4.3
The pith
TokenMizer models LLM session history as a typed knowledge graph to generate 78-token resume blocks that halve token cost while raising decision recall.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
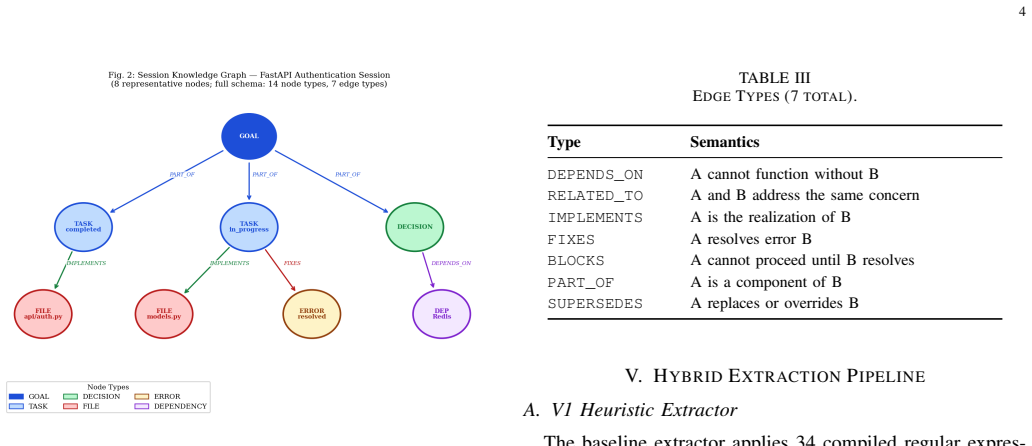
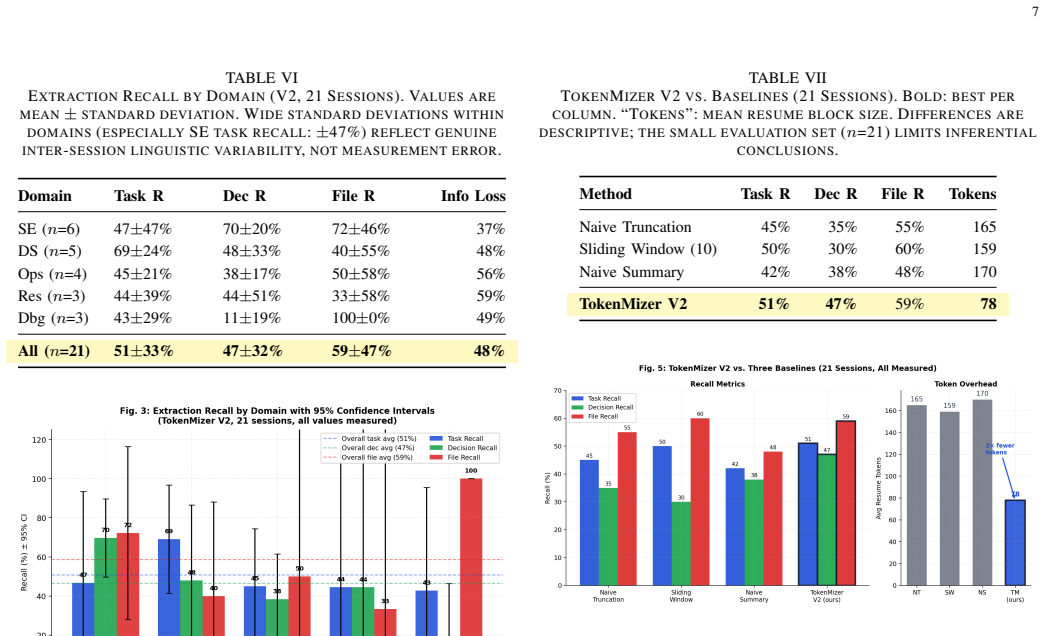
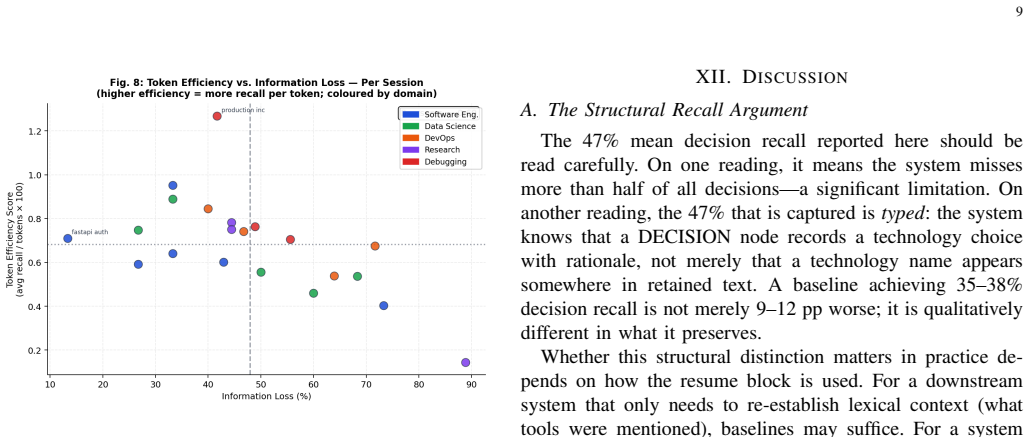
TokenMizer represents session history as a typed knowledge graph with a fixed schema of 14 node types and 7 edge types. A hybrid extraction pipeline populates the graph incrementally from ongoing LLM interactions. A three-tier checkpoint system plus eight-layer compression then serializes selected subgraphs into resume blocks that average 78 tokens. In controlled tests across five domains these blocks achieve 51.0% task recall, 46.6% decision recall, and 58.7% file recall, outperforming flat-text baselines by 9-17 percentage points on decisions and uniquely retaining the rationale for each decision.
