REVIEW 2 major objections 1 cited by
HydraPrompt detects synthetic images by anchoring real content with fixed prompts while using sample-specific adaptive prompts for fakes.
Reviewed by Pith at T0; open to challenge. T0 means a machine referee read the full paper against a public rubric. the ladder, T0–T4 →
T0 review · grok-4.3
2026-06-29 18:49 UTC pith:GHLSUVJ5
load-bearing objection HydraPrompt's asymmetric real/fake prompting plus CSC loss is a straightforward attempt to fix static prompts in VLM detection, but the abstract gives no mechanism for building sample-adaptive fake prompts at inference without extra signals. the 2 major comments →
HydraPrompt: An Adaptive and Asymmetric Framework of Vision-Language Models for Synthetic Image Detection
The pith
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
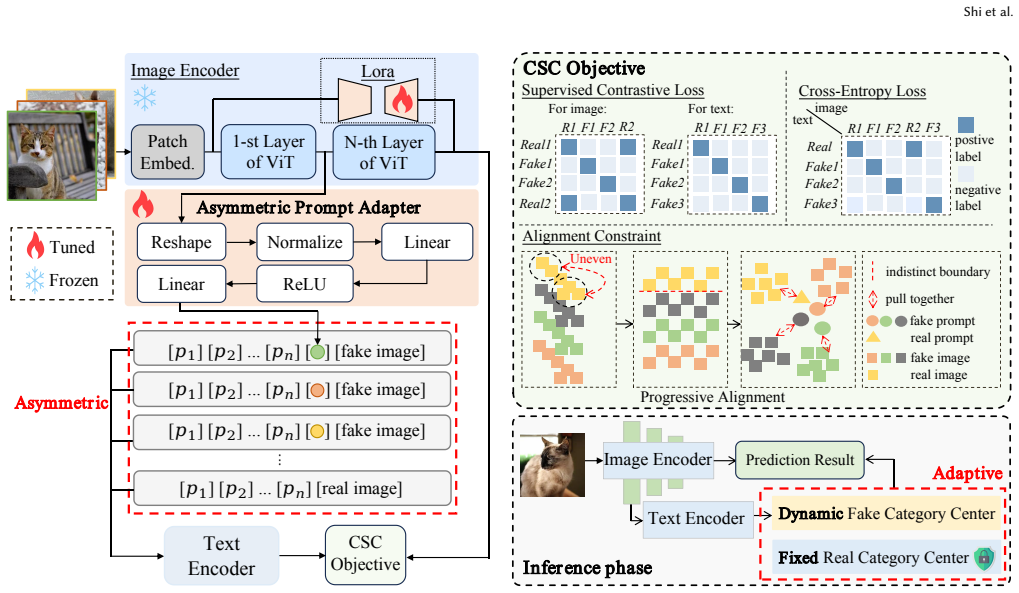
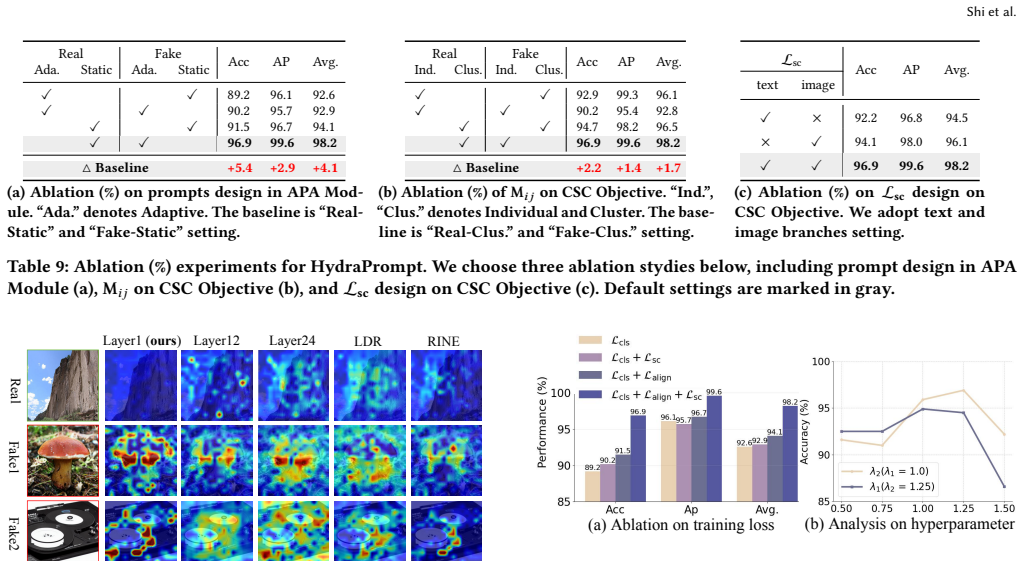
HydraPrompt is an asymmetric prompting framework that dynamically adjusts category centers by aligning with fine-grained image cues. An Asymmetric Prompt Adapter fixes one set of prompts for the authentic category as a unified anchor and builds sample-adaptive prompts for the fake category to capture diverse forgery variations. A Conditional Supervised Contrastive objective compacts authentic representations while preserving fine-grained forgery clues, producing state-of-the-art results on standard SID benchmarks.
