Overcoming Rank Collapse in Feedback Alignment
Pith reviewed 2026-06-27 13:51 UTC · model grok-4.3
The pith
Feedback alignment fails to scale because its error signals occupy lower-dimensional subspaces than backpropagation gradients.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
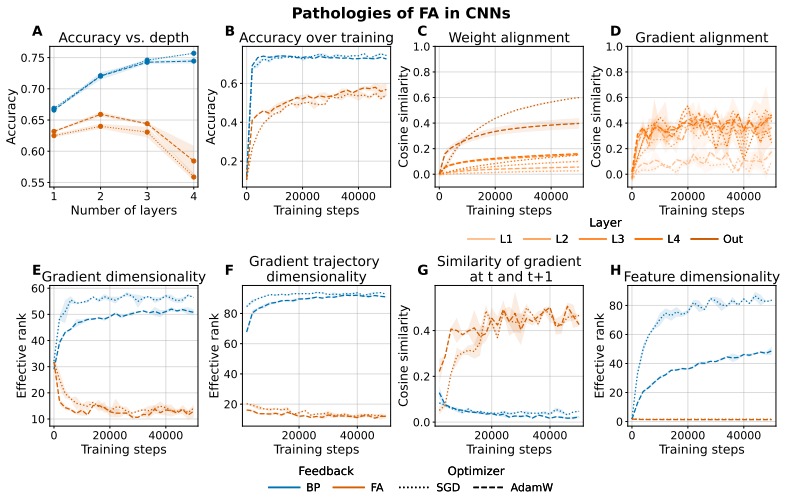
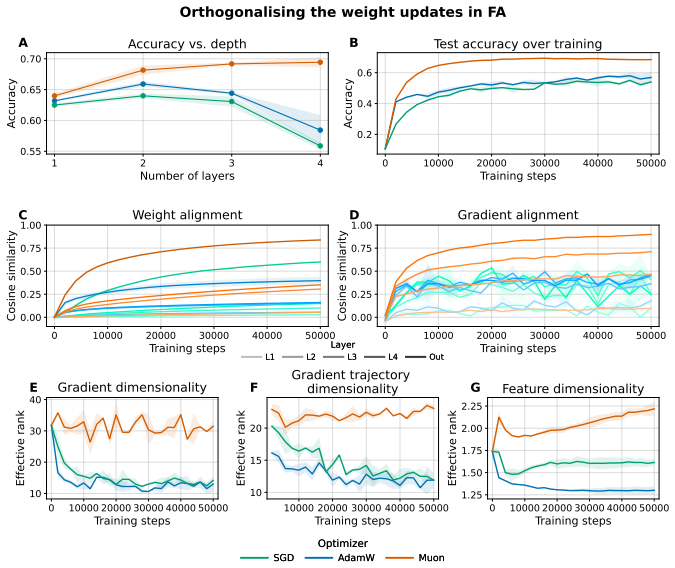
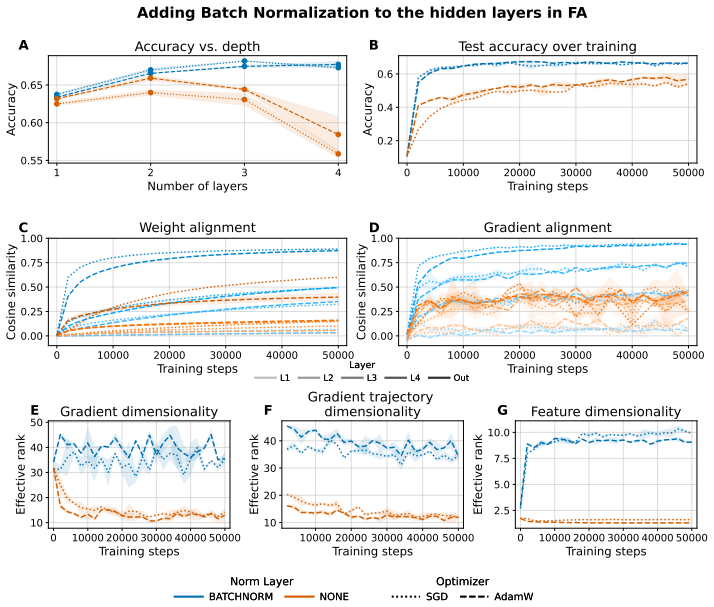
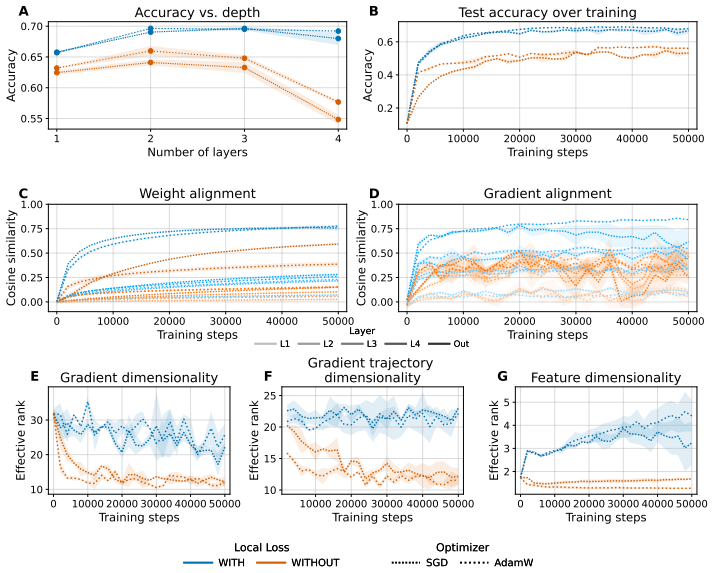
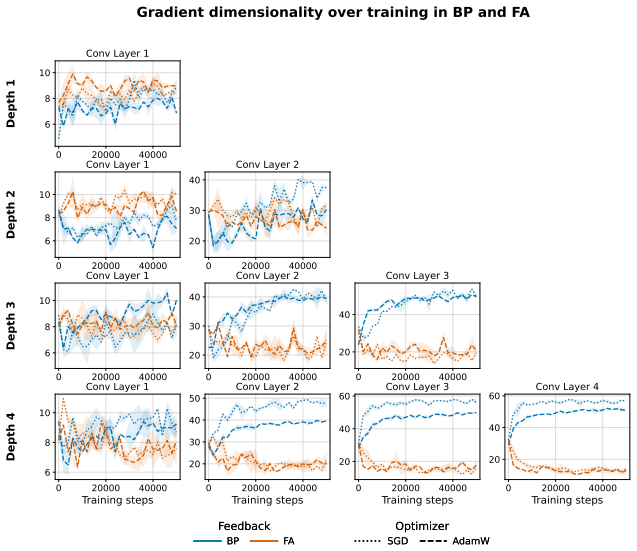
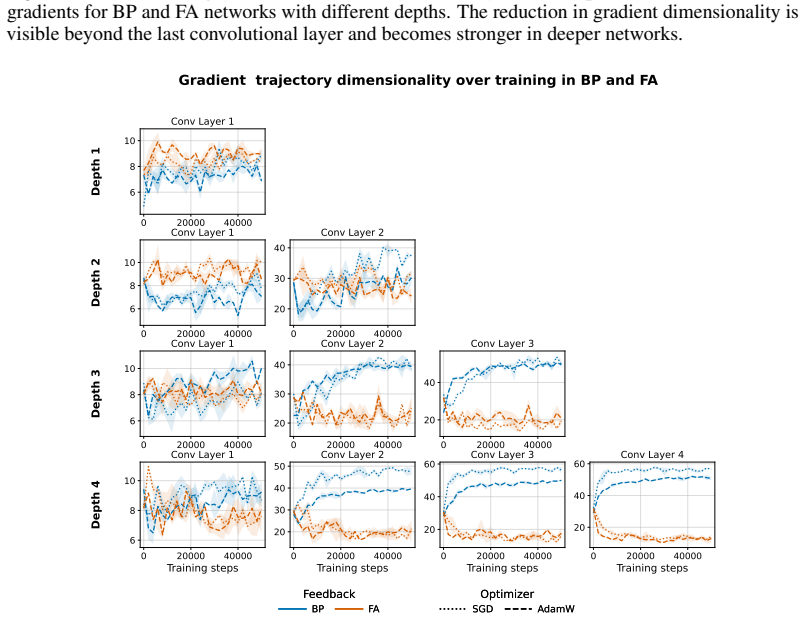
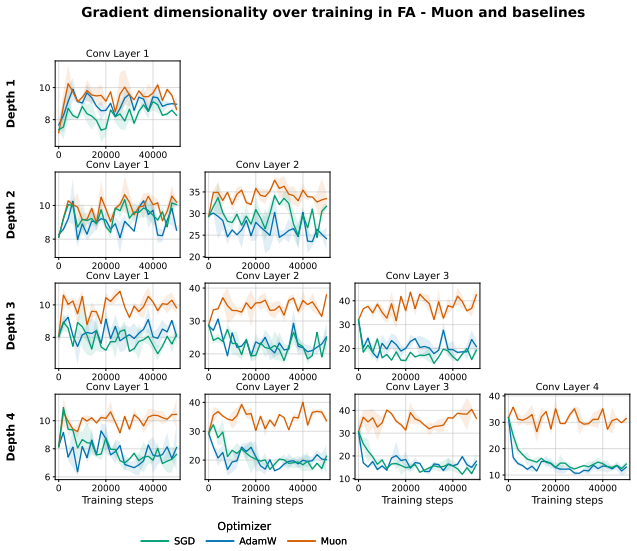
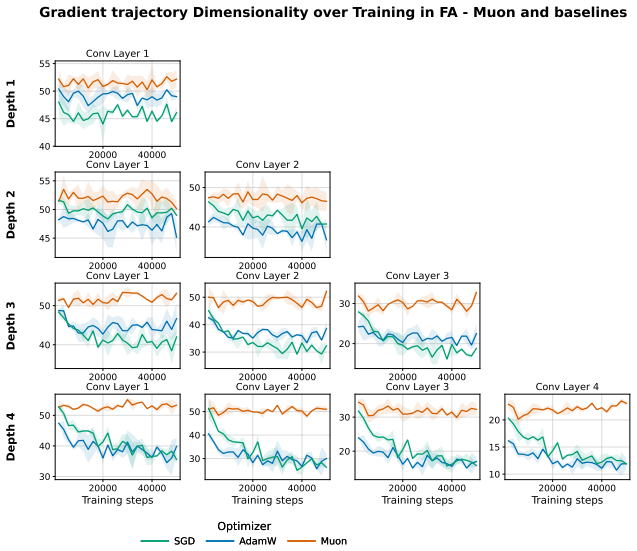
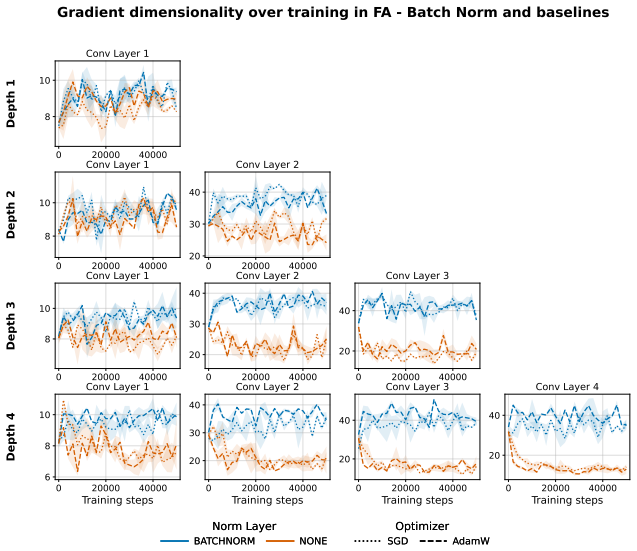
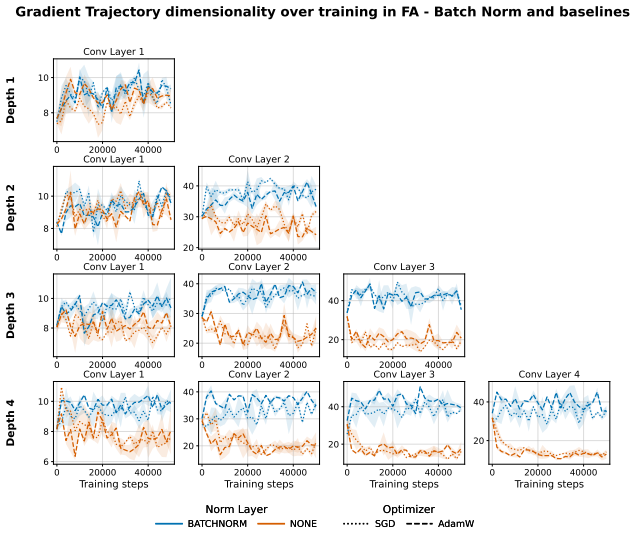
When a network is trained with fixed random feedback weights, the resulting error signal has considerably lower rank than the true gradient from backpropagation and is therefore confined to a lower-dimensional subspace; this limits exploration of the parameter space and prevents effective learning in deeper architectures. Mechanisms that orthogonalise weight updates or promote activation orthogonality increase the effective dimensionality of the updates and produce consistent accuracy improvements, including a nine-point gain on CIFAR100 with a ResNet-18.
