FactorLibrary: From Polynomials to Circuits via Recursive Subgoals
Pith reviewed 2026-06-25 21:10 UTC · model grok-4.3
The pith
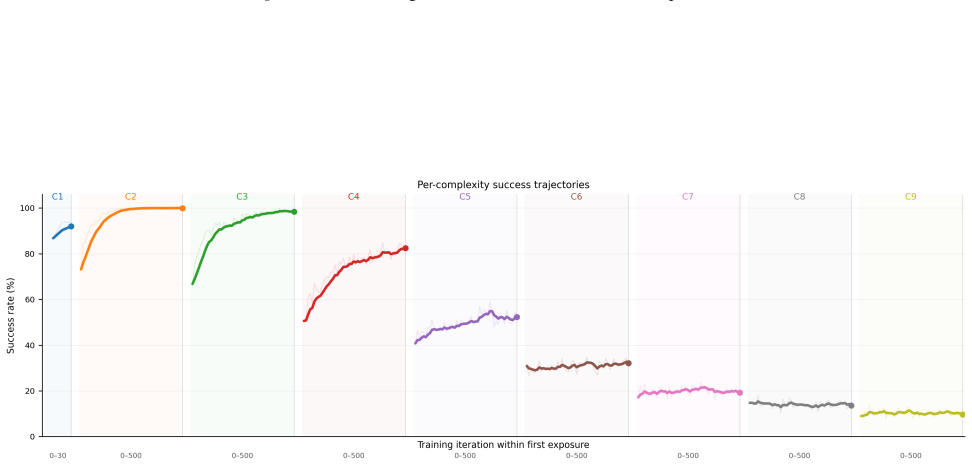
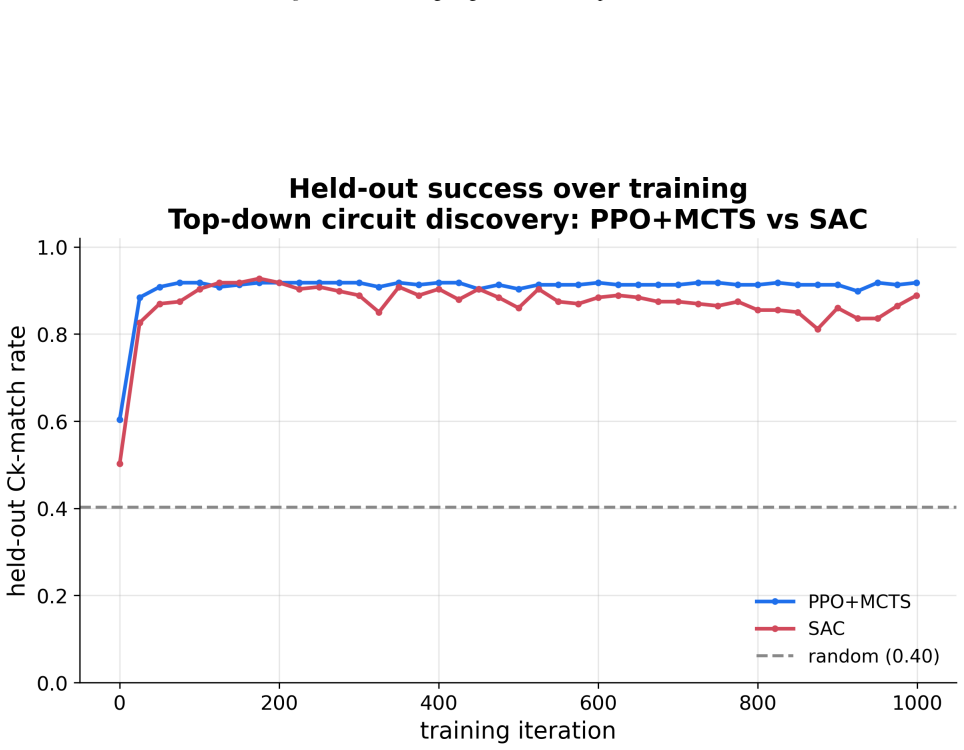
A top-down PPO+MCTS agent with FactorLibrary finds certified optimal arithmetic circuits for polynomials up to complexity 8 at 91.8 percent success.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
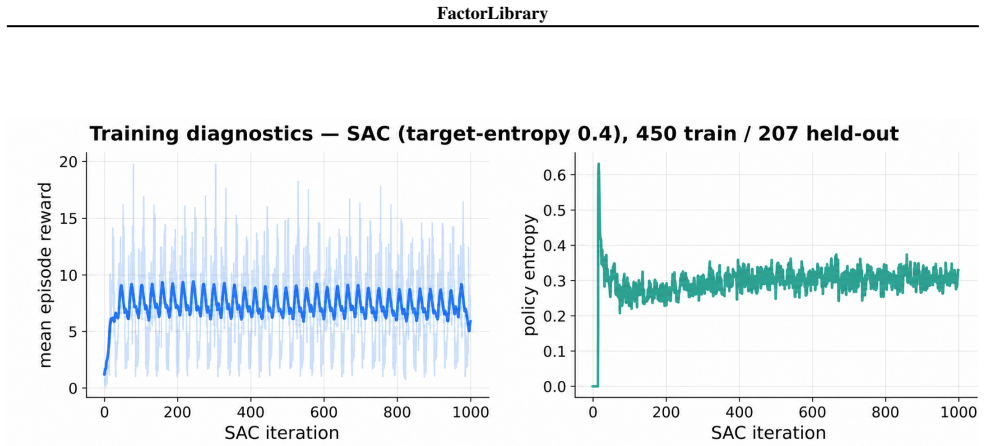
The central claim is that a top-down agent trained with PPO and MCTS, augmented by FactorLibrary for subgoal reuse, exhibits stable performance and locates certified optimal circuits for all tested polynomials whose complexity is at most 8, attaining a 91.8 percent success rate across the evaluation set.