What carries the argument
Asymmetric Prompt Adapter (APA) that applies one fixed prompt set to real images and per-sample adaptive prompts to fake images, together with the Conditional Supervised Contrastive (CSC) objective.
Load-bearing premise
Sample-adaptive prompts for the fake category can be built and aligned to image cues at inference time without knowing the forgery type or using extra supervision.
What would settle it
Performance drop on a benchmark containing forgery types absent from training where the adaptive prompts no longer separate real from fake better than a static-prompt baseline.
If this is right
- Detection remains effective across changing forgery methods because prompts adjust to each sample's cues rather than relying on a single fixed boundary.
- Real-image representations stay compact while forgery variations receive explicit modeling, increasing separation within the fake class.
- No prior forgery-type labels are required at test time, allowing deployment on unseen generators.
- State-of-the-art accuracy is reported on multiple popular synthetic image detection benchmarks.
Where Pith is reading between the lines
- The same fixed-versus-adaptive split could be tested on other vision-language classification tasks where one class is stable and the other contains high internal diversity.
- If the adaptive prompts prove robust, training pipelines might shift toward lighter supervision focused only on the real anchor rather than exhaustive fake-type labels.
- The approach suggests examining whether similar asymmetry helps in related domains such as deepfake video detection or adversarial example identification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HydraPrompt, an asymmetric prompting framework for synthetic image detection (SID) with vision-language models. It introduces an Asymmetric Prompt Adapter (APA) that maintains a single fixed set of prompts for the authentic category as a unified anchor while constructing sample-adaptive prompts for the fake category to capture diverse forgery cues. A Conditional Supervised Contrastive (CSC) objective is added to compact authentic representations and enhance discriminability among synthetic images. The framework claims state-of-the-art performance on popular SID benchmarks through dynamic adjustment of category centers aligned with fine-grained image cues.
Significance. If the adaptive mechanism for fake prompts operates at inference without forgery-type labels or extra supervision, the asymmetric design could meaningfully extend static-prompt VLM approaches by handling forgery variation, representing a targeted advance in SID. The explicit separation of fixed real anchors from per-sample fake adaptation, combined with the CSC loss, offers a clear architectural hypothesis worth testing if supported by reproducible results.
major comments (2)
- [Abstract] Abstract: The central claim that APA constructs sample-adaptive prompts for the fake category at inference time to align with fine-grained cues without forgery-type knowledge or additional supervision is load-bearing for the asymmetry and SOTA assertion, yet the abstract supplies no equations, architecture diagram, algorithm, or conditioning mechanism showing how the adapter produces these per-sample prompts from the input image and VLM alone.
- [Abstract] Abstract: The assertion of state-of-the-art performance on popular SID benchmarks is presented without any quantitative results, ablation studies, error analysis, or baseline comparisons, rendering the empirical contribution unverifiable from the provided text and undermining assessment of whether the APA+CSC design delivers the claimed gains.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address each major comment below and will revise the abstract to better support the central claims while maintaining its concise nature.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that APA constructs sample-adaptive prompts for the fake category at inference time to align with fine-grained cues without forgery-type knowledge or additional supervision is load-bearing for the asymmetry and SOTA assertion, yet the abstract supplies no equations, architecture diagram, algorithm, or conditioning mechanism showing how the adapter produces these per-sample prompts from the input image and VLM alone.
