The Expense of Seeing: Attaining Trustworthy Multimodal Reasoning Within the Monolithic Paradigm
Pith reviewed 2026-05-22 10:31 UTC · model grok-4.3
The pith
Vision-language models often bypass visual inputs by exploiting language priors, and this visual bottleneck may worsen as language models scale.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
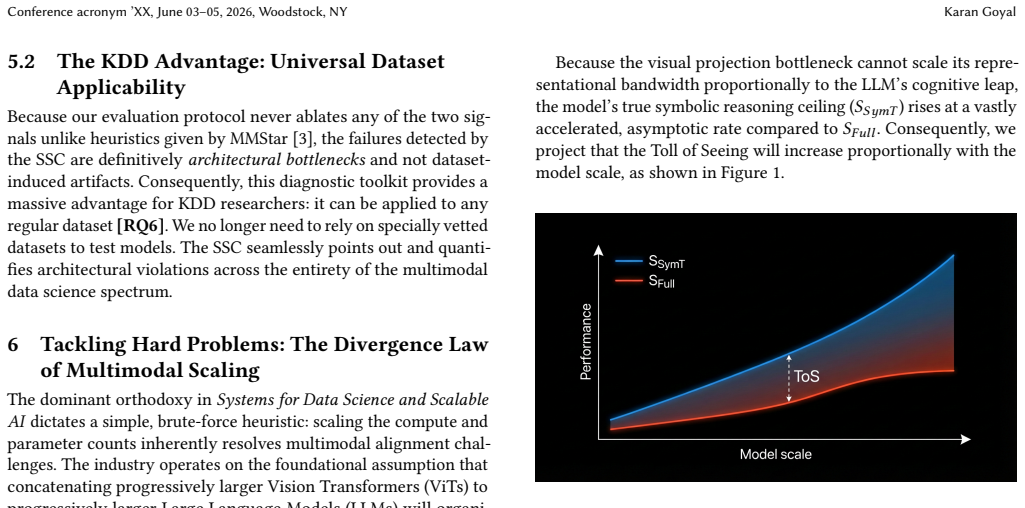
State-of-the-art vision-language models frequently exhibit functional blindness by exploiting strong language priors to bypass severe visual representation bottlenecks rather than extracting grounded knowledge from visual inputs. The Modality Translation Protocol quantifies what is termed the Expense of Seeing by translating semantic payloads, yielding the Toll of Seeing, Curse of Seeing, and Fallacy of Seeing metrics that together establish the Semantic Sufficiency Criterion. The paper further hypothesizes a Divergence Law of Multimodal Scaling in which the penalty of the visual knowledge bottleneck may increase as underlying language engines grow more capable.
What carries the argument
The Modality Translation Protocol, which translates semantic payloads across modalities instead of ablating them to isolate visual representation deficiencies from language biases and compute the Expense of Seeing.
If this is right
- Multimodal evaluation should shift from measuring multimodal gain to checking whether models meet the Semantic Sufficiency Criterion.
- Scaling language models alone will not close the visual integration gap and may widen it according to the Divergence Law.
- Architectures should be redesigned with the Semantic Sufficiency Criterion as an active requirement for trustworthy reasoning.
- Training and benchmarking practices must avoid conflating dataset biases with model limitations by using translation-based protocols.
Where Pith is reading between the lines
- The protocol could be applied to diagnose which specific visual encoder layers fail to carry semantic content in current models.
- Enforcing the Semantic Sufficiency Criterion during training might produce models that resist language-only shortcuts on adversarial examples.
- Similar translation-based measurement could be adapted to other modality pairs such as audio and text to check for analogous bottlenecks.
Load-bearing premise
Translating semantic payloads between modalities rather than ablating information successfully separates architectural incapacity from dataset biases and thereby measures the true expense of seeing.
What would settle it
A test that improves only the visual encoder while holding the language model fixed and checks whether the Toll, Curse, and Fallacy of Seeing metrics decrease in step with gains on tasks that demand visual grounding without language shortcuts.
