Merge-Bench: Resolve Merge Conflicts with Large Language Models
Pith reviewed 2026-06-29 22:41 UTC · model grok-4.3
The pith
A 14B-parameter model trained via reinforcement learning on real merge conflicts outperforms three commercial LLMs on Java.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
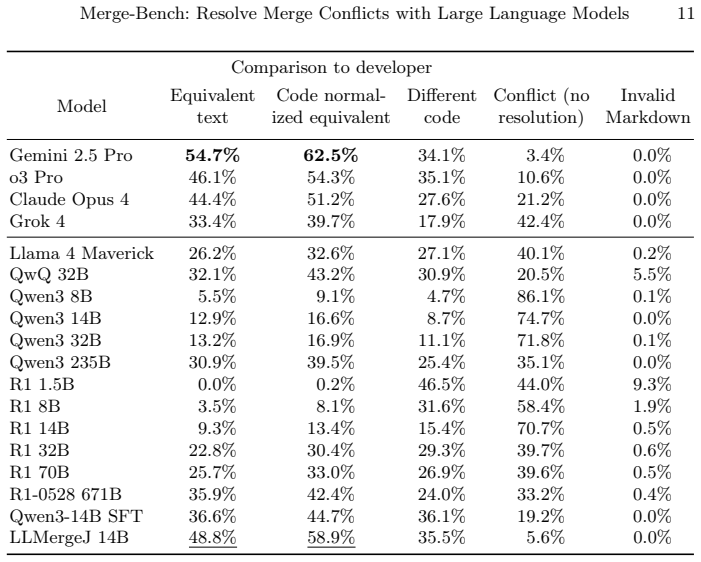
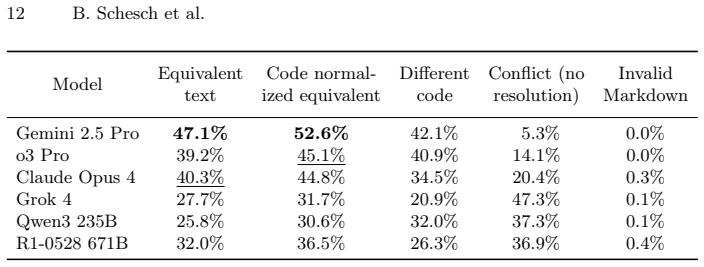
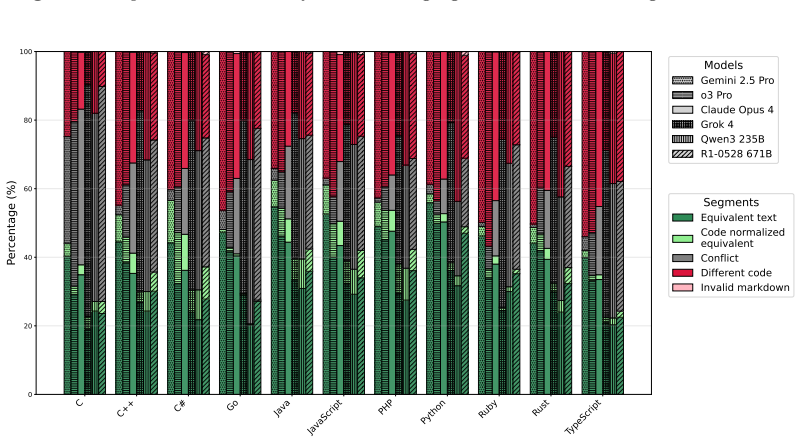
The paper establishes that LLMergeJ, a 14B-parameter model trained with Group Relative Policy Optimization on the Merge-Bench dataset of 7938 merge conflict hunks, outperforms three commercial large language models on resolving Java merge conflicts while trailing only Gemini 2.5 Pro, and that commercial LLM performance remains largely stable but below 60 percent success across eleven programming languages.
What carries the argument
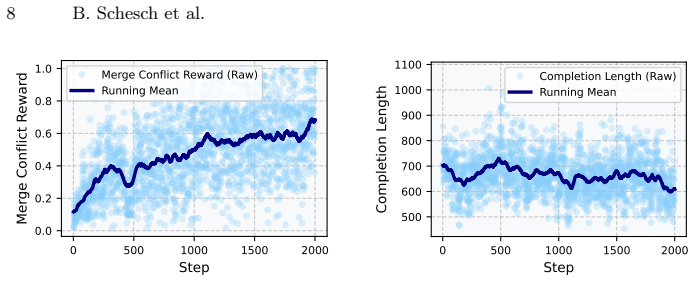
Merge-Bench dataset of real-world merge conflict hunks with developer-committed resolutions as ground truth, used to train LLMergeJ via GRPO reinforcement learning.
