Neural Architecture Search of Sample Reweighting Networks for Complex Distribution Shift
Pith reviewed 2026-06-26 08:47 UTC · model grok-4.3
The pith
Neural architecture search optimizes Meta-Weight-Net to handle simultaneous label noise and class imbalance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Meta-Weight-Net (MW-Net) is a promising sample reweighting network that computes weights based on classification loss. Although MW-Net improves prediction performance under a single type of distribution shift using a simple neural network, its performance degrades when facing both label noise and class imbalance, where it is hard to determine appropriate weights solely from classification loss and using a simple network. In this study, we introduce neural architecture search to MW-Net to mitigate such performance degradation. Using the tree-structured Parzen estimator, we explore the optimal number of hidden layers and nodes and select the most suitable intermediate layer in the classificati
What carries the argument
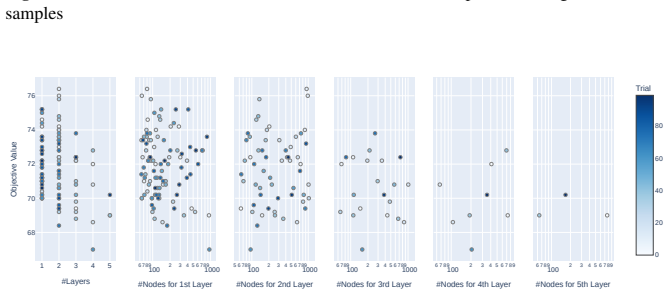
Tree-structured Parzen estimator search over MW-Net architecture, varying hidden layer count, node counts, and selection of an intermediate classifier layer as input to the reweighting network.
If this is right
- MW-Net can compute weights that better reflect the combined influence of label noise and class imbalance.
- Prediction accuracy rises on image classification tasks that contain both types of distribution shift at once.
- Sample reweighting networks no longer require manual architecture design when multiple shifts are present.
- Standard hyperparameter optimization routines become sufficient to adapt reweighting components for complex shifts.
Where Pith is reading between the lines
- The same search procedure could be applied to other meta-learning modules used in robustness methods beyond reweighting.
- Testing the discovered architectures on datasets with different noise rates or imbalance ratios would check whether the gains generalize.
- Replacing the base classifier with deeper models or different loss functions might interact with the searched MW-Net structure in useful ways.
- The approach raises the question of whether explicit modeling of multiple shift types inside the search objective would further improve results.
Load-bearing premise
The chosen search space of layer counts, node counts, and input layer choices is large enough to discover weight functions that correctly separate the effects of label noise from those of class imbalance.
What would settle it
If the TPE-searched MW-Net architectures produce no higher test accuracy than the original fixed MW-Net on the modified CIFAR-10 or CIFAR-100 datasets containing both label noise and class imbalance, the claim of effectiveness would be refuted.
Figures
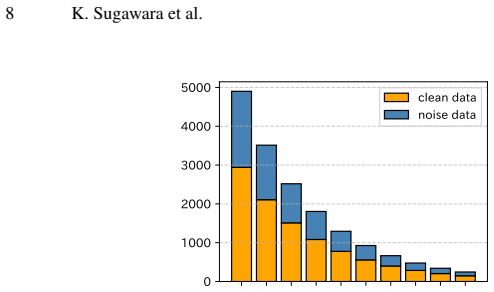
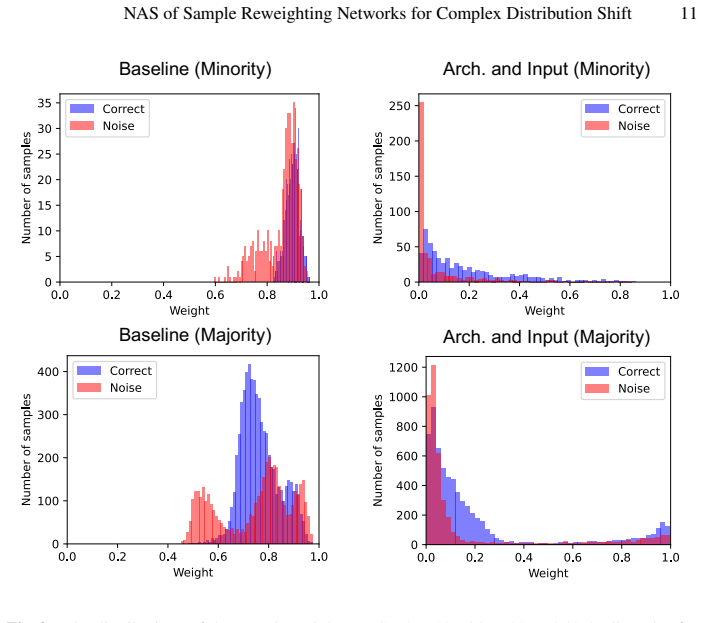
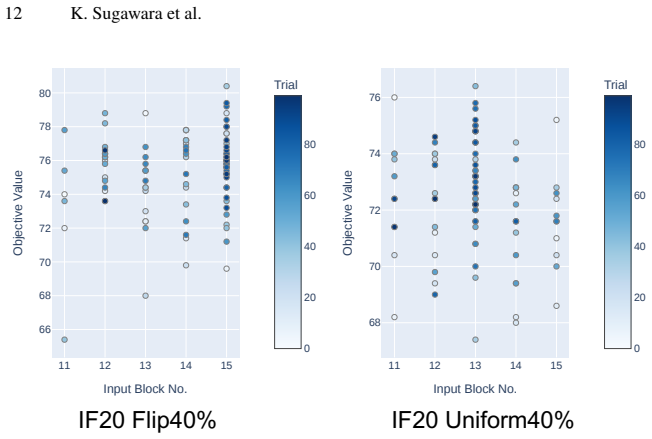
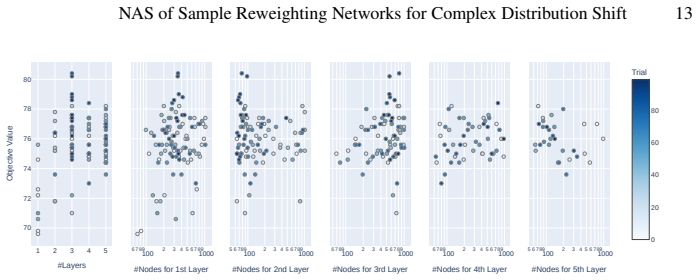
read the original abstract