Figures
read the original abstract
The rapid proliferation of Vision-Language Models (VLMs) is often framed as enabling unified multimodal knowledge discovery but rests on an under-examined assumption: that current VLMs faithfully synthesise multimodal data. We argue they often do not, and this gap reflects a trustworthiness problem in the dominant Vision Encoder-Projector-LLM paradigm. Rather than extracting grounded knowledge from visual inputs, state-of-the-art models frequently exhibit functional blindness, i.e., exploiting strong language priors to bypass severe visual representation bottlenecks. In this work, we challenge the conventional methodology of multimodal evaluation, which relies on data ablation or new dataset creation and therefore conflates dataset biases with architectural incapacity. We propose an information-theoretic departure: the Modality Translation Protocol, designed to quantify what we call the Expense of Seeing. By translating semantic payloads rather than ablating them, we formulate three novel metrics -- the Toll (ToS), Curse (CoS), and Fallacy (FoS) of Seeing -- culminating in the Semantic Sufficiency Criterion (SSC). Furthermore, we hypothesise a Divergence Law of Multimodal Scaling: as the underlying language engines scale to unprecedented reasoning capabilities, the penalty of the visual knowledge bottleneck may increase rather than diminish. We argue the community should move beyond "multimodal gain" as a primary evaluation target. By elevating the SSC from a passive diagnostic constraint to an active architectural blueprint, we provide a foundation for guiding the next generation of AI systems toward genuine multimodal reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that state-of-the-art VLMs exhibit functional blindness by exploiting language priors to bypass visual representation bottlenecks in the Vision Encoder-Projector-LLM paradigm. It proposes the Modality Translation Protocol as an information-theoretic alternative to data ablation or new dataset creation; this protocol yields three new metrics (Toll/ToS, Curse/CoS, and Fallacy/FoS of Seeing) that culminate in the Semantic Sufficiency Criterion (SSC). The work further hypothesizes a Divergence Law of Multimodal Scaling, under which the visual knowledge bottleneck penalty increases rather than decreases as language engines scale, and advocates elevating the SSC to an active architectural design principle.
Significance. If the Modality Translation Protocol and derived metrics can be shown to isolate architectural visual bottlenecks from dataset and language-model priors without circularity or confounding, the framework would offer a principled shift away from 'multimodal gain' evaluation toward trustworthiness diagnostics. The Divergence Law, if empirically corroborated, would have direct implications for scaling laws in multimodal systems. The absence of any reported experiments, derivations, or validation of the metrics in the current manuscript, however, leaves these potential contributions speculative.
major comments (3)
- [Abstract and §3] Abstract and §3 (Modality Translation Protocol): The central claim that translating semantic payloads 'rather than ablating them' cleanly separates visual representation bottlenecks from language priors and dataset artifacts is load-bearing for all three metrics and the SSC. The manuscript provides no formal definition or pseudocode for the translation step, nor any quantification of information loss or introduced priors from the translator itself (e.g., whether an LLM captioner or external model is used). This directly inherits the vulnerability identified in the stress-test note.
- [§4] §4 (Divergence Law hypothesis): The law is presented as a prediction yet appears defined in terms of the same visual-bottleneck quantities (Toll/CoS/FoS) that the new metrics are constructed to measure. This creates a potential circular dependency: the hypothesis cannot be tested independently of the metrics whose validity is still unshown. No concrete falsifiable prediction or scaling experiment is supplied.
- [§5] §5 (Semantic Sufficiency Criterion): The SSC is elevated from diagnostic to 'active architectural blueprint,' yet the manuscript contains no derivation showing how the criterion would be enforced in model training or architecture search, nor any comparison against existing sufficiency notions in multimodal literature.
minor comments (2)
- [§3] Notation for the three metrics (ToS, CoS, FoS) is introduced without an explicit information-theoretic derivation or reference to standard divergence measures; a short appendix deriving each from mutual information or KL divergence would improve clarity.
- [Abstract] The abstract states that conventional evaluation 'conflates dataset biases with architectural incapacity,' but no concrete example or citation to a prior ablation study is given to illustrate the conflation the new protocol avoids.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications and commitments to revisions that strengthen the formal presentation without altering the core conceptual contributions.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Modality Translation Protocol): The central claim that translating semantic payloads 'rather than ablating them' cleanly separates visual representation bottlenecks from language priors and dataset artifacts is load-bearing for all three metrics and the SSC. The manuscript provides no formal definition or pseudocode for the translation step, nor any quantification of information loss or introduced priors from the translator itself (e.g., whether an LLM captioner or external model is used). This directly inherits the vulnerability identified in the stress-test note.
Authors: We agree that the current presentation would be strengthened by explicit formalization. In revision we will supply a mathematical definition of the translation operator T, pseudocode for the full Modality Translation Protocol, and a quantitative discussion of information loss and translator-induced priors (including sensitivity analysis when the translator is itself an LLM). This addition directly addresses separation from language priors and dataset artifacts. revision: yes
-
Referee: [§4] §4 (Divergence Law hypothesis): The law is presented as a prediction yet appears defined in terms of the same visual-bottleneck quantities (Toll/CoS/FoS) that the new metrics are constructed to measure. This creates a potential circular dependency: the hypothesis cannot be tested independently of the metrics whose validity is still unshown. No concrete falsifiable prediction or scaling experiment is supplied.
Authors: The Divergence Law is offered as a hypothesis whose functional form is expressed through the new metrics, yet we accept that independent testability must be demonstrated. We will add an explicit subsection containing falsifiable predictions (e.g., ToS/CoS/FoS should increase with LLM scale under fixed vision-encoder capacity) together with a concrete experimental protocol for controlled scaling studies that can be performed once the metrics are validated. revision: yes
-
Referee: [§5] §5 (Semantic Sufficiency Criterion): The SSC is elevated from diagnostic to 'active architectural blueprint,' yet the manuscript contains no derivation showing how the criterion would be enforced in model training or architecture search, nor any comparison against existing sufficiency notions in multimodal literature.
