BAFIS: Dataset + Framework to assess occupational Bias and Human Preference in modern Text-to-image Models
Pith reviewed 2026-06-26 17:51 UTC · model grok-4.3
The pith
Text-to-image models display systematic gender and ethnicity biases when depicting occupations, and standard metrics align only partially with human ratings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that current text-to-image models exhibit systematic biases in gender and ethnicity for occupational images, demonstrated through a new dataset and human preference collection platform called BAFIS, with established metrics showing only partial correlation to subjective ratings.
What carries the argument
BAFIS, the Battle-Arena for Fair Image Synthesis platform, which collects human feedback on bias in generated images and pairs it with a dataset of 21,140 synthetic images.
If this is right
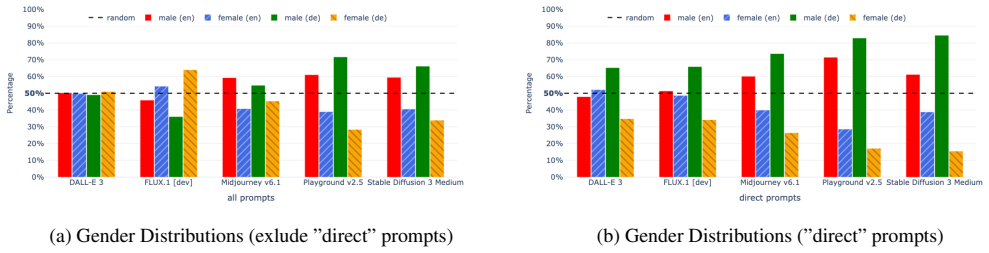
- Models including Midjourney v6.1, Stable Diffusion 3 Medium, DALL-E 3, Playground v2.5 and FLUX.1-dev produce occupation images that deviate from real employment distributions by gender and ethnicity.
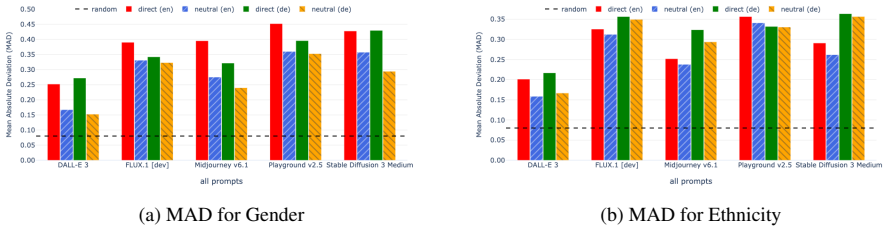
- Automated metrics for image quality and prompt alignment correlate only partially with human judgments of bias.
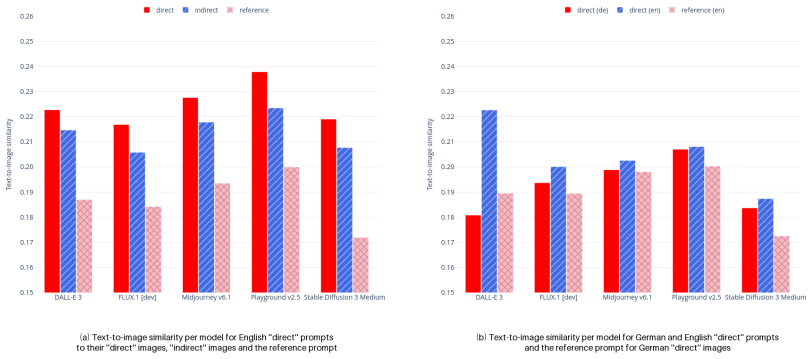
- Multilingual prompts still yield the same systematic biases.
- Human preference data must be added to evaluation pipelines if the goal is inclusive image generation.
Where Pith is reading between the lines
- The same human-arena collection method could be applied to other generative domains such as video or 3D to surface analogous biases.
- Model developers could close the loop by retraining on images that human raters in BAFIS judged as unbiased.
- Repeating the comparison against employment statistics from additional countries would test whether the observed biases are language- or culture-specific.
Load-bearing premise
The premise that prompts and human raters collected via BAFIS, together with comparison to German Federal Employment Agency statistics, provide an unbiased and generalizable measure of occupational bias in globally trained models.
