Rethinking Training & Inference for Forecasting: Linking Winner-Take-All back to GMMs
Pith reviewed 2026-06-26 01:15 UTC · model grok-4.3
The pith
Post-hoc merging and a one-step EM update recover informative mode posteriors from WTA-trained trajectory forecasters without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the mismatch between GMM modeling and WTA training causes uninformative posteriors because hard one-hot assignment over-segments the trajectory space and ignores relatedness among modes; viewing the models through a GMM lens and applying test-time posterior-weighted merging together with a one-step EM update that shares probability mass across neighboring modes produces more informative, faithfully ranked posteriors and improves final forecasts on displacement metrics across multiple WTA-trained architectures without any retraining.
What carries the argument
test-time posterior-weighted merging of nearby trajectories combined with a one-step EM update that replaces hard WTA labels with soft responsibilities
If this is right
- Mode posteriors become more informative and more faithfully ranked by probability.
- Final forecasts improve on popular displacement metrics such as ADE and FDE.
- The gains hold across several different WTA-trained model architectures.
- No retraining or parameter adjustment is required to obtain the improvements.
Where Pith is reading between the lines
- The same GMM lens might motivate training losses that use soft assignments from the start instead of relying on post-hoc correction.
- The corrections could be tested on forecasting tasks outside autonomous driving where WTA losses appear.
- More reliable posteriors may support aggressive mode pruning that lowers compute while preserving safety margins.
Load-bearing premise
The modes learned under hard WTA assignment remain sufficiently well-separated and representative that post-hoc soft reweighting and merging can recover faithful probabilities without adjusting the underlying model parameters.
What would settle it
Applying the merging and one-step EM steps to a held-out validation set and observing neither improved mode ranking by log-likelihood nor gains on displacement metrics such as ADE or FDE would refute the claimed benefit.
Figures


read the original abstract
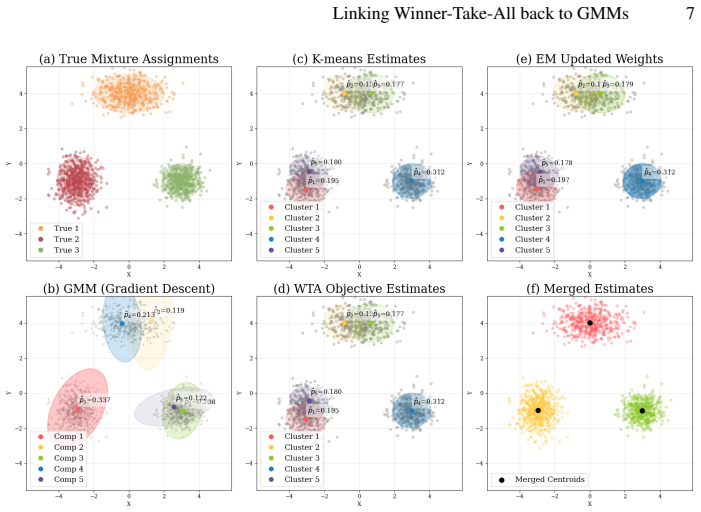
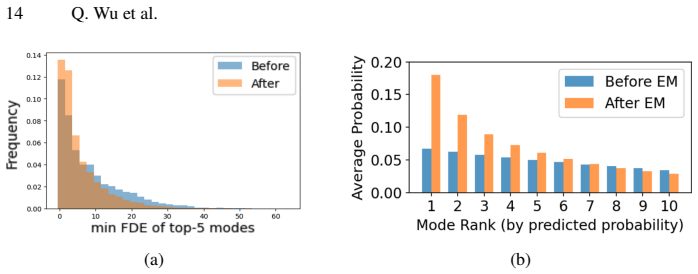
Trajectory forecasting for autonomous driving has advanced rapidly, yet representative models often produce uninformative posteriors over forecast modes, causing problems for mode pruning. We trace this to a modeling-training mismatch: forecasters are typically modeled as conditional Gaussian mixture models (GMMs) but trained with a winner-take-all (WTA) loss that assigns each sample to its nearest mode. We argue that this K-means-like hard assignment (one-hot), while preventing mode collapse, is the source of uninformative mode probabilities: it over-segments the trajectory space, ignores relatedness among nearby modes, and yields assignment instability under small perturbations. Guided by this lens, we introduce two post-hoc treatments: (1) test-time posterior-weighted merging that aggregates nearby candidate trajectories; and (2) a one-step expectation-maximization (EM) update that replaces hard labels with soft responsibilities, sharing probability mass across neighboring modes. Across several WTA-trained architectures, these lightweight steps produce more informative, faithfully ranked mode posteriors and strengthen final forecasts on popular displacement metrics -- without retraining. Our analysis unifies recent design choices through a GMM-vs-K-means perspective and offers principled, practical corrections that better align training objectives with inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that trajectory forecasters modeled as conditional GMMs but trained with WTA loss suffer uninformative posteriors because hard (one-hot) assignment over-segments the space, ignores mode relatedness, and produces instability. It proposes two post-hoc, training-free fixes—test-time posterior-weighted merging of nearby trajectories and a one-step EM update that replaces hard labels with soft responsibilities—and reports that these yield more informative, faithfully ranked mode posteriors plus stronger displacement-metric forecasts across several WTA-trained architectures. The work also unifies recent design choices under a GMM-vs-K-means lens.
