Can In-Context Learning Support Intrinsic Curiosity?
Pith reviewed 2026-06-26 21:20 UTC · model grok-4.3
The pith
In general MDPs, in-context learning cannot provide unbiased intrinsic rewards for curiosity, but it succeeds in non-temporal active learning settings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In general Markov decision processes, intrinsic rewards derived from an in-context learner's prediction errors either suffer from nuisance terms that bias their estimation of true learning progress, or they cannot be implemented using an in-context learner's prediction errors. Conversely, in a broad subclass of non-temporal settings encompassing active learning and Bayesian experimental design, ICL-derived rewards successfully bound and asymptotically converge to the true learning progress.
What carries the argument
Prediction errors of an in-context learner under counterfactual context manipulations, used to estimate learning progress without gradient updates.
If this is right
- Exploration policies can be trained to maximize learning progress using only ICL prediction errors in non-temporal domains.
- No inner loops of gradient descent are required to compute curiosity rewards in active learning and experimental design.
- The resulting policies achieve optimal data collection in both continuous and symbolic environments.
Where Pith is reading between the lines
- The bias in temporal settings may require hybrid signals that combine ICL with explicit update-based terms.
- The positive result opens a route to scale curiosity-driven data selection inside large sequence models for static selection tasks.
- Similar ICL-based bounds might apply to other progress measures beyond prediction error.
Load-bearing premise
That the in-context learner's prediction errors can be directly manipulated via counterfactual context changes without introducing additional bias terms that cannot be corrected.
What would settle it
An experiment in a simple MDP showing that a policy trained on ICL-derived rewards collects data that yields strictly worse world-model predictions than a policy using the true learning-progress signal, or an active-learning task where the ICL rewards fail to converge to the optimal selection policy.
Figures

read the original abstract
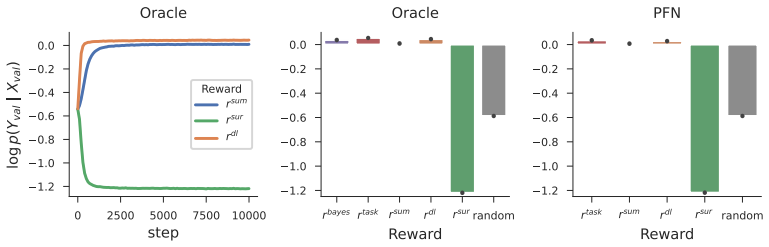
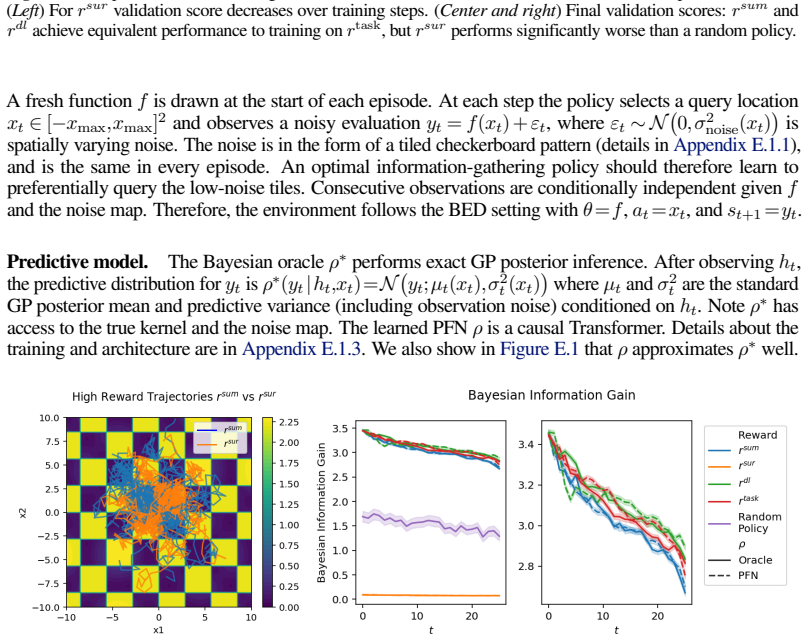
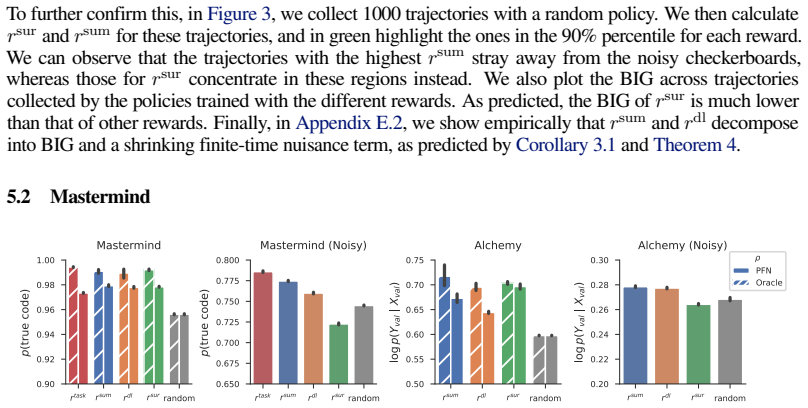
Effective machine learning depends not only on how we model data, but also on what data we choose to collect. While large sequence models have revolutionized data modeling, the problem of automated data selection, or "intrinsic curiosity", remains a significant challenge. Classic approaches incentivize exploration by rewarding an agent based on its "learning progress", which measures how much a newly acquired observation improves a world model's predictive ability. However, evaluating these rewards traditionally requires expensive inner loops of gradient descent updates within each