Recency/Frequency Adaptive KV Caching for Large Language Model Serving
Pith reviewed 2026-06-26 13:22 UTC · model grok-4.3
The pith
Dynamically allocating KV cache space between recent and frequent blocks improves hit rates and reduces latency in LLM serving.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
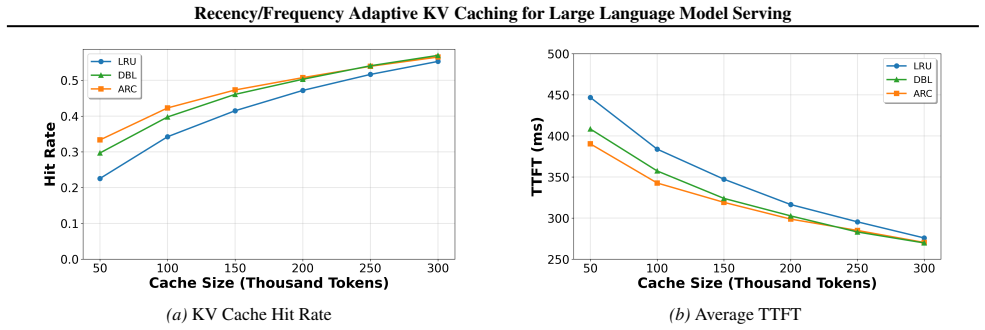
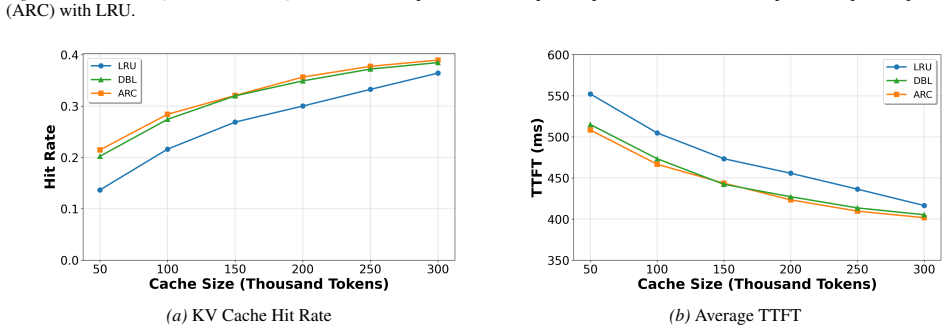
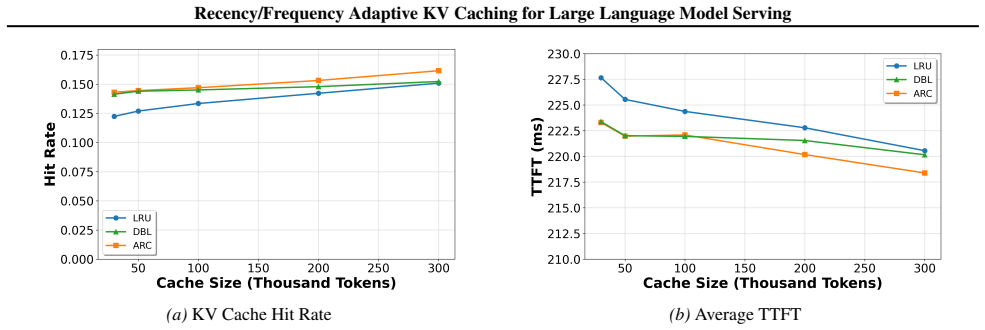
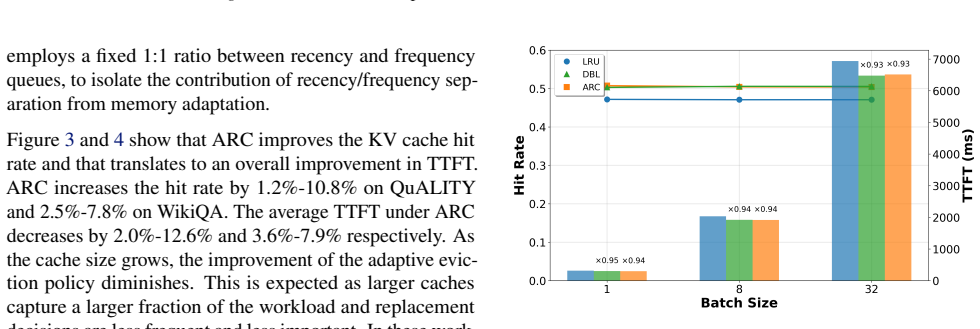
We integrate adaptive caching that dynamically allocates cache space between recently and frequently occurring KV blocks. Evaluations show that it improves the KV cache hit rate by up to 10.8% and reduces time to first token by up to 12.6% over naive vLLM on synthetic document question answering workloads, and 2.1% and 2.0% respectively on real-world conversation workloads. The method generalizes well to batch inference and demonstrates clear interpretability while effectively accommodating diverse workloads.
