Context Is What You Need: The Maximum Effective Context Window for Real World Limits of LLMs
Pith reviewed 2026-05-18 14:47 UTC · model grok-4.3
The pith
Large language models' usable context is often under 1 percent of their advertised maximum and changes with the task.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
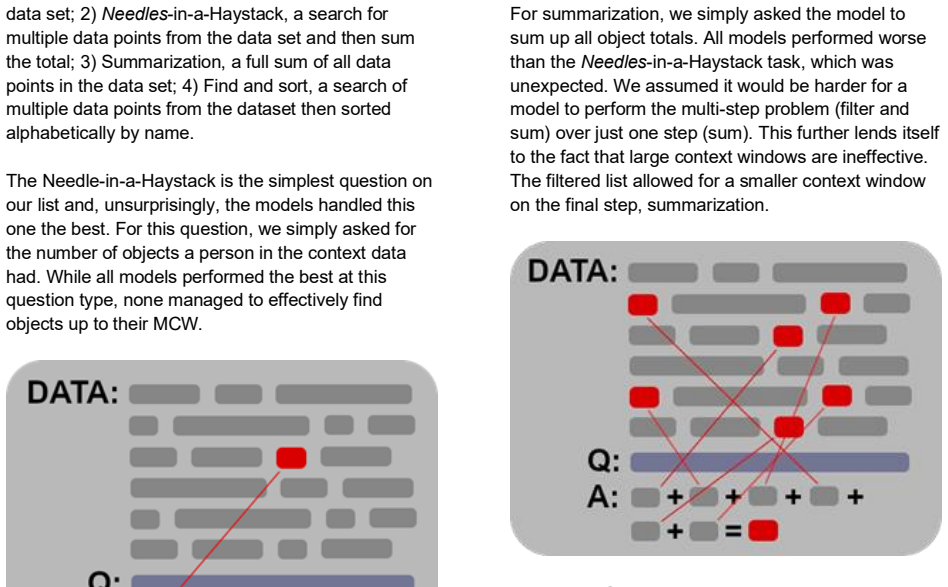
The authors establish that the Maximum Effective Context Window is drastically smaller than the reported Maximum Context Window for every model tested and that its size depends on the type of problem. Through hundreds of thousands of data points they show clear accuracy degradation well before advertised limits are reached, with the effective window varying by task.
What carries the argument
Maximum Effective Context Window (MECW), found by measuring accuracy drop-off across increasing context lengths for different problem types.
If this is right
- Accuracy falls and hallucinations rise once context exceeds the MECW for a given task.
- Context strategies should be adjusted to the problem type rather than using the full advertised window.
- Model comparisons and reporting should include MECW to reflect actual usable performance.
Where Pith is reading between the lines
- Systems could classify the incoming task first and then limit context to the expected MECW for that category.
- Standard benchmarks may start including MECW measurement alongside raw context length.
- Architecture work could target the specific failure modes that appear early for particular problem types.
Load-bearing premise
The testing method of measuring effectiveness over various context sizes and problem types accurately captures real-world limits without bias from problem selection, accuracy metrics, or data collection.
What would settle it
Finding even one model that sustains full accuracy across multiple problem types at context lengths near its advertised maximum would contradict the claim that MECW is much smaller than MCW.
Figures

read the original abstract
Large language model (LLM) providers boast big numbers for maximum context window sizes. To test the real world use of context windows, we 1) define a concept of maximum effective context window, 2) formulate a testing method of a context window's effectiveness over various sizes and problem types, and 3) create a standardized way to compare model efficacy for increasingly larger context window sizes to find the point of failure. We collected hundreds of thousands of data points across several models and found significant differences between reported Maximum Context Window (MCW) size and Maximum Effective Context Window (MECW) size. Our findings show that the MECW is, not only, drastically different from the MCW but also shifts based on the problem type. A few top of the line models in our test group failed with as little as 100 tokens in context; most had severe degradation in accuracy by 1000 tokens in context. All models fell far short of their Maximum Context Window by as much as 99 percent. Our data reveals the Maximum Effective Context Window shifts based on the type of problem provided, offering clear and actionable insights into how to improve model accuracy and decrease model hallucination rates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper defines the Maximum Effective Context Window (MECW) as a practical alternative to advertised Maximum Context Window (MCW) sizes for LLMs. It outlines a testing methodology that evaluates model accuracy across increasing context lengths and multiple problem types, collecting hundreds of thousands of data points from several models. The central empirical finding is that MECW is drastically smaller than MCW (by up to 99%), varies by problem type, and that many models exhibit severe accuracy degradation at context sizes as small as 100-1000 tokens.
Significance. If the results hold after addressing methodological gaps, the work would provide actionable empirical evidence for practitioners on the limited real-world utility of long context windows, potentially guiding better prompt engineering and context management to reduce hallucinations. The large-scale data collection across models and problem types is a strength that could inform model evaluation benchmarks, though the absence of theoretical derivations or formal proofs restricts its contribution to observational insights rather than foundational advances.
major comments (3)
- [Testing Method] Testing Method section: the formulation of the testing method lacks short-context baselines (e.g., accuracy at 10-50 tokens) to isolate context-window effects from task difficulty or prompt design. Without these controls, the claim that models 'fail with as little as 100 tokens' risks conflating inherent problem solvability with context limits, which is load-bearing for the MECW vs. MCW comparison.
- [Results] Results section: the quantification of the 'point of failure' and the reported 99% shortfall between MECW and MCW is not supported by explicit accuracy thresholds, statistical methods, confidence intervals, or how MECW is derived from the hundreds of thousands of data points. This undermines the reliability of the cross-problem-type claims.