Authors: We agree that the abstract would benefit from a clearer high-level indication of the APA's conditioning mechanism. The full details, including how the adapter derives per-sample fake prompts from image features extracted by the VLM without forgery labels, are provided in Section 3 with accompanying equations and Figure 2. To address the concern directly in the abstract, we will revise it to concisely describe the asymmetric adaptation process and its inference-time operation based solely on the input image and VLM. revision: yes
-
Referee: [Abstract] Abstract: The assertion of state-of-the-art performance on popular SID benchmarks is presented without any quantitative results, ablation studies, error analysis, or baseline comparisons, rendering the empirical contribution unverifiable from the provided text and undermining assessment of whether the APA+CSC design delivers the claimed gains.
Authors: We acknowledge that the current abstract does not include numerical results. While space constraints limit full ablations or error analysis, we will revise the abstract to include key quantitative highlights (e.g., performance margins over strong baselines on primary benchmarks) to better substantiate the SOTA claim. Complete experimental results, ablations, and analyses remain in Sections 4 and 5. revision: yes
Circularity Check
No circularity: empirical framework with no derivations or self-referential reductions
full rationale
The paper presents HydraPrompt as an empirical architecture (APA for asymmetric prompts and CSC objective) whose performance is asserted via benchmark experiments. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claims rest on the design of sample-adaptive prompts and contrastive loss rather than any reduction to inputs by construction, satisfying the default expectation of non-circularity for an applied method paper.
Axiom & Free-Parameter Ledger
read the original abstract
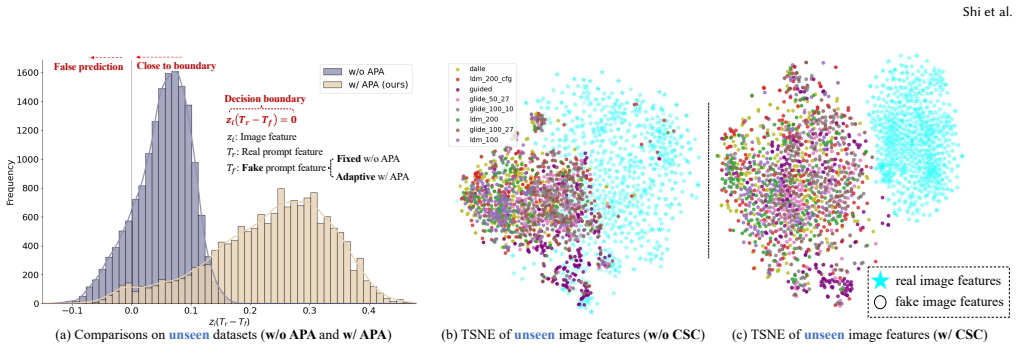
The rapid evolution of generative models has precipitated a proliferation of fabricated content, posing significant challenges to existing Synthetic Image Detection (SID) methods. Capitalizing on advancements in vision-language models (e.g., CLIP), recent attempts have leveraged learnable textual prompts to identify synthetic images. However, they still leverage static prompt as a fixed boundary for real and fake images, failing to adapt to the varying types of forgery that emerge during inference. To overcome this issue, we propose **HydraPrompt**, an asymmetric prompting framework that dynamically adjusts the category centers by aligning with fine-grained image cues. Specifically, we propose an Asymmetric Prompt Adapter (**APA**): (1) for authentic category, we introduce a single set of prompts to capture the consistent representative patterns, which serves as a unified anchor for real content. While (2) for fake category, we construct sample-adaptive prompts that specialize in capturing diverse cues from different samples, enabling adaptive modeling of forgery image variations. To increase pronounced discriminability within different synthetic images, we further introduce a Conditional Supervised Contrastive (**CSC**) objective, which compacts the authentic representations while capturing fine-grained forgery clues. Extensive experiments on popular SID benchmarks demonstrate the state-of-the-art performance of our framework.
