REVIEW 2 major objections 1 minor 11 cited by
Tree-structured rollouts with verifiable rewards and scheduled self-distillation deliver reliable step-wise advantages for diffusion language models.
Reviewed by Pith at T0; open to challenge. T0 means a machine referee read the full paper against a public rubric. the ladder, T0–T4 →
T0 review · grok-4.3
2026-05-16 23:19 UTC pith:GV7LXWOK
load-bearing objection d-TreeRPO pairs tree rollouts for step-wise advantages with scheduled self-distillation to tighten probability estimates in diffusion LLM RL, delivering large reported gains on puzzle benchmarks but leaving the advantage estimates without clear unbiasedness support. the 2 major comments →
d-TreeRPO: Towards More Reliable Policy Optimization for Diffusion Language Models
The pith
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
d-TreeRPO uses tree-structured rollouts and bottom-up advantage computation based on verifiable outcome rewards to supply fine-grained step-wise signals. It proves that higher prediction confidence reduces the difference between a single forward-pass probability estimate and the unbiased expectation over all decoding orders, and introduces a time-scheduled self-distillation loss to raise confidence in later training stages.
What carries the argument
Tree-structured rollouts whose leaves carry verifiable outcome rewards, with advantages propagated bottom-up, plus a time-scheduled self-distillation term that raises prediction confidence to close the gap to unbiased decoding-order expectations.
Load-bearing premise
Tree-structured rollouts based on verifiable outcome rewards produce unbiased fine-grained step-wise advantage estimates that remain valid outside the sampled trees.
What would settle it
Measure whether d-TreeRPO's advantage estimates remain accurate when the model is evaluated on decoding orders that were never present in any training tree.
If this is right
- Step-wise advantages become less noisy, so policy gradients exhibit lower variance during diffusion LLM training.
- Reasoning performance improves most on tasks whose final answers can be checked automatically.
- The self-distillation schedule allows later training epochs to use tighter probability estimates without changing the rollout procedure.
- The same tree construction can be reused across multiple policy updates as long as the reward function stays fixed.
Where Pith is reading between the lines
- If verifiable rewards are replaced by learned critics, the bias-variance tradeoff of the tree estimates would need fresh analysis.
- The method's gains may shrink on open-ended generation tasks where no automatic verifier exists.
- Extending rollout depth beyond the tested budgets could further reduce variance in long-horizon reasoning problems.
- The confidence-scheduling idea might transfer to other autoregressive or diffusion generators that face intractable marginalization over orderings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
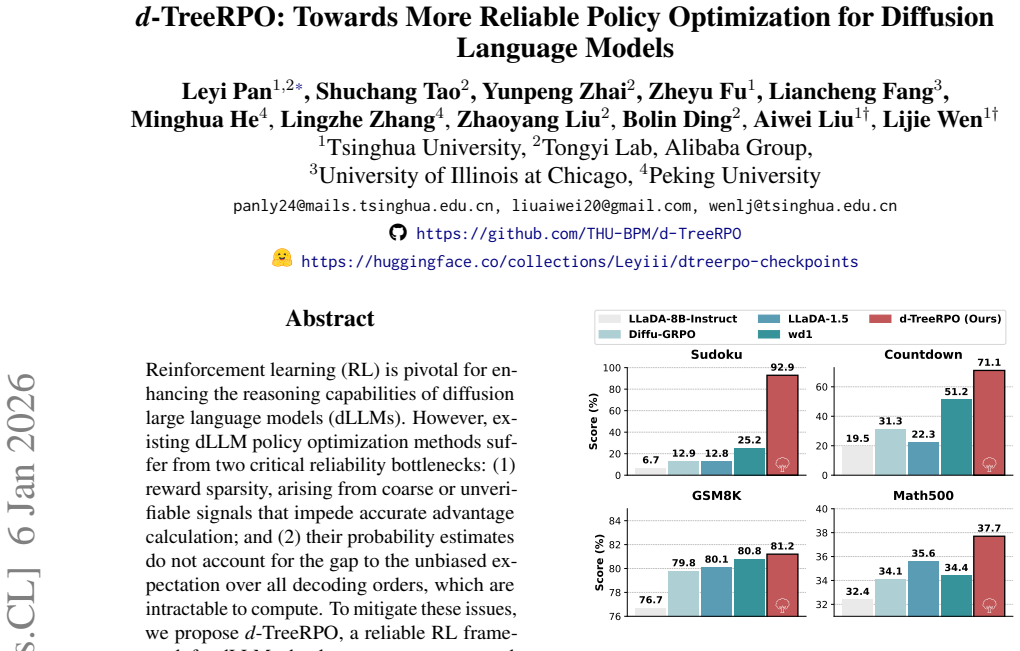
Summary. The paper proposes d-TreeRPO, an RL framework for diffusion language models that uses tree-structured rollouts with bottom-up advantage computation from verifiable outcome rewards to address reward sparsity, combined with a time-scheduled self-distillation loss. A theoretical proof shows that increasing prediction confidence minimizes the gap between single-step forward-pass probability estimates and the unbiased expectation over all decoding orders. Experiments report large gains over the base model: +86.2% on Sudoku, +51.6% on Countdown, +4.5% on GSM8K, and +5.3% on Math500.