What would settle it
A re-run of the human ratings with a new, demographically different rater pool that yields uncorrelated bias scores, or a model whose generated occupation images match the German employment statistics without detectable gender or ethnicity skew.
Figures


read the original abstract
Generative artificial intelligence has the potential to improve productivity and transform the production of creative content. However, existing research indicates that image generation models are significantly influenced by biases. This work investigates the inherent biases and language-induced biases present in text-to-image models within the context of occupation-related image generation, complementing established metrics with human preference feedback. We present a comprehensive evaluation of five current text-to-image models: Midjourney v6.1, Stable Diffusion 3 Medium, DALL-E 3, Playground v2.5, and FLUX.1-dev , focusing on gender and ethnicity bias, image quality, and prompt alignment. To facilitate this evaluation, we developed the "Battle-Arena for Fair Image Synthesis" (BAFIS), a platform designed to collect human feedback on bias in generated images. Furthermore, we created a dataset comprising 21,140 synthetic images generated using multilingual prompts, which serves as a basis for our analysis. We further place our results within a broader social context by comparing them to official statistics from the German Federal Employment Agency. Our findings reveal systematic biases in text-to-image models, with established evaluation metrics in partial correlation with subjective user ratings. Thus, our research emphasizes the need for including human preferences to develop fairer and more inclusive text-to-image models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the BAFIS platform and a dataset of 21,140 synthetic images generated from multilingual prompts to evaluate gender and ethnicity biases in five text-to-image models (Midjourney v6.1, Stable Diffusion 3 Medium, DALL-E 3, Playground v2.5, FLUX.1-dev) for occupational image generation. It collects human preference ratings via BAFIS, compares image distributions against German Federal Employment Agency statistics, and reports systematic biases along with partial correlation between established metrics and subjective user ratings.
Significance. If the ground-truth and protocol issues are resolved, the work supplies a sizable multilingual dataset and a human-feedback arena that can complement automated bias metrics in T2I evaluation. The explicit inclusion of human ratings and the scale of the image collection are concrete assets for the field.
major comments (2)
- [Abstract / Results] The central claim of systematic occupational bias rests on measuring deviation from German Federal Employment Agency workforce statistics. Because national labor-market demographics differ substantially by country for the same occupations, this single-nation reference cannot serve as a culture-independent ground truth for globally trained models without additional justification or cross-national validation (see abstract and the comparison paragraph in the results).
- [Abstract] The abstract states a concrete dataset size, systematic bias findings, and partial metric-human correlation, yet supplies no error bars, rater exclusion criteria, or full evaluation protocol. This omission prevents verification that post-hoc choices do not affect the reported correlations and bias magnitudes.
minor comments (2)
- [Abstract] The abstract does not specify the number of occupations or the exact prompt templates used; adding these counts would improve reproducibility.
- [Methods] Notation for the bias metrics and the precise definition of 'partial correlation' with human ratings should be clarified in the methods section.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond point by point to the major comments below.
read point-by-point responses
-
Referee: [Abstract / Results] The central claim of systematic occupational bias rests on measuring deviation from German Federal Employment Agency workforce statistics. Because national labor-market demographics differ substantially by country for the same occupations, this single-nation reference cannot serve as a culture-independent ground truth for globally trained models without additional justification or cross-national validation (see abstract and the comparison paragraph in the results).
Authors: We acknowledge the limitation of relying on a single national reference. The German Federal Employment Agency data were selected because they provide the most granular, publicly available occupation-level breakdowns by gender and ethnicity. In the revision we will add a dedicated paragraph in the Results section justifying this benchmark choice, explicitly note that it serves as one reference point rather than a universal ground truth, and list cross-national validation as an item of future work. revision: yes
-
Referee: [Abstract] The abstract states a concrete dataset size, systematic bias findings, and partial metric-human correlation, yet supplies no error bars, rater exclusion criteria, or full evaluation protocol. This omission prevents verification that post-hoc choices do not affect the reported correlations and bias magnitudes.