If this is right
- Automated tools could reduce time spent on Java merge conflicts in large codebases.
- Performance stability across languages suggests the approach does not require per-language retraining.
- Accuracy below 60 percent implies models would still need human review for the majority of cases.
- Scalable dataset construction allows training on far larger collections of conflicts.
Where Pith is reading between the lines
- If developers sometimes commit suboptimal merges, both training and evaluation would inherit that noise.
- Applying the same training method to other languages could test whether language-specific models improve beyond the observed stability.
- Embedding such models in Git clients might shift team practices around concurrent changes.
Load-bearing premise
That the merge resolutions developers actually committed to the repository are always the correct ground truth for both training and measuring performance.
What would settle it
Independent resolutions of the same conflicts by multiple experienced developers, compared against both the committed resolutions and model outputs to measure agreement rates.
Figures


read the original abstract
This paper applies machine learning to the difficult and important task of version control merging. (1) We constructed a dataset, Merge-Bench, of 7938 real-world merge conflict hunks from 1439 GitHub repositories. The ground truth is the merge resolution that developers committed to the repository. Our dataset construction methodology is scalable to arbitrary amounts of data since no manual labeling is required. (2) We trained a model, LLMergeJ, to resolve merge conflicts in Java programs. Our approach uses Group Relative Policy Optimization (GRPO), an online reinforcement learning method, to train a Large Language Model (LLM). (3) We performed two evaluations of the performance of LLMs on resolving merge conflicts. On Java programs, LLMergeJ with 14B parameters outperforms 3 commercial LLMs, trailing only Gemini 2.5 Pro. Across 11 programming languages, commercial LLM performance is largely stable from language to language. The best models correctly resolve less than 60% of merge conflicts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Merge-Bench, a dataset of 7938 real-world merge conflict hunks from 1439 GitHub repositories, with developer-committed resolutions serving as ground truth. It describes training LLMergeJ, a 14B-parameter LLM using Group Relative Policy Optimization (GRPO) for Java merge conflicts. Evaluations indicate that LLMergeJ outperforms three commercial LLMs on Java while trailing only Gemini 2.5 Pro; across 11 languages, commercial LLM performance is largely stable, with the best models correctly resolving less than 60% of conflicts.
Significance. If the central results hold, the work is significant for applying LLMs and RL to a practical software engineering task. The scalable, automatically constructed dataset (no manual labeling required) is a clear strength that supports large-scale training and benchmarking. The application of GRPO for policy optimization on merge resolution is a methodological contribution. The reported performance ceiling below 60% and cross-language stability provide falsifiable benchmarks that can guide future model development in this domain.
major comments (2)
- [Abstract] Abstract: The performance claims (LLMergeJ outperforming three commercial LLMs on Java; best models resolving <60% of conflicts) rest entirely on treating developer-committed resolutions as correct ground truth for both training (GRPO reward) and evaluation. No validation of GT quality, discussion of multiple valid resolutions, or analysis of selection biases in the 7938 hunks is reported. This assumption is load-bearing; if a non-negligible fraction of committed merges are suboptimal or later revised, both the 14B model win rates and the commercial ceiling become unreliable.
- [Abstract] Abstract: The abstract reports concrete performance numbers but supplies no information on evaluation methodology, how conflicts were selected from the 1439 repositories, statistical significance of the comparisons, or controls for dataset biases. This absence prevents verification of the central claims from the provided text.
minor comments (1)
- [Abstract] The manuscript could clarify whether the 11-language evaluation uses the same conflict selection criteria as the Java subset and whether any language-specific preprocessing was applied.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the importance of ground truth validation and methodological transparency. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The performance claims (LLMergeJ outperforming three commercial LLMs on Java; best models resolving <60% of conflicts) rest entirely on treating developer-committed resolutions as correct ground truth for both training (GRPO reward) and evaluation. No validation of GT quality, discussion of multiple valid resolutions, or analysis of selection biases in the 7938 hunks is reported. This assumption is load-bearing; if a non-negligible fraction of committed merges are suboptimal or later revised, both the 14B model win rates and the commercial ceiling become unreliable.
