RSICCLLM: A Multimodal Large Language Model for Remote Sensing Image Change Captioning
Pith reviewed 2026-06-29 04:06 UTC · model grok-4.3
The pith
A 7B-parameter vision-language model outperforms larger ones at describing changes in remote sensing images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
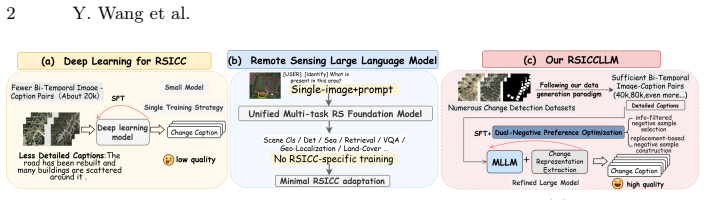
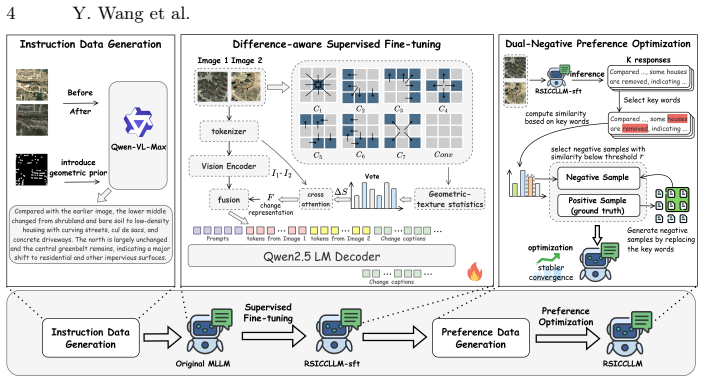
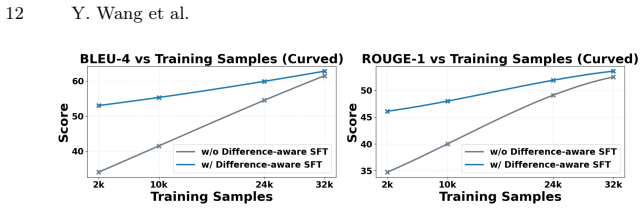
By releasing the RSICI instruction dataset, building a task-specific benchmark, applying Difference-aware Supervised Fine-tuning to extract change representations, and using Dual-Negative Preference Optimization on the RSICP preference dataset, a 7B-parameter multimodal large language model achieves superior performance on remote sensing image change captioning compared with models of substantially larger scale.
What carries the argument
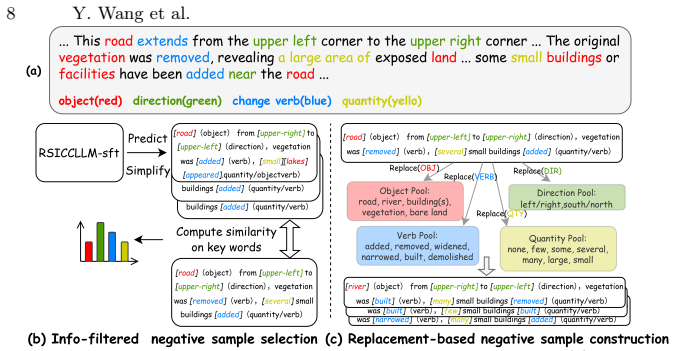
Difference-aware Supervised Fine-tuning combined with Dual-Negative Preference Optimization, which guide the model to focus on temporal differences and refine outputs via two complementary negative-sample strategies.
If this is right
- Task-specific post-training can close the performance gap between small and large models in remote sensing captioning.
- Explicit change extraction during fine-tuning improves the model's ability to handle bi-temporal image pairs.
- Preference optimization with dual negative samples further refines caption quality beyond standard supervised fine-tuning.
- The released datasets and benchmark enable direct comparison of future RSICC methods.
Where Pith is reading between the lines
- The same data-generation and optimization pattern could be tested on other remote sensing tasks that require comparing image pairs.
- If the 7B model still leads after the new datasets are given to larger baselines, the result would favor efficient adaptation over raw scale.
- The dual-negative construction may generalize to preference tuning in other vision-language domains where subtle differences matter.
Load-bearing premise
The reported gains arise from the new fine-tuning and optimization steps rather than from the newly created datasets or from choices in how the benchmark is evaluated.
What would settle it
Retraining a larger baseline model on exactly the same RSICI and RSICP datasets without Difference-aware Supervised Fine-tuning or Dual-Negative Preference Optimization and obtaining equal or better scores would falsify the claim that the post-training framework itself drives the improvement.