What carries the argument
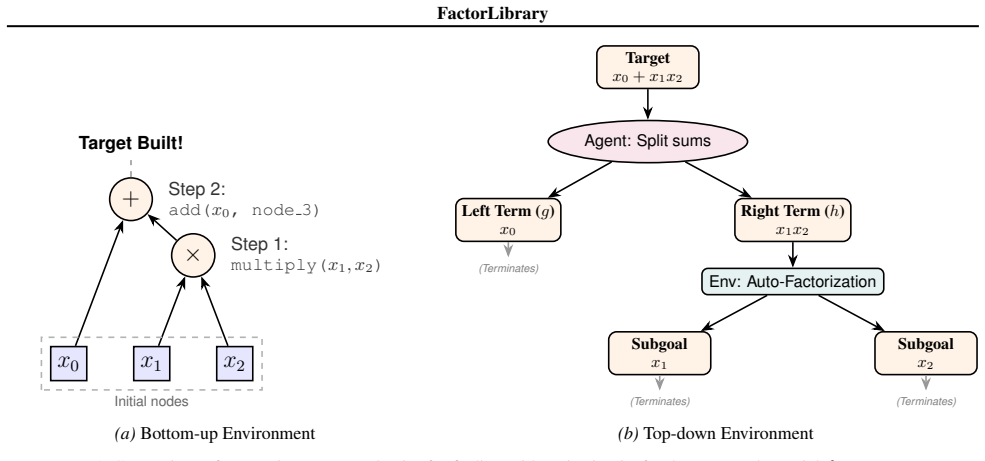
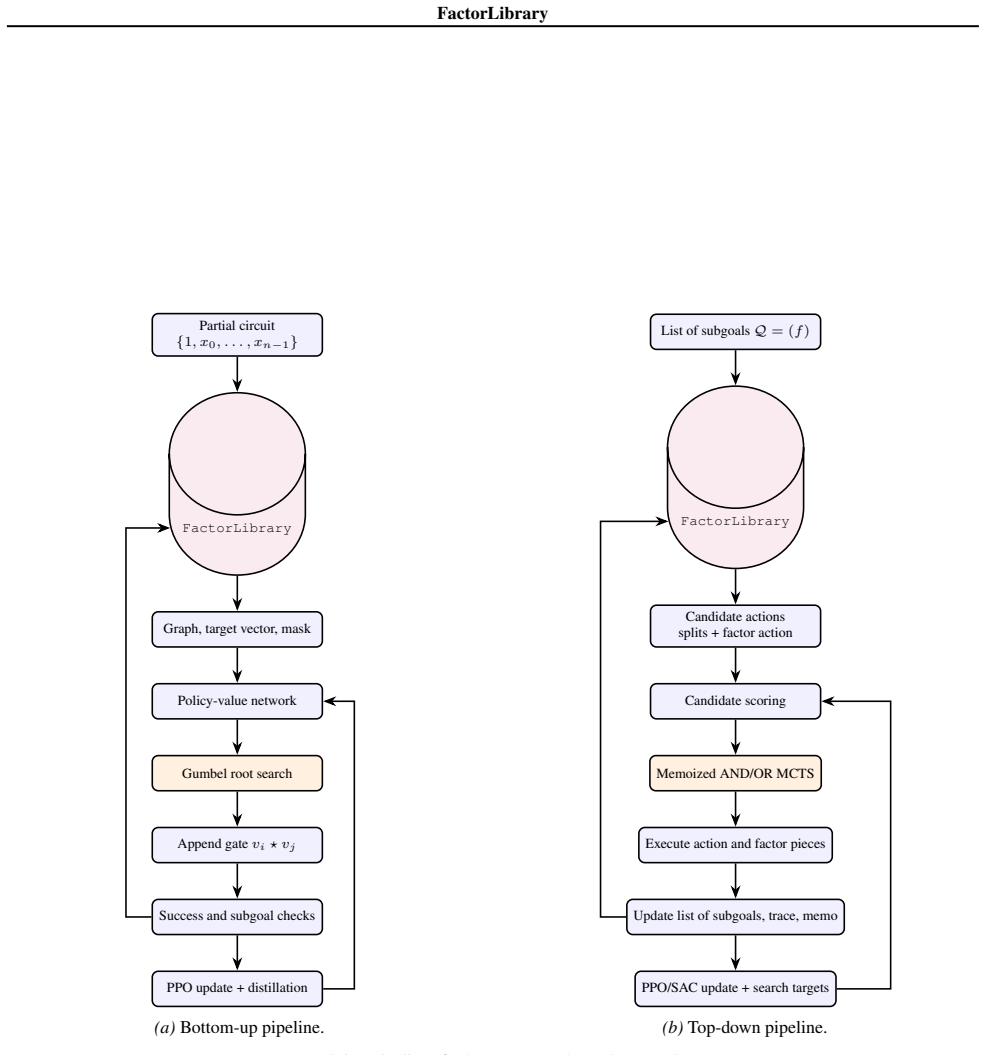
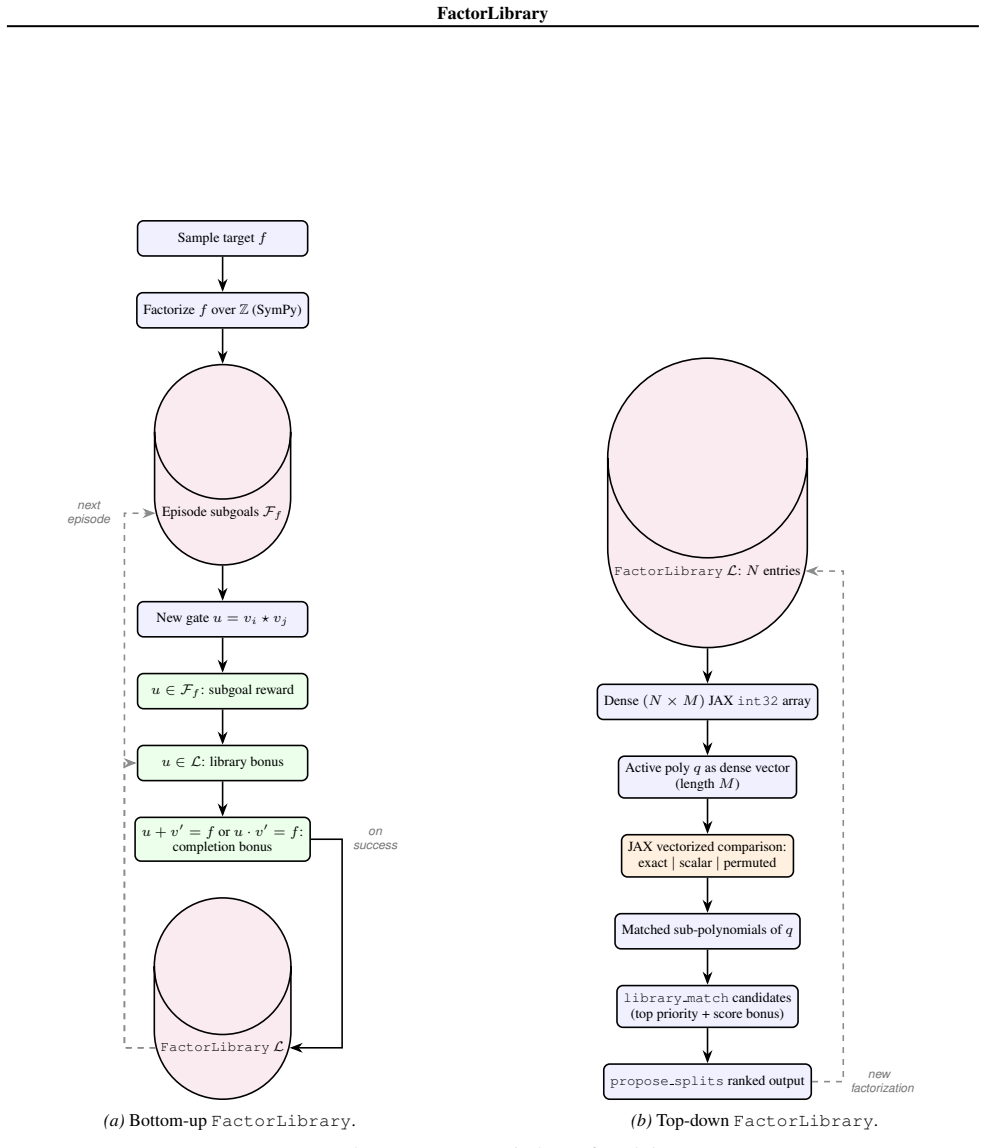
FactorLibrary, a persistent store of factorizable subexpressions that supplies reusable subgoals to the RL search process.