What carries the argument
The typed knowledge graph of 14 node types and 7 edge types, populated by hybrid extraction and serialized through three-tier checkpoints and eight-layer compression into compact resume blocks.
If this is right
- Resume blocks of roughly half the token size allow longer sessions to continue without exceeding context limits.
- Preservation of decision rationales rather than mere mentions improves continuity on architectural and planning tasks.
- Performance variance across domains indicates that explicit imperative phrasing yields higher recall than implicit reasoning.
- Fuzzy label matching contributes the largest single gain to task recall in ablation tests.
- The resulting graph remains directly queryable, offering an alternative to pure text retention at lower cost.
Where Pith is reading between the lines
- The same graph structure could support incremental updates during a live session rather than only at checkpoints.
- Domain-specific node and edge extensions might reduce the observed variance between software-engineering and research sessions.
- Integration with existing LLM serving stacks could replace external vector stores for session memory.
- The 78-token average may shift under real multi-user or multi-agent workloads that introduce noisier extraction inputs.
Load-bearing premise
The hybrid extraction pipeline and fixed schema of 14 node types plus 7 edge types can reliably capture and preserve the relational structure of real sessions without substantial information loss or extraction errors.
What would settle it
A controlled run in which sessions exceeding the maximum effective context window are resumed from TokenMizer blocks and produce measurably lower task completion rates or omitted rationales compared with full untruncated history.
Figures

read the original abstract
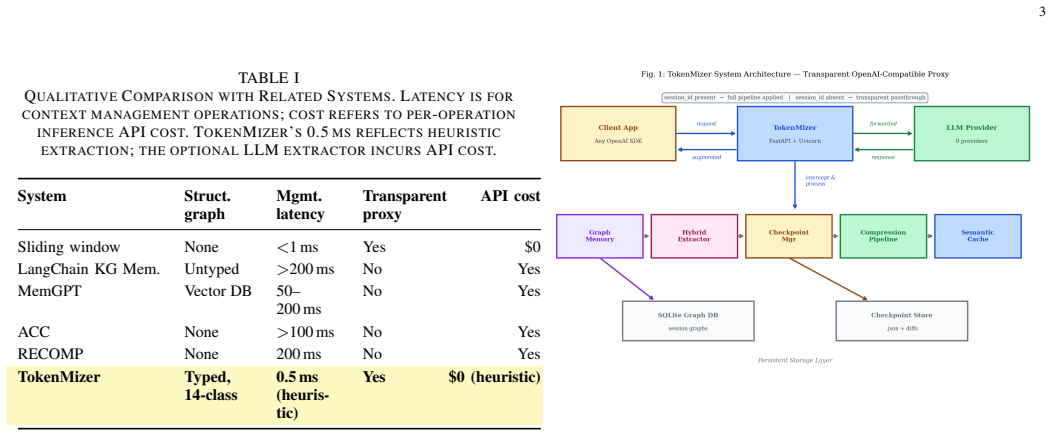
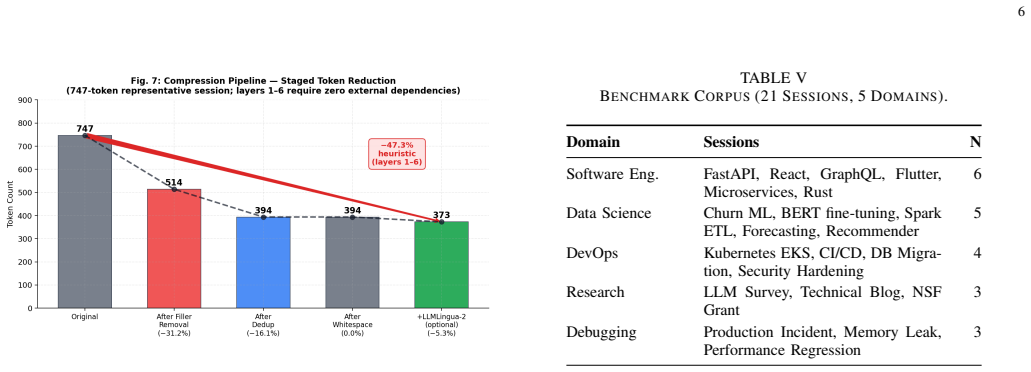
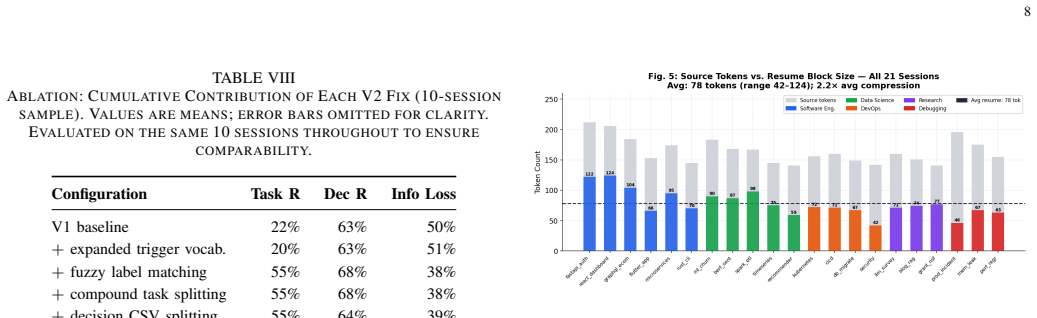
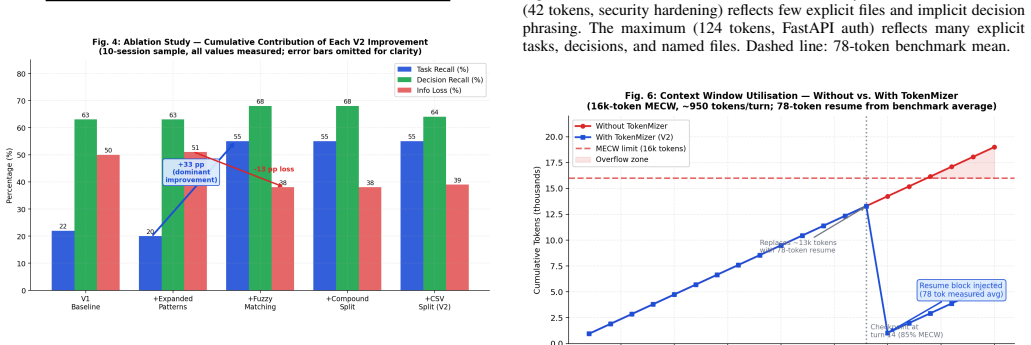