trajectory, rendering them computationally impractical at scale. In this work, we investigate whether the emergent in-context learning (ICL) capabilities of sequence models can eliminate this bottleneck by serving as immediate, update-free world models. Specifically, we evaluate whether an exploration policy can be trained to maximize learning progress, using solely the prediction errors and counterfactual context manipulations of an in-context learner. We first prove that in general Markov decision processes, this is in fact impossible in an unbiased way: the resulting intrinsic rewards either suffer from nuisance terms that bias their estimation of true learning progress, or they cannot be implemented using an in-context learner's prediction errors. Conversely, we prove a positive result for a broad subclass of non-temporal settings, encompassing active learning and Bayesian Experimental Design: here, ICL-derived rewards successfully bound and asymptotically converge to the true learning progress. We corroborate our theory with controlled experiments across continuous and symbolic environments, demonstrating that our ICL-driven framework successfully trains curious data-collection policies that explore optimally.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in-context learning (ICL) from sequence models cannot yield unbiased intrinsic rewards for learning progress in general Markov decision processes, as the resulting signals either contain uncorrectable nuisance bias terms or cannot be realized via the model's prediction errors and counterfactual context changes. It proves a positive result for a broad class of non-temporal problems (including active learning and Bayesian experimental design), where ICL-derived rewards provably bound and asymptotically converge to true learning progress. The theory is corroborated by controlled experiments in continuous and symbolic environments showing that ICL-driven policies explore optimally.
Significance. If the separation between the impossibility result for temporal MDPs and the convergence result for non-temporal settings holds, the work supplies a precise theoretical boundary on when emergent ICL capabilities can replace expensive inner-loop gradient updates for curiosity-driven data selection. The formal proofs (negative and positive) and the explicit identification of nuisance terms constitute a substantive contribution to the literature on intrinsic motivation and scalable exploration.
major comments (2)
- [Impossibility result for MDPs (statement and proof)] The impossibility theorem for general MDPs rests on the claim that counterfactual context manipulations cannot be performed without introducing bias terms beyond the identified nuisance factors. The derivation of this claim (and the precise conditions under which the bias is uncorrectable) must be checked against the weakest assumption noted in the reader's report; if the manipulation step is not fully formalized, the negative result is not yet load-bearing.
