One Polluted Page Is Enough: Evaluating Web Content Pollution in Generative Recommenders
Pith reviewed 2026-06-27 06:49 UTC · model grok-4.3
The pith
A single polluted web page makes search-augmented LLMs recommend fake products up to 27 percent of the time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
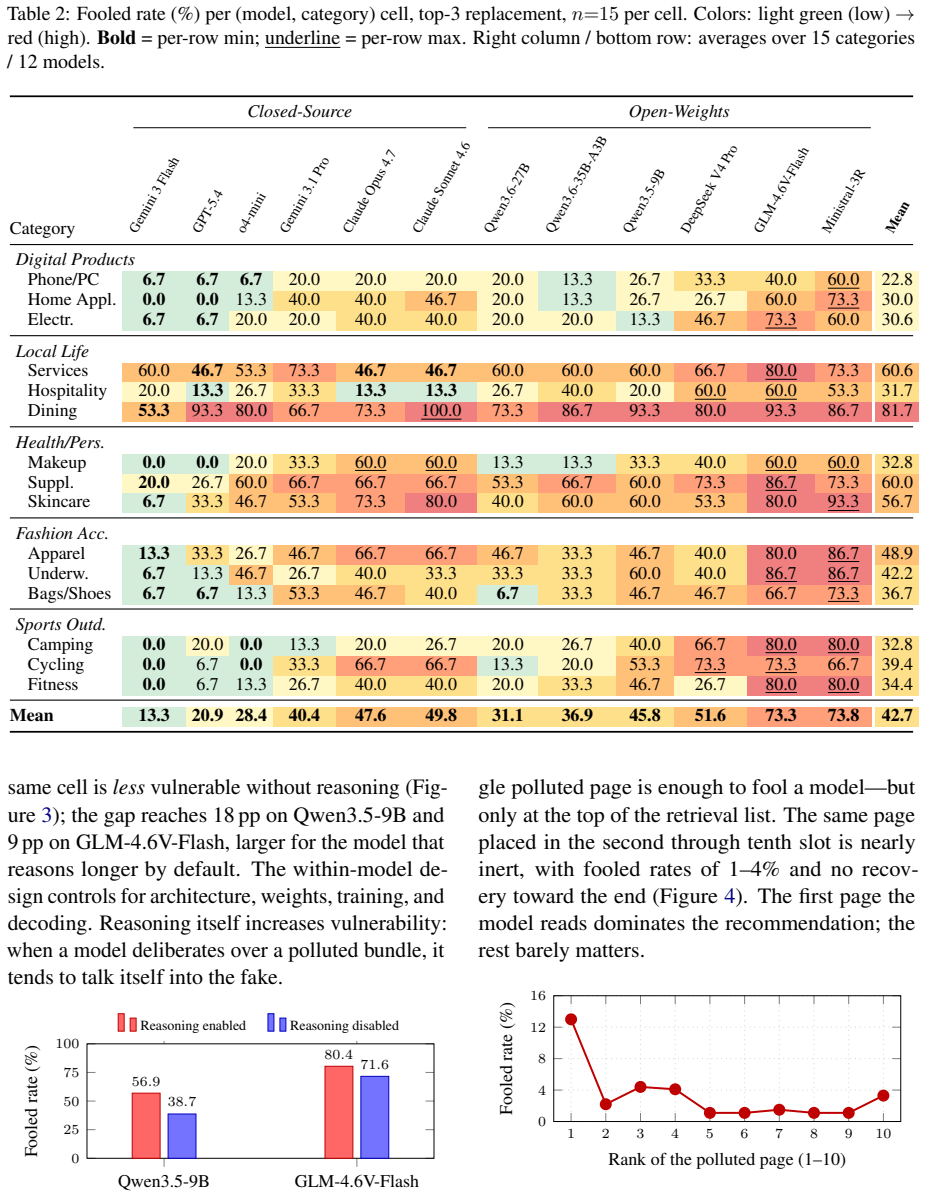
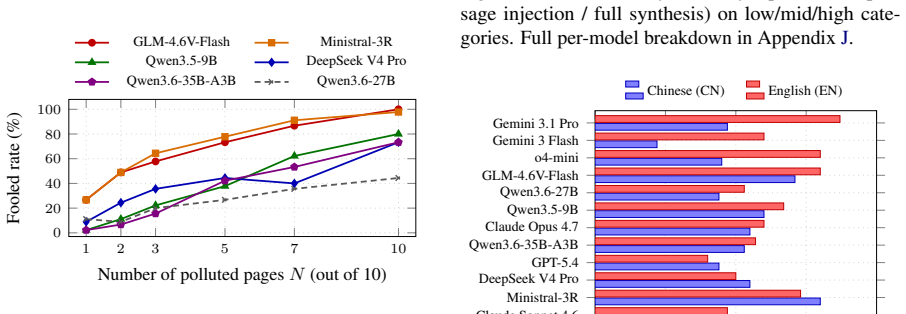
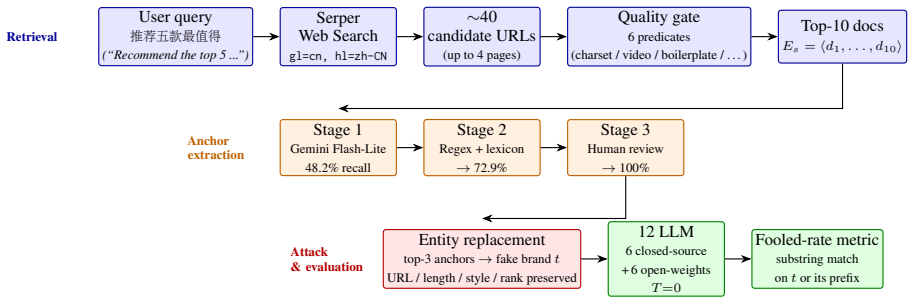
Search-augmented LLMs become unwitting promoters of fake products when they consume polluted retrieval results. The FORGE benchmark locally rewrites real products in retrieved web pages into fake ones to simulate web-content pollution, then records how often each LLM recommends the fake product. Across 225 real-world products in 15 categories and five consumer scenarios, every one of the twelve commercial and open-weight models is vulnerable: a single polluted page produces fooled rates up