If this is right
- The top-down PPO+MCTS configuration outperforms both the bottom-up Gumbel-PPO-MCTS agent and the top-down SAC agent in stability.
- FactorLibrary reuse allows the search to reach certified optimality for all instances whose complexity is at most 8.
- Formulating circuit minimization as an RL task with persistent subgoals converts an intractable combinatorial enumeration into a trainable policy search.
- Success rates remain high only when the agent is allowed to exploit the learned subgoal distribution during search.
Where Pith is reading between the lines
- If the subgoal library can be grown incrementally without retraining from scratch, the same framework could be applied to successively larger complexity thresholds.
- The method supplies a concrete generator of minimal-circuit examples that could be used to test conjectures in algebraic complexity theory.
- Because the approach separates search from certification, any future improvement in either component can be plugged in without redesigning the other.
Load-bearing premise
The RL search guided by FactorLibrary never systematically overlooks a smaller circuit that lies outside the distribution of learned subgoals, and the separate certification step is complete for every instance examined.
What would settle it
An exhaustive check or independent proof that some polynomial of complexity 8 or less possesses a strictly smaller circuit than the one returned and certified by the agent would falsify the optimality claim.
Figures
read the original abstract
Finding minimal arithmetic circuits for polynomials over finite fields is a combinatorially hard problem central to algebraic complexity theory. We formulate it as a reinforcement learning problem in two directions, bottom-up and top-down. To address the challenge of a fast-growing combinatorial search space, we introduce FactorLibrary, which stores factorizable subexpressions that serve as reusable subgoals across training episodes. We trained a bottom-up agent with Gumbel-PPO-MCTS and two top-down agents with PPO+MCTS and SAC. The PPO+MCTS top-down agent exhibited the most stable performance, finding certified optimal circuits up to complexity $8$ with a success rate of $91.8\%$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript formulates the search for minimal arithmetic circuits realizing polynomials over finite fields as a reinforcement-learning task. It introduces FactorLibrary to cache reusable factorizable subexpressions as subgoals, trains a bottom-up Gumbel-PPO-MCTS agent and two top-down agents (PPO+MCTS and SAC), and reports that the PPO+MCTS top-down agent finds certified-optimal circuits of complexity up to 8 with 91.8 % success rate on a held-out test set.
Significance. If the optimality certification is shown to be exhaustive and the reported success rates are reproducible, the work supplies a concrete empirical baseline for circuit minimization that could be used to generate candidate minimal circuits for further theoretical study. The reusable-subgoal mechanism directly targets the combinatorial explosion that has limited prior search-based approaches.
major comments (2)
- [Abstract, §4] Abstract and §4 (Results): the central claim that circuits are 'certified optimal' is load-bearing for the 91.8 % figure, yet the manuscript supplies no description of the certification procedure, no statement of its completeness (exhaustive enumeration versus bounded search over the learned subgoal distribution), and no error analysis showing that smaller circuits outside the FactorLibrary distribution cannot exist undetected.
- [§3.2] §3.2 (Certification): if the optimality check re-uses the same learned subgoals or a bounded enumeration rather than a complete exhaustive search over all arithmetic circuits of lower complexity, then the reported success rate may reflect search bias rather than true minimality; this must be clarified with an explicit statement of the certification algorithm and its complexity.
minor comments (2)
- [§2] Notation for circuit complexity and field size should be defined once in §2 before first use in the abstract.
- [Figures] Figure captions should state the exact number of test polynomials and the precise definition of 'success' (exact match to a known minimal circuit or merely lower than a baseline).