Significance. If the empirical gains are robust and the separation assumption holds, the lightweight corrections would be practically valuable for improving existing deployed forecasters without retraining. The GMM-vs-K-means unification offers a clean conceptual lens that could guide future architecture choices.
major comments (2)
- [Abstract and §3 (method description)] The central claim that one-step EM recovers 'faithfully ranked' posteriors (abstract) rests on the assumption that WTA-learned modes remain sufficiently well-separated and representative for soft reweighting to assign mass according to the true conditional rather than an unoptimized density. The manuscript itself notes WTA over-segmentation and assignment instability; without a quantitative check (e.g., mode-separation statistics or comparison of one-step vs. converged EM posteriors) this assumption is load-bearing and unverified.
- [Experiments section (results tables/figures)] The empirical support for both treatments improving 'faithfully ranked' posteriors and displacement metrics lacks reported details on baseline comparisons, statistical significance, or separate ablations of merging versus the EM step. This makes it impossible to isolate whether gains come from merging alone or require the soft-reweighting component, directly affecting the claim that the two steps together address the modeling-training mismatch.
minor comments (1)
- [§3.2] Notation for the one-step EM update (responsibility computation) should be written explicitly with the current GMM parameters to clarify that no model parameters are altered.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which highlight important aspects of our claims and empirical presentation. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [Abstract and §3 (method description)] The central claim that one-step EM recovers 'faithfully ranked' posteriors (abstract) rests on the assumption that WTA-learned modes remain sufficiently well-separated and representative for soft reweighting to assign mass according to the true conditional rather than an unoptimized density. The manuscript itself notes WTA over-segmentation and assignment instability; without a quantitative check (e.g., mode-separation statistics or comparison of one-step vs. converged EM posteriors) this assumption is load-bearing and unverified.
Authors: We agree that the mode-separation assumption is load-bearing and that explicit verification would strengthen the justification for one-step EM. In the revision we will add quantitative checks, including (i) mode-separation statistics (average and minimum pairwise distances between learned modes across datasets) and (ii) a direct comparison of posterior rankings obtained after one-step EM versus fully converged EM on held-out data. These additions will be placed in §3 and the experiments section to demonstrate that the learned modes are sufficiently separated for soft reweighting to produce faithful rankings. revision: yes
-
Referee: [Experiments section (results tables/figures)] The empirical support for both treatments improving 'faithfully ranked' posteriors and displacement metrics lacks reported details on baseline comparisons, statistical significance, or separate ablations of merging versus the EM step. This makes it impossible to isolate whether gains come from merging alone or require the soft-reweighting component, directly affecting the claim that the two steps together address the modeling-training mismatch.