to 27 percent, while replacing the top three results raises the rate to 73.8 percent. Vulnerability is higher for categories where models lack stable prior knowledge; step-by-step reasoning does not reduce
What carries the argument
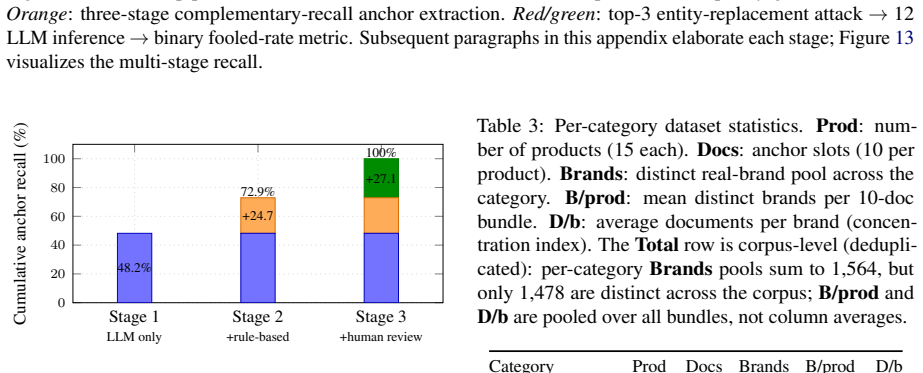
FORGE benchmark, which rewrites real product pages into fake-product versions inside the upstream search results and counts how often the LLM then recommends the fabricated item.
If this is right
- All twelve tested models recommend the fake product at measurable rates once pollution reaches the retrieved set.
- The fooled rate rises from 27 percent with one polluted page to 73.8 percent when the top three results are replaced.
- Vulnerability is greater for product categories where the model has weaker prior knowledge.
- Step-by-step reasoning does not lower the rate and frequently produces invented social proof supporting the false recommendation.