What carries the argument
The effective rank of the error signal, which determines the dimensionality of the subspace available for parameter updates.
If this is right
- Feedback alignment error signals are confined to lower-dimensional subspaces than backpropagation gradients.
- Muon and hidden activity normalisation each raise the effective rank of the updates.
- These changes produce consistent gains across larger architectures and benchmarks.
- Accuracy on CIFAR100 with ResNet-18 improves by nine percentage points over plain feedback alignment.
- Low-dimensional gradient dynamics constitute the central obstacle to scaling feedback alignment.
Where Pith is reading between the lines
- Measuring effective rank during training could act as an early diagnostic for whether feedback alignment will succeed on a given architecture.
- The same dimensionality constraint may affect other learning rules that avoid explicit backpropagation.
- Combining rank-increasing methods with different random feedback initialisations could be tested to isolate their separate contributions.
- The approach could be checked on recurrent or attention-based models to see whether rank collapse appears outside feed-forward convolutional networks.
Load-bearing premise
The reduced effective rank of the feedback error signal is the main reason feedback alignment fails to scale, rather than other factors such as random weight initialisation or hyperparameter choices.
What would settle it
Applying Muon or activity normalisation to deeper networks and finding no accuracy improvement, or measuring that the effective rank stays low despite these changes.
Figures
read the original abstract
Backpropagation (BP) is widely viewed as biologically implausible, in part because it requires feedback weights to be the transpose of forward weights for error propagation. Interestingly, when training a network with fixed random feedback weights to circumvent this issue, learning aligns the forward weights with the feedback weights, leading the backpropagated error signal to become an approximation of the standard gradient used by BP. This process, called Feedback Alignment (FA), occurs in MLPs and very shallow CNNs but does not scale well to deeper architectures. In this work, we first investigated differences between BP and FA models, trained on CIFAR10, specifically focusing on the effective rank of the signal. We found that the FA error has a considerably lower rank and hence is constrained to a lower-dimensional subspace compared to BP, limiting exploration of the parameter space. Motivated by this observation, we evaluated two mechanisms for increasing the effective dimensionality of FA: Muon, an optimiser that orthogonalises weight updates; and hidden activity normalisation, which promotes activation orthogonality. Across larger architectures and benchmarks, we find that these methods consistently improve over FA baselines, for example, on CIFAR100 with a Resnet-18, accuracy increases by 9 percentage points. Our results identify low-dimensional gradient dynamics as a key obstacle to scaling FA and suggest that inducing higher-dimensional update geometry is a promising route toward scaling alternatives to backpropagation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Feedback Alignment (FA) fails to scale to deeper networks because its error signal has lower effective rank than backpropagation (BP), constraining updates to a lower-dimensional subspace. It proposes Muon (orthogonalizing updates) and hidden-activity normalization to increase update dimensionality, reporting consistent accuracy gains over FA baselines (e.g., +9 pp on CIFAR-100 with ResNet-18).
