LLM-as-an-Investigator: Evidence-First Reasoning for Robust Interactive Problem Diagnosis
Pith reviewed 2026-06-27 06:57 UTC · model grok-4.3
The pith
An evidence-first LLM agent improves technical diagnosis accuracy by gathering targeted evidence before committing to any user-suggested explanation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
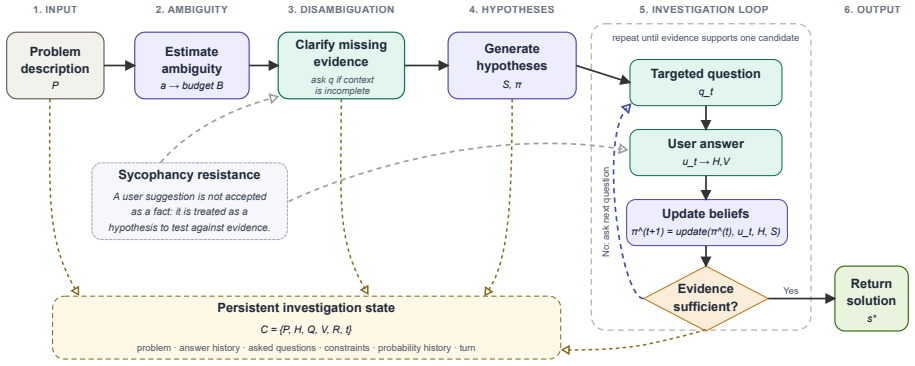
The Solution Investigator Agent estimates the ambiguity of an initial problem description, generates candidate hypotheses, asks targeted clarification questions, and updates hypothesis probabilities after each answer, continuing until the evidence makes one candidate stronger than the alternatives.
What carries the argument
The Solution Investigator Agent, which maintains and refines a set of hypotheses through iterative, evidence-driven questioning rather than immediate response generation.
If this is right
- The agent recovers the correct diagnosis more often than direct prompting or reasoning-only baselines across LLM backbones.
- The evidence-first protocol lowers the rate at which the model adopts a plausible but incorrect user hypothesis.
- The three-agent pipeline converts solved forum threads into repeatable test cases for interactive diagnosis.
- Performance gains appear in mechanical, electrical, and hydraulic troubleshooting domains.
Where Pith is reading between the lines
- The same questioning loop could be applied to domains such as medical symptom diagnosis where premature conclusions are costly.
- Adding external tool calls to verify answers during the probability update step would strengthen the evidence collection process.
- The method points toward a reusable template for any LLM task that involves distinguishing between competing explanations under user input.
Load-bearing premise
The Ground-Truth Evaluator Agent can faithfully simulate real user responses in the three-agent pipeline while hiding the known solution without introducing evaluation bias.
What would settle it
Replace the Ground-Truth Evaluator with actual human users who know the true solution and measure whether the accuracy advantage over baselines disappears.
Figures
read the original abstract
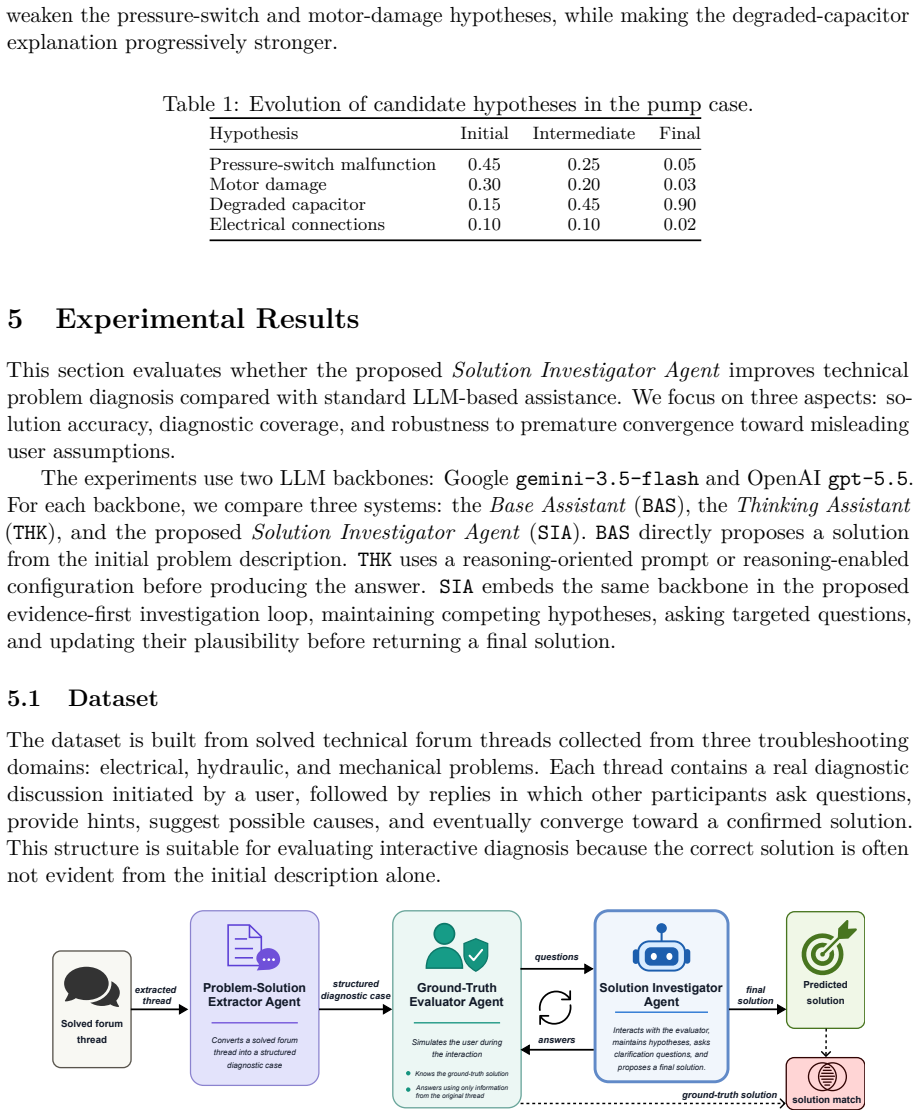