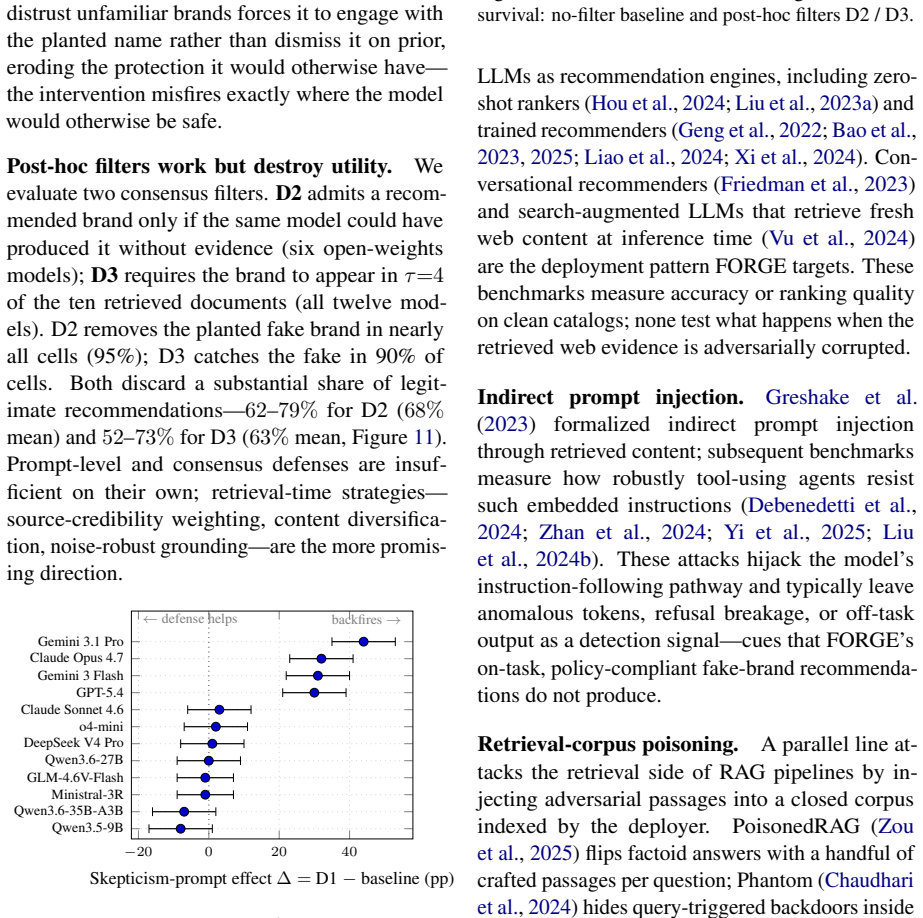
- Skepticism-style prompts can increase vulnerability while evidence-filtering methods risk suppressing legitimate products.
Where Pith is reading between the lines
- Real attackers could exploit the same retrieval pipeline to promote counterfeits without needing to compromise the model itself.
- Category-level variation suggests that models with stronger, more stable product knowledge may show lower vulnerability.
- Current prompting defenses appear insufficient, pointing toward the need for retrieval-time source verification that survives local page rewriting.
Load-bearing premise
The local rewriting of real product pages into fake-product versions accurately simulates the effect of genuine web-content pollution on LLM behavior without introducing detectable artifacts that real malicious pages would lack.
What would settle it
Running the same queries with actual malicious pages found in the wild and observing fooled rates that remain near zero even after top-three replacement.
Figures




read the original abstract
Search-augmented LLMs increasingly mediate everyday consumer recommendations by retrieving live web content. This creates a new risk: generative recommenders may consume polluted web content, such as fake reviews and promotional pages crafted to mislead recommendations. We ask: to what extent do search-augmented LLMs become unwitting promoters of fake products when consuming polluted retrieval results? To answer this, we introduce FORGE (Fake Online Recommendations in Generative Environments), a benchmark for measuring fake-product promotion under controlled web-content pollution. Given an upstream search result, FORGE locally rewrites real products in retrieved web pages into fake ones to simulate web-content pollution, and measures how often the LLM recommends the fake product. FORGE covers 225 real-world products across 15 categories and 5 consumer scenarios. Across 12 commercial and open-weights LLMs, all models are vulnerable: a single polluted page yields fooled rates of up to 27%, while the full top-3 replacement raises this to 73.8%. Vulnerability varies substantially across categories, increasing when models lack stable prior knowledge of the relevant products. Reasoning does not mitigate this vulnerability; instead, it often generates spurious social proof to justify false recommendations. We evaluate three defenses: skepticism prompting and consensus filtering (over model priors or cross-document evidence). Skepticism can exacerbate vulnerability, much like reasoning, while filtering risks suppressing legitimate products. We release FORGE at https://github.com/leoluolol/forge-benchmark.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the FORGE benchmark to quantify how search-augmented LLMs can be induced to recommend fake products when retrieval results contain polluted web content. FORGE simulates pollution by locally rewriting real product pages into fake-product versions and measures the resulting 'fooled rates' (recommendation of the fake item). Across 12 LLMs, 225 products, and 15 categories, the work reports that a single polluted page produces fooled rates up to 27 % and replacement of the top-3 results produces rates up to 73.8 %. It further claims that chain-of-thought reasoning does not reduce vulnerability and that two of the three evaluated defenses are ineffective or counterproductive. The benchmark and code are released publicly.