Authors: We agree that the abstract should convey more methodological transparency. The full protocol, rater exclusion rules, and statistical procedures (including error bars) appear in the Methods and Results sections. In revision we will expand the abstract with a concise clause mentioning error bars, rater criteria, and protocol overview while respecting length constraints. revision: yes
Circularity Check
No significant circularity; empirical evaluation with external benchmarks
full rationale
The paper is an empirical study that generates a dataset of 21,140 images from five text-to-image models using multilingual prompts, collects human ratings via the new BAFIS platform, computes standard bias metrics, and compares outputs against external German Federal Employment Agency statistics. No equations, fitted parameters, or self-citations are presented as load-bearing derivations; the central claims rest on direct measurement and external reference data rather than any quantity defined in terms of itself or renamed as a prediction. The reader's assessment of score 1.0 aligns with the absence of any self-definitional, fitted-input, or self-citation patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
artificialanalysis.ai|text to Image Arena |Artificial Analysis
Artifical Analysis. artificialanalysis.ai|text to Image Arena |Artificial Analysis. 1, 8
-
[2]
Improving image generation with better captions.Computer Science
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, et al. Improving image generation with better captions.Computer Science. https://cdn. openai. com/papers/dall-e-3. pdf, 2(3):8, 2023. 1
2023
-
[3]
Easily Ac- cessible Text-to-Image Generation Amplifies Demographic Stereotypes at Large Scale
Federico Bianchi, Pratyusha Kalluri, Esin Durmus, Faisal Ladhak, Myra Cheng, Debora Nozza, Tatsunori Hashimoto, Dan Jurafsky, James Zou, and Aylin Caliskan. Easily Ac- cessible Text-to-Image Generation Amplifies Demographic Stereotypes at Large Scale. In2023 ACM Conference on Fairness, Accountability, and Transparency, pages 1493– 1504, 2023. arXiv:2211.0...
-
[4]
Ledits++: Limitless image editing using text-to-image models
Manuel Brack, Felix Friedrich, Katharia Kornmeier, Linoy Tsaban, Patrick Schramowski, Kristian Kersting, and Apolin´ario Passos. Ledits++: Limitless image editing using text-to-image models. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 8861–8870, 2024. 2
2024
-
[5]
Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anasta- sios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Hao Zhang, Banghua Zhu, Michael Jordan, Joseph E. Gonzalez, and Ion Stoica. Chatbot Arena: An Open Platform for Evalu- ating LLMs by Human Preference, 2024. arXiv:2403.04132 [cs]. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
DALL-EV AL: Probing the Reasoning Skills and Social Biases of Text-to- Image Generation Models
Jaemin Cho, Abhay Zala, and Mohit Bansal. DALL-EV AL: Probing the Reasoning Skills and Social Biases of Text-to- Image Generation Models. In2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 3020–3031, Paris, France, 2023. IEEE. 1, 2, 3, 4, 5
2023
-
[7]
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, Kyle Lacey, Alex Goodwin, Yan- nik Marek, and Robin Rombach. Scaling Rectified Flow Transformers for High-Resolution Image Synthesis, 2024. arXiv:2403.03206 [cs]. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
imgsys.org|an image model arena by fal.ai
fal.ai. imgsys.org|an image model arena by fal.ai. 1, 8
-
[9]
Fair diffusion: instructing text-to- image generation models on fairness
Felix Friedrich, Manuel Brack, Lukas Struppek, Dominik Hintersdorf, Patrick Schramowski, Sasha Luccioni, and Kristian Kersting. Fair diffusion: instructing text-to- image generation models on fairness. arxiv.arXiv preprint arXiv:2302.10893, 2023. 1, 2, 3
-
[10]
Felix Friedrich, Katharina H ¨ammerl, Patrick Schramowski, Manuel Brack, Jindrich Libovicky, Kristian Kersting, and Alexander Fraser. Multilingual Text-to-Image Generation Magnifies Gender Stereotypes and Prompt Engineering May Not Help You, 2024. arXiv:2401.16092 [cs]. 1, 2, 3, 4, 6, 8
-
[11]
Multilingual text-to-image generation magnifies gender stereotypes