Large language models (LLMs) are increasingly used as interactive assistants for technical problem solving. However, when users provide incomplete descriptions or plausible but unverified explanations, LLMs may prematurely align with these assumptions and propose solutions before collecting sufficient evidence. We refer to this behavior as user-driven sycophancy: the tendency of an LLM to reinforce a user-provided hypothesis instead of testing alternative explanations. This paper introduces LLM-as-an-Investigator, an evidence-first agentic AI methodology for robust problem diagnosis. The approach is implemented through a Solution Investigator Agent, which estimates the ambiguity of an initial problem description, generates candidate hypotheses, asks targeted clarification questions, and updates hypothesis probabilities after each answer. Rather than producing an immediate response, the agent continues the investigation until the evidence makes one candidate explanation stronger than the alternatives. To evaluate the approach, we build a benchmark from solved technical forum threads in mechanical, electrical, and hydraulic domains. We use a three-agent evaluation pipeline in which a Problem-Solution Extractor Agent converts solved threads into structured cases, a Ground-Truth Evaluator Agent simulates the user while hiding the known solution, and the tested assistant attempts to recover the solution through dialogue. The experiments compare standard assistants, reasoning-oriented LLMs, and the proposed investigator-based model across LLM backbones. In addition to diagnostic accuracy, we analyze how standard assistants follow misleading user hypotheses in diagnostic cases. The results show that the proposed approach identifies the problem more accurately than direct prompting and reasoning-only baselines, while its evidence-first protocol helps reduce user-induced conversational bias.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LLM-as-an-Investigator, an evidence-first agentic methodology for robust interactive technical problem diagnosis. A Solution Investigator Agent estimates ambiguity in the initial user description, generates candidate hypotheses, poses targeted clarification questions, and iteratively updates hypothesis probabilities until the evidence sufficiently favors one explanation over alternatives. The approach is evaluated on a benchmark derived from solved forum threads in mechanical, electrical, and hydraulic domains via a three-agent pipeline (Problem-Solution Extractor, Ground-Truth Evaluator simulating the user while hiding the known solution, and the tested assistant). The authors claim higher diagnostic accuracy than direct-prompting and reasoning-only baselines together with reduced susceptibility to user-induced conversational bias.