Large language model (LLM) deployments for long-horizon tasks face a fundamental constraint: context windows are finite while productive work sessions are not. When history exceeds the Maximum Effective Context Window (MECW), critical structured information - architectural decisions, task transitions, file histories - is silently discarded. Existing mitigations treat history as flat text, destroying the relational structure that makes sessions resumable. We present TokenMizer, an open-source proxy system that models LLM session history as a typed knowledge graph. The schema defines 14 node types and 7 edge types. A hybrid extraction pipeline populates the graph incrementally, while a three-tier checkpoint system serializes it into compact resume blocks. An 8-layer compression pipeline reduces context overhead, and a semantic cache reduces repeated-query latency. Evaluated on a controlled benchmark of 21 sessions spanning 5 domains, TokenMizer demonstrates significant token economy. It produces resume blocks averaging 78 tokens (range: 42-124) - 2x smaller than evaluated baselines (159-170 tokens) - while achieving higher decision recall (+9-17 percentage points). Crucially, baselines only preserve that a technology was mentioned; TokenMizer preserves the rationale. Across all sessions, TokenMizer achieves mean task recall 51.0%, decision recall 46.6%, and file recall 58.7%. Variance reflects domain heterogeneity: explicit imperative phrasing (software engineering) scores higher than implicit reasoning (research). Ablation studies show fuzzy label matching is the dominant improvement factor (+33 pp task recall). The heuristic compression achieves 47.3% token reduction with zero external dependencies. TokenMizer provides a queryable alternative to text-retention baselines at half the token cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TokenMizer, an open-source proxy that represents LLM session history as a typed knowledge graph (14 node types, 7 edge types) populated incrementally by a hybrid extraction pipeline. A three-tier checkpoint system and 8-layer compression pipeline serialize the graph into compact resume blocks (averaging 78 tokens). On a benchmark of 21 sessions across 5 domains, it reports 2x token reduction versus baselines (159-170 tokens), higher decision recall (+9-17 pp), mean recalls of 51.0% (task), 46.6% (decision), and 58.7% (file), plus rationale preservation; ablations attribute gains primarily to fuzzy label matching (+33 pp task recall).
