Coachable agents for interactive gameplay
Pith reviewed 2026-07-02 12:49 UTC · model grok-4.3
The pith
Combining universal value function approximators with targeted training allows agents to adopt user-chosen styles in complex games at runtime while completing core tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
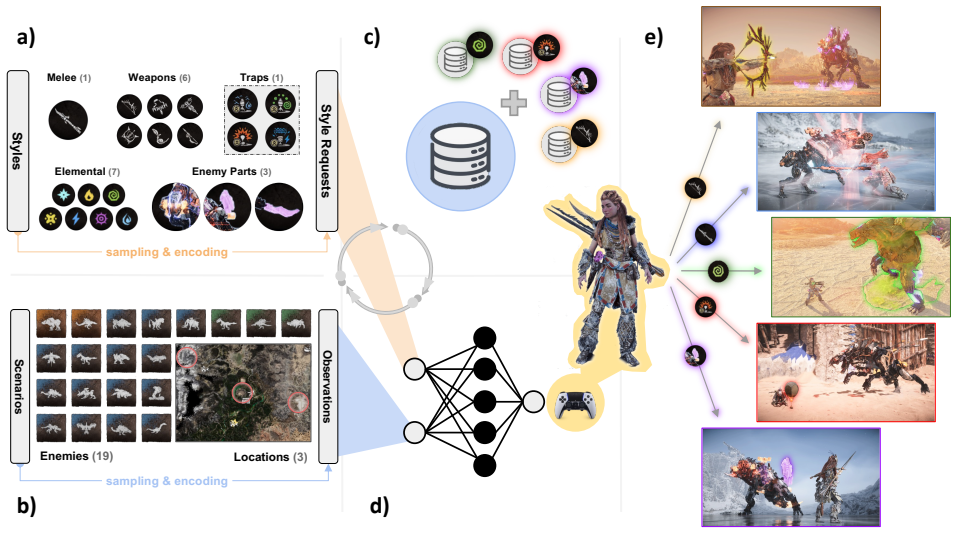
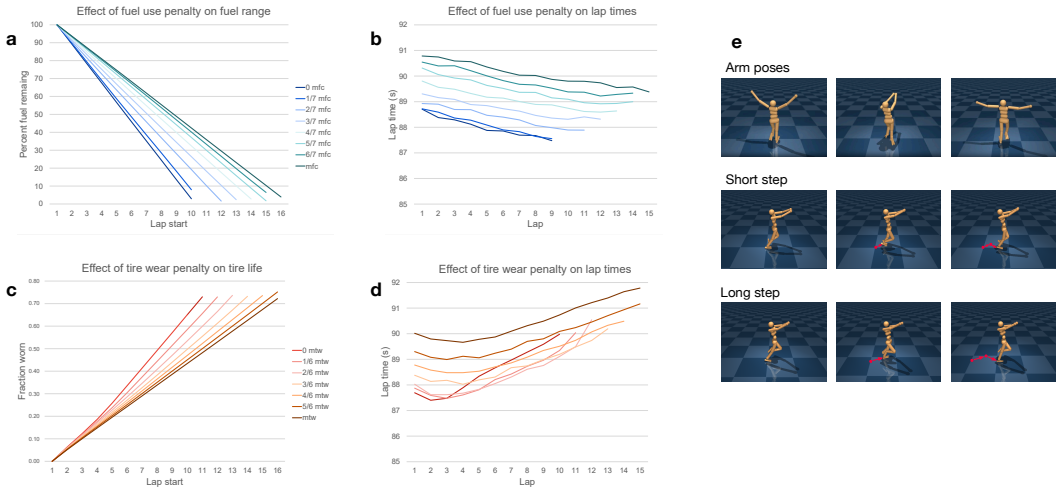
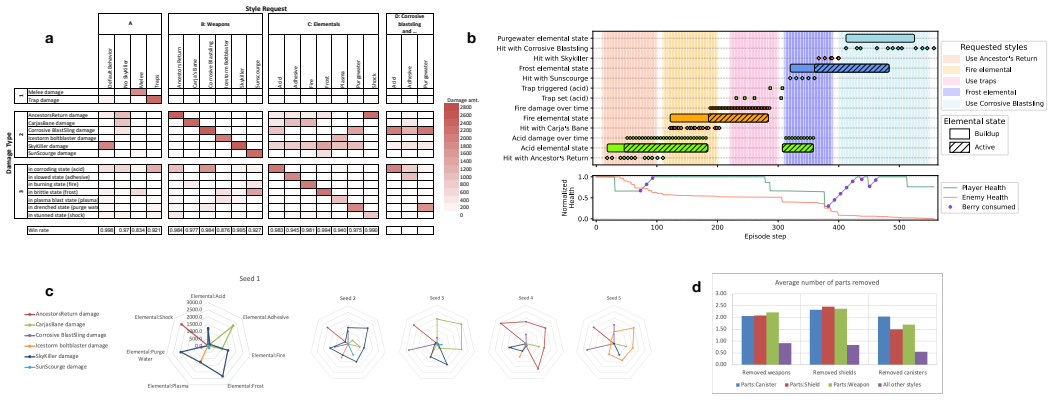
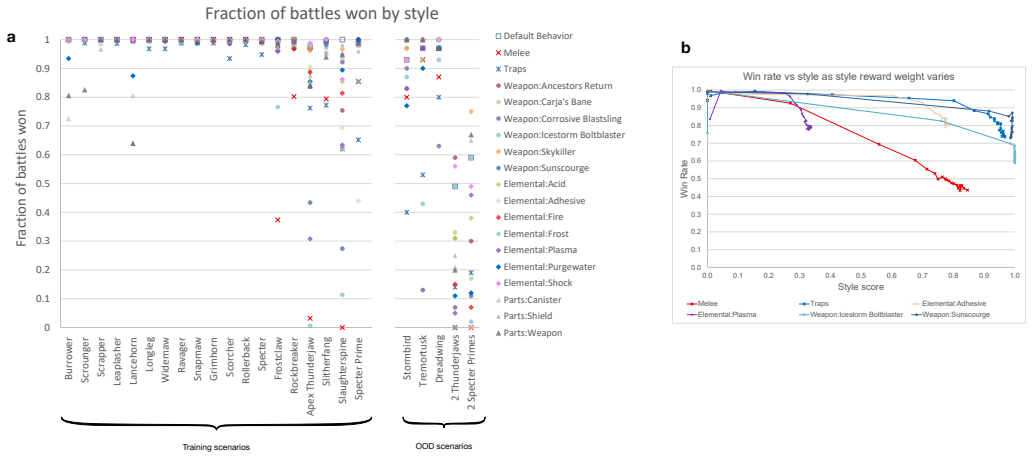