Significance. If the core claims hold, the work could provide a practical route to more reliable policy optimization in dLLMs by supplying finer-grained verifiable signals and tighter probability estimates. The reported benchmark gains, especially on Sudoku and Countdown, indicate potential impact for reasoning tasks if the tree-based advantages prove stable and generalizable. The explicit theoretical treatment of the self-distillation term is a constructive element.
major comments (2)
- [Abstract and theoretical analysis section] The central claim that finite tree rollouts with bottom-up advantage computation yield unbiased step-wise estimates is load-bearing but unsupported. The diffusion process involves intractable expectations over decoding orders; no analysis shows that the particular tree sampling (depth, branching, selection) produces estimates whose expectation matches the true value function or remains stable under changes to the tree distribution. This is distinct from the self-distillation term, which receives a proof.
- [Experiments section] Experimental reporting is insufficient to assess the claimed improvements. No baseline descriptions, number of runs, statistical significance tests, variance estimates, or ablations on tree hyperparameters are provided, making it impossible to determine whether the +86.2% Sudoku and +51.6% Countdown gains are robust or method-specific.
minor comments (1)
- [Method section] The time schedule for the self-distillation loss is described only at a high level; an explicit functional form or pseudocode would clarify how the schedule interacts with the RL objective.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback on our manuscript. We appreciate the recognition of the potential impact of d-TreeRPO and will address the major comments by providing additional analysis and experimental details in the revised version.
read point-by-point responses
-
Referee: [Abstract and theoretical analysis section] The central claim that finite tree rollouts with bottom-up advantage computation yield unbiased step-wise estimates is load-bearing but unsupported. The diffusion process involves intractable expectations over decoding orders; no analysis shows that the particular tree sampling (depth, branching, selection) produces estimates whose expectation matches the true value function or remains stable under changes to the tree distribution. This is distinct from the self-distillation term, which receives a proof.
Authors: We thank the referee for pointing out this important distinction. The manuscript provides a theoretical proof specifically for the self-distillation loss, showing that increasing prediction confidence minimizes the gap to the unbiased expectation over decoding orders. For the tree-structured rollouts, the approach relies on bottom-up advantage computation from verifiable outcome rewards to deliver fine-grained signals, which we demonstrate empirically through substantial performance gains. However, we acknowledge that a formal proof or analysis establishing that the finite tree sampling produces unbiased estimates matching the true value function or its stability under varying tree distributions is not included. In the revised manuscript, we will add a discussion section addressing the potential bias and stability of the tree-based estimates, including any available bounds or empirical validation of robustness to tree hyperparameters. revision: yes
-
Referee: [Experiments section] Experimental reporting is insufficient to assess the claimed improvements. No baseline descriptions, number of runs, statistical significance tests, variance estimates, or ablations on tree hyperparameters are provided, making it impossible to determine whether the +86.2% Sudoku and +51.6% Countdown gains are robust or method-specific.
Authors: We agree that the current experimental reporting is insufficient for full assessment of the results' robustness. In the revised manuscript, we will expand the experiments section to include: detailed descriptions of all baselines and their implementations; results averaged over multiple independent runs with reported means, standard deviations, and variance estimates; statistical significance tests (e.g., t-tests) comparing d-TreeRPO to baselines; and comprehensive ablations on tree hyperparameters such as rollout depth, branching factor, and selection strategies. These additions will allow readers to better evaluate the reliability of the reported gains on Sudoku, Countdown, and other benchmarks. revision: yes
Circularity Check
No significant circularity; methods derive from RL principles and internal proof without reduction to inputs
full rationale
The paper introduces tree-structured rollouts for bottom-up advantage computation from verifiable outcome rewards and a separate theoretical proof that increasing prediction confidence reduces the gap to unbiased expectations over decoding orders. The self-distillation loss is then scheduled based on that proof. No equations or claims reduce by construction to fitted parameters, self-citations, or renamed inputs; the advantage estimates and probability correction are presented as independent constructions, with empirical gains reported separately on benchmarks. The derivation chain remains self-contained against external RL and diffusion baselines.