Figures


Forward citations
Cited by 1 Pith paper
-
Veritas++: Value-aware On-Policy Distillation for Perception-Enhanced AIGI Detection
Strengthening fine-grained, semantic-anomaly, and pixel-level perception with verifiable rewards, then value-aware on-policy self-distillation, improves generalizable MLLM AI-image detection and adaptation.
Reference graph
Works this paper leans on
-
[1]
Andrew Brock, Jeff Donahue, and Karen Simonyan. 2018. Large scale GAN training for high fidelity natural image synthesis.arXiv preprint arXiv:1809.11096 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Bar Cavia, Eliahu Horwitz, Tal Reiss, and Yedid Hoshen. 2024. Real-time deepfake detection in the real-world.arXiv preprint arXiv:2406.09398(2024)
work page Pith review arXiv 2024
-
[3]
George Cazenavette, Avneesh Sud, Thomas Leung, and Ben Usman. 2024. Fakein- version: Learning to detect images from unseen text-to-image models by in- verting stable diffusion. InProceedings of the IEEE/CVF Conference on Computer HydraPrompt: An Adaptive and Asymmetric Framework of Vision-Language Models for Synthetic Image Detection Vision and Pattern Re...
2024
-
[4]
Lucy Chai, David Bau, Ser-Nam Lim, and Phillip Isola. 2020. What makes fake images detectable? understanding properties that generalize. InEuropean conference on computer vision. Springer, 103–120
2020
-
[5]
Baoying Chen, Jishen Zeng, Jianquan Yang, and Rui Yang. 2024. Drct: Diffusion reconstruction contrastive training towards universal detection of diffusion generated images. InForty-first International Conference on Machine Learning
2024
- [6]
- [7]
- [8]
-
[9]
Yunjey Choi, Minje Choi, Munyoung Kim, Jung-Woo Ha, Sunghun Kim, and Jaegul Choo. 2018. Stargan: Unified generative adversarial networks for multi- domain image-to-image translation. InProceedings of the IEEE conference on computer vision and pattern recognition. 8789–8797
2018
-
[10]
Beilin Chu, Xuan Xu, Xin Wang, Yufei Zhang, Weike You, and Linna Zhou
-
[11]
InProceedings of the Computer Vision and Pattern Recognition Conference
Fire: Robust detection of diffusion-generated images via frequency-guided reconstruction error. InProceedings of the Computer Vision and Pattern Recognition Conference. 12830–12839
-
[12]
Casey Chu, Andrey Zhmoginov, and Mark Sandler. 2017. Cyclegan, a master of steganography.arXiv preprint arXiv:1712.02950(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [13]
-
[14]
Xinjie Cui, Yuezun Li, Ao Luo, Jiaran Zhou, and Junyu Dong. 2025. Forensics adapter: Adapting clip for generalizable face forgery detection. InProceedings of the Computer Vision and Pattern Recognition Conference. 19207–19217
2025
-
[15]
Prafulla Dhariwal and Alexander Nichol. 2021. Diffusion models beat gans on image synthesis.Advances in neural information processing systems34 (2021), 8780–8794
2021
-
[16]
Ricard Durall, Margret Keuper, and Janis Keuper. 2020. Watch your up- convolution: Cnn based generative deep neural networks are failing to reproduce spectral distributions. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition. 7890–7899
2020
-
[17]
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. 2024. Scaling rectified flow transformers for high-resolution image synthesis. InForty- first international conference on machine learning
2024
-
[18]
Joel Frank, Thorsten Eisenhofer, Lea Schönherr, Asja Fischer, Dorothea Kolossa, and Thorsten Holz. 2020. Leveraging frequency analysis for deep fake image recognition. InInternational conference on machine learning. PMLR, 3247–3258
2020
-
[19]
Xinghe Fu, Zhiyuan Yan, Taiping Yao, Shen Chen, and Xi Li. 2025. Exploring unbiased deepfake detection via token-level shuffling and mixing. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 3040–3048
2025
-
[20]
Hongchang Gao, Jian Pei, and Heng Huang. 2019. Progan: Network embedding via proximity generative adversarial network. InProceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining. 1308– 1316