What carries the argument
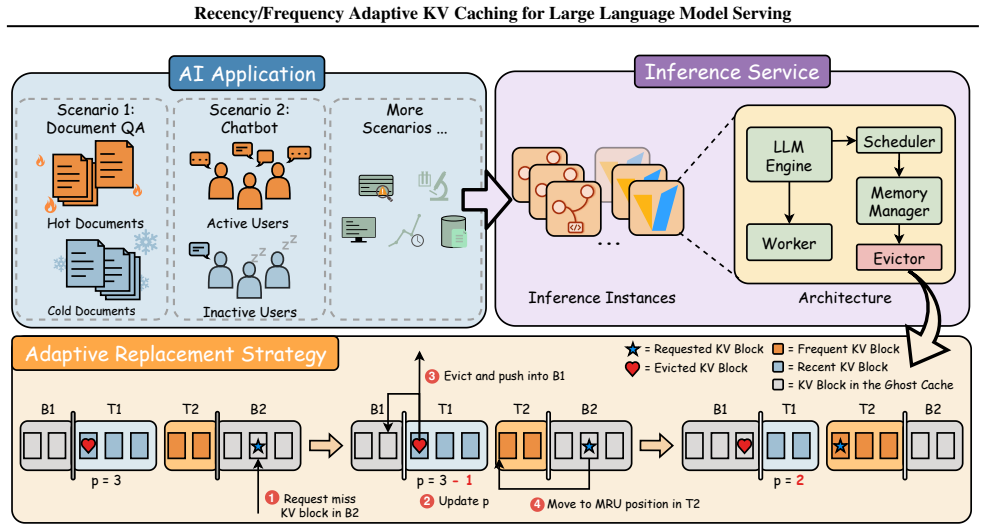
The recency/frequency adaptive allocation mechanism that dynamically balances cache space between recent and frequent KV blocks.
If this is right
- KV cache hit rates rise by as much as 10.8 percent on synthetic document question answering workloads.
- Time to first token falls by as much as 12.6 percent on the same synthetic workloads.
- Real-world conversation workloads see smaller gains of 2.1 percent hit rate and 2.0 percent time to first token.
- The policy works without conflict when requests are processed in batches.
- Cache decisions remain interpretable across varying workload mixes.
Where Pith is reading between the lines
- The same balancing idea could lower the total memory needed to serve many simultaneous users.
- Comparable recency-frequency rules might help other shared caches in distributed computing.
- Running the method on models larger than those tested would show whether the gains hold at scale.
Load-bearing premise
The overhead of tracking frequency and recency and making allocation decisions stays low enough that the extra work does not erase the gains from higher hit rates.
What would settle it
A workload where the added tracking and decision steps raise total latency even though the hit rate improves.