- [Problem Types] Problem Types subsection: the specific problem types, their selection criteria, and any controls for confounding factors (such as output complexity or exact-match metrics) are not detailed, making it impossible to evaluate whether the observed MECW shifts are general or artifactual.
minor comments (2)
- [Abstract] Abstract: the claim of 'hundreds of thousands of data points' would benefit from specifying the exact number of models, context size ranges tested, and accuracy metric used.
- [Introduction] Introduction: the distinction between MCW and MECW would be clearer with a concise formal definition or pseudocode for the testing procedure rather than prose only.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive report. We address each major comment below and have revised the manuscript accordingly to improve clarity and methodological rigor.
read point-by-point responses
-
Referee: [Testing Method] Testing Method section: the formulation of the testing method lacks short-context baselines (e.g., accuracy at 10-50 tokens) to isolate context-window effects from task difficulty or prompt design. Without these controls, the claim that models 'fail with as little as 100 tokens' risks conflating inherent problem solvability with context limits, which is load-bearing for the MECW vs. MCW comparison.
Authors: We agree that short-context baselines are necessary to isolate context-length effects. In the revised Testing Method section we now report accuracy at 10, 25, and 50 tokens for every problem type and model. These baselines are used to normalize subsequent accuracy curves when identifying the MECW, thereby separating task-inherent difficulty from context-window degradation. revision: yes
-
Referee: [Results] Results section: the quantification of the 'point of failure' and the reported 99% shortfall between MECW and MCW is not supported by explicit accuracy thresholds, statistical methods, confidence intervals, or how MECW is derived from the hundreds of thousands of data points. This undermines the reliability of the cross-problem-type claims.
Authors: The referee correctly identifies that the original manuscript presented the MECW derivation at a high level. We have added an explicit operational definition: MECW is the largest context length at which mean accuracy remains within one standard error of the short-context baseline. We now report binomial confidence intervals for all accuracy estimates and describe the aggregation procedure across the collected data points. The maximum 99% shortfall is the largest observed gap between advertised MCW and this empirically derived MECW; the revised Results section includes the supporting tables and formulas. revision: yes
-
Referee: [Problem Types] Problem Types subsection: the specific problem types, their selection criteria, and any controls for confounding factors (such as output complexity or exact-match metrics) are not detailed, making it impossible to evaluate whether the observed MECW shifts are general or artifactual.
Authors: We have substantially expanded the Problem Types subsection. Each task is now described with its input format, expected output format, and evaluation metric (exact match for retrieval-style tasks, F1 for reasoning tasks). Selection criteria are stated explicitly: tasks were chosen to span retrieval, multi-step reasoning, and summarization while keeping output length distributions comparable across context sizes. Additional controls for output complexity (token-length caps and prompt templates) are documented to reduce the chance that observed MECW differences are artifacts of generation difficulty. revision: yes
Circularity Check
No significant circularity: purely empirical data collection with no derivations or self-referential reductions
full rationale
The paper defines MECW conceptually, formulates a testing procedure over context sizes and problem types, then reports observed accuracy differences across hundreds of thousands of data points. No equations, fitted parameters, or derivation chain exist that could reduce any claim to its own inputs by construction. Central results (MECW << MCW, shifts by problem type, degradation at 100-1000 tokens) are presented as direct measurements rather than predictions derived from prior fits or self-citations. This is self-contained empirical work; external benchmarks (accuracy on chosen tasks) are independent of any internal redefinition. No load-bearing self-citation, ansatz smuggling, or renaming of known results is present in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Context window effectiveness can be reliably quantified by accuracy degradation across selected problem types and context sizes.
invented entities (1)
-
Maximum Effective Context Window (MECW)
no independent evidence
Forward citations
Cited by 4 Pith papers
-
OPSDL: On-Policy Self-Distillation for Long-Context Language Models
OPSDL improves long-context LLM performance by having the model self-distill from its short-context capability using point-wise reverse KL divergence on generated tokens, outperforming SFT and DPO on benchmarks withou...
-
Correctness-Aware Repository Filtering Under Maximum Effective Context Window Constraints
A pre-execution size filter cuts repository tokens by 80-89% at sub-millisecond cost and raises file-level accuracy from 25% to 72% in a small CodeLlama evaluation.
-
Instruction Adherence in Coding Agent Configuration Files: A Factorial Study of Four File-Structure Variables
A 1650-session factorial study found no measurable impact from config file size, instruction position, architecture, or conflicts on coding agent adherence, though compliance declined within sessions.
-
A Decomposition Perspective to Long-context Reasoning for LLMs
Decomposing long-context reasoning into atomic skills, synthesizing targeted pseudo-datasets, and applying RL improves LLM performance on long-context benchmarks by an average of 7.7%.
Reference graph
Works this paper leans on
-
[1]
Reasoning Models Don't Always Say What They Think. ArXiv:2505.05410 Xingyu Chen, Jiahao Xu, Tian Liang, Zhiwei He, Jianhui Pang, Dian Yu, Linfeng Song, Qiuzhi Liu, Mengfei Zhou, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, Dong Yu. 2024. Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs. ArXiv:2412.21187 James Chua and Owain Evans...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Maximum Effective Context Window: The maximum token count, for a given problem type, before the model performance begins to degrade in a measurable fashion
-
[3]
A 3 agent system with 70% success per agent results in a system with a 34.3% success rate
Cascading Failures: where an agentic framework consisting of multiple agents fails most of the time because each agent has a mediocre success rate. A 3 agent system with 70% success per agent results in a system with a 34.3% success rate. A.3 Graphical Data A.4 P-Value Calculation Charted P-Values for each bucket for each model for each problem set. A.4.1...
work page 1900
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.