Authors: We agree that developer-committed resolutions are an imperfect proxy for optimality and that the manuscript does not include explicit validation of GT quality or analysis of selection biases. This is a standard limitation in large-scale, automatically constructed SE benchmarks where manual inspection of thousands of cases is infeasible. However, the approach follows established practice in prior merge-conflict and code-generation datasets. To address the concern directly, we will add a dedicated limitations subsection (in Section 3) that (a) discusses the possibility of multiple valid resolutions, (b) reports any available post-hoc checks on a random sample of hunks, and (c) quantifies repository-level selection criteria to surface potential biases. These additions will not change the reported numbers but will qualify their interpretation. revision: yes
-
Referee: [Abstract] Abstract: The abstract reports concrete performance numbers but supplies no information on evaluation methodology, how conflicts were selected from the 1439 repositories, statistical significance of the comparisons, or controls for dataset biases. This absence prevents verification of the central claims from the provided text.
Authors: The current abstract prioritizes brevity and contribution highlights; full details on hunk selection, evaluation protocol, statistical tests, and bias controls appear in Sections 3 (Dataset Construction) and 4 (Experiments). We accept that the abstract should be more self-contained for readers who encounter only that section. We will revise the abstract to include one additional sentence summarizing the evaluation methodology, conflict filtering criteria, and the use of exact-match accuracy with statistical significance testing, while keeping the word count within typical limits. revision: yes
Circularity Check
No significant circularity: external developer resolutions serve as independent ground truth
full rationale
The paper's dataset and evaluation rest on merge resolutions that developers independently committed to GitHub repositories. These serve as external labels for both GRPO-based training and accuracy metrics. No step reduces a claimed prediction or result to a quantity fitted from the model's own outputs, nor does any load-bearing premise rely on self-citation chains or ansatzes imported from the authors' prior work. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: ESEC/FSE
Apel, S., Liebig, J., Brandl, B., Lengauer, C., Kästner, C.: Semistructured merge: Rethinking merge in revision control systems. In: ESEC/FSE. pp. 190–200 (Sep 2011)
2011
-
[2]
Brindescu, C., Ahmed, I., Jensen, C., Sarma, A.: An empirical investigation into merge conflicts and their effect on software quality. Empirical Softw. Engg.25, 562–590 (Jan 2020). https://doi.org/10.1007/s10664-019-09735-4
-
[3]
IEEE TSE49(4), 1599–1614 (Apr 2023)
Dinella, E., Mytkowicz, T., Svyatkovskiy, A., Bird, C., Naik, M., Lahiri, S.: Deep- Merge: Learning to merge programs. IEEE TSE49(4), 1599–1614 (Apr 2023)
2023
-
[4]
Dong, J., Zhu, Q., Sun, Z., Lou, Y., Hao, D.: Merge conflict resolution: Classifica- tion or generation? In: ASE. pp. 1652–1663 (Sep 2023)
2023
-
[5]
Gousios, G.: The GHTorrent dataset and tool suite. In: MSR. pp. 233–236 (May 2013). https://doi.org/https://doi.org/10.1109/MSR.2013.6624034
-
[6]
Guo, D., Yang, D., Zhang, H., Song, J., Wang, P., Zhu, Q., Xu, R., Zhang, R., Ma, S., et al.: DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning. Nature645, 633–638 (Sep 2025). https://doi.org/10.1038/s41586-025- 09422-z
-
[7]
Han,D.,Han,M.,UnslothTeam:Unsloth(2023),http://github.com/unslothai/ unsloth
2023
-
[8]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Jain, N., Han, K., Gu, A., Li, W.D., Yan, F., Zhang, T., Wang, S., Solar-Lezama, A., Sen, K., Stoica, I.: LiveCodeBench: Holistic and contamination free evaluation of large language models for code. arXiv preprint arXiv:2403.07974 (June 2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Jimenez, C.E., Yang, J., Wettig, A., Yao, S., Pei, K., Press, O., Narasimhan, K.: SWE-bench: Can language models resolve real-world GitHub issues?{https:// arxiv.org/abs/2310.06770}(Nov 2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