Simulated Author's Rebuttal
We thank the referee for the careful review and for identifying the need to clarify the optimality certification procedure, which underpins the reported success rates. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Results): the central claim that circuits are 'certified optimal' is load-bearing for the 91.8 % figure, yet the manuscript supplies no description of the certification procedure, no statement of its completeness (exhaustive enumeration versus bounded search over the learned subgoal distribution), and no error analysis showing that smaller circuits outside the FactorLibrary distribution cannot exist undetected.
Authors: We agree that the manuscript does not currently contain a sufficient description of the certification procedure. In the revised version we will add an explicit account of the certification algorithm in §3.2, including a statement of its completeness (exhaustive enumeration via an independent dynamic-programming table over all circuits of lower complexity) and an error analysis confirming that no undetected smaller circuits exist outside the FactorLibrary distribution for the reported range. revision: yes
-
Referee: [§3.2] §3.2 (Certification): if the optimality check re-uses the same learned subgoals or a bounded enumeration rather than a complete exhaustive search over all arithmetic circuits of lower complexity, then the reported success rate may reflect search bias rather than true minimality; this must be clarified with an explicit statement of the certification algorithm and its complexity.
Authors: We will revise §3.2 to state explicitly that the optimality check performs a complete exhaustive enumeration of all arithmetic circuits of lower complexity using a recursive factorization procedure that is independent of both the learned policy and the FactorLibrary subgoals. The algorithm and its complexity (feasible for complexity ≤8) will be described in full, together with pseudocode, to remove any ambiguity about possible search bias. revision: yes
Circularity Check
No significant circularity; empirical success rate on held-out instances
full rationale
The paper's central claim is an empirical performance metric (91.8% success rate of PPO+MCTS top-down agent on certified optimal circuits up to complexity 8). This is measured on test instances after training, not derived from any equation or parameter that reduces to the input by construction. No self-definitional steps, fitted-input predictions, self-citation load-bearing arguments, uniqueness theorems, or ansatz smuggling appear in the abstract or described claims. The FactorLibrary and RL formulation are presented as engineering contributions whose value is assessed by external performance numbers rather than internal reduction. Certification completeness is a separate verification concern, not a circularity issue.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A general reinforcement learning algorithm that masters chess, shogi, and. Science , author =. 2018 , pages =. doi:10.1126/science.aar6404 , language =
-
[3]
International Conference on Learning Representations (ICLR) , year=
High-Dimensional Continuous Control Using Generalized Advantage Estimation , author=. International Conference on Learning Representations (ICLR) , year=
-
[4]
International Conference on Learning Representations (ICLR) , year=
Semi-Supervised Classification with Graph Convolutional Networks , author=. International Conference on Learning Representations (ICLR) , year=
-
[5]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Attention Is All You Need , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[6]
and Powley, Edward and Whitehouse, Daniel and Lucas, Simon M
Browne, Cameron B. and Powley, Edward and Whitehouse, Daniel and Lucas, Simon M. and Cowling, Peter I. and Rohlfshagen, Philipp and Tavener, Stephen and Perez, Diego and Samothrakis, Spyridon and Colton, Simon , journal=. A Survey of
-
[7]
Fawzi, Alhussein and Balog, Matej and Huang, Aja and Hubert, Thomas and Romera-Paredes, Bernardino and Barekatain, Mohammadamin and Novikov, Alexander and Ruiz, Francisco J. R. and Schrittwieser, Julian and Swirszcz, Grzegorz and Silver, David and Hassabis, Demis and Kohli, Pushmeet , title =. Nature, London , issn =. 2022 , language =. doi:10.1038/s41586...