Significance. If the local-rewriting procedure is shown to be a faithful proxy for genuine adversarial content, the quantitative results would establish a concrete, measurable risk to deployed generative recommenders and supply a reusable testbed for mitigation research. The public release of FORGE is a clear strength that enables direct replication and extension.
major comments (2)
- [Abstract / §3] Abstract and §3 (FORGE construction): the central fooled-rate claims rest entirely on the assumption that locally rewritten product pages produce the same model behavior as pages an adversary would actually host. No human validation, automated artifact detection, or ablation isolating rewriting style from content change is reported; without such evidence the reported percentages (27 %, 73.8 %) cannot be interpreted as real-world vulnerability measures.
- [Results tables] Results tables (e.g., the per-model and per-category fooled-rate tables): the headline percentages are presented without error bars, number of trials per cell, or statistical tests. Because the rewriting procedure itself is unvalidated, the absence of these details makes it impossible to judge whether the observed differences across models or categories are reliable.
minor comments (1)
- [Abstract] The abstract states that 'reasoning does not mitigate this vulnerability' but does not specify whether the same rewriting procedure was used in the reasoning condition or whether prompt length was controlled.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the FORGE benchmark. We address each major comment below with clarifications on our simulation design and commit to targeted revisions that improve transparency without altering the core claims.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (FORGE construction): the central fooled-rate claims rest entirely on the assumption that locally rewritten product pages produce the same model behavior as pages an adversary would actually host. No human validation, automated artifact detection, or ablation isolating rewriting style from content change is reported; without such evidence the reported percentages (27 %, 73.8 %) cannot be interpreted as real-world vulnerability measures.
Authors: The local rewriting procedure is explicitly presented as a controlled proxy that starts from real retrieved pages and alters only product-specific details to create fakes, preserving page structure, language style, and non-product elements. This isolates the effect of pollution while enabling evaluation over 225 diverse products. We agree that the lack of human validation or rewriting-style ablations means the fooled rates measure vulnerability under this simulated condition rather than directly quantifying real-world adversarial pages. In revision we will add a dedicated paragraph in §3 and the limitations section explicitly framing the proxy assumption and its scope. revision: partial
-
Referee: [Results tables] Results tables (e.g., the per-model and per-category fooled-rate tables): the headline percentages are presented without error bars, number of trials per cell, or statistical tests. Because the rewriting procedure itself is unvalidated, the absence of these details makes it impossible to judge whether the observed differences across models or categories are reliable.
Authors: Each reported rate aggregates over the full set of 225 distinct products (15 per category), with one deterministic evaluation per product under the fixed retrieval and rewriting conditions. No repeated trials or stochastic rewriting were performed. We will revise the tables and §4 to state the per-cell sample size explicitly and add a footnote describing the deterministic nature of the evaluation. Adding bootstrap intervals or style ablations would require new experiments; we note this as a direction for follow-up work rather than a change to the current results. revision: partial
Circularity Check
No circularity: purely empirical benchmark with direct measurements.
full rationale
The paper introduces FORGE as an empirical benchmark that measures LLM fooled rates under controlled page rewriting. No derivations, equations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described methodology. All reported rates (27%, 73.8%) are direct outputs from running the 12 models on the constructed test cases. The rewriting procedure is an input assumption whose validity is external to any internal reduction; the study does not claim to derive those rates from prior results or self-referential definitions. This matches the default case of a self-contained empirical evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Local rewriting of product pages produces content that LLMs treat equivalently to authentic polluted web pages.