Figures

read the original abstract
Key-value (KV) caching is a powerful technique for accelerating large language model inference and generation. Inference workloads are large and diverse, which makes them difficult to cache effectively. Existing cache management strategies adopt the least-recently-used policy for evicting cache blocks. However, LRU leads to multiple unrelated workloads flushing each other's caches. To address this, we integrate adaptive caching that dynamically allocates cache space between recently and frequently occurring KV blocks. Evaluations show that it improves the KV cache hit rate by up to 10.8% and reduces time to first token by up to 12.6% over naive vLLM on synthetic document question answering workloads, and 2.1% and 2.0% respectively on real-world conversation workloads. The method generalizes well to batch inference and demonstrates clear interpretability while effectively accommodating diverse workloads.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a recency/frequency adaptive KV caching method for LLM serving that dynamically allocates cache space between recently and frequently occurring KV blocks to mitigate cache interference from LRU under diverse workloads. It claims empirical improvements over naive vLLM of up to 10.8% in KV cache hit rate and 12.6% in time-to-first-token on synthetic document QA workloads, with 2.1% and 2.0% gains respectively on real-world conversation workloads, plus generalization to batch inference and interpretability.
Significance. If the adaptive allocator's overhead proves negligible, the approach could improve serving efficiency for mixed inference workloads by better balancing recency and frequency signals. The dual synthetic/real-world evaluation and emphasis on interpretability are strengths that would support practical relevance in distributed LLM systems if the net gains hold after overhead accounting.
major comments (1)
- [Evaluation] Evaluation section: the reported TTFT reductions (up to 12.6% synthetic, 2.0% real-world) are presented without any quantification or measurement of the overhead from frequency counter maintenance, reallocation decisions, or data-structure costs in the adaptive allocator. This is load-bearing for the central claim, as unaccounted costs could erase the modest real-world margins.
minor comments (1)
- [Abstract] Abstract: the description of the adaptive allocation mechanism is high-level only and provides no pseudocode, parameter definitions, or pseudocode for the balance factor, hindering immediate assessment of implementation complexity.
Simulated Author's Rebuttal
We thank the referee for identifying the need to quantify allocator overhead, which is essential for validating the net performance gains. We will revise the evaluation section accordingly.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the reported TTFT reductions (up to 12.6% synthetic, 2.0% real-world) are presented without any quantification or measurement of the overhead from frequency counter maintenance, reallocation decisions, or data-structure costs in the adaptive allocator. This is load-bearing for the central claim, as unaccounted costs could erase the modest real-world margins.
Authors: We agree that the manuscript should quantify these costs. The current evaluation reports only end-to-end TTFT and hit-rate improvements without isolating the allocator's overhead. In the revised manuscript we will add micro-benchmark results measuring (1) CPU cycles and wall-clock time for frequency-counter updates, (2) latency of the reallocation decision logic, and (3) memory and cache-miss overhead of the additional data structures, both in isolation and as a fraction of total TTFT. These measurements will be reported for the same synthetic and real-world workloads used in the original experiments. revision: yes
Circularity Check
No circularity: empirical method with external baseline comparison
full rationale
The paper describes an engineering technique for adaptive recency/frequency KV cache allocation and reports measured improvements (hit rate up to 10.8%, TTFT up to 12.6%) against the external vLLM baseline on both synthetic and real workloads. No derivation chain, equations, fitted parameters renamed as predictions, or self-citation load-bearing steps appear in the provided text. The central claims rest on observable runtime metrics that can be independently reproduced or falsified, satisfying the self-contained criterion with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- allocation balance factor