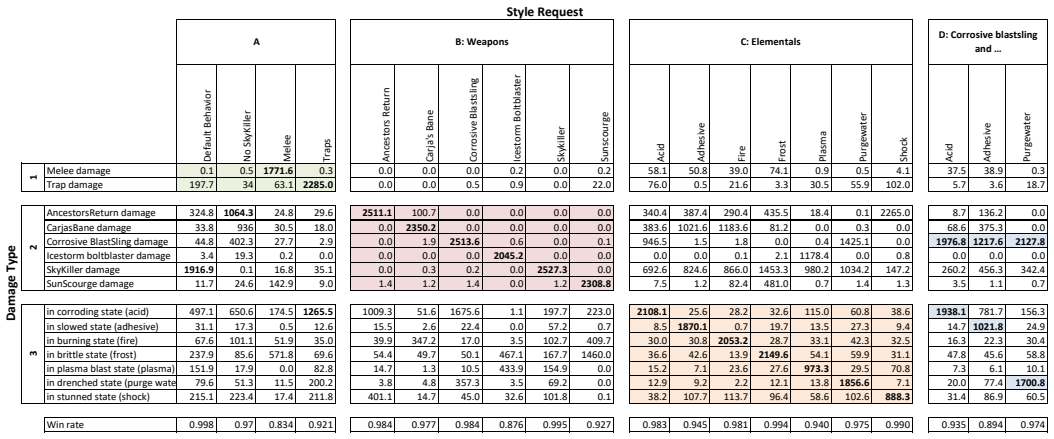
The framework uses universal value function approximators together with carefully selected training scenarios, learning algorithms, and data augmentation to train agents that can exhibit requested styles in domains such as Horizon Forbidden West, Gran Turismo, and humanoid walking. Each resulting agent maintains coherence with the style instructions while still achieving the main task goals. This setup permits an end user to select the desired behavior in real time.