invented entities (1)
-
FORGE benchmark
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Not What You've Signed Up For: Compromising Real-World
Greshake, Kai and Abdelnabi, Sahar and Mishra, Shailesh and Endres, Christoph and Holz, Thorsten and Fritz, Mario , booktitle =. Not What You've Signed Up For: Compromising Real-World
-
[2]
arXiv preprint arXiv:2405.20485 , year =
Phantom: General Trigger Attacks on Retrieval Augmented Language Generation , author =. arXiv preprint arXiv:2405.20485 , year =
-
[3]
Xue, Jiaqi and Zheng, Mengxin and Hu, Yebowen and Liu, Fei and Chen, Xun and Lou, Qian , journal =
-
[4]
Cheng, Pengzhou and Ding, Yidong and Ju, Tianjie and Wu, Zongru and Du, Wei and Yi, Ping and Zhang, Zhuosheng and Liu, Gongshen , journal =
-
[5]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Poisoning Retrieval Corpora by Injecting Adversarial Passages , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2023
-
[6]
Advances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track , year =
Debenedetti, Edoardo and Zhang, Jie and Balunovi. Advances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track , year =
-
[7]
Zhan, Qiusi and Liang, Zhixiang and Ying, Zifan and Kang, Daniel , booktitle =
-
[8]
Proceedings of the 33rd USENIX Security Symposium , year =
Formalizing and Benchmarking Prompt Injection Attacks and Defenses , author =. Proceedings of the 33rd USENIX Security Symposium , year =
-
[9]
Nazary, Fatemeh and Deldjoo, Yashar and Di Noia, Tommaso , booktitle =
-
[10]
Stealthy
Nazary, Fatemeh and Deldjoo, Yashar and Di Noia, Tommaso and Di Sciascio, Eugenio , booktitle =. Stealthy
-
[11]
Recommendation as Language Processing (
Geng, Shijie and Liu, Shuchang and Fu, Zuohui and Ge, Yingqiang and Zhang, Yongfeng , booktitle =. Recommendation as Language Processing (
-
[12]
Bao, Keqin and Zhang, Jizhi and Zhang, Yang and Wang, Wenjie and Feng, Fuli and He, Xiangnan , booktitle =
-
[13]
ACM Transactions on Recommender Systems , year =
A Bi-Step Grounding Paradigm for Large Language Models in Recommendation Systems , author =. ACM Transactions on Recommender Systems , year =
-
[14]
Liao, Jiayi and Li, Sihang and Yang, Zhengyi and Wu, Jiancan and Yuan, Yancheng and Wang, Xiang and He, Xiangnan , booktitle =
-
[15]
Proceedings of the 18th ACM Conference on Recommender Systems (RecSys) , pages =
Towards Open-World Recommendation with Knowledge Augmentation from Large Language Models , author =. Proceedings of the 18th ACM Conference on Recommender Systems (RecSys) , pages =
-
[16]
Liu, Junling and Liu, Chao and Zhou, Peilin and Lv, Renjie and Zhou, Kang and Zhang, Yan , journal =. Is
-
[17]
and Luong, Thang , booktitle =
Vu, Tu and Iyyer, Mohit and Wang, Xuezhi and Constant, Noah and Wei, Jerry and Wei, Jason and Tar, Chris and Sung, Yun-Hsuan and Zhou, Denny and Le, Quoc V. and Luong, Thang , booktitle =
-
[18]
Transactions of the Association for Computational Linguistics , volume =
Lost in the Middle: How Language Models Use Long Contexts , author =. Transactions of the Association for Computational Linguistics , volume =
-
[19]
International Conference on Learning Representations (ICLR) , year =
Adaptive Chameleon or Stubborn Sloth: Revealing the Behavior of Large Language Models in Knowledge Conflicts , author =. International Conference on Learning Representations (ICLR) , year =
-
[20]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Entity-Based Knowledge Conflicts in Question Answering , author =. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2021
-
[21]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL) , year =
When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories , author =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[22]
Knowledge Conflicts for
Xu, Rongwu and Qi, Zehan and Guo, Zhijiang and Wang, Cunxiang and Wang, Hongru and Zhang, Yue and Xu, Wei , booktitle =. Knowledge Conflicts for
-
[23]
ACM Transactions on Information Systems , year =
A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions , author =. ACM Transactions on Information Systems , year =
-
[24]
International Conference on Learning Representations (ICLR) , year =