Sample reweighting is a major approach to addressing distribution shifts, such as label noise and class imbalance. Meta-Weight-Net (MW-Net) is a promising sample reweighting network that computes weights based on classification loss. Although MW-Net improves prediction performance under a single type of distribution shift using a simple neural network, its performance degrades when facing both label noise and class imbalance, where it is hard to determine appropriate weights solely from classification loss and using a simple network. In this study, we introduce neural architecture search to MW-Net to mitigate such performance degradation. Using the tree-structured Parzen estimator, we explore the optimal number of hidden layers and nodes and select the most suitable intermediate layer in the classification model to serve as the input for MW-Net. Experimental results on the CIFAR-10 and CIFAR-100 datasets that were modified to include both label noise and class imbalance demonstrate the effectiveness of neural architecture search for MW-Net.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that applying neural architecture search (NAS) via the tree-structured Parzen estimator (TPE) to Meta-Weight-Net (MW-Net) improves sample reweighting performance under simultaneous label noise and class imbalance. The search varies the number of hidden layers and nodes in MW-Net plus the choice of which intermediate layer from the classifier is used as input; experiments on CIFAR-10 and CIFAR-100 modified with both shifts are said to demonstrate effectiveness where plain MW-Net degrades.
Significance. If the experimental claims hold after addressing the search-space limitation, the work would indicate that modest NAS can mitigate the ambiguity of loss-based reweighting when multiple distribution shifts are present simultaneously. No machine-checked proofs, reproducible code artifacts, or parameter-free derivations are described.
major comments (2)
- The central claim rests on the assertion that NAS discovers weight functions capable of handling combined shifts where loss alone is ambiguous. However, the search space is restricted to hidden-layer count/width and input-layer selection with the same meta-loss objective on classification error; no analysis shows that any architecture inside this space can factor the two shifts rather than memorize their joint signature on the modified splits. This is load-bearing because performance gains could be explained by capacity alone.
- Abstract and experimental description: no quantitative results, baselines, statistical significance tests, or construction details for the modified CIFAR datasets are supplied, preventing verification that the reported gains exceed what a higher-capacity MW-Net would achieve without NAS.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We address each major comment below and will revise the manuscript to strengthen the experimental claims and clarify limitations of the search space.
read point-by-point responses
-
Referee: The central claim rests on the assertion that NAS discovers weight functions capable of handling combined shifts where loss alone is ambiguous. However, the search space is restricted to hidden-layer count/width and input-layer selection with the same meta-loss objective on classification error; no analysis shows that any architecture inside this space can factor the two shifts rather than memorize their joint signature on the modified splits. This is load-bearing because performance gains could be explained by capacity alone.