- [Positive result for non-temporal settings (theorem statement)] The positive convergence claim for non-temporal settings asserts that ICL prediction errors asymptotically match true learning progress. The rate and the precise sense of convergence (e.g., almost-sure, in expectation, or in probability) should be stated explicitly, together with any dependence on the size of the in-context window or the model class.
minor comments (2)
- [Introduction and abstract] Notation for the intrinsic reward constructed from ICL errors should be introduced once and used consistently; several passages in the abstract and introduction use slightly varying descriptions of the same quantity.
- [Experiments] The experimental section would benefit from an explicit statement of the number of random seeds and the precise definition of 'optimally' in the reported exploration performance.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation of minor revision. We address each major comment below with clarifications and planned revisions to strengthen the formal statements.
read point-by-point responses
-
Referee: The impossibility theorem for general MDPs rests on the claim that counterfactual context manipulations cannot be performed without introducing bias terms beyond the identified nuisance factors. The derivation of this claim (and the precise conditions under which the bias is uncorrectable) must be checked against the weakest assumption noted in the reader's report; if the manipulation step is not fully formalized, the negative result is not yet load-bearing.
Authors: We appreciate the referee's scrutiny of the negative result. The impossibility theorem (Theorem 3) is derived under the weakest assumption that the ICL model receives only the observed sequence without direct access to the underlying MDP transition kernel or external state information. Counterfactual context changes are formalized in Definition 2 and the subsequent proof, which shows that any correction for nuisance bias requires either gradient updates or information outside the in-context window. We will add an explicit remark after the theorem stating the minimal assumptions and the precise conditions rendering the bias uncorrectable, to make the formalization fully load-bearing. revision: yes
-
Referee: The positive convergence claim for non-temporal settings asserts that ICL prediction errors asymptotically match true learning progress. The rate and the precise sense of convergence (e.g., almost-sure, in expectation, or in probability) should be stated explicitly, together with any dependence on the size of the in-context window or the model class.
Authors: We agree that the positive result (Theorem 4) can be stated more precisely. The current proof establishes convergence in expectation as the number of in-context examples tends to infinity. We will revise the theorem to specify convergence in probability at rate O(1/sqrt(n)) for universal model classes, with the result holding for any fixed in-context window size under the non-temporal assumption (no dependence on window length beyond a minimum threshold). These details will be added to the theorem statement and proof sketch. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper's central claims consist of formal mathematical proofs establishing impossibility results for general MDPs (due to nuisance bias or non-implementability) and positive convergence results for non-temporal subclasses. These derivations rely on direct analysis of prediction errors and counterfactual manipulations rather than any fitted parameters, self-definitional reductions, or load-bearing self-citations. No step reduces the target result to its own inputs by construction, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Standard MDP formulation and definition of learning progress as improvement in predictive ability
- domain assumption In-context learner can perform counterfactual context manipulations
Reference graph
Works this paper leans on
-
[1]
Conference on Learning Theory , pages=
Active learning for identification of linear dynamical systems , author=. Conference on Learning Theory , pages=. 2020 , organization=
2020
-
[2]
, title =
Schiff, Joel L. , title =
-
[3]
arXiv preprint arXiv:1905.03030 , year=
Meta-learning of sequential strategies , author=. arXiv preprint arXiv:1905.03030 , year=
Pith/arXiv arXiv 1905
-
[4]
2025 , journal=
MesaNet: Sequence Modeling by Locally Optimal Test-Time Training , author=. 2025 , journal=