-
[9]
2024 , eprint=
OpenTensor: Reproducing Faster Matrix Multiplication Discovering Algorithms , author=. 2024 , eprint=
2024
-
[10]
2018 , eprint=
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor , author=. 2018 , eprint=
2018
-
[11]
Algebraic complexity theory
B. Algebraic complexity theory. 1997 , publisher =
1997
-
[12]
Bandit Based Monte-Carlo Planning
Kocsis, Levente and Szepesv \'a ri, Csaba. Bandit Based Monte-Carlo Planning. Machine Learning: ECML 2006. 2006
2006
-
[13]
International Conference on Learning Representations , year=
Deep Learning For Symbolic Mathematics , author=. International Conference on Learning Representations , year=
-
[14]
2019 , eprint=
Soft Actor-Critic for Discrete Action Settings , author=. 2019 , eprint=
2019
-
[16]
2024 , eprint=
Completeness classes in algebraic complexity theory , author=. 2024 , eprint=
2024
-
[19]
Soft Actor-Critic (SAC) , year =
-
[20]
Hindsight Experience Replay , volume =
Andrychowicz, Marcin and Wolski, Filip and Ray, Alex and Schneider, Jonas and Fong, Rachel and Welinder, Peter and McGrew, Bob and Tobin, Josh and Pieter Abbeel, OpenAI and Zaremba, Wojciech , booktitle =. Hindsight Experience Replay , volume =
-
[21]
Policy Improvement by Planning with
Danihelka, Ivo and Guez, Arthur and Schrittwieser, Julian and Silver, David , booktitle =. Policy Improvement by Planning with. 2022 , url =
2022
-
[22]
and Precup, Doina and Singh, Satinder , journal =
Sutton, Richard S. and Precup, Doina and Singh, Satinder , journal =. Between. 1999 , doi =
1999
-
[23]
2017 , volume =
Vezhnevets, Alexander Sasha and Osindero, Simon and Schaul, Tom and Heess, Nicolas and Jaderberg, Max and Silver, David and Kavukcuoglu, Koray , booktitle =. 2017 , volume =
2017
-
[24]
1997 , isbn =
Lidl, Rudolf and Niederreiter, Harald , title =. 1997 , isbn =
1997
-
[25]
Macdonald, I. G. , title =. 1995 , isbn =
1995
-
[26]
IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems , volume =
Hosangadi, Anup and Fallah, Farzan and Kastner, Ryan , title =. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems , volume =. 2006 , doi =
2006
-
[27]
and Narasimhan, Karthik and Saeedi, Ardavan and Tenenbaum, Joshua B
Kulkarni, Tejas D. and Narasimhan, Karthik and Saeedi, Ardavan and Tenenbaum, Joshua B. , title =. Advances in Neural Information Processing Systems , volume =
-
[28]
Proceedings of the 35th International Conference on Machine Learning , pages =
Florensa, Carlos and Held, David and Geng, Xinyang and Abbeel, Pieter , title =. Proceedings of the 35th International Conference on Machine Learning , pages =. 2018 , editor =
2018
-
[29]
Advances in Neural Information Processing Systems , volume =
Anthony, Thomas and Tian, Zheng and Barber, David , title =. Advances in Neural Information Processing Systems , volume =
-
[30]
and Harada, Daishi and Russell, Stuart J
Ng, Andrew Y. and Harada, Daishi and Russell, Stuart J. , title =. Proceedings of the Sixteenth International Conference on Machine Learning , pages =. 1999 , publisher =
1999
-
[31]
2026 , eprint=
CircuitBuilder: From Polynomials to Circuits via Reinforcement Learning , author=. 2026 , eprint=
2026
-
[32]
European Conference on Machine Learning , pages =
Bandit Based Monte-Carlo Planning , author =. European Conference on Machine Learning , pages =. 2006 , publisher =
2006
-
[33]
Science , volume =
A General Reinforcement Learning Algorithm that Masters Chess, Shogi, and Go through Self-Play , author =. Science , volume =
-
[35]
International Conference on Machine Learning , pages =
Policy Invariance under Reward Transformations: Theory and Application to Reward Shaping , author =. International Conference on Machine Learning , pages =
-
[37]
International Conference on Learning Representations , year=
LILO: Learning Interpretable Libraries by Compressing and Documenting Code , author=. International Conference on Learning Representations , year=
-
[38]
SAT Competition 2020 , journal =
Nils Froleyks and Marijn Heule and Ashlin Iser and Matti Järvisalo and Martin Suda , keywords =. SAT Competition 2020 , journal =. 2021 , issn =. doi:https://doi.org/10.1016/j.artint.2021.103572 , url =
-
[40]
Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =
Kurin, Vitaly and Godil, Saad and Whiteson, Shimon and Catanzaro, Bryan , title =. Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =. 2020 , isbn =
2020
-
[41]
Learning local search heuristics for boolean satisfiability , year =
Yolcu, Emre and P\'. Learning local search heuristics for boolean satisfiability , year =. Proceedings of the 33rd International Conference on Neural Information Processing Systems , articleno =
-
[42]