Axiom & Free-Parameter Ledger
free parameters (1)
- time schedule for self-distillation
axioms (1)
- domain assumption Increasing prediction confidence minimizes the gap between single-step probability estimates and the unbiased expectation over all decoding orders
read the original abstract
Reinforcement learning (RL) is pivotal for enhancing the reasoning capabilities of diffusion large language models (dLLMs). However, existing dLLM policy optimization methods suffer from two critical reliability bottlenecks: (1) reward sparsity, arising from coarse or unverifiable signals that impede accurate advantage calculation; and (2) their probability estimates do not account for the gap to the unbiased expectation over all decoding orders, which are intractable to compute. To mitigate these issues, we propose d-TreeRPO, a reliable RL framework for dLLMs that leverages tree-structured rollouts and bottom-up advantage computation based on verifiable outcome rewards to provide fine-grained and verifiable step-wise reward signals. Furthermore, we provide a theoretical proof demonstrating that increasing prediction confidence effectively minimizes the gap between unbiased expected prediction probabilities and its single-step forward pass estimate. Guided by this analysis, we introduce a time-scheduled self-distillation loss during training that enhances prediction confidence in later training stages, thereby enabling more accurate probability estimation and better performance. Experiments demonstrate that d-TreeRPO outperforms existing baselines and achieves significant improvements across multiple reasoning benchmarks. Specifically, it achieves +86.2% on Sudoku, +51.6% on Countdown, +4.5% on GSM8K, and +5.3% on Math500 compared to the base model.
Figures
















Forward citations
Cited by 11 Pith papers
-
Learning from the Self-future: On-policy Self-distillation for dLLMs
d-OPSD reframes on-policy self-distillation for dLLMs via suffix conditioning from self-generated answers and step-level supervision, outperforming RLVR and SFT on reasoning benchmarks with ~10% of the optimization steps.
-
Read the Trace, Steer the Path: Trajectory-Aware Reinforcement Learning for Diffusion Language Models
CAPR is a new dLLM-RL method that uses cached trajectory states and block-wise reward redistribution from the denoising trace to deliver tree-like supervision at 0.75x flat and 0.6x tree rollout compute, achieving SOT...
-
From Feedback Loops to Policy Updates: Reinforcement Fine-Tuning for LLM-Based Alpha Factor Discovery
QuantEvolver applies reinforcement fine-tuning to evolve an LLM policy for generating executable alpha factor expressions, yielding higher-quality and more complementary factors than prompt-based baselines on market b...
-
Relative Score Policy Optimization for Diffusion Language Models
RSPO interprets reward advantages as targets for relative log-ratios in dLLMs, calibrating noisy estimates to stabilize RLVR training and achieve strong gains on planning tasks with competitive math reasoning performance.
-
Towards Robust LLM Post-Training: Automatic Failure Management for Reinforcement Fine-Tuning
Introduces the first benchmark for fine-grained failures in reinforcement fine-tuning of LLMs and an automatic management framework that detects, diagnoses, and remediates them.
-
E2E-REME: Towards End-to-End Microservices Auto-Remediation via Experience-Simulation Reinforcement Fine-Tuning
E2E-REME outperforms nine LLMs in accuracy and efficiency for end-to-end microservice remediation by using experience-simulation reinforcement fine-tuning on a new benchmark called MicroRemed.
-
DMax: Aggressive Parallel Decoding for dLLMs
DMax uses On-Policy Uniform Training and Soft Parallel Decoding to enable aggressive parallelism in dLLMs, raising TPF on GSM8K from 2.04 to 5.47 and on MBPP from 2.71 to 5.86 while preserving accuracy.
-
Sketch Then Paint: Hierarchical Reinforcement Learning for Diffusion Multi-Modal Large Language Models
Proposes HT-GRPO with sketch-then-paint staged updates, prompt-conditioned importance ratios, and hierarchical credit assignment for dMLLMs, reporting gains on GenEval and DPG plus quality metrics.
-
Towards In-Depth Root Cause Localization for Microservices with Multi-Agent Recursion-of-Thought
RCLAgent uses multi-agent recursion-of-thought with parallel reasoning on trace graphs to outperform prior methods in root cause localization accuracy and efficiency for microservice systems.
-
TACG: Trajectory-Aware Commit Gating for Diffusion Language Model Decoding
Trajectory-aware commit gating (TILG + History Gate + capped extra promotion) improves or preserves DLLM accuracy while reducing steps and raising tokens-per-forward without retraining.
-
DMax: Aggressive Parallel Decoding for dLLMs
DMax enables faster parallel decoding in diffusion language models by using on-policy training to recover from errors and soft embedding interpolations for iterative revision, boosting tokens per forward pass roughly ...