Authors: We agree that the search space is limited to layer count, width, and input-layer choice, and that the manuscript provides no theoretical analysis or ablation demonstrating that discovered architectures factor the two shifts rather than exploit their joint signature. The reported gains are empirical comparisons against the original MW-Net; capacity alone remains a plausible alternative explanation. In revision we will add controlled experiments that fix the MW-Net architecture to the largest searched size and compare against the NAS-selected variant, plus a short discussion of this limitation. revision: partial
-
Referee: Abstract and experimental description: no quantitative results, baselines, statistical significance tests, or construction details for the modified CIFAR datasets are supplied, preventing verification that the reported gains exceed what a higher-capacity MW-Net would achieve without NAS.
Authors: The abstract is intentionally concise, but the referee is correct that the experimental section must supply the missing quantitative details. The full manuscript contains tables comparing against MW-Net and other baselines on the modified CIFAR-10/100, yet it lacks explicit dataset-construction pseudocode, standard-error bars, and significance tests. We will expand the experimental section with these elements and a dedicated paragraph describing how label noise and class imbalance were jointly injected. revision: yes
Circularity Check
No circularity; empirical NAS results stand on experimental comparison
full rationale
The paper describes an application of TPE-based neural architecture search over MW-Net hyperparameters (hidden layer count/width and input layer selection) whose objective is the standard meta-loss on classification error. The central claim is supported solely by performance numbers on modified CIFAR-10/100 splits containing simultaneous label noise and class imbalance; no equations, fitted parameters, or self-citations are presented as load-bearing derivations. The search procedure and evaluation protocol are independent of the target performance metric and do not reduce to re-labeling of inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Akiba, T., Sano, S., Yanase, T., Ohta, T., Koyama, M.: Optuna: A next-generation hy- perparameter optimization framework. In: Proceedings of the 25th ACM SIGKDD Inter- national Conference on Knowledge Discovery & Data Mining. pp. 2623–2631 (2019). https://doi.org/10.1145/3292500.3330701
-
[2]
In: International Conference on Machine Learning (ICML)
Akimoto, Y ., Shirakawa, S., Yoshinari, N., Uchida, K., Saito, S., Nishida, K.: Adaptive stochastic natural gradient method for one-shot neural architecture search. In: International Conference on Machine Learning (ICML). pp. 171–180 (2019)
2019
-
[3]
Advances in Neural Information Processing Systems24(2011)
Bergstra, J., Bardenet, R., Bengio, Y ., Kégl, B.: Algorithms for hyper-parameter optimiza- tion. Advances in Neural Information Processing Systems24(2011)
2011
-
[4]
IEEE Transactions on Knowledge and Data Engineering21(9), 1263–1284 (2009)
He, H., Garcia, E.A.: Learning from imbalanced data. IEEE Transactions on Knowledge and Data Engineering21(9), 1263–1284 (2009)
2009
-
[5]
In: Pro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Pro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 770–778 (2016) NAS of Sample Reweighting Networks for Complex Distribution Shift 15
2016
-
[6]
Master’s thesis, University of Toronto, Toronto, ON, Canada (2009)
Krizhevsky, A.: Learning Multiple Layers of Features from Tiny Images. Master’s thesis, University of Toronto, Toronto, ON, Canada (2009)
2009
-
[7]
Advances in Neural Information Processing Systems23(2010)
Kumar, M., Packer, B., Koller, D.: Self-paced learning for latent variable models. Advances in Neural Information Processing Systems23(2010)
2010
-
[8]
Li, J., Zhang, M., Xu, K., Dickerson, J., Ba, J.: How does a neural network’s architecture im- pact its robustness to noisy labels? In: Advances in Neural Information Processing Systems. vol. 34, pp. 9788–9803 (2021)
2021
-
[9]
In: Advances in Neural Information Processing Systems
Li, X., Wang, W., Wu, L., Chen, S., Hu, X., Li, J., Tang, J., Yang, J.: Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. In: Advances in Neural Information Processing Systems. vol. 33, pp. 21002–21012 (2020)