What carries the argument
Universal value function approximators (UVFAs) extended through style-specific training scenarios and data augmentation, enabling a single approximator to represent multiple styles for runtime selection.
If this is right
- End users gain real-time control over agent behavior in gameplay.
- The method works across disparate domains without per-style redesign.
- Core task performance remains intact alongside style adherence.
- Flexible coaching applies to AAA games and test environments alike.
Where Pith is reading between the lines
- This approach might allow similar style control in non-game RL applications such as robotic manipulation.
- Further work could explore whether the encoding supports continuous style parameters rather than discrete requests.
- Integration with user interfaces for style specification could enhance interactivity in deployed systems.
Load-bearing premise
Carefully chosen training scenarios, algorithms, and data augmentation suffice to encode arbitrary styles in UVFAs without harming core task performance.
What would settle it
A test in which an agent is coached with a new style at runtime but either violates the main task constraints or fails to display the requested style characteristics.
Figures
read the original abstract
Reinforcement learning has proven to be a valuable tool in the creation of advanced AI and robotic systems, contributing to everything from game playing to robotics to foundation models. Through trial-and-error, these AI systems typically learn one, near-optimal behavior to solve their tasks. However, there are many use cases in which one would like to assert some level of control, preferably in real time, over how the task is solved. We refer to these modifications of a core task as styles. We combine universal value function approximators (UVFAs) with carefully selected training scenarios, learning algorithms, and data augmentation to create a framework for coaching agents that exhibit styles in complex domains. We demonstrate the framework's application in the AAA video games Horizon Forbidden West and Gran Turismo, and in an open-source humanoid test domain. Despite the different nature of the domains -- car racing, stylized game combat, and humanoid walking -- each agent shows strong coherence to the style requests while still satisfying the main task in its domain. Importantly, the techniques outlined in this paper allow an end user to choose the final behavior at run time, giving them flexible control over the final executed performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes combining universal value function approximators (UVFAs) with carefully selected training scenarios, learning algorithms, and data augmentation to enable coachable RL agents that exhibit user-specified styles at runtime while completing core tasks. It claims successful application in three dissimilar domains—Horizon Forbidden West (stylized game combat), Gran Turismo (car racing), and an open-source humanoid walking domain—where agents show strong style coherence without sacrificing main-task performance, providing end-user control over behavior.
Significance. If the empirical results hold with supporting metrics, the work would offer a practical, domain-agnostic method for runtime style control in RL agents, addressing a gap between single near-optimal policies and flexible, user-coachable behaviors in interactive systems like games and robotics. The cross-domain demonstrations, if quantitatively validated, would strengthen the case for UVFA-based style encoding as a general technique.
