Where Does the Signal Live? A Web Data Recipe for Medical Encoder Pretraining
Pith reviewed 2026-06-26 11:52 UTC · model grok-4.3
The pith
Medical-term density filtering plus LLM rephrasing on web data beats standard educational filters for pretraining medical encoders.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
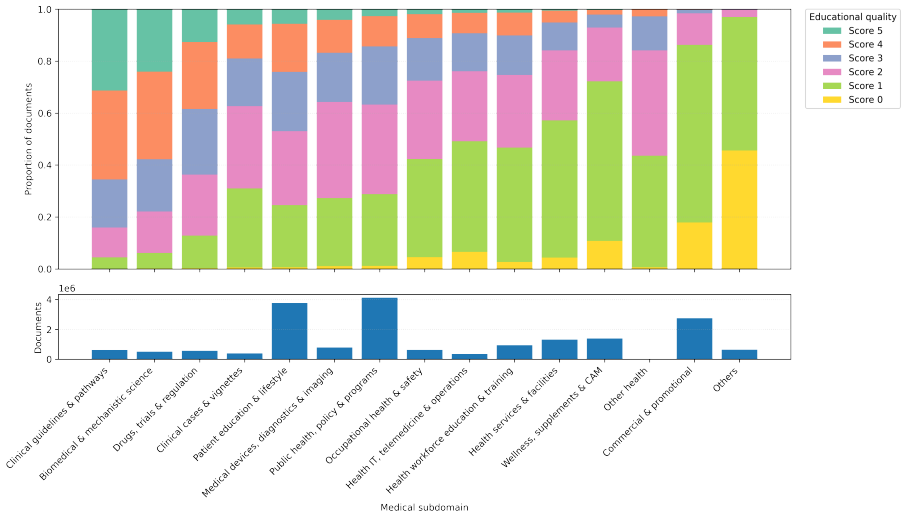
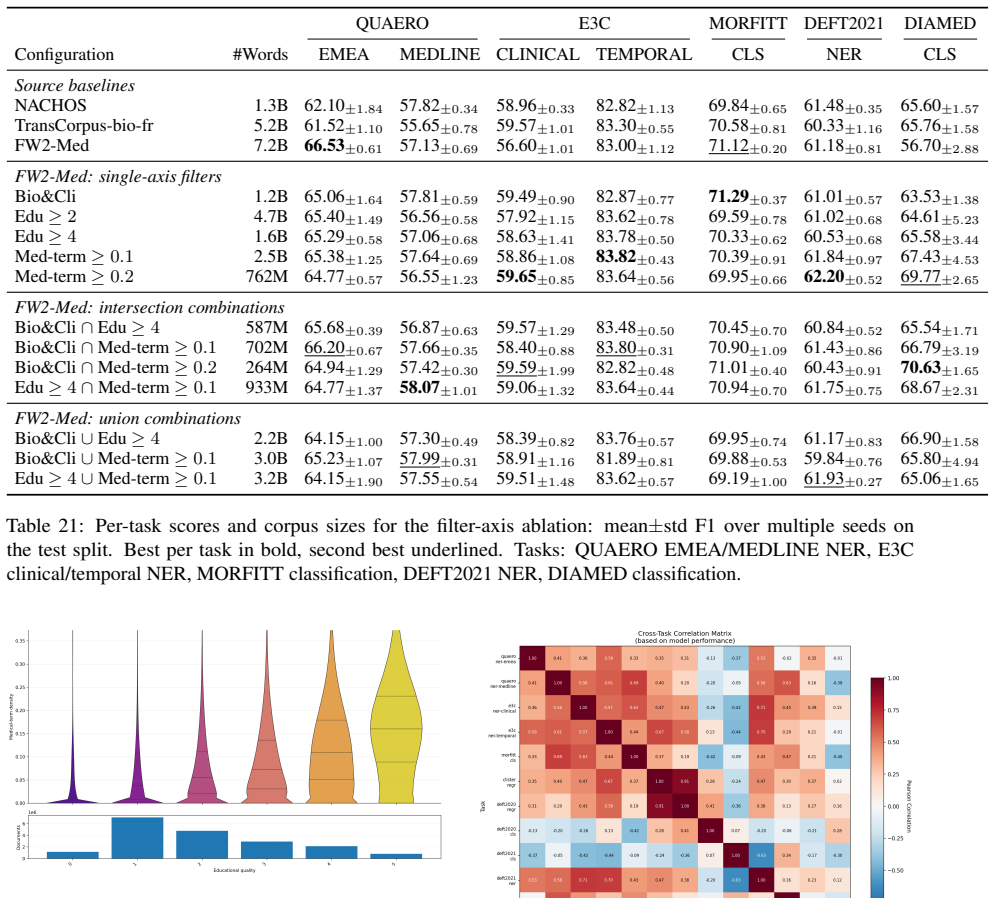
A medical-term density filter applied to web documents outperforms the widely used educational quality filter on downstream medical tasks; the two filters are complementary; signal-amplifying rephrasing by LLM alone improves over raw web text; and the largest gains come from mixing filtered and rephrased data, yielding the FineMed pretraining corpus and the DoctoBERT family of French medical encoders.