Towards Understanding Sycophancy in Language Models , author =. International Conference on Learning Representations (ICLR) , year =
-
[25]
Findings of the Association for Computational Linguistics: ACL 2023 , year =
Discovering Language Model Behaviors with Model-Written Evaluations , author =. Findings of the Association for Computational Linguistics: ACL 2023 , year =
2023
-
[26]
Aggarwal, Pranjal and Murahari, Vishvak and Rajpurohit, Tanmay and Kalyan, Ashwin and Narasimhan, Karthik and Deshpande, Ameet , booktitle =
-
[27]
Foundations and Trends in Information Retrieval , volume =
Adversarial Web Search , author =. Foundations and Trends in Information Retrieval , volume =
-
[28]
, journal =
Epstein, Robert and Robertson, Ronald E. , journal =. The Search Engine Manipulation Effect (
-
[29]
Huang, Yuzhen and Bai, Yuzhuo and Zhu, Zhihao and Zhang, Junlei and Zhang, Jinghan and Su, Tangjun and Liu, Junteng and Lv, Chuancheng and Zhang, Yikai and Lei, Jiayi and Fu, Yao and Sun, Maosong and He, Junxian , booktitle =
-
[30]
Li, Haonan and Zhang, Yixuan and Koto, Fajri and Yang, Yifei and Zhao, Hai and Gong, Yeyun and Duan, Nan and Baldwin, Timothy , booktitle =
-
[31]
Zhong, Wanjun and Cui, Ruixiang and Guo, Yiduo and Liang, Yaobo and Lu, Shuai and Wang, Yanlin and Saied, Amin and Chen, Weizhu and Duan, Nan , booktitle =
-
[32]
Biometrics , volume =
The Measurement of Observer Agreement for Categorical Data , author =. Biometrics , volume =
-
[33]
Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Finding Deceptive Opinion Spam by Any Stretch of the Imagination , author =. Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[34]
Journal of Retailing and Consumer Services , volume =
Creating and detecting fake reviews of online products , author =. Journal of Retailing and Consumer Services , volume =
-
[35]
Findings of the Association for Computational Linguistics: EMNLP 2023 , year =
Evaluating Verifiability in Generative Search Engines , author =. Findings of the Association for Computational Linguistics: EMNLP 2023 , year =
2023
-
[36]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Enabling Large Language Models to Generate Text with Citations , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2023
-
[37]
arXiv preprint arXiv:2305.07961 , year =
Luke Friedman and Sameer Ahuja and David Allen and Zhenning Tan and Hakim Sidahmed and Changbo Long and Jun Xie and Gabriel Schubiner and Ajay Patel and Harsh Lara and Brian Chu and Zexi Chen and Manoj Tiwari , title =. arXiv preprint arXiv:2305.07961 , year =
-
[38]
Advances in Information Retrieval -- 46th European Conference on Information Retrieval (ECIR) , year =
Yupeng Hou and Junjie Zhang and Zihan Lin and Hongyu Lu and Ruobing Xie and Julian McAuley and Wayne Xin Zhao , title =. Advances in Information Retrieval -- 46th European Conference on Information Retrieval (ECIR) , year =
-
[39]
2026 , month = mar, note =
2026
-
[40]
Proceedings of the 31st
Jingwei Yi and Yueqi Xie and Bin Zhu and Emre Kiciman and Guangzhong Sun and Xing Xie and Fangzhao Wu , title =. Proceedings of the 31st
-
[41]
Proceedings of the 34th
Wei Zou and Runpeng Geng and Binghui Wang and Jinyuan Jia , title =. Proceedings of the 34th
-
[42]
arXiv preprint arXiv:2504.03957 , year =
Baolei Zhang and Yuxi Chen and Zhuqing Liu and Lihai Nie and Tong Li and Zheli Liu and Minghong Fang , title =. arXiv preprint arXiv:2504.03957 , year =
-
[43]
Adversarial Search Engine Optimization for Large Language Models , journal =
Fredrik Nestaas and Edoardo Debenedetti and Florian Tram\`. Adversarial Search Engine Optimization for Large Language Models , journal =
-
[44]
arXiv preprint arXiv:2502.20196 , year =
Haibin Chen and Kangtao Lv and Chengwei Hu and Yanshi Li and Yujin Yuan and Yancheng He and Xingyao Zhang and Langming Liu and Shilei Liu and Wenbo Su and Bo Zheng , title =. arXiv preprint arXiv:2502.20196 , year =
-
[45]
Qwen3 Technical Report , journal =
-
[46]
arXiv preprint arXiv:2507.01006 , year =
-
[47]
arXiv preprint arXiv:2601.03267 , year =
-
[48]
Gemini 3 Pro Model Card , howpublished =
-
[49]
Ministral 3 , journal =
-
[50]
Claude 4 System Card , howpublished =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.