major comments (2)
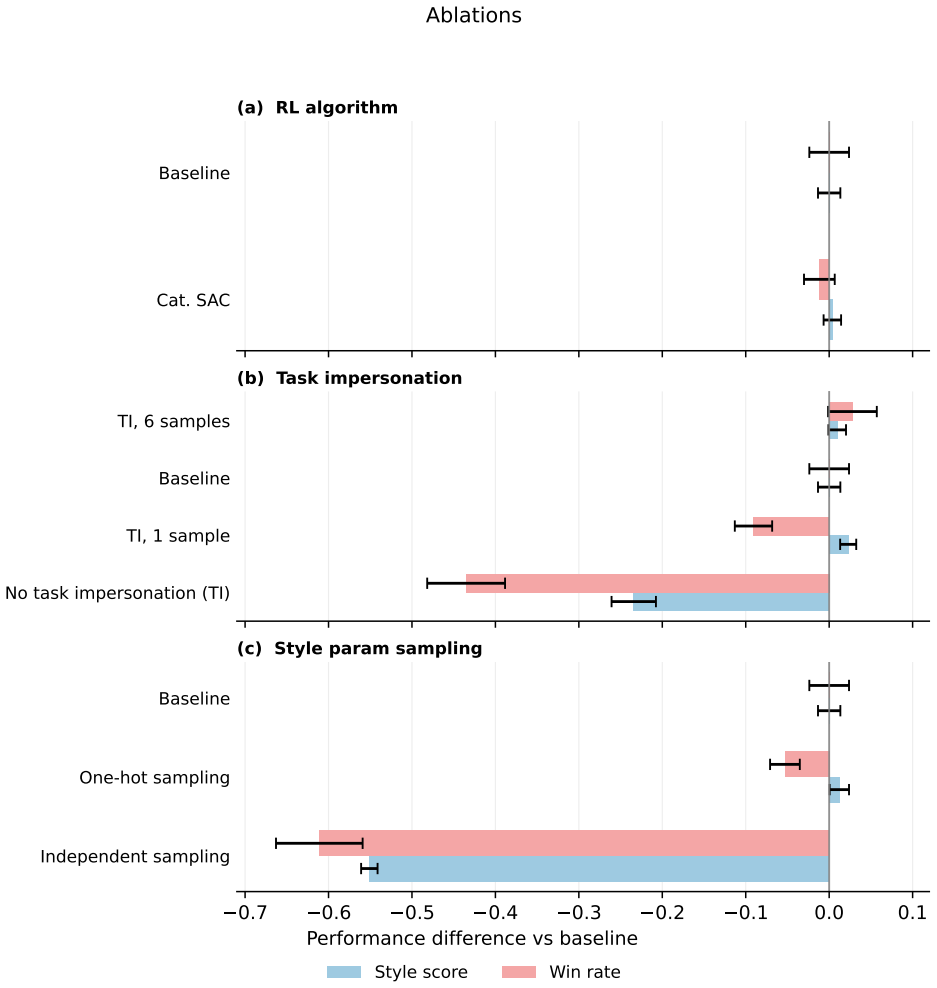
- [Abstract] Abstract: the central claim that 'each agent shows strong coherence to the style requests while still satisfying the main task' and that the approach works 'across domains without redesign' is asserted without any quantitative metrics (e.g., task success rates, lap times, or win rates with vs. without style conditioning), error analysis, or description of how style coherence was measured or parameterized as an auxiliary UVFA input. This leaves the load-bearing empirical demonstration without visible supporting data or tests for optimization conflicts.
- [Abstract / Introduction] The framework description (implicit in the abstract and introduction) assumes that style conditioning via UVFA auxiliary input preserves core value-function performance across domains, but supplies no equations, input parameterization details, or ablation results addressing potential capacity limits or interference between style and task objectives.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below, clarifying where supporting details appear in the manuscript and indicating revisions to improve visibility of the empirical claims and framework description.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'each agent shows strong coherence to the style requests while still satisfying the main task' and that the approach works 'across domains without redesign' is asserted without any quantitative metrics (e.g., task success rates, lap times, or win rates with vs. without style conditioning), error analysis, or description of how style coherence was measured or parameterized as an auxiliary UVFA input. This leaves the load-bearing empirical demonstration without visible supporting data or tests for optimization conflicts.