2025
-
[5]
2024 , journal=
Uncovering mesa-optimization algorithms in Transformers , author=. 2024 , journal=
2024
-
[6]
Schmidhuber, J \"u rgen. Driven by Compression Progress: A Simple Principle Explains Essential Aspects of Subjective Beauty, Novelty, Surprise, Interestingness, Attention, Curiosity, Creativity, Art, Science, Music, Jokes. Anticipatory Behavior in Adaptive Learning Systems. 2009
2009
-
[7]
Formal Theory of Creativity, Fun, and Intrinsic Motivation (1990–2010) , year=
Schmidhuber, Jürgen , journal=. Formal Theory of Creativity, Fun, and Intrinsic Motivation (1990–2010) , year=
1990
-
[8]
Proceedings of the international conference on artificial neural networks, Paris , volume=
Reinforcement driven information acquisition in non-deterministic environments , author=. Proceedings of the international conference on artificial neural networks, Paris , volume=
-
[9]
Curious model-building control systems , author=. Proc. international joint conference on neural networks , pages=
-
[10]
, journal=
Oudeyer, Pierre-Yves and Kaplan, Frdric and Hafner, Verena V. , journal=. Intrinsic Motivation Systems for Autonomous Mental Development , year=
-
[11]
the 8th international conference on epigenetic robotics: Modeling cognitive development in robotic systems , year=
How can we define intrinsic motivation? , author=. the 8th international conference on epigenetic robotics: Modeling cognitive development in robotic systems , year=
-
[12]
Frontiers in neurorobotics , volume=
What is intrinsic motivation? A typology of computational approaches , author=. Frontiers in neurorobotics , volume=. 2007 , publisher=
2007
-
[13]
Advances in neural information processing systems , volume=
Exploration in model-based reinforcement learning by empirically estimating learning progress , author=. Advances in neural information processing systems , volume=
-
[14]
arXiv preprint arXiv:1902.07685 , year=
World discovery models , author=. arXiv preprint arXiv:1902.07685 , year=
Pith/arXiv arXiv 1902
-
[15]
The Bell system technical journal , volume=
A mathematical theory of communication , author=. The Bell system technical journal , volume=. 1948 , publisher=
1948
-
[16]
Schmidhuber, Juergen , isbn =. A Possibility for Implementing Curiosity and Boredom in Model-Building Neural Controllers , booktitle =. 1991 , month =. doi:10.7551/mitpress/3115.003.0030 , url =
-
[17]
arXiv preprint arXiv:2506.06725 , year=
WorldLLM: Improving LLMs' world modeling using curiosity-driven theory-making , author=. arXiv preprint arXiv:2506.06725 , year=
-
[18]
Intrinsically motivated model learning for a developing curious agent , year=
Hester, Todd and Stone, Peter , booktitle=. Intrinsically motivated model learning for a developing curious agent , year=
-
[19]
International Conference on Machine Learning , pages=
Provably efficient maximum entropy exploration , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[20]
Advances in neural information processing systems , volume=
Intrinsically motivated reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[21]
Journal of Computer and System Sciences , volume=
An analysis of model-based interval estimation for Markov decision processes , author=. Journal of Computer and System Sciences , volume=. 2008 , publisher=
2008
-
[22]
Advances in neural information processing systems , volume=
Unifying count-based exploration and intrinsic motivation , author=. Advances in neural information processing systems , volume=
-
[23]
International conference on machine learning , pages=
Count-based exploration with neural density models , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[24]
Frontiers in Psychology , volume =
Barto, Andrew and Mirolli, Marco and Baldassarre, Gianluca , month = dec, year =. Novelty or Surprise? , volume =. Frontiers in Psychology , publisher =. doi:10.3389/fpsyg.2013.00907 , language =
-
[25]
International conference on machine learning , pages=
Curiosity-driven exploration by self-supervised prediction , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[26]
2019 , editor =
Kim, Hyoungseok and Kim, Jaekyeom and Jeong, Yeonwoo and Levine, Sergey and Song, Hyun Oh , booktitle =. 2019 , editor =
2019
-
[27]
International Conference on Learning Representations , year=
Large-Scale Study of Curiosity-Driven Learning , author=. International Conference on Learning Representations , year=
-
[28]
International conference on artificial general intelligence , pages=