Significance. If the mechanism holds, the work identifies low-dimensional dynamics as a concrete obstacle to scaling alternatives to backpropagation and supplies practical interventions that improve FA on standard benchmarks. The direct experimental comparisons on CIFAR-10/100 and ResNet architectures constitute a strength.
major comments (3)
- [§4] §4 (CIFAR-100 ResNet-18 results): the 9 pp accuracy gain is presented without reported standard deviations, number of independent runs, or statistical tests, so the magnitude and reliability of the improvement cannot be assessed.
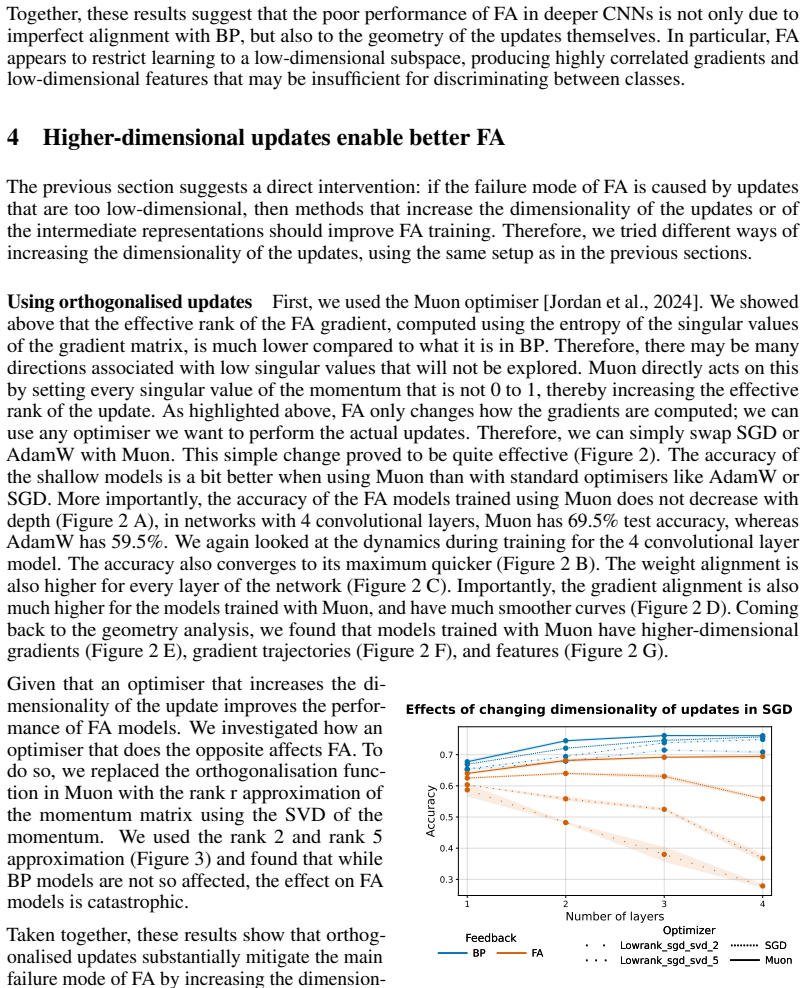
- [Motivation and experimental sections] Motivation and experimental sections: no ablation applies Muon or normalization to standard BP (or to FA while holding rank fixed) to test whether gains are specific to FA's rank deficiency or arise from generic conditioning/optimization effects; without this, the causal attribution of performance to rank remains untested.
- [Results] Results: the paper does not report measurements of effective rank after applying the proposed methods, nor any correlation between rank increase and accuracy delta across runs or architectures.
minor comments (1)
- The rank analysis on CIFAR-10 is described only briefly; expanding the description of how effective rank is computed (e.g., singular-value threshold) would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of statistical reporting, experimental controls, and mechanistic validation. We address each point below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [§4] §4 (CIFAR-100 ResNet-18 results): the 9 pp accuracy gain is presented without reported standard deviations, number of independent runs, or statistical tests, so the magnitude and reliability of the improvement cannot be assessed.