2019
-
[21]
Peng Gao, Shijie Geng, Renrui Zhang, Teli Ma, Rongyao Fang, Yongfeng Zhang, Hongsheng Li, and Yu Qiao. 2024. Clip-adapter: Better vision-language models with feature adapters.International Journal of Computer Vision132, 2 (2024), 581–595
2024
-
[22]
Harshayu Girase, Haiming Gang, Srikanth Malla, Jiachen Li, Akira Kanehara, Karttikeya Mangalam, and Chiho Choi. 2021. Loki: Long term and key intentions for trajectory prediction. InProceedings of the IEEE/CVF International Conference on Computer Vision. 9803–9812
2021
-
[23]
Zhihao Gu, Yang Chen, Taiping Yao, Shouhong Ding, Jilin Li, Feiyue Huang, and Lizhuang Ma. 2021. Spatiotemporal inconsistency learning for deepfake video detection. InProceedings of the 29th ACM international conference on multimedia. 3473–3481
2021
-
[24]
Zhihao Gu, Yang Chen, Taiping Yao, Shouhong Ding, Jilin Li, and Lizhuang Ma
-
[25]
InProceedings of the AAAI conference on artificial intelligence, Vol
Delving into the local: Dynamic inconsistency learning for deepfake video detection. InProceedings of the AAAI conference on artificial intelligence, Vol. 36. 744–752
-
[26]
Zhihao Gu, Taiping Yao, Yang Chen, Shouhong Ding, and Lizhuang Ma. 2022. Hierarchical contrastive inconsistency learning for deepfake video detection. In European conference on computer vision. Springer, 596–613
2022
-
[27]
Fabrizio Guillaro, Giada Zingarini, Ben Usman, Avneesh Sud, Davide Cozzolino, and Luisa Verdoliva. 2025. A bias-free training paradigm for more general ai- generated image detection. InProceedings of the Computer Vision and Pattern Recognition Conference. 18685–18694
2025
-
[28]
Xiao Guo, Xiufeng Song, Yue Zhang, Xiaohong Liu, and Xiaoming Liu. 2025. Rethinking Vision-Language Model in Face Forensics: Multi-Modal Interpretable Forged Face Detector. InProceedings of the Computer Vision and Pattern Recogni- tion Conference. 105–116
2025
- [29]
-
[30]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models.Advances in neural information processing systems33 (2020), 6840–6851
2020
-
[31]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models.ICLR1, 2 (2022), 3
2022
-
[32]
Zhenglin Huang, Jinwei Hu, Xiangtai Li, Yiwei He, Xingyu Zhao, Bei Peng, Baoyuan Wu, Xiaowei Huang, and Guangliang Cheng. 2025. Sida: Social media image deepfake detection, localization and explanation with large multimodal model. InProceedings of the Computer Vision and Pattern Recognition Conference. 28831–28841
2025
-
[33]
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. 2021. Scaling up visual and vision- language representation learning with noisy text supervision. InInternational conference on machine learning. PMLR, 4904–4916
2021
-
[34]
Yan Ju, Shan Jia, Lipeng Ke, Hongfei Xue, Koki Nagano, and Siwei Lyu. 2022. Fusing global and local features for generalized ai-synthesized image detection. In2022 IEEE International Conference on Image Processing (ICIP). IEEE, 3465–3469
2022
-
[35]
Tero Karras, Samuli Laine, and Timo Aila. 2019. A style-based generator ar- chitecture for generative adversarial networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 4401–4410
2019
-
[36]
Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. 2020. Analyzing and Improving the Image Quality of StyleGAN. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2020
-
[37]
Hossein Kashiani, Niloufar Alipour Talemi, and Fatemeh Afghah. 2025. Fre- qDebias: Towards Generalizable Deepfake Detection via Consistency-Driven Frequency Debiasing. InProceedings of the Computer Vision and Pattern Recogni- tion Conference. 8775–8785
2025
-
[38]
Muhammad Uzair Khattak, Hanoona Rasheed, Muhammad Maaz, Salman Khan, and Fahad Shahbaz Khan. 2023. Maple: Multi-modal prompt learning. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 19113–19122
2023
-
[39]