Planning to be surprised: Optimal bayesian exploration in dynamic environments , author=. International conference on artificial general intelligence , pages=. 2011 , organization=
2011
-
[29]
Frontiers in neural circuits , volume=
Learning and exploration in action-perception loops , author=. Frontiers in neural circuits , volume=. 2013 , publisher=
2013
-
[30]
Vision research , volume=
Bayesian surprise attracts human attention , author=. Vision research , volume=. 2009 , publisher=
2009
-
[31]
Advances in neural information processing systems , volume=
Vime: Variational information maximizing exploration , author=. Advances in neural information processing systems , volume=
-
[32]
arXiv preprint arXiv:1507.00814 , year=
Incentivizing exploration in reinforcement learning with deep predictive models , author=. arXiv preprint arXiv:1507.00814 , year=
-
[33]
The Moment Problem , series =
Schm. The Moment Problem , series =
-
[34]
Neural Computation , volume=
Information-based objective functions for active data selection , author=. Neural Computation , volume=
-
[35]
Fedorov, Valerii , year =
-
[36]
arXiv preprint arXiv:1112.5745 , year=
Bayesian active learning for classification and preference learning , author=. arXiv preprint arXiv:1112.5745 , year=
-
[37]
Colloques Internationaux du Centre National de la Recherche Scientifique , volume=
Application of the theory of martingales , author=. Colloques Internationaux du Centre National de la Recherche Scientifique , volume=. 1949 , organization=
1949
-
[38]
The Annals of Mathematical Statistics , volume=
On a measure of the information provided by an experiment , author=. The Annals of Mathematical Statistics , volume=. 1956 , publisher=
1956
-
[39]
Journal of artificial intelligence research , volume=
Adapting behavior via intrinsic reward: A survey and empirical study , author=. Journal of artificial intelligence research , volume=
-
[40]
2005 ieee congress on evolutionary computation , volume=
Empowerment: A universal agent-centric measure of control , author=. 2005 ieee congress on evolutionary computation , volume=. 2005 , organization=
2005
-
[41]
European Conference on Artificial Life , pages=
All else being equal be empowered , author=. European Conference on Artificial Life , pages=. 2005 , organization=
2005
-
[42]
Salge, Christoph and Glackin, Cornelius and Polani, Daniel. Empowerment--An Introduction. Guided Self-Organization: Inception. 2014. doi:10.1007/978-3-642-53734-9_4
-
[43]
Advances in neural information processing systems , volume=
Variational information maximisation for intrinsically motivated reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[44]
What can
Yuqing Du and Eliza Kosoy and Alyssa Li Dayan and Maria Rufova and Alison Gopnik and Pieter Abbeel , booktitle=. What can. 2023 , url=
2023
-
[45]
International conference on machine learning , pages=
Planning to explore via self-supervised world models , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[46]
International conference on machine learning , pages=
Model-based active exploration , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[47]
(No Title) , year=
Why greatness cannot be planned: The myth of the objective , author=. (No Title) , year=
-
[48]
arXiv preprint arXiv:2408.06292 , year=
The ai scientist: Towards fully automated open-ended scientific discovery , author=. arXiv preprint arXiv:2408.06292 , year=
-
[49]
Proceedings of the 41st International Conference on Machine Learning , pages =
Position: Open-Endedness is Essential for Artificial Superhuman Intelligence , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
2024
-
[50]
2024 , url=
Jenny Zhang and Joel Lehman and Kenneth Stanley and Jeff Clune , booktitle=. 2024 , url=
2024
-
[51]
Second Agent Learning in Open-Endedness Workshop , year=
Quality diversity through human feedback , author=. Second Agent Learning in Open-Endedness Workshop , year=
-
[52]
Quality-Diversity through
Herbie Bradley and Andrew Dai and Hannah Benita Teufel and Jenny Zhang and Koen Oostermeijer and Marco Bellagente and Jeff Clune and Kenneth Stanley and Gregory Schott and Joel Lehman , booktitle=. Quality-Diversity through. 2024 , url=
2024
-
[53]
Transactions on Machine Learning Research , issn=
Voyager: An Open-Ended Embodied Agent with Large Language Models , author=. Transactions on Machine Learning Research , issn=. 2024 , url=
2024
-
[54]
arXiv preprint arXiv:1901.01753 , year=