Authors: We agree that standard deviations, the number of independent runs, and statistical tests are necessary to assess reliability. In the revised manuscript we will report all CIFAR-100 ResNet-18 results as means over at least five independent runs together with standard deviations and appropriate statistical comparisons. revision: yes
-
Referee: [Motivation and experimental sections] Motivation and experimental sections: no ablation applies Muon or normalization to standard BP (or to FA while holding rank fixed) to test whether gains are specific to FA's rank deficiency or arise from generic conditioning/optimization effects; without this, the causal attribution of performance to rank remains untested.
Authors: The manuscript's primary contribution is the identification of rank collapse as a scaling obstacle for FA and the demonstration that the proposed interventions improve FA. We acknowledge that ablations on BP would help isolate whether the benefits are FA-specific. We will add these ablations (Muon and normalization applied to BP) in the revised experimental section. revision: yes
-
Referee: [Results] Results: the paper does not report measurements of effective rank after applying the proposed methods, nor any correlation between rank increase and accuracy delta across runs or architectures.
Authors: We will add direct measurements of effective rank of the error signals after Muon and activity normalization. We will also include correlations between observed rank increases and accuracy deltas across the reported architectures and runs to provide quantitative support for the mechanistic claim. revision: yes
Circularity Check
Empirical study; no derivation chain or self-referential reductions
full rationale
The paper reports experimental observations of lower effective rank in FA error signals compared to BP on CIFAR-10, then tests two interventions (Muon optimizer and hidden-activity normalization) on larger models and benchmarks, reporting accuracy gains. No equations, first-principles derivations, or predictions are presented that reduce to fitted inputs, self-definitions, or self-citation chains. All central claims rest on direct benchmark comparisons rather than any closed logical loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Adrien Bardes, Jean Ponce, and Yann LeCun. Vicreg: Variance-invariance-covariance regularization for self-supervised learning.arXiv preprint arXiv:2105.04906,
-
[2]
Jeremy Bernstein and Laker Newhouse
URL https://jeremybernste.in/writing/ deriving-muon. Jeremy Bernstein and Laker Newhouse. Old optimizer, new norm: An anthology.arXiv preprint arXiv:2409.20325,
-
[3]
Michael Cogswell, Faruk Ahmed, Ross Girshick, Larry Zitnick, and Dhruv Batra. Reducing overfit- ting in deep networks by decorrelating representations.arXiv preprint arXiv:1511.06068,
-
[4]
Training large neural networks with low-dimensional error feedback.arXiv preprint arXiv:2502.20580,
Maher Hanut and Jonathan Kadmon. Training large neural networks with low-dimensional error feedback.arXiv preprint arXiv:2502.20580,
-
