BhashaSetu: A Data-Centric Approach to Low-Resource Machine Translation
Pith reviewed 2026-06-29 18:10 UTC · model grok-4.3
The pith
Corpus-level deduplication delivers the largest quality gain for English-Marathi neural machine translation
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
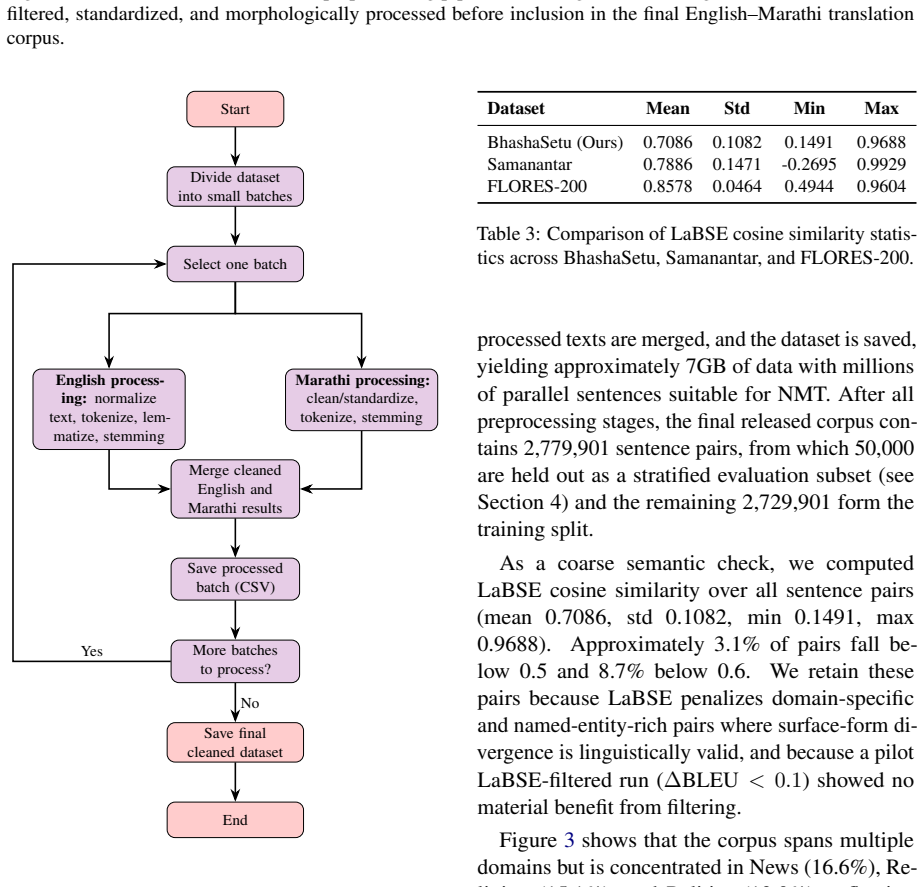
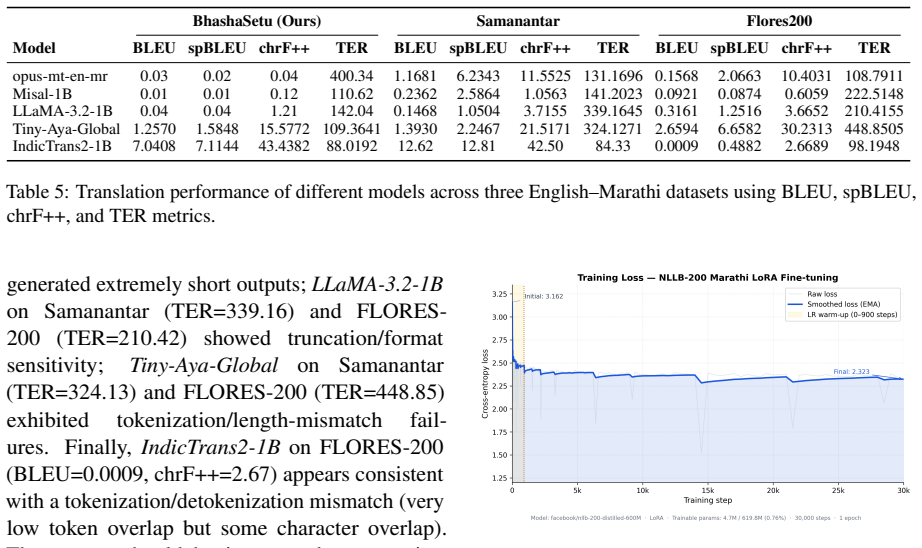
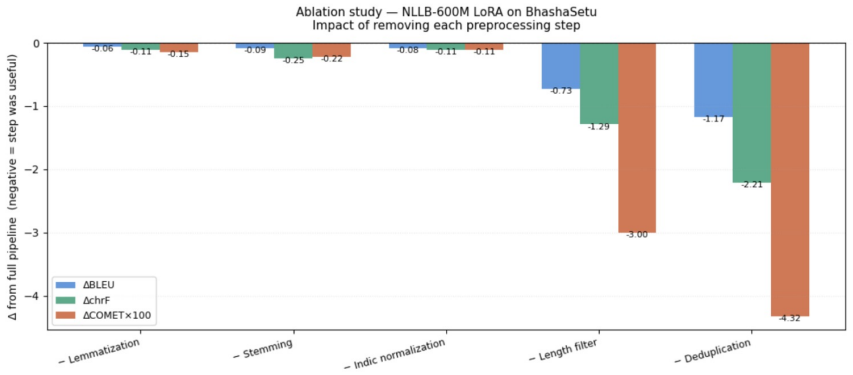
BhashaSetu provides 2.78 million English-Marathi sentence pairs enriched with stemmed and lemmatized forms. When used to fine-tune the NLLB-200-distilled-600M model via LoRA, the dataset yields competitive translation results across BLEU, spBLEU, chrF++ and TER. The central discovery is that omitting corpus-level deduplication causes the largest drop in performance, specifically 1.17 BLEU and 2.21 chrF++, establishing cross-source deduplication as the dominant preprocessing factor for this low-resource setting.