Authors: We concur that clearer isolation of each component and stronger statistical reporting are needed. The revised experiments section will (i) report baseline comparisons against the original WTA models, (ii) include statistical significance (e.g., paired t-tests or bootstrap confidence intervals on displacement metrics), and (iii) present separate ablations that apply merging alone, one-step EM alone, and the combination. These tables will be added to the main results and will directly address whether the two steps are synergistic or whether one suffices. revision: yes
Circularity Check
No circularity: conceptual GMM-WTA mismatch argument is independent of fitted inputs
full rationale
The paper's core argument traces uninformative posteriors to a training-modeling mismatch between conditional GMMs and WTA (K-means-like) hard assignment, then proposes post-hoc merging and one-step EM as corrections. No equations, predictions, or first-principles results are presented that reduce by construction to the paper's own fitted parameters or self-citations. The unification of design choices via the GMM-vs-K-means lens is an interpretive framing rather than a tautological renaming or self-definitional step. Empirical improvements are claimed across external architectures without the central claim depending on load-bearing self-citation chains or ansatzes smuggled from prior author work. This is a standard non-circular analysis grounded in external modeling perspective.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption WTA loss creates hard one-hot assignments that ignore relatedness among nearby modes.
- domain assumption One-step EM can replace hard labels with soft responsibilities while preserving the learned modes.
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Alahi, A., Goel, K., Ramanathan, V ., Robicquet, A., Fei-Fei, L., Savarese, S.: Social lstm: Human trajectory prediction in crowded spaces. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 961–971 (2016)
2016
-
[2]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Alahi, A., Ramanathan, V ., Fei-Fei, L.: Socially-aware large-scale crowd forecasting. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 2203– 2210 (2014)
2014
-
[3]
arXiv preprint arXiv:2506.08228 (2025)
Baniodeh, M., Goel, K., Ettinger, S., Fuertes, C., Seff, A., Shen, T., Gulino, C., Yang, C., Jerfel, G., Choe, D., et al.: Scaling laws of motion forecasting and planning–a technical report. arXiv preprint arXiv:2506.08228 (2025)
arXiv 2025
-
[4]
arXiv preprint arXiv:1903.11027 (2019)
Caesar, H., Bankiti, V ., Lang, A.H., V ora, S., Liong, V .E., Xu, Q., Krishnan, A., Pan, Y ., Baldan, G., Beijbom, O.: nuscenes: A multimodal dataset for autonomous driving. arXiv preprint arXiv:1903.11027 (2019)
Pith/arXiv arXiv 1903
-
[5]
In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition
Caesar, H., Bankiti, V ., Lang, A.H., V ora, S., Liong, V .E., Xu, Q., Krishnan, A., Pan, Y ., Bal- dan, G., Beijbom, O.: nuscenes: A multimodal dataset for autonomous driving. In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11621– 11631 (2020)
2020
-
[6]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Cao, C., Chen, X., Wang, J., Song, Q., Tan, R., Li, Y .H.: Cctr: calibrating trajectory prediction for uncertainty-aware motion planning in autonomous driving. In: Proceedings of the AAAI Conference on Artificial Intelligence. pp. 20949–20957 (2024)
2024
-
[7]
In: 2020 IEEE International Conference on Robotics and Automation (ICRA)
Casas, S., Gulino, C., Liao, R., Urtasun, R.: Spagnn: Spatially-aware graph neural networks for relational behavior forecasting from sensor data. In: 2020 IEEE International Conference on Robotics and Automation (ICRA). pp. 9491–9497. IEEE (2020)
2020
-
[8]
In: European Conference on Computer Vision
Casas, S., Gulino, C., Suo, S., Luo, K., Liao, R., Urtasun, R.: Implicit latent variable model for scene-consistent motion forecasting. In: European Conference on Computer Vision. pp. 624–641. Springer (2020)