[5]
The low-rank simplicity bias in deep networks.arXiv preprint arXiv:2103.10427,
Minyoung Huh, Hossein Mobahi, Richard Zhang, Brian Cheung, Pulkit Agrawal, and Phillip Isola. The low-rank simplicity bias in deep networks.arXiv preprint arXiv:2103.10427,
-
[6]
2007 Matplotlib: A 2D Graphics Environment
doi: 10.1109/MCSE.2007.55. Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. InInternational conference on machine learning, pages 448–456. pmlr,
-
[7]
Julien Launay, Iacopo Poli, and Florent Krzakala. Principled training of neural networks with direct feedback alignment.arXiv preprint arXiv:1906.04554,
Pith/arXiv arXiv 1906
-
[8]
Muon is scalable for llm training.arXiv preprint arXiv:2502.16982,
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, et al. Muon is scalable for llm training.arXiv preprint arXiv:2502.16982,
-
[9]
Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101,
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101,
-
[10]
Feedback alignment in deep convolu- tional networks.arXiv preprint arXiv:1812.06488,
Theodore H Moskovitz, Ashok Litwin-Kumar, and LF Abbott. Feedback alignment in deep convolu- tional networks.arXiv preprint arXiv:1812.06488,
-
[11]
Razvan Pascanu, Clare Lyle, Ionut-Vlad Modoranu, Naima Elosegui Borras, Dan Alistarh, Petar Velickovic, Sarath Chandar, Soham De, and James Martens. Optimizers qualitatively alter solutions and we should leverage this.arXiv preprint arXiv:2507.12224,
-
[12]
Zakhar Shumaylov, Natha¨el Da Costa, Peter Zaika, B´alint Mucs´anyi, Alex Massucco, Yoav Gelberg, Carola-Bibiane Sch¨onlieb, Yarin Gal, and Philipp Hennig. Muon is not that special: Random or inverted spectra work just as well.arXiv preprint arXiv:2605.11181,
-
[13]
Guillermo Valle-Perez, Chico Q Camargo, and Ard A Louis. Deep learning generalizes because the parameter-function map is biased towards simple functions.arXiv preprint arXiv:1805.08522,
-
[14]
Will Xiao, Honglin Chen, Qianli Liao, and Tomaso Poggio. Biologically-plausible learning algorithms can scale to large datasets.arXiv preprint arXiv:1811.03567,
-
[15]
12 A Reproducibility For sections 3 and 4, we trained all models with 2 random seeds on the CIFAR10 [Krizhevsky, 2009] dataset
URLhttps://github.com/facebookresearch/hydra. 12 A Reproducibility For sections 3 and 4, we trained all models with 2 random seeds on the CIFAR10 [Krizhevsky, 2009] dataset. The results were stable enough not to require using more seeds. We used the cross-entropy loss, mini-batch size 64 for 50,000 steps, the configured optimiser (SGD, AdamW, Muon, or low...
2009
-
[16]
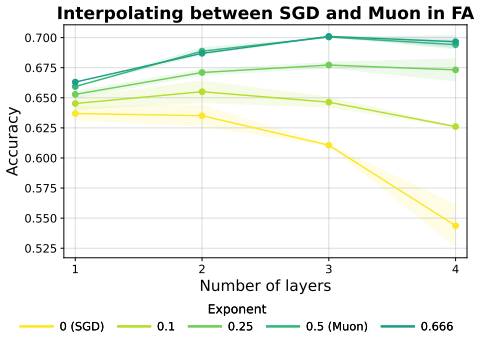
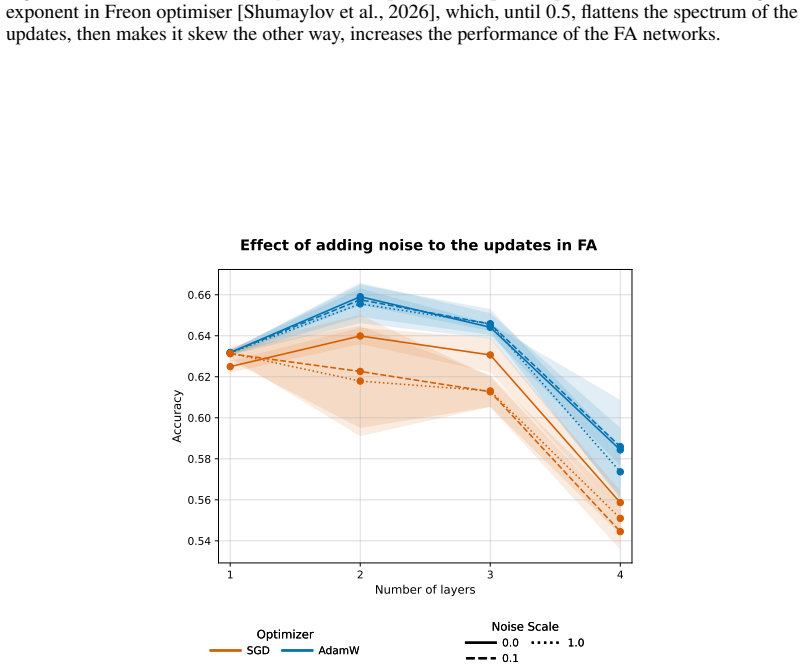
When applied to FA models, performance improves as the Freon exponent is increased from the SGD regime toward the Muon regime (Figure 6), supporting the claim that making the update higher-dimensional improves FA. 14 1 2 3 4 Number of layers 0.525 0.550 0.575 0.600 0.625 0.650 0.675 0.700Accuracy Interpolating between SGD and Muon in FA Exponent 0 (SGD) 0...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.