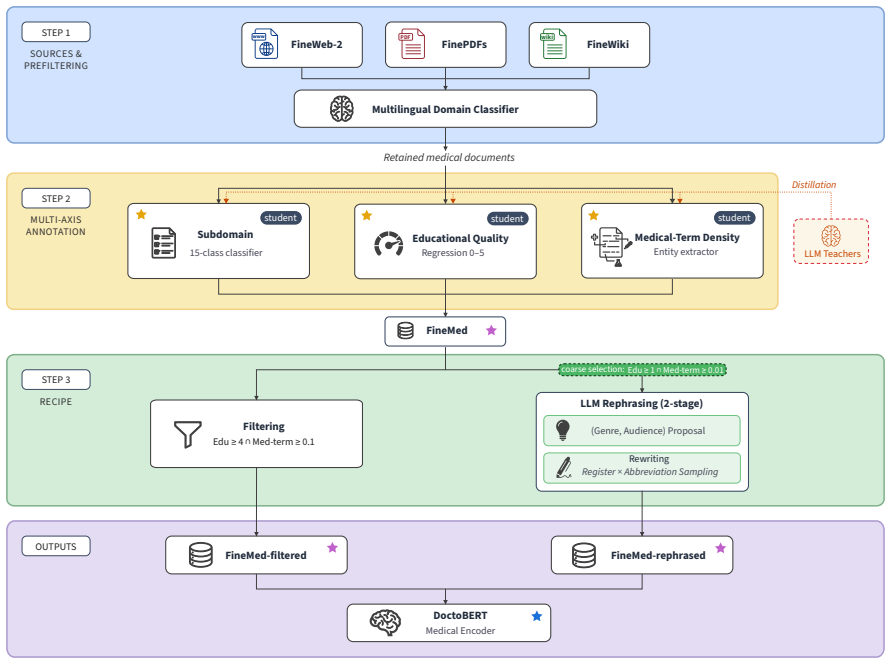
What carries the argument
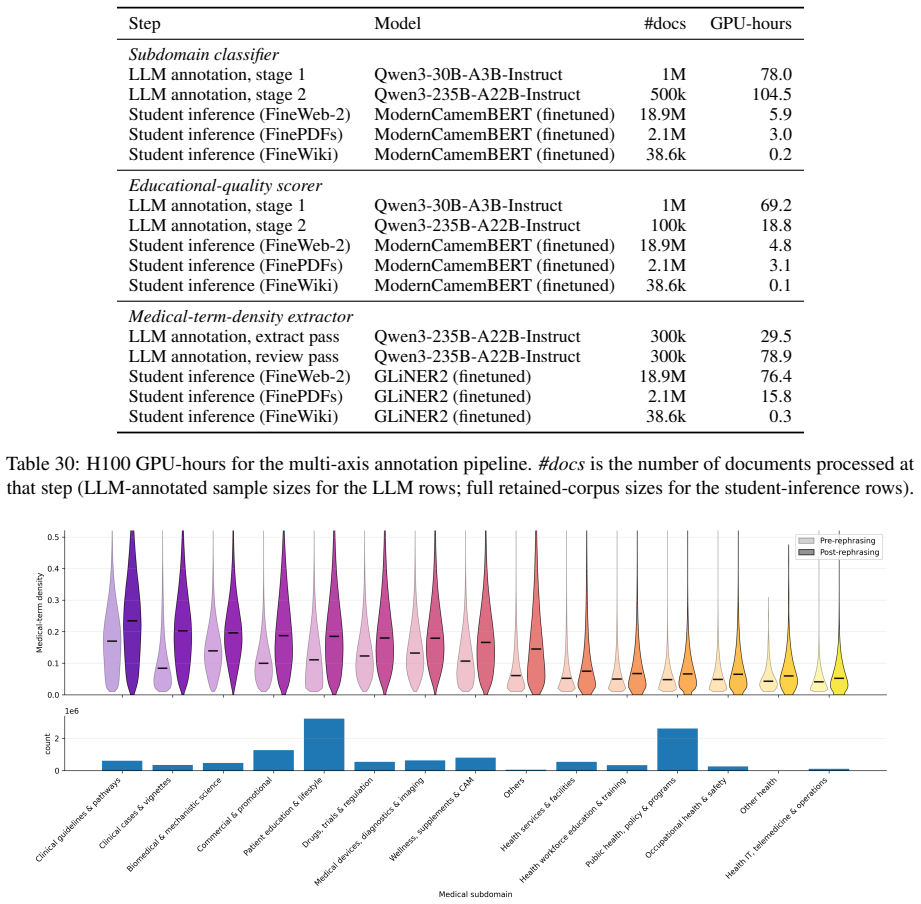
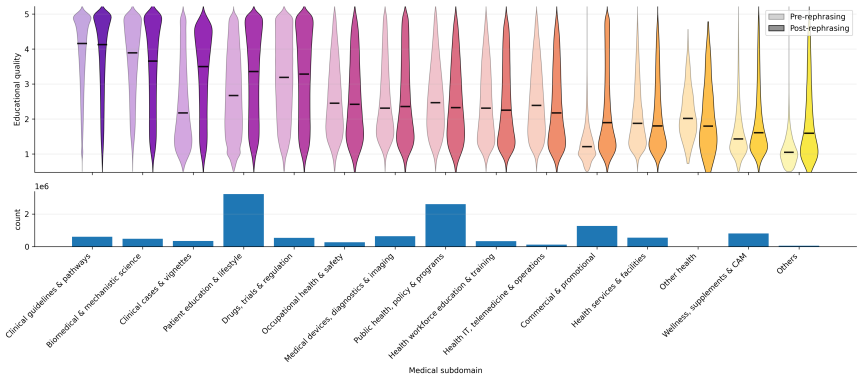
Medical-term density filter that selects documents rich in medical terms, paired with LLM-based signal-amplifying rephrasing that rewrites documents into denser variants with broader entity contexts.
If this is right
- Medical-term density filtering outperforms educational quality filtering on medical downstream tasks.
- Density and educational filters complement each other when combined.
- Signal-amplifying rephrasing alone raises performance over raw web data.
- The largest gains occur when filtered web data is mixed with its rephrased versions.
- The resulting corpus and encoder family reach state-of-the-art results on French medical benchmarks.
Where Pith is reading between the lines
- The same two levers could be tested on other dense-terminology domains such as legal or scientific text.
- Signal density may matter more than stylistic polish for encoder MLM objectives.
- The approach offers a route to reduce reliance on small manually curated corpora in non-English medical settings.
Load-bearing premise
LLM rephrasing of web documents reliably increases medical signal without adding hallucinations or factual distortions that would hurt downstream performance.
What would settle it
Downstream scores on DrBenchmark or the clinical NER task fall below the filtered-only baseline when the rephrased data is added to the training mix.