Significance. If the empirical claims hold after validation of the simulator, the work supplies a concrete protocol for mitigating user-driven sycophancy in LLM assistants for technical troubleshooting. The construction of an evaluation benchmark from real solved threads is a constructive step toward reproducible assessment of interactive diagnostic agents.
major comments (2)
- [Evaluation (three-agent pipeline)] Evaluation section (three-agent pipeline description): The accuracy and bias-reduction claims rest entirely on the Ground-Truth Evaluator Agent producing responses that are (a) consistent with the hidden ground-truth solution and (b) representative of real forum-user behavior. The manuscript provides no external validation, human-subject comparison, or distributional analysis demonstrating that the simulated dialogues match actual user reply patterns; any systematic deviation would directly inflate reported gains.
- [Abstract and Experiments] Abstract and Experiments: The abstract states that 'the results show' superior accuracy, yet supplies no quantitative metrics, benchmark sizes, statistical significance tests, or per-domain breakdowns. Without these data the central empirical claim cannot be verified against the stated baselines.
minor comments (2)
- [Method] Clarify the exact probabilistic update rule (Bayesian or otherwise) used by the investigator after each user answer; the current description mentions 'updates hypothesis probabilities' without an equation or pseudocode.
- [Method] Add a short discussion of how the ambiguity estimator is implemented and whether it is itself learned or heuristic.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important aspects of our evaluation methodology and presentation of results. We respond to each major comment below and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: [Evaluation (three-agent pipeline)] Evaluation section (three-agent pipeline description): The accuracy and bias-reduction claims rest entirely on the Ground-Truth Evaluator Agent producing responses that are (a) consistent with the hidden ground-truth solution and (b) representative of real forum-user behavior. The manuscript provides no external validation, human-subject comparison, or distributional analysis demonstrating that the simulated dialogues match actual user reply patterns; any systematic deviation would directly inflate reported gains.
Authors: We agree that the absence of external validation for the Ground-Truth Evaluator is a substantive limitation. The evaluator is constructed to remain consistent with the hidden solution by design, but we did not conduct human-subject studies or distributional comparisons against real forum users. In the revised manuscript we will add an explicit limitations subsection that discusses this assumption, reports basic statistics on simulated dialogue characteristics (e.g., turn counts and response patterns), and notes the risk of simulator-induced bias. This addition will make the evaluation assumptions transparent without requiring new human experiments. revision: yes
-
Referee: [Abstract and Experiments] Abstract and Experiments: The abstract states that 'the results show' superior accuracy, yet supplies no quantitative metrics, benchmark sizes, statistical significance tests, or per-domain breakdowns. Without these data the central empirical claim cannot be verified against the stated baselines.
Authors: The experiments section contains the requested quantitative details, including benchmark sizes per domain and accuracy comparisons to baselines. To make the abstract self-contained and verifiable, we will revise it to include the key numerical results (overall and per-domain accuracies), benchmark sizes, and any statistical significance tests that were performed. revision: yes
Circularity Check
No significant circularity; evaluation pipeline is externally anchored
full rationale
The paper constructs its benchmark from real solved forum threads via a three-agent pipeline (Problem-Solution Extractor, Ground-Truth Evaluator hiding the solution, and tested assistant). Diagnostic accuracy and bias-reduction claims are measured against this benchmark rather than being derived from any internal equations, fitted parameters, or self-referential definitions. No self-citations appear as load-bearing premises, no ansatzes are smuggled, and no result is renamed or forced by construction. The Ground-Truth Evaluator's simulation role is an explicit design choice whose fidelity is an external validity question, not a circular reduction of the reported gains to the method's own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Brown et al
Tom B. Brown et al. Language models are few-shot learners. InAdvances in Neural Information Processing Systems, volume 33, pages 1877–1901, 2020
1901
-
[2]
Training language models to follow instructions with human feedback
Long Ouyang et al. Training language models to follow instructions with human feedback. arXiv:2203.02155, 2022