Authors: The abstract is a high-level summary. Quantitative metrics appear in the experimental sections: win rates and style alignment scores for Horizon Forbidden West, lap times with and without conditioning for Gran Turismo, and stability metrics for the humanoid domain, each with vs. without style inputs and reported with standard deviations across runs. Style coherence is quantified via the auxiliary UVFA head as the correlation between requested style vectors and observed behavior statistics. We will revise the abstract to include representative numerical results and a brief note on the measurement approach. revision: yes
-
Referee: [Abstract / Introduction] The framework description (implicit in the abstract and introduction) assumes that style conditioning via UVFA auxiliary input preserves core value-function performance across domains, but supplies no equations, input parameterization details, or ablation results addressing potential capacity limits or interference between style and task objectives.
Authors: Section 3 provides the UVFA equations, with the value function defined as Q(s, a, z) where z is the style embedding concatenated to the state. Input parameterization and training details are given there, and ablations on network capacity and objective interference appear in the appendix, showing preserved task performance. We will add a concise overview of the equations and parameterization to the introduction and reference the ablations explicitly. revision: partial
Circularity Check
No circularity; empirical demonstration is self-contained
full rationale
The paper describes an empirical framework that combines known UVFA techniques with selected training scenarios, algorithms, and augmentation to produce agents exhibiting requested styles while completing core tasks. No equations, parameter fits, or derivations are presented that would make any claimed outcome equivalent to its inputs by construction. Claims of coherence and task satisfaction rest on reported applications in three domains rather than on self-definitional mappings, fitted-input predictions, or load-bearing self-citations. The result is therefore not forced by the paper's own definitions or prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
& Steckelmacher, D.Dynamic weights in multi- objective deep reinforcement learninginInternational conference on machine learning(2019), 11– 20
Abels, A., Roijers, D., Lenaerts, T., Nowé, A. & Steckelmacher, D.Dynamic weights in multi- objective deep reinforcement learninginInternational conference on machine learning(2019), 11– 20
2019
-
[2]
M.et al.Learning dexterous in-hand manipulation.The International Journal of Robotics Research39,3–20 (2020)
Andrychowicz, O. M.et al.Learning dexterous in-hand manipulation.The International Journal of Robotics Research39,3–20 (2020)
2020
-
[3]
Asperti, A., George, F., Marras, T., Stricescu, R. C. & Zanotti, F. A critical assessment of modern generative models’ ability to replicate artistic styles.Big Data and Cognitive Computing9,231 (2025)
2025
-
[4]
Hearts, clubs, diamonds, spades: Players who suit MUDs.Journal of MUD research1, 19 (1996)
Bartle, R. Hearts, clubs, diamonds, spades: Players who suit MUDs.Journal of MUD research1, 19 (1996)
1996
-
[5]
An analog of the minimax theorem for vector payoffs.Pacific J
Blackwell, D. An analog of the minimax theorem for vector payoffs.Pacific J. Math.6,1–8. http://projecteuclid.org/euclid.pjm/1103044235(1956)
-
[6]
& Tammelin, O
Bowling, M., Burch, N., Johanson, M. & Tammelin, O. Heads-Up Limit Hold’em Poker is Solved. Science347,145–149 (2015)
2015
-
[7]
& Sandholm, T
Brown, N. & Sandholm, T. Superhuman AI for Heads-Up No-Limit Poker: Libratus Beats Top Professionals.Science359,418–424 (2018)
2018
-
[8]
& Sandholm, T
Brown, N. & Sandholm, T. Superhuman AI for Multiplayer Poker.Science365,885–890 (2019)