Figures
read the original abstract
Web data curation has been widely studied for decoder Large Language Model (LLM) pretraining. Encoders for dense-terminology domains such as medicine, by contrast, are pretrained on small, manually-curated corpora that limit scalability and writing style diversity, a bottleneck even more severe in non-English clinical settings. Whether web-scale data curation also benefits encoder Masked Language Modeling (MLM) in a dense-terminology domain remains an open question. To address this, we introduce two complementary levers. Medical-term density filtering selects documents rich in medical terms. Signal-amplifying rephrasing uses an LLM to rewrite documents into denser variants with broader entity contexts. We instantiate the recipe on French medical NLP. The medical-term density filter outperforms the widely-used educational quality filter on downstream medical tasks, and the two complement each other. Signal-amplifying rephrasing alone improves on raw web data, and mixing it with filtered web data produces the largest gain. The recipe yields FineMed, a French medical pretraining corpus, and DoctoBERT, a state-of-the-art French medical encoder family evaluated on both the public benchmark DrBenchmark and a proprietary clinical Named Entity Recognition (NER) task.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a web data curation recipe for pretraining medical encoders consisting of medical-term density filtering and LLM-based signal-amplifying rephrasing. On French web data, the density filter outperforms the educational quality filter and the two complement each other; rephrasing alone improves over raw web data, and mixing yields the largest gain. This produces the FineMed corpus and DoctoBERT models, claimed as state-of-the-art on DrBenchmark and a proprietary clinical NER task.
Significance. If the results hold, the work shows that web-scale curation techniques can scale medical encoder pretraining beyond small manually-curated corpora in dense-terminology domains, with value for non-English settings. The empirical comparisons on held-out downstream tasks are a strength.
major comments (1)
- [Abstract and rephrasing method] The central claim that signal-amplifying rephrasing improves performance (and complements density filtering) depends on the rephrased documents being higher-signal without introduced hallucinations, factual distortions, or entity errors. No audit or validation of rephrased vs. original pairs for medical accuracy or entity fidelity is described, which is load-bearing because downstream DrBenchmark and NER metrics may be insensitive to distortions in clinical spans. (Abstract; section on signal-amplifying rephrasing)
minor comments (2)
- [Abstract] The abstract reports positive downstream gains but supplies no quantitative numbers, error bars, statistical tests, baseline details, or information on data splits and evaluation protocols.
- Consider clarifying the exact definition and implementation of the medical-term density filter (e.g., term list, threshold) to allow reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of major revision. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract and rephrasing method] The central claim that signal-amplifying rephrasing improves performance (and complements density filtering) depends on the rephrased documents being higher-signal without introduced hallucinations, factual distortions, or entity errors. No audit or validation of rephrased vs. original pairs for medical accuracy or entity fidelity is described, which is load-bearing because downstream DrBenchmark and NER metrics may be insensitive to distortions in clinical spans. (Abstract; section on signal-amplifying rephrasing)
Authors: We agree that the absence of a direct audit or validation of rephrased versus original document pairs for medical accuracy and entity fidelity is a substantive limitation. The submitted manuscript does not describe any such audit and instead presents downstream task improvements as the primary evidence for the rephrasing step. While consistent gains on DrBenchmark and the clinical NER task provide indirect support, these metrics could indeed overlook localized distortions. In the revised manuscript we will add a dedicated subsection presenting a qualitative review of a sampled set of original-rephrased pairs, with explicit checks for hallucinations, factual changes, and entity fidelity, plus a limitations paragraph discussing the risks of LLM rephrasing in the medical domain. revision: yes
Circularity Check
No circularity: empirical comparisons on held-out tasks
full rationale
The paper reports empirical results from data filtering and rephrasing experiments evaluated on downstream benchmarks (DrBenchmark, proprietary NER). No equations, parameter fits, self-referential predictions, or derivation chains appear in the abstract or described methodology. Claims rest on held-out task deltas rather than any reduction of outputs to inputs by construction or self-citation load-bearing. This is the standard non-circular case for an empirical curation study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Iz Beltagy, Kyle Lo, and Arman Cohan
ModernBERT or DeBERTaV3? Exam- ining Architecture and Data Influence on Trans- former Encoder Models Performance.Preprint, arXiv:2504.08716. Iz Beltagy, Kyle Lo, and Arman Cohan. 2019. SciBERT: A Pretrained Language Model for Scientific Text. Preprint, arXiv:1903.10676. Aman Berhe, Guillaume Draznieks, Vincent Martenot, Valentin Masdeu, Lucas Davy, and Je...