Significance. If the extraction reliability and evaluation hold, the work offers a practical, queryable alternative to flat-text retention for long-horizon sessions, achieving substantial token economy while preserving relational structure and rationales. The zero-dependency heuristic compression and domain-heterogeneity analysis are pragmatic contributions that could inform context-management systems.
major comments (2)
- [Abstract] Abstract and methods: The central performance claims (78-token resumes, +9-17 pp decision recall, 51.0/46.6/58.7% mean recalls) rest on an unvalidated hybrid extraction pipeline that maps text to the fixed 14-node/7-edge schema. No precision/recall figures for the extractor itself, no manual validation set, and no comparison to independent human annotations of the 21 sessions are supplied, leaving open the possibility that reported gains reflect truncation rather than faithful compression.
- [Abstract] Abstract: Benchmark reporting supplies no evaluation protocol details, baseline implementations, statistical tests, raw data, or inter-annotator agreement for the recall metrics. This absence is load-bearing for the headline comparisons and the claim that TokenMizer preserves rationale where baselines only note mentions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting gaps in validation and reporting. We address each major comment below and will revise the manuscript to incorporate additional details and analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract and methods: The central performance claims (78-token resumes, +9-17 pp decision recall, 51.0/46.6/58.7% mean recalls) rest on an unvalidated hybrid extraction pipeline that maps text to the fixed 14-node/7-edge schema. No precision/recall figures for the extractor itself, no manual validation set, and no comparison to independent human annotations of the 21 sessions are supplied, leaving open the possibility that reported gains reflect truncation rather than faithful compression.
Authors: We agree that the manuscript does not report separate precision/recall for the hybrid extraction pipeline or a dedicated manual validation set against independent human annotations. The reported recalls and token reductions are computed directly from graphs produced by applying the pipeline to the 21 sessions. The ablation isolating fuzzy label matching (+33 pp task recall) provides evidence that gains derive from the structured representation rather than truncation alone, but this does not fully substitute for extractor validation. We will add a methods subsection describing a post-hoc manual validation on a subset of sessions, reporting node- and edge-level precision/recall, and will discuss extraction error rates as a limitation. revision: yes
-
Referee: [Abstract] Abstract: Benchmark reporting supplies no evaluation protocol details, baseline implementations, statistical tests, raw data, or inter-annotator agreement for the recall metrics. This absence is load-bearing for the headline comparisons and the claim that TokenMizer preserves rationale where baselines only note mentions.