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.arXiv preprint arXiv:2110.14168. Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, and 1 others. 2025. The entropy mechanism of reinforcement learning for reasoning language models.arXiv preprint arXiv:2505.22617. Shansan Gong, Ruixiang ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Let’s verify step by step.arXiv preprint arXiv:2305.20050. Nianyi Lin, Jiajie Zhang, Lei Hou, and Juanzi Li. 2025. Boundary-guided policy optimization for memory- efficient rl of diffusion large language models.arXiv preprint arXiv:2510.11683. Shen Nie, Fengqi Zhu, Chao Du, Tianyu Pang, Qian Liu, Guangtao Zeng, Min Lin, and Chongxuan Li
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Scaling up Masked Diffusion Models on Text
Scaling up masked diffusion models on text. arXiv preprint arXiv:2410.18514. Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. 2025. Large language dif- fusion models.arXiv preprint arXiv:2502.09992. Jingyang Ou, Jiaqi Han, Minkai Xu, Shaoxuan Xu, Jian- wen Xie, Stefano Ermon, Yi Wu, a...
work page Pith review arXiv 2025
-
[4]
Improving reasoning for diffusion language models via group diffusion policy optimization
Improving reasoning for diffusion language models via group diffusion policy optimization. arXiv preprint arXiv:2510.08554. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proxi- mal policy optimization algorithms.arXiv preprint arXiv:1707.06347. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Ha...
-
[5]
Dream 7B: Diffusion Large Language Models
Dream 7b: Diffusion large language models. arXiv preprint arXiv:2508.15487. Jiasheng Ye, Zaixiang Zheng, Yu Bao, Lihua Qian, and Quanquan Gu. 2023. Diffusion language models can perform many tasks with scaling and instruction- finetuning.arXiv preprint arXiv:2308.12219. Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tia...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
A survey on parallel text generation: From par- allel decoding to diffusion language models.arXiv preprint arXiv:2508.08712. Siyan Zhao, Devaansh Gupta, Qinqing Zheng, and Aditya Grover. 2025a. d1: Scaling reasoning in diffusion large language models via reinforcement learning.arXiv preprint arXiv:2504.12216. Siyan Zhao, Mengchen Liu, Jing Huang, Miao Liu...
-
[7]
Why “high probability”?The randomness comes from σ∼ Q . Theorem 1 states that the estimation error is bounded on an event of probability at least1−δw.r.t. dQ
-
[8]
Why does confidence tighten the bound?The bound is monotone in ϵd,δ: as ϵd,δ decreases, −log(1−ϵ d,δ) decreases and approaches
-
[9]
Thus, higher token confidence (smaller typical-path confidence gap) yields a tighter error bound
-
[10]
Relation to ptrue d .Theorem 1 bounds the deviation between ˆpd and the random vari- able qτ(d,σ) (σ) for typical decoding orders. Since ptrue d is the expectation of qτ(d,σ) (σ) over σ∼ Q , reducing the typical-path devi- ation (smaller ϵd,δ) makes ˆpd a more reliable proxy when approximatingp true d . 11 B Detailed Descriptions of dLLM RL Baselines Diff...
work page 2025
-
[12]
From the second relationship, we know that 2T+G=S
Two treeks and one goolee are equal in weight to one squig:2T+G=S We need to find the number of treeks whose combined weight equals the weight of one squig. From the second relationship, we know that 2T+G=S . This implies that the combined weight of two treeks and one goolee is equal to the weight of one squig. Therefore, the weight of two treeks equals t...
-
[13]
Ten treeks weigh as much as three squigs and one goolee:10T= 3S+G
-
[14]
From the second relationship, we know that 2T+G=S
Two treeks and one goolee are equal in weight to one squig:2T+G=S We need to find the number of treeks whose combined weight equals the weight of one squig. From the second relationship, we know that 2T+G=S . This means that the combined weight of two treeks and one goolee is equal to the weight of one squig. Therefore, the number of treeks that equal the...
-
[15]
Let the weight of one treek be T , the weight of one squig be S, and the weight of one goolee be G
-
[16]
From the first equation:10T= 3S+G
-
[17]
From the second equation:2T+G=S
-
[18]
Substitute S= 2T+G from the second equation into the first: 10T= 3(2T+G) +G , 10T= 6 +T+G,4T=G✗
-
[19]
LLaDA-8B-Instruct +d-TreeRPO Question:Ten treeks weigh as much as three squigs and one goolee
To find how many treeks equal the weight of one squig:S= 6Twhich means 6 treeks </reasoning> <answer> 6 ✗ </answer> Figure 18: A case study of LLaDA-8B-Instruct trained with wd1 responding to a GSM8K question. LLaDA-8B-Instruct +d-TreeRPO Question:Ten treeks weigh as much as three squigs and one goolee. Two treeks and one goolee are equal in weight to one...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.