axioms (1)
- domain assumption LRU is the baseline eviction policy that can be improved by frequency consideration
Reference graph
Works this paper leans on
-
[1]
Locality- aware Fair Scheduling in LLM Serving.arXiv preprint arXiv:2501.14312,
Cao, S., Wang, Y ., Mao, Z., Hsu, P.-L., Yin, L., Xia, T., Li, D., Liu, S., Zhang, Y ., Zhou, Y ., et al. Locality- aware Fair Scheduling in LLM Serving.arXiv preprint arXiv:2501.14312,
-
[2]
E., et al
Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y ., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y ., Gonzalez, J. E., et al. Vicuna: An open-source chatbot impressing GPT-4 with 90%* ChatGPT quality.See https://vicuna. lmsys. org (accessed 14 April 2023), 2(3):6,
2023
-
[3]
Feng, Y ., Lv, J., Cao, Y ., Xie, X., and Zhou, S. K. Ada- KV: Optimizing KV cache eviction by adaptive budget allocation for efficient LLM inference.arXiv preprint arXiv:2407.11550,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Evidential fuzzy rule-based machine learning to quantify classification uncertainty,
URL https://doi.org/10.36227/techrxiv. 176046306.66521015/v1. Jin, C., Zhang, Z., Jiang, X., Liu, F., Liu, S., Liu, X., and Jin, X. Ragcache: Efficient knowledge caching for retrieval- augmented generation.ACM Transactions on Computer Systems, 44(1):1–27,
-
[5]
Lmcache: An efficient kv cache layer for enterprise-scale llm inference,
Liu, Y ., Cheng, Y ., Yao, J., An, Y ., Chen, X., Feng, S., Huang, Y ., Shen, S., Zhang, R., Du, K., et al. Lmcache: An efficient KV cache layer for enterprise-scale LLM inference.arXiv preprint arXiv:2510.09665,
-
[6]
Marconi: Prefix caching for the era of hybrid LLMs.arXiv preprint arXiv:2411.19379,
Pan, R., Wang, Z., Jia, Z., Karakus, C., Zancato, L., Dao, T., Wang, Y ., and Netravali, R. Marconi: Prefix caching for the era of hybrid LLMs.arXiv preprint arXiv:2411.19379,
-
[7]
Y ., Parrish, A., Joshi, N., Nangia, N., Phang, J., Chen, A., Padmakumar, V ., Ma, J., Thompson, J., He, H., et al
Pang, R. Y ., Parrish, A., Joshi, N., Nangia, N., Phang, J., Chen, A., Padmakumar, V ., Ma, J., Thompson, J., He, H., et al. Quality: Question answering with long input texts, yes! InProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 5336– 5358,
2022
-
[8]
Preble: Efficient distributed prompt scheduling for LLM serving.arXiv preprint arXiv:2407.00023,
Srivatsa, V ., He, Z., Abhyankar, R., Li, D., and Zhang, Y . Preble: Efficient distributed prompt scheduling for LLM serving.arXiv preprint arXiv:2407.00023,
-
[9]
Effi- cient large language models: A survey.arXiv preprint arXiv:2312.03863,
Wan, Z., Wang, X., Liu, C., Alam, S., Zheng, Y ., Liu, J., Qu, Z., Yan, S., Zhu, Y ., Zhang, Q., et al. Effi- cient large language models: A survey.arXiv preprint arXiv:2312.03863,
-
[10]
7 Recency/Frequency Adaptive KV Caching for Large Language Model Serving Wang, J., Han, J., Wei, X., Shen, S., Zhang, D., Fang, C., Chen, R., Yu, W., and Chen, H. KVCache cache in the wild: Characterizing and optimizing KVCache cache at a large cloud provider.arXiv preprint arXiv:2506.02634, 2025a. Wang, Y ., Chen, Y ., Li, Z., Kang, X., Fang, Y ., Zhou, ...
-
[11]
FlashInfer: Efficient and Customizable Attention Engine for LLM Inference Serving
Ye, Z., Chen, L., Lai, R., Lin, W., Zhang, Y ., Wang, S., Chen, T., Kasikci, B., Grover, V ., Krishnamurthy, A., et al. Flash- infer: Efficient and customizable attention engine for LLM inference serving.arXiv preprint arXiv:2501.01005,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Taming the titans: A survey of efficient LLM inference serving.arXiv preprint arXiv:2504.19720,
Zhen, R., Li, J., Ji, Y ., Yang, Z., Liu, T., Xia, Q., Duan, X., Wang, Z., Huai, B., and Zhang, M. Taming the titans: A survey of efficient LLM inference serving.arXiv preprint arXiv:2504.19720,
-
[13]
A Survey on Efficient Inference for Large Language Models
Zhou, Z., Ning, X., Hong, K., Fu, T., Xu, J., Li, S., Lou, Y ., Wang, L., Yuan, Z., Li, X., et al. A survey on effi- cient inference for large language models.arXiv preprint arXiv:2404.14294,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.