Pith/arXiv arXiv 2022
-
[3]
A survey on large language model based autonomous agents.arXiv preprint arXiv:2308.11432, 2023
Lei Wang et al. A survey on large language model based autonomous agents.arXiv preprint arXiv:2308.11432, 2023
Pith/arXiv arXiv 2023
-
[4]
Junyu Luo et al. Large language model agent: A survey on methodology, applications and challenges.arXiv preprint arXiv:2503.21460, 2025
Pith/arXiv arXiv 2025
-
[5]
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. CLAM: Selective clarification for ambiguous questions with generative language models.arXiv preprint arXiv:2212.07769, 2022. 15
arXiv 2022
-
[6]
Gangwoo Kim, Sungdong Kim, Byeongguk Jeon, Joonsuk Park, and Jaewoo Kang. Tree of clarifications: Answering ambiguous questions with retrieval-augmented large language models.arXiv preprint arXiv:2310.14696, 2023
arXiv 2023
-
[7]
Discovering language model behaviors with model-written evaluations
Ethan Perez et al. Discovering language model behaviors with model-written evaluations. arXiv preprint arXiv:2212.09251, 2022
Pith/arXiv arXiv 2022
-
[8]
Towards understanding sycophancy in language models.arXiv preprint arXiv:2310.13548, 2023
Mrinank Sharma et al. Towards understanding sycophancy in language models.arXiv preprint arXiv:2310.13548, 2023
Pith/arXiv arXiv 2023
-
[9]
Leonardo Ranaldi and Giulia Pucci. When large language models contradict humans? large language models’ sycophantic behaviour.arXiv preprint arXiv:2311.09410, 2023
arXiv 2023
-
[10]
Sule Ozturk Birim, Fabrizio Marozzo, and Yigit Kazancoglu. Generative ai in managerial decision-making: Redefining boundaries through ambiguity resolution and sycophancy analysis.arXiv preprint arXiv:2603.03970, 2026
arXiv 2026
-
[11]
Junyi Li, Xiaoxue Cheng, Wayne Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen. HaluEval: A large-scale hallucination evaluation benchmark for large language models.arXiv preprint arXiv:2305.11747, 2023
arXiv 2023
- [12]
-
[13]
Pengyu Zhao, Zijian Jin, and Ning Cheng. An in-depth survey of large language model-based artificial intelligence agents.arXiv preprint arXiv:2309.14365, 2023
arXiv 2023
-
[14]
Pranab Sahoo et al. A systematic survey of prompt engineering in large language models: Techniques and applications.arXiv preprint arXiv:2402.07927, 2024
Pith/arXiv arXiv 2024
-
[15]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei et al. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems, volume 35, pages 24824–24837, 2022
2022
-
[16]
Largelanguagemodelsarezero-shotreasoners
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Largelanguagemodelsarezero-shotreasoners. InAdvances in Neural Information Processing Systems, volume 35, pages 22199–22213, 2022
2022
-
[17]
Self-consistency improves chain of thought reasoning in language models
Xuezhi Wang et al. Self-consistency improves chain of thought reasoning in language models. InInternational Conference on Learning Representations, 2023
2023
-
[18]
Least-to-most prompting enables complex reasoning in large language models
Denny Zhou et al. Least-to-most prompting enables complex reasoning in large language models. InInternational Conference on Learning Representations, 2023
2023
-
[19]
Automatic chain of thought prompting in large language models
Zhuosheng Zhang, Aston Zhang, Mu Li, and Alex Smola. Automatic chain of thought prompting in large language models. InInternational Conference on Learning Representa- tions, 2023
2023
-
[20]
Griffiths, Yuan Cao, and Karthik Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. InAdvances in Neural Information Processing Systems, volume 36, 2023
2023
-
[21]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations, 2023
2023
-
[22]
Agarwal, Joanna Lin, Anson Zhou, Roxana Daneshjou, and Sanmi Koyejo
Aaron Fanous, Jacob Goldberg, Ank A. Agarwal, Joanna Lin, Anson Zhou, Roxana Daneshjou, and Sanmi Koyejo. SycEval: Evaluating llm sycophancy.arXiv preprint arXiv:2502.08177, 2025. 16
arXiv 2025
-
[23]
Good arguments against the people pleasers: How reasoning mitigates (yet masks) llm sycophancy
Zhaoxin Feng, Zheng Chen, Jianfei Ma, Yip Tin Po, Emmanuele Chersoni, and Bo Li. Good arguments against the people pleasers: How reasoning mitigates (yet masks) llm sycophancy. arXiv preprint arXiv:2603.16643, 2026
arXiv 2026
-
[24]
Iterative resolution of prompt ambiguities using a progressive cutting- search approach
Fabrizio Marozzo. Iterative resolution of prompt ambiguities using a progressive cutting- search approach. InArtificial Intelligence Applications and Innovations, volume 756 of IFIP Advances in Information and Communication Technology, pages 210–224, Cham, 2025. Springer
2025
-
[25]
Judging llm-as-a-judge with mt-bench and chatbot arena
Lianmin Zheng et al. Judging llm-as-a-judge with mt-bench and chatbot arena. InAdvances in Neural Information Processing Systems, volume 36, pages 46595–46623, 2023. 17
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.