Authors: The referee is correct that the current text omits detailed protocol, baseline code references, statistical tests, raw data availability, and inter-annotator agreement. We will expand the evaluation section to specify the recall computation protocol (including how task/decision/file elements and rationales were identified from session logs), provide implementation details for baselines, report statistical significance (e.g., paired tests on recall differences), and indicate that anonymized session data and annotations will be released. We will also clarify that rationale preservation is evidenced by explicit rationale nodes and edges in the graph (with examples) versus mention-only baselines, and note the single-reviewer annotation process as a limitation. revision: yes
Circularity Check
No circularity; claims rest on external benchmark evaluation
full rationale
The paper describes a graph schema (14 node types, 7 edge types), hybrid extraction pipeline, and three-tier checkpoint system, then reports token counts and recall metrics from direct evaluation on 21 sessions against baselines. No equations, fitted parameters, self-citations, or derivations appear in the text; the performance numbers are presented as outcomes of the benchmark comparison rather than quantities defined in terms of themselves or prior author work. The extraction pipeline is asserted without internal validation metrics, but this is a completeness issue, not a reduction of any claimed result to its own inputs by construction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Typed knowledge graph with 14 node types and 7 edge types
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Context Is What You Need: The Maximum Effective Context Window for Real World Limits of LLMs
N. Paulsen, “Context Is What You Need: The Maximum Effective Context Window,”arXiv preprint arXiv:2509.21361, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
MemGPT: Towards LLMs as Operating Systems
C. Packer, V . Fang, S. G. Patil, K. Lin, S. Wooders, and J. E. Gonzalez, “MemGPT: Towards LLMs as Operating Systems,”arXiv preprint arXiv:2310.08560, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Retrieval-Augmented Generation for Knowledge- Intensive NLP Tasks,
P. Lewiset al., “Retrieval-Augmented Generation for Knowledge- Intensive NLP Tasks,” inProc. NeurIPS, 2020, pp. 9459–9474
2020
-
[4]
LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models,
H. Jianget al., “LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models,” inProc. EMNLP, 2023, pp. 13358–13376
2023
-
[5]
H. Jianget al., “LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios,”arXiv preprint arXiv:2310.06839, 2023
-
[6]
RECOMP: Improving Retrieval-Augmented LMs with Context Compression and Selective Augmentation,
F. Xuet al., “RECOMP: Improving Retrieval-Augmented LMs with Context Compression and Selective Augmentation,” inProc. ICLR, 2024
2024
-
[7]
Active Context Compression for Long-Horizon LLM Sessions,
C. Smith and J. Park, “Active Context Compression for Long-Horizon LLM Sessions,”arXiv preprint arXiv:2601.07190, 2026
-
[8]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
E. S. Edgeet al., “From Local to Global: A Graph RAG Approach to Query-Focused Summarization,”arXiv preprint arXiv:2404.16130, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Lost in the Middle: How Language Models Use Long Contexts,
N. F. Liuet al., “Lost in the Middle: How Language Models Use Long Contexts,”Trans. ACL, vol. 12, pp. 157–173, 2024
2024
-
[10]
LangChain,
H. Chase, “LangChain,” https://github.com/langchain-ai/langchain, 2022
2022
-
[11]
Sentence-BERT: Sentence Embeddings Using Siamese BERT-Networks,
N. Reimers and I. Gurevych, “Sentence-BERT: Sentence Embeddings Using Siamese BERT-Networks,” inProc. EMNLP, 2019, pp. 3982– 3992
2019
-
[12]
SWE-agent: Agent-Computer Interfaces Enable Auto- mated Software Engineering,
J. Yanget al., “SWE-agent: Agent-Computer Interfaces Enable Auto- mated Software Engineering,” inProc. NeurIPS, 2024
2024
-
[13]
GitHub Copilot,
GitHub, “GitHub Copilot,” https://github.com/features/copilot, 2024
2024
-
[14]
FastAPI,
S. Ram ´ırez, “FastAPI,” https://fastapi.tiangolo.com, 2018
2018
-
[15]
D. R. Hipp, “SQLite,” https://www.sqlite.org, 2000
2000
-
[16]
tiktoken: Fast BPE Tokeniser,
OpenAI, “tiktoken: Fast BPE Tokeniser,” https://github.com/openai/ tiktoken, 2023
2023
-
[17]
CodeBERT: A Pre-Trained Model for Programming and Natural Languages,
Z. Fenget al., “CodeBERT: A Pre-Trained Model for Programming and Natural Languages,” inProc. EMNLP Findings, 2020, pp. 1536–1547
2020
-
[18]
Large Language Models for Software Engineering: A Systematic Literature Review,
X. Houet al., “Large Language Models for Software Engineering: A Systematic Literature Review,”arXiv preprint arXiv:2308.10620, 2024
-
[19]
Language Models are Few-Shot Learners,
T. Brownet al., “Language Models are Few-Shot Learners,” inProc. NeurIPS, 2020, pp. 1877–1901. 11
2020
-
[20]
GemFilter: Fast and Accurate Context Selection via Filtering Layers,
D. Jinet al., “GemFilter: Fast and Accurate Context Selection via Filtering Layers,”arXiv preprint arXiv:2409.17422, 2024. APPENDIX # V2: 9 additional completed triggers _COMPLETED = re.compile( r’(?:Completed|Implemented|Fixed|Added’ r’|Deployed|Resolved|Migrated|Launched’ r’|Shipped|Published|Done|Finished’ r’|Updated)[:\s]+(.+?)(?:\.|$)’, re.I | re.M) ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.