Christos Koutlis and Symeon Papadopoulos. 2024. Leveraging representations from intermediate encoder-blocks for synthetic image detection. InEuropean Conference on Computer Vision. Springer, 394–411
2024
-
[40]
Kaiqing Lin, Yuzhen Lin, Weixiang Li, Taiping Yao, and Bin Li. 2025. Standing on the shoulders of giants: Reprogramming visual-language model for general deepfake detection. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 5262–5270
2025
-
[41]
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. 2014. Microsoft coco: Common objects in context. InEuropean conference on computer vision. Springer, 740–755
2014
-
[42]
Bo Liu, Fan Yang, Xiuli Bi, Bin Xiao, Weisheng Li, and Xinbo Gao. 2022. Detecting generated images by real images. InEuropean Conference on Computer Vision. Springer, 95–110
2022
-
[43]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual in- struction tuning.Advances in neural information processing systems36 (2023), 34892–34916
2023
-
[44]
Huan Liu, Zichang Tan, Chuangchuang Tan, Yunchao Wei, Jingdong Wang, and Yao Zhao. 2024. Forgery-aware adaptive transformer for generalizable synthetic image detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10770–10780
2024
-
[45]
Zhengzhe Liu, Xiaojuan Qi, and Philip HS Torr. 2020. Global texture enhancement for fake face detection in the wild. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 8060–8069
2020
- [46]
-
[47]
Laurens van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-SNE. Journal of machine learning research9, Nov (2008), 2579–2605
2008
-
[48]
Anant Mehta, Bryant McArthur, Nagarjuna Kolloju, and Zhengzhong Tu. 2025. HFMF: Hierarchical Fusion Meets Multi-Stream Models for Deepfake Detection. InProceedings of the Winter Conference on Applications of Computer Vision. 724– 733
2025
-
[49]
Dat Nguyen, Nesryne Mejri, Inder Pal Singh, Polina Kuleshova, Marcella Astrid, Anis Kacem, Enjie Ghorbel, and Djamila Aouada. 2024. Laa-net: Localized artifact attention network for quality-agnostic and generalizable deepfake detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion. 17395–17405
2024
-
[50]
Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. 2021. Glide: Towards photorealistic Shi et al. image generation and editing with text-guided diffusion models.arXiv preprint arXiv:2112.10741(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[51]
Utkarsh Ojha, Yuheng Li, and Yong Jae Lee. 2023. Towards universal fake image detectors that generalize across generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 24480–24489
2023
-
[52]
Taesung Park, Ming-Yu Liu, Ting-Chun Wang, and Jun-Yan Zhu. 2019. Gau- gan: semantic image synthesis with spatially adaptive normalization. InACM SIGGRAPH 2019 Real-Time Live!1–1
2019
-
[53]
Yuyang Qian, Guojun Yin, Lu Sheng, Zixuan Chen, and Jing Shao. 2020. Think- ing in frequency: Face forgery detection by mining frequency-aware clues. In European conference on computer vision. Springer, 86–103
2020
-
[54]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sand- hini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al
-
[55]
In International conference on machine learning
Learning transferable visual models from natural language supervision. In International conference on machine learning. PmLR, 8748–8763
-
[56]
Anirudh Sundara Rajan, Utkarsh Ojha, Jedidiah Schloesser, and Yong Jae Lee
-
[57]
arXiv preprint arXiv:2410.11835(2024)
Aligned datasets improve detection of latent diffusion-generated images. arXiv preprint arXiv:2410.11835(2024)
-
[58]
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Rad- ford, Mark Chen, and Ilya Sutskever. 2021. Zero-shot text-to-image generation. InInternational conference on machine learning. Pmlr, 8821–8831
2021
-
[59]
Jonas Ricker, Denis Lukovnikov, and Asja Fischer. 2024. Aeroblade: Training-free detection of latent diffusion images using autoencoder reconstruction error. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion. 9130–9140
2024
-