arXiv 2019
-
[2]
9 Lola Le Breton, Quentin Fournier, Mariam El Mezouar, John X
EuroBERT: Scaling Multilingual Encoders for European Languages.Preprint, arXiv:2503.05500. 9 Lola Le Breton, Quentin Fournier, Mariam El Mezouar, John X. Morris, and Sarath Chandar. 2025. NeoBERT: A Next-Generation BERT.Preprint, arXiv:2502.19587. Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan...
Pith/arXiv arXiv 2025
-
[3]
Bioinformatics, 36(4):1234–1240
BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics, 36(4):1234–1240. Simon A. Lee, Anthony Wu, and Jeffrey N. Chiang
-
[4]
Clinical ModernBERT: An efficient and long context encoder for biomedical text.Preprint, arXiv:2504.03964. Yoav Levine, Barak Lenz, Opher Lieber, Omri Abend, Kevin Leyton-Brown, Moshe Tennenholtz, and Yoav Shoham. 2020. PMI-Masking: Principled masking of correlated spans.Preprint, arXiv:2010.01825. 10 Jeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Ma...
arXiv 2020
-
[5]
Scaling Data-Constrained Language Models. Preprint, arXiv:2305.16264. Joel Niklaus, Atsuki Yamaguchi, Michal Štefánik, Guilherme Penedo, Hynek Kydlíˇcek, Elie Bakouch, Lewis Tunstall, Edward Emanuel Beeching, Thibaud Frere, Colin Raffel, Leandro von Werra, and Thomas Wolf. 2026. How Can We Synthesize High-Quality Pretraining Data? A Systematic Study of Pr...
Pith/arXiv arXiv 2026
-
[6]
Captures the magnitude of differences: a model that underperforms on a few tasks is penalized heavily. • Win Probability: for each ordered pair of models (A, B), compute the fraction of tasks where A’s mean score exceeds B’s (ties Figure 5: Pairwise Pearson correlation between Dr- Benchmark tasks, computed over per-model mean scores. Cells with low absolu...
2025
-
[7]
We report annotation hours as4×wall-clock
with TP=4 on H100s: Qwen3-30B-A3B- Instruct in bf16, Qwen3-235B-A22B-Instruct as the native-FP8 checkpoint. We report annotation hours as4×wall-clock. 20 QUAERO E3C MORFITT DEFT2021 DIAMED Configuration #Words EMEA MEDLINE CLINICAL TEMPORAL CLS NER CLS Baseline Raw (no rephrasing) 392M65.49 ±1.73 56.19±0.47 59.78±2.15 82.99±0.55 68.98±1.04 59.94±0.77 64.8...
2023
-
[8]
If a URL is present, use it for context only; the document's text is the primary source of truth
Analyze the document: Carefully read the provided text to identify its primary focus, key themes, and specific terminology. If a URL is present, use it for context only; the document's text is the primary source of truth
-
[9]
Choose the one topic that most accurately reflects the document's main subject
Select the best topic: Compare the document's content against the list of allowed topics and their definitions. Choose the one topic that most accurately reflects the document's main subject
-
[10]
This reasoning must be 100 words or less and include 1−2 short, direct quotes from the text as evidence
Construct reasoning: Write a concise justification for your topic selection. This reasoning must be 100 words or less and include 1−2 short, direct quotes from the text as evidence
-
[11]
Handle exceptions: If the text is too short to analyze, is not clearly health−related, or consists mainly of navigational elements (like menus or footers), you must assign the topic "Others"
-
[12]
reasoning
Strict topic selection: You must **choose exactly one topic** from the provided list. Do not invent new topics or alter the existing ones. </guidelines> Allowed Topics: <topics> ... (15 classes; full names and descriptions in the taxonomy table above) </topics> Output Format: Your response must be in strict JSON format with the following structure: <outpu...