What carries the argument
Corpus-level deduplication of sentence pairs collected from heterogeneous public sources, shown through ablation to be the dominant factor improving downstream NMT quality.
If this is right
- For morphologically rich low-resource languages, data hygiene steps like deduplication yield measurable gains in translation accuracy.
- Parameter-efficient methods such as LoRA enable effective adaptation of large multilingual models to new language pairs using the released corpus.
- Releasing linguistically annotated parallel data supports reproducible experiments and morphology-aware analysis.
- Disciplined preprocessing can substitute for larger data volumes in resource-constrained translation tasks.
Where Pith is reading between the lines
- Similar deduplication strategies may benefit other language pairs where data is scraped from multiple domains.
- The emphasis on corpus hygiene suggests that data-centric approaches could outperform purely model-centric scaling in low-resource scenarios.
- The dataset's domain diversity opens opportunities to study cross-domain transfer in machine translation.
- Extending the ablation to other preprocessing steps or languages would test the generality of the deduplication finding.
Load-bearing premise
The sentence pairs gathered from various public sources form sufficiently accurate and parallel translations without substantial systematic errors or domain mismatches.
What would settle it
Reproducing the ablation study on the public dataset and observing no performance difference or an increase when deduplication is skipped would falsify the claim that deduplication is the largest contributor.
Figures

read the original abstract
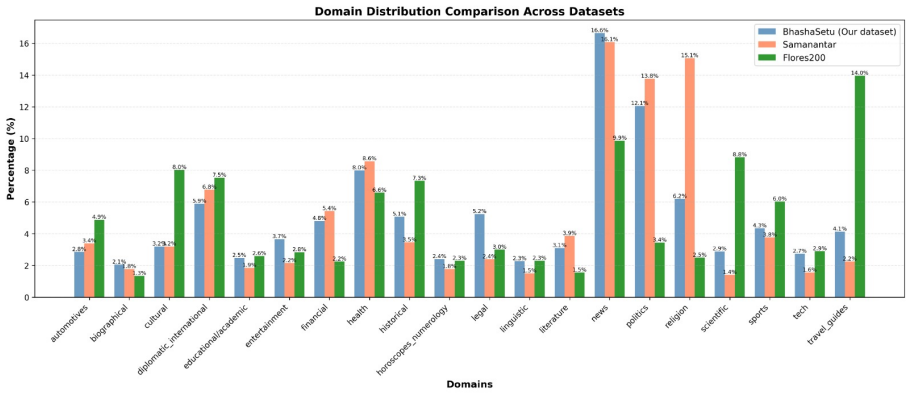
We present BhashaSetu, a linguistically enriched English--Marathi parallel dataset addressing persistent data limitations in low-resource neural machine translation (NMT). Marathi, spoken by over 95 million people, remains underrepresented in high-quality parallel corpora across diverse domains. Our dataset comprises 2.78 million sentence pairs from heterogeneous sources including news, politics, healthcare, literature, and culture, with stemmed and lemmatized representations to support morphology-aware analysis. We benchmark multiple state-of-the-art translation models using BLEU, spBLEU, chrF++, and TER metrics, and conduct parameter-efficient fine-tuning of NLLB-200-distilled-600M using LoRA. A key finding from our ablation: corpus-level deduplication is the single largest preprocessing contributor to downstream quality (removing it reduces performance by 1.17 BLEU and 2.21 chrF++), demonstrating that disciplined cross-source corpus hygiene is a low-cost, high-impact intervention for low-resource, morphologically rich languages. The dataset is publicly released to promote reproducible and linguistically informed low-resource NMT research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BhashaSetu, a 2.78M English–Marathi parallel corpus compiled from heterogeneous public sources (news, politics, healthcare, literature, culture) and augmented with stemmed/lemmatized forms. It reports benchmarks of multiple NMT systems under BLEU/spBLEU/chrF++/TER, describes LoRA fine-tuning of NLLB-200-distilled-600M, and presents an ablation showing that corpus-level deduplication is the single largest preprocessing contributor (its removal drops performance by 1.17 BLEU and 2.21 chrF++). The dataset is released publicly.