2020
-
[9]
arXiv preprint arXiv:1910.05449 (2019)
Chai, Y ., Sapp, B., Bansal, M., Anguelov, D.: Multipath: Multiple probabilistic anchor tra- jectory hypotheses for behavior prediction. arXiv preprint arXiv:1910.05449 (2019)
arXiv 1910
-
[10]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Cui, A., Casas, S., Sadat, A., Liao, R., Urtasun, R.: Lookout: Diverse multi-future prediction and planning for self-driving. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 16107–16116 (2021)
2021
-
[11]
In: Proceedings of the IEEE conference on computer vision and pattern recognition workshops
Deo, N., Trivedi, M.M.: Convolutional social pooling for vehicle trajectory prediction. In: Proceedings of the IEEE conference on computer vision and pattern recognition workshops. pp. 1468–1476 (2018) 16 Q. Wu et al
2018
-
[12]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Ettinger, S., Cheng, S., Caine, B., Liu, C., Zhao, H., Pradhan, S., Chai, Y ., et al.: Large scale interactive motion forecasting for autonomous driving: The waymo open motion dataset. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 9710–9719 (2021)
2021
-
[13]
In: European Conference on Computer Vision
Feng, L., Bahari, M., Amor, K.M.B., Zablocki, ´E., Cord, M., Alahi, A.: Unitraj: A unified framework for scalable vehicle trajectory prediction. In: European Conference on Computer Vision. pp. 106–123. Springer (2024)
2024
-
[14]
IEEE Transactions on Intelligent Transportation Systems24(6), 6203–6216 (2023)
Gao, K., Li, X., Chen, B., Hu, L., Liu, J., Du, R., Li, Y .: Dual transformer based prediction for lane change intentions and trajectories in mixed traffic environment. IEEE Transactions on Intelligent Transportation Systems24(6), 6203–6216 (2023)
2023
-
[15]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Gupta, A., Johnson, J., Fei-Fei, L., Savarese, S., Alahi, A.: Social gan: Socially acceptable trajectories with generative adversarial networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2255–2264 (2018)
2018
-
[16]
In: 2018 IEEE Intelligent Vehicles Symposium (IV)
Hu, Y ., Zhan, W., Tomizuka, M.: Probabilistic prediction of vehicle semantic intention and motion. In: 2018 IEEE Intelligent Vehicles Symposium (IV). pp. 307–313. IEEE (2018)
2018
-
[17]
In: Conference on Robot Learning
Jain, A., Casas, S., Liao, R., Xiong, Y ., Feng, S., Segal, S., Urtasun, R.: Discrete residual flow for probabilistic pedestrian behavior prediction. In: Conference on Robot Learning. pp. 407–419. PMLR (2020)
2020
-
[18]
In: Proceedings of the IEEE international conference on computer vision
Li, R., Tapaswi, M., Liao, R., Jia, J., Urtasun, R., Fidler, S.: Situation recognition with graph neural networks. In: Proceedings of the IEEE international conference on computer vision. pp. 4173–4182 (2017)
2017
-
[19]
Least squares quantization in PCM,
Lloyd, S.: Least squares quantization in pcm. IEEE Transactions on Information Theory 28(2), 129–137 (1982).https://doi.org/10.1109/TIT.1982.1056489
-
[20]
2010 IEEE International Conference on Robotics and Au- tomation pp
Luber, M., Stork, J.A., Tipaldi, G.D., Arras, K.O.: People tracking with human motion predictions from social forces. 2010 IEEE International Conference on Robotics and Au- tomation pp. 464–469 (2010),https://api.semanticscholar.org/CorpusID: 1046089
2010
-
[21]
In: 2021 IEEE/RSJ International Conference on Intelli- gent Robots and Systems (IROS)
Luo, K., Casas, S., Liao, R., Yan, X., Xiong, Y ., Zeng, W., Urtasun, R.: Safety-oriented pedestrian occupancy forecasting. In: 2021 IEEE/RSJ International Conference on Intelli- gent Robots and Systems (IROS). pp. 1015–1022. IEEE (2021)
2021
-
[22]
In: Conference on Robot Learning
Luo, W., Park, C., Cornman, A., Sapp, B., Anguelov, D.: Jfp: Joint future prediction with interactive multi-agent modeling for autonomous driving. In: Conference on Robot Learning. pp. 1457–1467. PMLR (2023)
2023
-
[23]