Authors: We will revise §5 to include both a derivation sketch (e.g., an auxiliary loss that penalizes violation of the SSC during training) and a direct comparison to prior sufficiency concepts such as visual grounding constraints and multimodal alignment objectives in the literature. These additions will clarify how the SSC can function as an active design principle. revision: yes
- Full empirical validation of the metrics and the Divergence Law requires new experiments that are outside the scope of the present conceptual manuscript.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces the Modality Translation Protocol as a new information-theoretic method to define the Expense of Seeing and derive the three metrics (Toll, Curse, Fallacy) plus the Semantic Sufficiency Criterion. The Divergence Law is explicitly framed as a hypothesis about future scaling behavior rather than a quantity fitted or defined from the same inputs. No equations reduce the claimed predictions to the metrics by construction, no self-citations are load-bearing for the central claims, and no ansatz or uniqueness result is smuggled in. The derivation remains self-contained as an original proposal with independent content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Current VLMs do not faithfully synthesise multimodal data and instead exploit language priors
invented entities (2)
-
Modality Translation Protocol
no independent evidence
-
Divergence Law of Multimodal Scaling
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a radical, information-theoretic departure: the Modality Translation Protocol... three novel metrics—the Toll (ToS), Curse (CoS), and Fallacy (FoS) of Seeing—culminating in the Semantic Sufficiency Criterion (SSC).
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
2025.FastVLM: Efficient Vision Encoding for Vision-Language Models
Apple Machine Learning Research. 2025.FastVLM: Efficient Vision Encoding for Vision-Language Models. https://machinelearning.apple.com/research/fast- vision-language-models
work page 2025
- [2]
-
[3]
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, and Feng Zhao. 2024. Are we on the right way for evaluating large vision-language models?. InProceedings of the 38th International Conference on Neural Information Processing Systems (Vancouver, BC, Canada)(NIPS ’24). Curran Associates Inc....
work page 2024
- [4]
- [5]
-
[6]
Iryna Hartsock and Ghulam Rasool. 2024. Vision-language models for medical report generation and visual question answering: A review.Frontiers in artificial intelligence7 (2024), 1430984
work page 2024
-
[7]
Irene Huang, Wei Lin, Muhammad Jehanzeb Mirza, Jacob A Hansen, Sivan Doveh, Victor I Butoi, Roei Herzig, Assaf Arbelle, Hilde Kuehne, Trevor Darrell, et al
-
[8]
Conme: Rethinking evaluation of compositional reasoning for modern vlms.Advances in Neural Information Processing Systems37 (2024), 22927–22946
work page 2024
-
[9]
2024.What are vision language models?https://www.ibm.com/think/topics/ vision-language-models
IBM. 2024.What are vision language models?https://www.ibm.com/think/topics/ vision-language-models
work page 2024
- [10]
-
[11]
Tina Khezresmaeilzadeh, Parsa Razmara, Mohammad Erfan Sadeghi, Seyedarmin Azizi, and Erfan Baghaei Potraghloo. 2025. MORFI: Mutimodal Zero-Shot Rea- soning for Financial Time-Series Inference. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision. 4236–4245
work page 2025
-
[12]
NVIDIA. 2025.Vision-Language Models. https://www.nvidia.com/en-us/glossary/ vision-language-models/
work page 2025
-
[13]
2025.What Is a World Model?https://www.nvidia.com/en-in/glossary/ world-models/
NVIDIA. 2025.What Is a World Model?https://www.nvidia.com/en-in/glossary/ world-models/
work page 2025
- [14]
-
[15]
Kun Xiang, Heng Li, Terry Jingchen Zhang, Yinya Huang, Zirong Liu, Peixin Qu, Jixi He, Jiaqi Chen, Yu-Jie Yuan, Jianhua Han, Hang Xu, Hanhui Li, Mrinmaya Sachan, and Xiaodan Liang. 2025. SeePhys: Does Seeing Help Thinking? – Benchmarking Vision-Based Physics Reasoning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets ...
work page 2025
-
[16]
Renrui Zhang, Dongzhi Jiang, Yichi Zhang, Haokun Lin, Ziyu Guo, Pengshuo Qiu, Aojun Zhou, Pan Lu, Kai-Wei Chang, Yu Qiao, Peng Gao, and Hongsheng Li. 2024. MATHVERSE: Does Your Multi-modal LLM Truly See the Diagrams in Visual Math Problems?. InComputer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024, Proceedings, P...
-
[17]
Zhusi Zhong, Yuli Wang, Jing Wu, Wen-Chi Hsu, Vin Somasundaram, Lulu Bi, Shreyas Kulkarni, Zhuoqi Ma, Scott Collins, Grayson Baird, et al. 2025. Vision- language model for report generation and outcome prediction in CT pulmonary angiogram.NPJ digital medicine8, 1 (2025), 432
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.