Significance. If the parallel pairs are verifiably high-quality, the work supplies a sizable, domain-diverse resource for an underrepresented language and supplies concrete evidence that disciplined deduplication yields larger gains than other common preprocessing steps in morphologically rich low-resource settings. Public release of the corpus directly supports reproducibility.
major comments (2)
- [Corpus construction section] Corpus construction (the section describing collection of the 2.78M pairs): no human validation, automatic alignment scoring, or error-rate sampling of the final corpus is reported. Because the central ablation treats these pairs as reliable gold parallels, the observed 1.17 BLEU / 2.21 chrF++ drop when deduplication is omitted could be driven by differential noise amplification rather than duplication per se.
- [Ablation study section] Ablation study (the section reporting the deduplication result): the experiment removes only deduplication while keeping all other preprocessing fixed, but does not report whether the non-deduplicated corpus was re-balanced for domain or length distribution; without that control it is unclear whether the metric deltas are attributable solely to duplicate removal.
minor comments (2)
- [Abstract] The abstract states concrete metric deltas but does not indicate whether the reported BLEU/chrF++ figures are averages over multiple random seeds or single runs; adding this detail would strengthen the ablation claim.
- [Results section] Table or figure presenting the ablation results should include the full set of preprocessing variants tested so readers can verify that deduplication indeed ranks as the largest single contributor.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on corpus validation and experimental controls. We address each major comment below and indicate the changes planned for the revised manuscript.
read point-by-point responses
-
Referee: [Corpus construction section] Corpus construction (the section describing collection of the 2.78M pairs): no human validation, automatic alignment scoring, or error-rate sampling of the final corpus is reported. Because the central ablation treats these pairs as reliable gold parallels, the observed 1.17 BLEU / 2.21 chrF++ drop when deduplication is omitted could be driven by differential noise amplification rather than duplication per se.
Authors: We acknowledge that the original manuscript did not report human validation, automatic alignment scoring, or error-rate sampling. The corpus was assembled from heterogeneous public sources with the assumption of reasonable quality, but this leaves open the possibility that noise differences contribute to the ablation results. In the revised manuscript we will add automatic alignment scores (e.g., via LASER) for the full corpus and results from manual inspection of a random sample of 500 pairs, including the estimated error rate. We will also expand the discussion to note that some portion of the observed 1.17 BLEU drop could arise from differential noise amplification and that future work should further disentangle these factors. revision: yes
-
Referee: [Ablation study section] Ablation study (the section reporting the deduplication result): the experiment removes only deduplication while keeping all other preprocessing fixed, but does not report whether the non-deduplicated corpus was re-balanced for domain or length distribution; without that control it is unclear whether the metric deltas are attributable solely to duplicate removal.
Authors: The ablation intentionally kept all other preprocessing steps identical to isolate the effect of deduplication. The non-deduplicated corpus was therefore not re-balanced. In the revision we will report domain and sentence-length distributions for both versions to allow readers to assess whether distributional shifts beyond duplicate removal are present. If imbalances exist we will note them explicitly as a limitation of the current experimental design. revision: partial
Circularity Check
Empirical ablation on new corpus exhibits no circular derivation
full rationale
The paper reports an empirical study of dataset curation followed by ablation experiments that measure downstream NMT performance (BLEU, chrF++) with and without corpus-level deduplication. These results are obtained by direct training and evaluation on held-out test data using standard metrics; no equations, fitted parameters, or self-citations are invoked to derive the reported deltas. The central claim therefore rests on observable performance differences rather than any reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption BLEU, spBLEU, chrF++ and TER are appropriate and sufficient metrics for comparing translation quality in this setting.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2601.09012
Translategemma technical report.Preprint, arXiv:2601.09012. Jay Gala, Pranjal A. Chitale, A K Raghavan, Varun Gumma, Sumanth Doddapaneni, Aswanth Kumar M, Janki Atul Nawale, Anupama Sujatha, Ratish Pudup- pully, Vivek Raghavan, Pratyush Kumar, Mitesh M. Khapra, Raj Dabre, and Anoop Kunchukuttan. 2023. Indictrans2: Towards high-quality and accessible ma- c...
-
[2]
Findings of the loresmt 2021 shared task on covid and sign language for low-resource languages. InProceedings of the 4th Workshop on Technologies for MT of Low Resource Languages (LoResMT2021), pages 114–123, Virtual. Association for Machine Translation in the Americas. Kishore Papineni, Salim Roukos, Todd Ward, and Wei- Jing Zhu. 2002. Bleu: a method for...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.