2020
-
[10]
Lin, T.Y ., Goyal, P., Girshick, R., He, K., Dollár, P.: Focal loss for dense object detection. IEEE Transactions on Pattern Analysis and Machine Intelligence42(2), 318–327 (2020). https://doi.org/10.1109/TPAMI.2018.2858826
-
[11]
In: International Conference on Learning Representations (ICLR) (2019)
Liu, H., Simonyan, K., Yang, Y .: DARTS: Differentiable architecture search. In: International Conference on Learning Representations (ICLR) (2019)
2019
-
[12]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Lu, Y ., Zhang, Y ., Han, B., Cheung, Y ., Wang, H.: Label-noise learning with intrinsically long-tailed data. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 1369–1378 (2023)
2023
-
[13]
Advances in Neural Information Processing Systems33, 15288–15299 (2020)
Mukhoti, J., Kulharia, V ., Sanyal, A., Golodetz, S., Torr, P., Dokania, P.: Calibrating deep neural networks using focal loss. Advances in Neural Information Processing Systems33, 15288–15299 (2020)
2020
-
[14]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Real, E., Aggarwal, A., Huang, Y ., Le, Q.V .: Regularized evolution for image classifier ar- chitecture search. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 33, pp. 4780–4789 (2019)
2019
-
[15]
Advances in Neural Information Processing Systems 32(2019)
Shu, J., Xie, Q., Yi, L., Zhao, Q., Zhou, S., Xu, Z., Meng, D.: Meta-Weight-Net: Learning an explicit mapping for sample weighting. Advances in Neural Information Processing Systems 32(2019)
2019
-
[16]
IEEE Transactions on Pattern Analysis and Machine In- telligence45(10), 11521–11539 (2023)
Shu, J., Yuan, X., Meng, D., Xu, Z.: CMW-Net: Learning a class-aware sample weighting mapping for robust deep learning. IEEE Transactions on Pattern Analysis and Machine In- telligence45(10), 11521–11539 (2023)
2023
-
[17]
In: 2022 IEEE/CVF Winter Conference on Appli- cations of Computer Vision (W ACV)
Simon, C., Koniusz, P., Petersson, L., Han, Y ., Harandi, M.: Towards a robust differentiable architecture search under label noise. In: 2022 IEEE/CVF Winter Conference on Appli- cations of Computer Vision (W ACV). pp. 3584–3594 (2022).https://doi.org/10. 1109/WACV51458.2022.00364
arXiv 2022
-
[18]
In: Proceedings of the Genetic and Evolution- ary Computation Conference (GECCO)
Suganuma, M., Shirakawa, S., Nagao, T.: A genetic programming approach to designing convolutional neural network architectures. In: Proceedings of the Genetic and Evolution- ary Computation Conference (GECCO). pp. 497–504 (2017).https://doi.org/10. 1145/3071178.3071229
arXiv 2017
-
[19]
In: International Conference on Machine Learning (ICML)
Tao, L., Dong, M., Xu, C.: Dual focal loss for calibration. In: International Conference on Machine Learning (ICML). pp. 33833–33849 (2023)
2023
-
[20]
arXiv preprint arXiv:2109.08580 (2021)
Timofeev, A., Chrysos, G.G., Cevher, V .: Self-supervised neural architecture search for im- balanced datasets. arXiv preprint arXiv:2109.08580 (2021)
arXiv 2021
-
[21]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Xiao, T., Xia, T., Yang, Y ., Huang, C., Wang, X.: Learning from massive noisy labeled data for image classification. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 2691–2699 (2015)
2015
-
[22]
arXiv preprint arXiv:2406.16972 (2024)
Yao, Z.: An efficient NAS-based approach for handling imbalanced datasets. arXiv preprint arXiv:2406.16972 (2024)
arXiv 2024
-
[23]
Advances in Neural Information Processing Systems31(2018) 16 K
Zhang, Z., Sabuncu, M.: Generalized cross entropy loss for training deep neural networks with noisy labels. Advances in Neural Information Processing Systems31(2018) 16 K. Sugawara et al
2018
-
[24]
arXiv preprint arXiv:2212.11542 (2022)
Zhong, X., Wang, G., Liu, W., Wu, Z., Deng, Y .: Mask focal loss: A unifying frame- work for dense crowd counting with canonical object detection networks. arXiv preprint arXiv:2212.11542 (2022)
arXiv 2022
-
[25]
In: Interna- tional Conference on Learning Representations (2017),https://openreview.net/ forum?id=r1Ue8Hcxg
Zoph, B., Le, Q.: Neural architecture search with reinforcement learning. In: Interna- tional Conference on Learning Representations (2017),https://openreview.net/ forum?id=r1Ue8Hcxg
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.