Moro, Lorenzo and Paris, Matteo G. A. and Restelli, Marcello and Prati, Enrico , title =. Communications Physics , volume =. 2021 , doi =
2021
-
[43]
2021 , eprint=
Quantum circuit optimization with deep reinforcement learning , author=. 2021 , eprint=
2021
-
[44]
Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
LeanDojo: Theorem Proving with Retrieval-Augmented Language Models , author=. Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[45]
The Thirteenth International Conference on Learning Representations , year=
DeepSeek-Prover-V1.5: Harnessing Proof Assistant Feedback for Reinforcement Learning and Monte-Carlo Tree Search , author=. The Thirteenth International Conference on Learning Representations , year=
-
[46]
https://satcompetition.github.io/
SAT Competition . https://satcompetition.github.io/. Accessed 2026-06-19
2026
-
[47]
Hindsight experience replay
Andrychowicz, M., Wolski, F., Ray, A., Schneider, J., Fong, R., Welinder, P., McGrew, B., Tobin, J., Pieter Abbeel, O., and Zaremba, W. Hindsight experience replay. In Guyon, I., Luxburg, U. V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., and Garnett, R. (eds.), Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017
2017
-
[48]
Thinking fast and slow with deep learning and tree search
Anthony, T., Tian, Z., and Barber, D. Thinking fast and slow with deep learning and tree search. In Advances in Neural Information Processing Systems, volume 30, 2017
2017
-
[49]
B., Powley, E., Whitehouse, D., Lucas, S
Browne, C. B., Powley, E., Whitehouse, D., Lucas, S. M., Cowling, P. I., Rohlfshagen, P., Tavener, S., Perez, D., Samothrakis, S., and Colton, S. A survey of Monte Carlo tree search methods. IEEE Transactions on Computational Intelligence and AI in Games, 4 0 (1): 0 1--43, 2012
2012
-
[50]
B \"u rgisser, P., Clausen, M., and Shokrollahi, M. A. Algebraic complexity theory. With the collaboration of Thomas Lickteig , volume 315 of Grundlehren Math. Wiss. Berlin: Springer, 1997. ISBN 3-540-60582-7
1997
-
[51]
Soft actor-critic for discrete action settings
Christodoulou, P. Soft actor-critic for discrete action settings. arXiv preprint arXiv:1910.07207, 2019
arXiv 1910
-
[52]
Policy improvement by planning with Gumbel
Danihelka, I., Guez, A., Schrittwieser, J., and Silver, D. Policy improvement by planning with Gumbel . In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=bERaNdoegnO
2022
-
[53]
B., Solar-Lezama, A., and Tenenbaum, J
Ellis, K., Wong, C., Nye, M., Sablé-Meyer, M., Cary, L., Morales, L., Hewitt, L. B., Solar-Lezama, A., and Tenenbaum, J. B. Dreamcoder: Growing generalizable, interpretable knowledge with wake-sleep bayesian program learning. arXiv preprint arXiv:2006.08381, 2020
arXiv 2006
-
[54]
Automatic goal generation for reinforcement learning agents
Florensa, C., Held, D., Geng, X., and Abbeel, P. Automatic goal generation for reinforcement learning agents. In Dy, J. and Krause, A. (eds.), Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pp.\ 1515--1528. PMLR, 2018. URL https://proceedings.mlr.press/v80/florensa18a.html
2018
-
[55]
Fösel, T., Niu, M. Y., Marquardt, F., and Li, L. Quantum circuit optimization with deep reinforcement learning, 2021. URL https://arxiv.org/abs/2103.07585
arXiv 2021
-
[56]
X., Liu, M., Tenenbaum, J
Grand, G., Wong, L., Bowers, M., Olausson, T. X., Liu, M., Tenenbaum, J. B., and Andreas, J. Lilo: Learning interpretable libraries by compressing and documenting code. In International Conference on Learning Representations, 2024
2024
-
[57]
Haarnoja, T., Zhou, A., Abbeel, P., and Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor, 2018. URL https://arxiv.org/abs/1801.01290
Pith/arXiv arXiv 2018
-
[58]
Horner, W. G. Xxi. a new method of solving numerical equations of all orders, by continuous approximation. Philosophical Transactions of the Royal Society of London, 109: 0 308--335, 12 1819. ISSN 0261-0523. doi:10.1098/rstl.1819.0023. URL https://doi.org/10.1098/rstl.1819.0023
-
[59]
Optimizing polynomial expressions by algebraic factorization and common subexpression elimination
Hosangadi, A., Fallah, F., and Kastner, R. Optimizing polynomial expressions by algebraic factorization and common subexpression elimination. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 25 0 (10): 0 2012--2022, 2006. doi:10.1109/TCAD.2006.875712
-
[60]
Hubert, T., Mehta, R., Sartran, L., Horváth, M. Z., Žužić, G., Wieser, E., Huang, A., Schrittwieser, J., Schroecker, Y., Masoom, H., Bertolli, O., Zahavy, T., Mandhane, A., Yung, J., Beloshapka, I., Ibarz, B., Veeriah, V., Yu, L., Nash, O., Lezeau, P., Mercuri, S., Sönne, C., Mehta, B., Davies, A., Zheng, D., Pedregosa, F., Li, Y., von Glehn, I., Rowland,...