[60]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-Resolution Image Synthesis With Latent Diffusion Mod- els. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 10684–10695
2022
-
[61]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10684–10695
2022
-
[62]
Andreas Rossler, Davide Cozzolino, Luisa Verdoliva, Christian Riess, Justus Thies, and Matthias Nießner. 2019. Faceforensics++: Learning to detect manipulated facial images. InProceedings of the IEEE/CVF international conference on computer vision. 1–11
2019
-
[63]
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedan- tam, Devi Parikh, and Dhruv Batra. 2017. Grad-cam: Visual explanations from deep networks via gradient-based localization. InProceedings of the IEEE inter- national conference on computer vision. 618–626
2017
-
[64]
Ke Sun, Shen Chen, Taiping Yao, Ziyin Zhou, Jiayi Ji, Xiaoshuai Sun, Chia-Wen Lin, and Rongrong Ji. 2025. Towards general visual-linguistic face forgery detec- tion. InProceedings of the Computer Vision and Pattern Recognition Conference. 19576–19586
2025
-
[65]
Chuangchuang Tan, Renshuai Tao, Huan Liu, Guanghua Gu, Baoyuan Wu, Yao Zhao, and Yunchao Wei. 2025. C2p-clip: Injecting category common prompt in clip to enhance generalization in deepfake detection. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 7184–7192
2025
-
[66]
Chuangchuang Tan, Yao Zhao, Shikui Wei, Guanghua Gu, Ping Liu, and Yunchao Wei. 2024. Frequency-aware deepfake detection: Improving generalizability through frequency space domain learning. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 5052–5060
2024
-
[67]
Chuangchuang Tan, Yao Zhao, Shikui Wei, Guanghua Gu, Ping Liu, and Yunchao Wei. 2024. Rethinking the up-sampling operations in cnn-based generative network for generalizable deepfake detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 28130–28139
2024
-
[68]
Chuangchuang Tan, Yao Zhao, Shikui Wei, Guanghua Gu, and Yunchao Wei. 2023. Learning on gradients: Generalized artifacts representation for gan-generated images detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12105–12114
2023
- [69]
- [70]
-
[71]
Hao Tan, Zichang Tan, Jun Li, Ajian Liu, Jun Wan, and Zhen Lei. 2025. Re- cover and Match: Open-Vocabulary Multi-Label Recognition through Knowledge- Constrained Optimal Transport. InProceedings of the Computer Vision and Pattern Recognition Conference. 4650–4660
2025
-
[72]
Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Liwei Wang. 2024. Visual autoregressive modeling: Scalable image generation via next-scale prediction. Advances in neural information processing systems37 (2024), 84839–84865
2024
- [73]
-
[74]
Sheng-Yu Wang, Oliver Wang, Richard Zhang, Andrew Owens, and Alexei A Efros. 2020. CNN-generated images are surprisingly easy to spot... for now. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 8695–8704
2020
-
[75]
Tongzhou Wang and Phillip Isola. 2020. Understanding contrastive representa- tion learning through alignment and uniformity on the hypersphere. InInterna- tional conference on machine learning. PMLR, 9929–9939
2020
-
[76]
Zhendong Wang, Jianmin Bao, Wengang Zhou, Weilun Wang, Hezhen Hu, Hong Chen, and Houqiang Li. 2023. Dire for diffusion-generated image detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 22445– 22455
2023
-
[77]
Monika Wysoczańska, Oriane Siméoni, Michaël Ramamonjisoa, Andrei Bursuc, Tomasz Trzciński, and Patrick Pérez. 2024. CLIP-DINOiser: Teaching CLIP a few DINO tricks for open-vocabulary semantic segmentation. InEuropean Conference on Computer Vision. Springer, 320–337
2024
-
[78]
Zhipei Xu, Xuanyu Zhang, Runyi Li, Zecheng Tang, Qing Huang, and Jian Zhang
- [79]
-
[80]
Shilin Yan, Ouxiang Li, Jiayin Cai, Yanbin Hao, Xiaolong Jiang, Yao Hu, and Weidi Xie. 2024. A sanity check for ai-generated image detection.arXiv preprint arXiv:2406.19435(2024)
work page Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.