2019
-
[9]
& Schulman, J.Leveraging procedural generation to benchmark reinforcement learninginInternational conference on machine learning(2020), 2048–2056
Cobbe, K., Hesse, C., Hilton, J. & Schulman, J.Leveraging procedural generation to benchmark reinforcement learninginInternational conference on machine learning(2020), 2048–2056
2020
-
[10]
D’Orazio, R., Morrill, D., Wright, J. R. & Bowling, M.Alternative Function Approximation Param- eterizations for Solving Games: An Analysis ofƒ-Regression Counterfactual Regret Minimizationin Proceedings of the 19th International Conference on Autonomous Agents and MultiAgent Systems (2020), 339–347
2020
-
[11]
De Woillemont, P. L. P., Labory, R. & Corruble, V.Automated play-testing through RL based human-like play-styles generationinProceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment18(2022), 146–154
2022
-
[12]
De Woillemont, P. L. P., Labory, R. & Corruble, V.Configurable agent with reward as input: A play-style continuum generationin2021 IEEE Conference on Games (CoG)(2021), 1–8
2021
-
[13]
Stop Regressing: Training Value Functions via Classification for Scalable Deep RLinInternational Conference on Machine Learning(2024).https://openreview.net/forum? id=dVpFKfqF3R
Farebrother, J.et al. Stop Regressing: Training Value Functions via Classification for Scalable Deep RLinInternational Conference on Machine Learning(2024).https://openreview.net/forum? id=dVpFKfqF3R
2024
- [14]
-
[15]
J.Statistical theory of extreme values and some practical applications: a series of lectures(US Government Printing Office, 1954)
Gumbel, E. J.Statistical theory of extreme values and some practical applications: a series of lectures(US Government Printing Office, 1954)
1954
-
[16]
Guo, D.et al.DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning.Nature 645,633–638 (2025). 11
2025
-
[17]
& Levine, S.Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic ActorinInternational Conference on Machine Learning(2018), 1856–1865
Haarnoja, T., Zhou, A., Abbeel, P. & Levine, S.Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic ActorinInternational Conference on Machine Learning(2018), 1856–1865
2018
-
[18]
& Mas-Colell, A
Hart, S. & Mas-Colell, A. A Simple Adaptive Procedure Leading to Correlated Equilibrium.Econo- metrica68,1127–1150 (2000)
2000
-
[19]
Hayes, C. F.et al.A practical guide to multi-objective reinforcement learning and planning.arXiv preprint arXiv:2103.09568(2021)
- [20]
-
[21]
Huijben, I. A. M., Kool, W., Paulus, M. B. & van Sloun, R. J. G. A Review of the Gumbel-max Trick and its Extensions for Discrete Stochasticity in Machine Learning.IEEE Transactions on Pattern Analysis and Machine Intelligence45,1353–1371 (2023)
2023
-
[22]
& Hutter, M
Hwangbo, J., Sa, I., Siegwart, R. & Hutter, M. Control of a quadrotor with reinforcement learning. IEEE Robotics and Automation Letters2,2096–2103 (2017)
2096
-
[23]
& White, M.Improving regression performance with distributional lossesinInternational conference on machine learning(2018), 2157–2166
Imani, E. & White, M.Improving regression performance with distributional lossesinInternational conference on machine learning(2018), 2157–2166
2018
-
[24]
& Poole, B.Categorical Reparameterization with Gumbel-SoftmaxinInternational Conference on Learning Representations(2017)
Jang, E., Gu, S. & Poole, B.Categorical Reparameterization with Gumbel-SoftmaxinInternational Conference on Learning Representations(2017)
2017
- [25]
-
[26]
Scaling Up Multi-Task Robotic Reinforcement Learningin5th Annual Con- ference on Robot Learning(2021).https://openreview.net/forum?id=p9Pe-l9MMEq
Kalashnikov, D.et al. Scaling Up Multi-Task Robotic Reinforcement Learningin5th Annual Con- ference on Robot Learning(2021).https://openreview.net/forum?id=p9Pe-l9MMEq
2021
-
[27]