Felix Friedrich, Katharina H ¨ammerl, Patrick Schramowski, Manuel Brack, Jind ˇrich Libovick `y, Alexander Fraser, and Kristian Kersting. Multilingual text-to-image generation magnifies gender stereotypes. InProceedings of the 63rd An- nual Meeting of the Association for Computational Linguis- tics (Volume 1: Long Papers), pages 19656–19679, 2025. 3
2025
-
[12]
statistik.arbeitsagentur.de|Statistik der Bundesagentur f¨ur Arbeit
Agentur f ¨ur Arbeit. statistik.arbeitsagentur.de|Statistik der Bundesagentur f¨ur Arbeit. 5
-
[13]
Gans trained by a two time-scale update rule converge to a local nash equilib- rium, 2018
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilib- rium, 2018. 5
2018
-
[14]
Ultralytics YOLO, 2023
Glenn Jocher, Ayush Chaurasia, and Jing Qiu. Ultralytics YOLO, 2023. 3
2023
-
[15]
Fairface: Face attribute dataset for balanced race, gender, and age for bias measurement and mitigation
Kimmo Karkkainen and Jungseock Joo. Fairface: Face attribute dataset for balanced race, gender, and age for bias measurement and mitigation. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 1548–1558, 2021. 3
2021
-
[16]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 4401–4410, 2019. 6
2019
-
[17]
Playground v2.5: Three Insights towards Enhancing Aesthetic Quality in Text-to-Image Generation
Daiqing Li, Aleks Kamko, Ehsan Akhgari, Ali Sabet, Lin- miao Xu, and Suhail Doshi. Playground v2.5: Three Insights towards Enhancing Aesthetic Quality in Text-to-Image Gen- eration, 2024. arXiv:2402.17245 [cs]. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Stable Bias: Analyz- ing Societal Representations in Diffusion Models, 2023
Alexandra Sasha Luccioni, Christopher Akiki, Margaret Mitchell, and Yacine Jernite. Stable Bias: Analyz- ing Societal Representations in Diffusion Models, 2023. arXiv:2303.11408 [cs]. 1, 2
-
[19]
MagFace: A universal representation for face recognition and quality assessment
Qiang Meng, Shichao Zhao, Zhida Huang, and Feng Zhou. MagFace: A universal representation for face recognition and quality assessment. InIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021, pages 14225–14234. Computer Vision Founda- tion / IEEE, 2021. 6
2021
-
[20]
On aliased resizing and surprising subtleties in gan evaluation
Gaurav Parmar, Richard Zhang, and Jun-Yan Zhu. On aliased resizing and surprising subtleties in gan evaluation. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 11410–11420, 2022. 5
2022
-
[21]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 6, 8
2021
-
[22]
Improved techniques for training gans.Advances in neural information processing systems, 29, 2016
Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans.Advances in neural information processing systems, 29, 2016. 5
2016
-
[23]
Multilingual con- ceptual coverage in text-to-image models.arXiv preprint arXiv:2306.01735, 2023
Michael Saxon and William Yang Wang. Multilingual con- ceptual coverage in text-to-image models.arXiv preprint arXiv:2306.01735, 2023. 2
-
[24]
Bradley-terry models in r: the bradleyterry2 package.Journal of statistical software, 48:1–21, 2012
Heather Turner and David Firth. Bradley-terry models in r: the bradleyterry2 package.Journal of statistical software, 48:1–21, 2012. 6
2012
-
[25]
Survey of Bias In Text- to-Image Generation: Definition, Evaluation, and Mitiga- tion, 2024
Yixin Wan, Arjun Subramonian, Anaelia Ovalle, Zongyu Lin, Ashima Suvarna, Christina Chance, Hritik Bansal, Re- becca Pattichis, and Kai-Wei Chang. Survey of Bias In Text- to-Image Generation: Definition, Evaluation, and Mitiga- tion, 2024. arXiv:2404.01030 [cs]. 2
-
[26]
Altdiffu- sion: A multilingual text-to-image diffusion model
Fulong Ye, Guang Liu, Xinya Wu, and Ledell Wu. Altdiffu- sion: A multilingual text-to-image diffusion model. InPro- ceedings of the AAAI conference on artificial intelligence, pages 6648–6656, 2024. 2
2024
-
[27]
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
Jiahui Yu, Yuanzhong Xu, Jing Yu Koh, Thang Luong, Gun- jan Baid, Zirui Wang, Vijay Vasudevan, Alexander Ku, Yin- fei Yang, Burcu Karagol Ayan, et al. Scaling autoregres- sive models for content-rich text-to-image generation.arXiv preprint arXiv:2206.10789, 2(3):5, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023. 2
2023
-
[29]
Mi Zhou, Vibhanshu Abhishek, Timothy Derdenger, Jaymo Kim, and Kannan Srinivasan. Bias in Generative AI, 2024. arXiv:2403.02726 [cs, econ, q-fin]. 1, 2, 3, 4
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.