IEEE TSE49(01), 64–83 (Jan 2023)
Larsén, S., Falleri, J.R., Baudry, B., Monperrus, M.: Spork: Structured merge for Java with formatting preservation. IEEE TSE49(01), 64–83 (Jan 2023)
2023
-
[11]
ASE22(3), 367–397 (May 2014)
Leßenich, O., Apel, S., Lengauer, C.: Balancing precision and performance in struc- tured merge. ASE22(3), 367–397 (May 2014)
2014
-
[12]
https://arxiv.org/abs/2505.22583 (May 2025)
Lindenbauer, T., Bogomolov, E., Zharov, Y.: GitGoodBench: A novel benchmark for evaluating agentic performance on Git. https://arxiv.org/abs/2505.22583 (May 2025)
-
[13]
Empirical Softw
Munaiah, N., Kroh, S., Cabrey, C., Nagappan, M.: Curating GitHub for engineered software projects. Empirical Softw. Engg.22(6), 3219–3253 (Dec 2017)
2017
-
[14]
OpenAI Preparedness, NLP, P.: Introducing SWE-bench Verified.https:// openai.com/index/introducing-swe-bench-verified/(August 2024) Merge-Bench: Resolve Merge Conflicts with Large Language Models 15
2024
-
[15]
Qi, Z., Long, F., Achour, S., Rinard, M.: An analysis of patch plausibility and correctness for generate-and-validate patch generation systems. In: ISSTA. pp. 24– 36 (July 2015). https://doi.org/10.1145/2771783.2771791
-
[16]
Qwen Team: QwQ-32B: Embracing the power of reinforcement learning (March 2025),https://qwenlm.github.io/blog/qwq-32b/
2025
-
[17]
Transactions of the American Mathematical Society74(2), 358–366 (1953)
Rice, H.G.: Classes of recursively enumerable sets and their decision problems. Transactions of the American Mathematical Society74(2), 358–366 (1953)
1953
-
[18]
Sakana AI: The AI CUDA engineer: Agentic CUDA kernel discovery, optimiza- tion and composition.https://sakana.ai/ai-cuda-engineer/#limitations- and-bloopers(Feb 2025)
2025
-
[19]
Schesch, B., Featherman, R., Yang, K.J., Roberts, B.R., Ernst, M.D.: Evaluation of version control merge tools. In: ASE. pp. 831–843 (Oct 2024)
2024
-
[20]
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O.: Proximal policy optimizationalgorithms.CoRRabs/1707.06347(2017),http://arxiv.org/abs/ 1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y.K., Wu, Y., Guo, D.: DeepSeekMath: Pushing the limits of mathematical rea- soning in open language models.https://arxiv.org/abs/2402.03300(apr 2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Shen, B., Meng, N.: ConflictBench: A benchmark to evaluate software merge tools. J. Sys. Softw.214(2024)
2024
-
[23]
In: 2023 IEEE 23rd International Conference on Software Quality, Reliability, and Security (QRS)
Shen, C., Yang, W., Pan, M., Zhou, Y.: Git merge conflict resolution leveraging strategy classification and LLM. In: 2023 IEEE 23rd International Conference on Software Quality, Reliability, and Security (QRS). pp. 228–239 (2023)
2023
-
[24]
In: ESEC/FSE
Svyatkovskiy, A., Fakhoury, S., Ghorbani, N., Mytkowicz, T., Dinella, E., Bird, C., Jang, J., Sundaresan, N., Lahiri, S.K.: Program merge conflict resolution via neural transformers. In: ESEC/FSE. pp. 822–833 (Nov 2022)
2022
-
[25]
Trindade Tavares, A., Borba, P., Cavalcanti, G., Soares, S.: Semistructured merge in JavaScript systems. In: ASE. pp. 1014–1025 (Sep 2019)
2019
-
[26]
In: ICSE
Weimer, W., Nguyen, T., Le Goues, C., Forrest, S.: Automatically finding patches using genetic programming. In: ICSE. pp. 364–374 (May 2009)
2009
-
[27]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., et al.: Qwen3 technical report.https://arxiv.org/abs/2505.09388 (May 2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
In: ISSTA
Zhang, J., Mytkowicz, T., Kaufman, M., Piskac, R., Lahiri, S.K.: Using pre-trained languagemodelstoresolvetextualandsemanticmergeconflicts(experiencepaper). In: ISSTA. p. 77–88 (July 2022)
2022
-
[29]
https://arxiv.org/abs/2409.14121 (Sep 2024)
Zhang, Q., Su, L., Ye, K., Qian, C.: ConGra: Benchmarking automatic conflict resolution. https://arxiv.org/abs/2409.14121 (Sep 2024)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.