-
[61]
and Szepesv \'a ri, C
Kocsis, L. and Szepesv \'a ri, C. Bandit based monte-carlo planning. In European Conference on Machine Learning, pp.\ 282--293. Springer, 2006
2006
-
[62]
D., Narasimhan, K., Saeedi, A., and Tenenbaum, J
Kulkarni, T. D., Narasimhan, K., Saeedi, A., and Tenenbaum, J. B. Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation. In Advances in Neural Information Processing Systems, volume 29, 2016
2016
-
[63]
Kurin, V., Godil, S., Whiteson, S., and Catanzaro, B. Can q-learning with graph networks learn a generalizable branching heuristic for a sat solver? In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS '20, Red Hook, NY, USA, 2020. Curran Associates Inc. ISBN 9781713829546
2020
-
[64]
and Niederreiter, H
Lidl, R. and Niederreiter, H. Finite Fields, volume 20 of Encyclopedia of Mathematics and Its Applications. Cambridge University Press, Cambridge, 2 edition, 1997. ISBN 9780521392310
1997
-
[65]
Moro, L., Paris, M. G. A., Restelli, M., and Prati, E. Quantum compiling by deep reinforcement learning. Communications Physics, 4 0 (178), 2021. doi:10.1038/s42005-021-00684-3. URL https://doi.org/10.1038/s42005-021-00684-3
-
[66]
High-dimensional continuous control using generalized advantage estimation
Schulman, J., Moritz, P., Levine, S., Jordan, M., and Abbeel, P. High-dimensional continuous control using generalized advantage estimation. In International Conference on Learning Representations (ICLR), 2016
2016
-
[67]
Proximal policy optimization algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[68]
Shpilka, A. and Yehudayoff, A. Arithmetic circuits: A survey of recent results and open questions. Foundations and Trends in Theoretical Computer Science, 5 0 (3-4): 0 207--388, 12 2010. ISSN 1551-305X. doi:10.1561/0400000039. URL https://doi.org/10.1561/0400000039
-
[69]
A general reinforcement learning algorithm that masters chess, shogi, and go through self-play
Silver, D., Hubert, T., Schrittwieser, J., Antonoglou, I., Lai, M., Guez, A., Lanctot, M., Sifre, L., Kumaran, D., Graepel, T., Lillicrap, T., Simonyan, K., and Hassabis, D. A general reinforcement learning algorithm that masters chess, shogi, and go through self-play. Science, 362 0 (6419): 0 1140--1144, 2018
2018
-
[70]
The complexity of computing the permanent
Valiant, L. The complexity of computing the permanent. Theoretical Computer Science, 8 0 (2): 0 189--201, 1979 a . ISSN 0304-3975. doi:10.1016/0304-3975(79)90044-6
-
[71]
Valiant, L. G. Completeness classes in algebra. In Proceedings of the Eleventh Annual ACM Symposium on Theory of Computing, STOC '79, pp.\ 249–261, New York, NY, USA, 1979 b . Association for Computing Machinery. ISBN 9781450374385. doi:10.1145/800135.804419. URL https://doi.org/10.1145/800135.804419
-
[72]
Deepseek-prover-v1.5: Harnessing proof assistant feedback for reinforcement learning and monte-carlo tree search
Xin, H., Ren, Z., Song, J., Shao, Z., Zhao, W., Wang, H., Liu, B., Zhang, L., Lu, X., Du, Q., Gao, W., Zhang, H., Zhu, Q., Yang, D., Gou, Z., Wu, Z., Luo, F., and Ruan, C. Deepseek-prover-v1.5: Harnessing proof assistant feedback for reinforcement learning and monte-carlo tree search. In The Thirteenth International Conference on Learning Representations,...
2025
-
[73]
M., Gu, A., Chalamala, R., Song, P., Yu, S., Godil, S., Prenger, R., and Anandkumar, A
Yang, K., Swope, A. M., Gu, A., Chalamala, R., Song, P., Yu, S., Godil, S., Prenger, R., and Anandkumar, A. Leandojo: Theorem proving with retrieval-augmented language models. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023. URL https://openreview.net/forum?id=g7OX2sOJtn
2023
-
[74]
and P\' o czos, B
Yolcu, E. and P\' o czos, B. Learning local search heuristics for boolean satisfiability. Curran Associates Inc., Red Hook, NY, USA, 2019
2019
-
[75]
K., Pandey, R., Mehta, B., Jin, K., Morato, N., Ganapule, A., Zeng, M
Zhang, W. K., Pandey, R., Mehta, B., Jin, K., Morato, N., Ganapule, A., Zeng, M. R., and Alper, J. Circuitbuilder: From polynomials to circuits via reinforcement learning, 2026. URL https://arxiv.org/abs/2603.17075
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.