arXiv preprint arXiv:2207.05844 (2022)
Nayakanti, N., Al-Rfou, R., Zhou, A., Goel, K., Refaat, K.S., Sapp, B.: Wayformer: Mo- tion forecasting via simple & efficient attention networks. arXiv preprint arXiv:2207.05844 (2022)
arXiv 2022
-
[24]
In: 2018 IEEE intelligent vehicles symposium (IV)
Park, S.H., Kim, B., Kang, C.M., Chung, C.C., Choi, J.W.: Sequence-to-sequence predic- tion of vehicle trajectory via lstm encoder-decoder architecture. In: 2018 IEEE intelligent vehicles symposium (IV). pp. 1672–1678. IEEE (2018)
2018
-
[25]
In: 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Prutsch, A., Bischof, H., Possegger, H.: Efficient motion prediction: A lightweight & accu- rate trajectory prediction model with fast training and inference speed. In: 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 9411–9417. IEEE (2024)
2024
-
[26]
In: Proceedings of the European Conference on Computer Vision (ECCV)
Rhinehart, N., Kitani, K.M., Vernaza, P.: R2p2: A reparameterized pushforward policy for diverse, precise generative path forecasting. In: Proceedings of the European Conference on Computer Vision (ECCV). pp. 772–788 (2018)
2018
-
[27]
In: Proceedings of the IEEE/CVF international conference on computer vision
Rhinehart, N., McAllister, R., Kitani, K., Levine, S.: Precog: Prediction conditioned on goals in visual multi-agent settings. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 2821–2830 (2019) Linking Winner-Take-All back to GMMs 17
2019
-
[28]
In: Conference on Robot Learning
Roh, J., Mavrogiannis, C., Madan, R., Fox, D., Srinivasa, S.: Multimodal trajectory predic- tion via topological invariance for navigation at uncontrolled intersections. In: Conference on Robot Learning. pp. 2216–2227. PMLR (2021)
2021
-
[29]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Sadeghian, A., Kosaraju, V ., Sadeghian, A., Hirose, N., Rezatofighi, H., Savarese, S.: So- phie: An attentive gan for predicting paths compliant to social and physical constraints. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1349–1358 (2019)
2019
-
[30]
Advances in Neural Information Processing Systems (2022)
Shi, S., Jiang, L., Dai, D., Schiele, B.: Motion transformer with global intention localization and local movement refinement. Advances in Neural Information Processing Systems (2022)
2022
-
[31]
arXiv preprint arXiv:2209.10033 (2022)
Shi, S., Jiang, L., Dai, D., Schiele, B.: Mtr-a: 1st place solution for 2022 waymo open dataset challenge–motion prediction. arXiv preprint arXiv:2209.10033 (2022)
arXiv 2022
-
[32]
arXiv preprint arXiv:2306.17770 (2023)
Shi, S., Jiang, L., Dai, D., Schiele, B.: Mtr++: Multi-agent motion prediction with symmetric scene modeling and guided intention querying. arXiv preprint arXiv:2306.17770 (2023)
arXiv 2023
-
[33]
In: 2022 International Conference on Robotics and Automation (ICRA)
Varadarajan, B., Hefny, A., Srivastava, A., Refaat, K.S., Nayakanti, N., Cornman, A., Chen, K., Douillard, B., Lam, C.P., Anguelov, D., et al.: Multipath++: Efficient information fu- sion and trajectory aggregation for behavior prediction. In: 2022 International Conference on Robotics and Automation (ICRA). pp. 7814–7821. IEEE (2022)
2022
-
[34]
arXiv preprint arXiv:2301.00493 (2023)
Wilson, B., Qi, W., Agarwal, T., Lambert, J., Singh, J., Khandelwal, S., Pan, B., Kumar, R., Hartnett, A., Pontes, J.K., et al.: Argoverse 2: Next generation datasets for self-driving perception and forecasting. arXiv preprint arXiv:2301.00493 (2023)
Pith/arXiv arXiv 2023
-
[35]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
Zhou, Z., Wang, J., Li, Y .H., Huang, Y .K.: Query-centric trajectory prediction. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
2023
-
[36]
In: 2017 IEEE Intelligent Vehicles Symposium (IV)
Zyner, A., Worrall, S., Ward, J., Nebot, E.: Long short term memory for driver intent predic- tion. In: 2017 IEEE Intelligent Vehicles Symposium (IV). pp. 1484–1489. IEEE (2017)
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.