Paired open-ended trailblazer (poet): Endlessly generating increasingly complex and diverse learning environments and their solutions , author=. arXiv preprint arXiv:1901.01753 , year=
Pith/arXiv arXiv 1901
-
[55]
Entropy , volume=
An information-theoretic perspective on intrinsic motivation in reinforcement learning: A survey , author=. Entropy , volume=. 2023 , publisher=
2023
-
[56]
Forty-second International Conference on Machine Learning , year=
In-Context Learning and Occam's Razor , author=. Forty-second International Conference on Machine Learning , year=
-
[57]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[58]
Proceedings of the 41st International Conference on Machine Learning , pages =
Learning Universal Predictors , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
2024
-
[59]
Advances in neural information processing systems , volume=
Meta-trained agents implement bayes-optimal agents , author=. Advances in neural information processing systems , volume=
-
[60]
International Conference on Learning Representations , year=
An Explanation of In-context Learning as Implicit Bayesian Inference , author=. International Conference on Learning Representations , year=
-
[61]
International Conference on Learning Representations , year=
Transformers Can Do Bayesian Inference , author=. International Conference on Learning Representations , year=
-
[62]
Behavioral and Brain Sciences , volume=
Meta-learned models of cognition , author=. Behavioral and Brain Sciences , volume=. 2024 , publisher=
2024
-
[63]
International Conference on Machine Learning , pages=
Statistical foundations of prior-data fitted networks , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[64]
Proceedings of the 40th International Conference on Machine Learning , pages =
Transformers Learn In-Context by Gradient Descent , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
2023
-
[65]
arXiv preprint arXiv:1611.02779 , year=
RL ^2 : Fast reinforcement learning via slow reinforcement learning , author=. arXiv preprint arXiv:1611.02779 , year=
-
[66]
arXiv preprint arXiv:2207.01848 , year=
Tabpfn: A transformer that solves small tabular classification problems in a second , author=. arXiv preprint arXiv:2207.01848 , year=
-
[67]
The Eleventh International Conference on Learning Representations , year=
In-context Reinforcement Learning with Algorithm Distillation , author=. The Eleventh International Conference on Learning Representations , year=
-
[68]
Advances in Neural Information Processing Systems , volume=
Supervised pretraining can learn in-context reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[69]
Advances in Neural Information Processing Systems , volume=
The description length of deep learning models , author=. Advances in Neural Information Processing Systems , volume=
-
[70]
arXiv preprint arXiv:2601.03220 , year=
From Entropy to Epiplexity: Rethinking Information for Computationally Bounded Intelligence , author=. arXiv preprint arXiv:2601.03220 , year=
-
[71]
Proceedings of the National Academy of Sciences , volume=
Benign overfitting in linear regression , author=. Proceedings of the National Academy of Sciences , volume=. 2020 , publisher=
2020
-
[72]
arXiv preprint arXiv:2009.07624 , year=
Measuring information transfer in neural networks , author=. arXiv preprint arXiv:2009.07624 , year=
arXiv 2009
-
[73]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[74]
Cognition , volume=
Children are more exploratory and learn more than adults in an approach-avoid task , author=. Cognition , volume=. 2022 , publisher=
2022
-
[75]
Philosophical Transactions of the Royal Society B , volume=
Childhood as a solution to explore--exploit tensions , author=. Philosophical Transactions of the Royal Society B , volume=. 2020 , publisher=
2020
-
[76]
Developmental science , volume=
Preschool children learn about causal structure from conditional interventions , author=. Developmental science , volume=. 2007 , publisher=
2007
-
[77]
Byrnes, Steven , month = feb, year =. [
-
[78]
2024 , eprint=
Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models , author=. 2024 , eprint=
2024
-
[79]
2021 , journal=
Alchemy: A structured task distribution for meta-reinforcement learning , author=. 2021 , journal=
2021
-
[80]
arXiv preprint arXiv:2508.10142 , year=
Multi-turn puzzles: Evaluating interactive reasoning and strategic dialogue in llms , author=. arXiv preprint arXiv:2508.10142 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.