Kanervisto, A.et al.World and human action models towards gameplay ideation.Nature638, 656–663 (2025)
2025
-
[28]
Kaufmann, E.et al.Champion-level drone racing using deep reinforcement learning.Nature620, 982–987 (2023)
2023
-
[29]
Kompella, V., Walsh, T. J., Barrett, S., Wurman, P. & Stone, P.Event Tables for Efficient Expe- rience Replay2023. arXiv:2211.00576 [cs.LG].https://arxiv.org/abs/2211.00576
-
[30]
& Abbeel, P
Levine, S., Finn, C., Darrell, T. & Abbeel, P. End-to-end training of deep visuomotor policies. Journal of Machine Learning Research17,1–40 (2016)
2016
-
[31]
Li, Q.et al.Metadrive: Composing diverse driving scenarios for generalizable reinforcement learn- ing.IEEE transactions on pattern analysis and machine intelligence45,3461–3475 (2022)
2022
-
[32]
Liu, M., Zhu, M. & Zhang, W. Goal-conditioned reinforcement learning: Problems and solutions. arXiv preprint arXiv:2201.08299(2022)
-
[33]
Lundberg, S. M. & Lee, S.-I. in (Curran Associates, Inc., 2017).http://papers.nips.cc/paper/ 7062-a-unified-approach-to-interpreting-model-predictions.pdf
2017
-
[34]
& Levine, S
Luo, J., Xu, C., Wu, J. & Levine, S. Precise and dexterous robotic manipulation via human-in- the-loop reinforcement learning.Science Robotics10,eads5033 (2025)
2025
-
[35]
J., Mnih, A
Maddison, C. J., Mnih, A. & Teh, Y. W.The Concrete Distribution: A Continuous Relaxation of Discrete Random VariablesinInternational Conference on Learning Representations(2017). 12
2017
-
[36]
Mnih, V.et al.Playing Atari with deep reinforcement learning.arXiv preprint arXiv:1312.5602 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[37]
Science356,508–513 (2017)
Moravčík, M.et al.DeepStack: Expert-Level Artificial Intelligence in Heads-Up No-Limit Poker. Science356,508–513 (2017)
2017
-
[38]
Morrill, D.Hindsight rational learning for sequential decision-making: Foundations and experimen- tal applicationsDoctoral thesis (University of Alberta, 2022)
2022
-
[39]
Morrill, D.Using Regret Estimation to Solve Games CompactlyMaster’s thesis (University of Alberta, 2016)
2016
-
[40]
Reward-Conditioned Reinforcement Learning
Nauman, M., Cygan, M. & Abbeel, P. A practical guide to multi-objective reinforcement learning and planning.arXiv preprint arXiv:2603.05066(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[41]
Noukhovitch, M.et al.Asynchronous RLHF: Faster and More Efficient Off-Policy RL for Language ModelsinThe Thirteenth International Conference on Learning Representations()
-
[42]
Ouyang, L.et al.Training language models to follow instructions with human feedback.Advances in neural information processing systems35,27730–27744 (2022)
2022
-
[43]
& Peter, S
Riemer, K. & Peter, S. Conceptualizing generative AI as style engines: Application archetypes and implications.International Journal of Information Management79,102824 (2024)
2024
-
[44]
& Silver, D.Universal Value Function ApproximatorsinPro- ceedings of the 32nd International Conference on Machine Learning(eds Bach, F
Schaul, T., Horgan, D., Gregor, K. & Silver, D.Universal Value Function ApproximatorsinPro- ceedings of the 32nd International Conference on Machine Learning(eds Bach, F. & Blei, D.)37 (PMLR, Lille, France, July 2015), 1312–1320.https://proceedings.mlr.press/v37/schaul15. html
2015
-
[45]
Schmid, M.et al.Student of Games: A unified learning algorithm for both perfect and imperfect information games.Science Advances9,eadg3256 (2023)
2023
-
[46]
Silver, D.et al.Mastering the game of Go with deep neural networks and tree search.Nature529, 484–489 (2016)
2016
-
[47]
Silver, D.et al.Mastering the game of Go without human knowledge.Nature550,354–359 (2017)
2017
-
[48]
& Zisserman, A.Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency MapsinWorkshop at International Conference on Learning Representations(2014)