-
[13]
A term qualifies only if its meaning is intrinsically medical — not merely because it appears in a clinical document
Strictly biomedical: Only extract entities with inherent **biomedical or clinical meaning**. A term qualifies only if its meaning is intrinsically medical — not merely because it appears in a clinical document
-
[14]
Favor recall: Within the biomedical scope, if a term plausibly fits a group and is explicitly present, extract it
-
[15]
Do not infer, summarize, rephrase, or generate entities that are not explicitly present
Extract verbatim: Only extract text spans that appear exactly in the input. Do not infer, summarize, rephrase, or generate entities that are not explicitly present
-
[16]
acute myocardial infarction
Longest span: Prefer the longest meaningful span (e.g., "acute myocardial infarction" over "infarction")
-
[17]
Preserve surface form: Keep exact case, punctuation, and spacing
-
[18]
Include abbreviations: Extract medical abbreviations and acronyms (e.g., MI, COPD, MRI, CT)
-
[19]
Extract once: If an entity appears multiple times, include it only once per group
-
[20]
63 years old
One category per entity: Assign each entity to exactly one group. ## Extraction Order − Process entity groups in this order: disease, drug, body_part, medical_procedure, molecular_marker, clinical_device, vital_function, living_beings. − For each group, scan the text from beginning to end and output spans in the same order they appear. − Omit any entity g...
-
[21]
**Adding** any valid medical entities that were missed
-
[22]
**Removing** any false positives (non−medical terms or incorrectly categorized entities)
-
[23]
acute myocardial infarction
**Reclassifying** any entities assigned to the wrong category ## Review Guidelines ### What to ADD (Missed Entities) Add entities that: − Have clear biomedical or clinical meaning and appear verbatim in the text − Are medical abbreviations or acronyms (e.g., MI, COPD, MRI, CT) − Are drug names, disease names, anatomical terms, procedures, etc. that were o...
-
[24]
Identify any that should be removed or reclassified
**Analyze false positives**: Examine each entity in the initial extraction. Identify any that should be removed or reclassified
-
[25]
Find any medical entities not captured in the initial extraction
**Identify missed entities**: Read the original text carefully. Find any medical entities not captured in the initial extraction
-
[26]
**Reason through changes**: Document your reasoning for each modification
-
[27]
reasoning
**Produce corrected output**: Generate the final corrected extraction. ## Output Format Return ONLY a JSON object with reasoning followed by the corrected extraction. No explanations outside JSON. No markdown code blocks. { "reasoning": { "false_positives": "<List entities to remove and explain why each is not a valid medical entity or doesn't belong. Wri...
-
[28]
**Per−dimension breadth**: across your {n_stage1_pairs} proposals, use at least 3 distinct genres AND at least 3 distinct audiences
-
[29]
E.g.,`(patient_education, layperson)`+`(patient_leaflet, layperson)`are duplicates
**No near−duplicates**: if two proposals share both genre and audience, or could be summarized with the same one−sentence description, replace one. E.g.,`(patient_education, layperson)`+`(patient_leaflet, layperson)`are duplicates
-
[30]
**Anti−bias**: include`patient_education`in at most ONE proposal, and`patient_or_layperson`as audience in at most TWO
-
[31]
**Pair−level plausibility**: each pair must be plausible in real medical writing. Do NOT couple`(prescription, researcher)`,`(research_abstract, layperson)`, or`(clinical_note, layperson)`— the brainstorm gave per−dimension flexibility; coupling must respect real−world combinations
-
[32]
no", "denies
**Honesty floor**: if fewer than {n_stage1_pairs} pairs satisfy rules 1–4 from the realizable lists, return fewer pairs. Do NOT invent realizability. ## Language `reasoning`uses natural prose.`genre`and`audience`are English machine identifiers (not translated). The stage−2 rewriter renders the document in {language}. Prompt 5. Stage-1 rephrasing prompt (g...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.