Simonyan, K., Vedaldi, A. & Zisserman, A.Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency MapsinWorkshop at International Conference on Learning Representations(2014)
2014
-
[49]
Aligning large multimodal models with factually augmented rlhfinFindings of the Association for Computational Linguistics: ACL 2024(2024), 13088–13110
Sun, Z.et al. Aligning large multimodal models with factually augmented rlhfinFindings of the Association for Computational Linguistics: ACL 2024(2024), 13088–13110
2024
-
[50]
Sutton, R. S.et al. Horde: A scalable real-time architecture for learning knowledge from unsuper- vised sensorimotor interactioninThe 10th International Conference on Autonomous Agents and Multiagent Systems-Volume 2(2011), 761–768
2011
-
[51]
net/book/the-book-2nd.html(The MIT Press, 2018)
Sutton,R.S.&Barto,A.G.Reinforcement Learning: An IntroductionSecond.http://incompleteideas. net/book/the-book-2nd.html(The MIT Press, 2018)
2018
-
[52]
Tammelin,O.SolvingLargeImperfectInformationGamesUsingCFR+.arXiv preprint arXiv:1407.5042 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[53]
& Bowling, M.Solving Heads-up Limit Texas Hold’emin 24th International Joint Conference on Artificial Intelligence (IJCAI 2015)(2015)
Tammelin, O., Burch, N., Johanson, M. & Bowling, M.Solving Heads-up Limit Texas Hold’emin 24th International Joint Conference on Artificial Intelligence (IJCAI 2015)(2015)
2015
-
[54]
Tassa, Y.et al. DeepMind Control Suite2018. arXiv:1801.00690 [cs.AI].https://arxiv.org/ abs/1801.00690. 13
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
Tobin, J.et al. Domain randomization for transferring deep neural networks from simulation to the real worldin2017 IEEE/RSJ international conference on intelligent robots and systems (IROS) (2017), 23–30
2017
-
[56]
& Tassa, Y.Mujoco: A physics engine for model-based controlin2012 IEEE/RSJ international conference on intelligent robots and systems(2012), 5026–5033
Todorov, E., Erez, T. & Tassa, Y.Mujoco: A physics engine for model-based controlin2012 IEEE/RSJ international conference on intelligent robots and systems(2012), 5026–5033
2012
-
[57]
Tunyasuvunakool,S.et al.dm_control:Softwareandtasksforcontinuouscontrol.Software Impacts 6,100022 (2020)
2020
-
[58]
Nature575,350–354 (2019)
Vinyals, O.et al.Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature575,350–354 (2019)
2019
-
[59]
& Bowling, M.Solving games with functional regret estimation inProceedings of the AAAI Conference on Artificial Intelligence29(2015)
Waugh, K., Morrill, D., Bagnell, J. & Bowling, M.Solving games with functional regret estimation inProceedings of the AAAI Conference on Artificial Intelligence29(2015)
2015
-
[60]
Dynamic Multi-Team Racing: Competitive Driving on 1/10-th Scale Vehicles via Learning in Simulationin7th Annual Conference on Robot Learning(2023), 1667–1685
Werner, P.et al. Dynamic Multi-Team Racing: Competitive Driving on 1/10-th Scale Vehicles via Learning in Simulationin7th Annual Conference on Robot Learning(2023), 1667–1685
2023
-
[61]
average” policy that partially satisfies both 0 and positive values. Using 0 to indicate “not encouraged
Wurman, P. R.et al.Outracing champion Gran Turismo drivers with deep reinforcement learning. Nature602,223–228 (2022). 14 Appendices Overview •Appendix A: Style-Conditioned UVFA •Appendix B: Training Algorithms •Appendix C: Domain Details •Appendix D: Extended Data –Table 1 - Horizon Forbidden West machine types reference. –Table 2 - configured weapons re...
2022
-
[62]
vibrating
Initialization uses Glorot–Uniform weights and zero biases; networks are trained with Cat-RAC. Policy.Actions for analog sticks use tanh-Gaussian distributions, with meanµ∈[−1,1](after tanh) and standard deviationsσobtained by squashing the network output to[−2,2]with2 tanh(·)and then exponentiating. The discrete actions necessary to enforce the virtual h...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.