Figures

read the original abstract
Remote Sensing Image Change Captioning (RSICC) aims to describe changes between bi-temporal remote sensing images and holds significant research and application value. However, most existing methods rely on conventional deep learning architectures, and the limited model capacity constrains performance. Although large-model post-training techniques have achieved great success in general domains, their direct transfer to RSICC remains challenging due to data scarcity and the need for fine-grained change understanding. To address this, we propose RSICCLLM, the first post-training framework for large vision-language models in RSICC. Specifically, we design a data generation paradigm, release the instruction dataset RSICI, and establish a task-specific RSICC benchmark. We further introduce Difference-aware Supervised Fine-tuning to explicitly extract change representations and guide the model in perceiving and understanding temporal differences. In addition, we propose Dual-Negative Preference Optimization (DNPO), which employs two complementary negative-sample construction strategies to construct the preference dataset RSICP and further refine model performance. Extensive experiments validate the superior capability of RSICCLLM, which achieves outstanding results with only 7B parameters, surpassing models of substantially larger scales. The code and dataset will be made publicly available at https://github.com/keaill/RSICCLLM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RSICCLLM, the first post-training framework adapting multimodal LLMs to remote sensing image change captioning (RSICC). It introduces a data-generation paradigm that releases the RSICI instruction dataset and establishes a new task-specific benchmark, along with Difference-aware Supervised Fine-tuning to extract change representations and Dual-Negative Preference Optimization (DNPO) that constructs the RSICP preference dataset via two negative-sample strategies. The central claim is that the resulting 7B-parameter model achieves superior performance over substantially larger models.
Significance. If the performance gains can be shown to arise from the proposed Difference-aware SFT and DNPO steps rather than from the new datasets alone, the work would be a meaningful step in transferring general-domain post-training methods to the data-scarce RSICC setting. Public release of the datasets and code would also be a concrete contribution to the community.
major comments (2)
- [Experimental results] Experimental results section: The claim that a 7B model surpasses substantially larger models requires controlled comparisons that isolate the contribution of Difference-aware SFT and DNPO. No evidence is presented that larger-scale baselines were retrained or re-evaluated on the new RSICI/RSICP data; without such ablations the superiority may be driven primarily by dataset novelty rather than the algorithmic steps.
- [§3, §4] §3 and §4: The methods are described at a high level, but the manuscript provides no quantitative ablation tables, no comparison of the base model on prior data versus the new RSICI/RSICP data, and no details on evaluation protocol that would allow assessment of whether the reported gains are genuine capability improvements.
minor comments (1)
- [Abstract] Abstract: Phrases such as 'outstanding results' and 'superior capability' are not accompanied by any concrete metrics or baseline names, reducing the ability of readers to immediately gauge the scale of the claimed improvement.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on strengthening the experimental validation. We address the major comments below and commit to revisions that provide the requested ablations and clarifications.
read point-by-point responses
-
Referee: [Experimental results] Experimental results section: The claim that a 7B model surpasses substantially larger models requires controlled comparisons that isolate the contribution of Difference-aware SFT and DNPO. No evidence is presented that larger-scale baselines were retrained or re-evaluated on the new RSICI/RSICP data; without such ablations the superiority may be driven primarily by dataset novelty rather than the algorithmic steps.
Authors: We agree that isolating the contributions of Difference-aware SFT and DNPO from dataset effects is important. The current comparisons use published results of larger models on standard benchmarks because retraining those models on the newly introduced RSICI/RSICP datasets was not feasible due to computational limits. In the revised manuscript we will add ablation experiments that apply the base 7B model to the new data with and without our SFT and DNPO stages, thereby quantifying the incremental gains attributable to the proposed techniques. revision: yes
-
Referee: [§3, §4] §3 and §4: The methods are described at a high level, but the manuscript provides no quantitative ablation tables, no comparison of the base model on prior data versus the new RSICI/RSICP data, and no details on evaluation protocol that would allow assessment of whether the reported gains are genuine capability improvements.
Authors: We acknowledge the absence of these quantitative elements in the submitted version. The revised manuscript will expand §§3 and 4 with (i) full ablation tables, (ii) direct performance comparisons of the base model on prior versus RSICI/RSICP data, and (iii) a complete description of the evaluation protocol, metrics, and splits to permit independent verification of the reported improvements. revision: yes
Circularity Check
No circularity; empirical adaptation with no derivations or self-referential reductions
full rationale
The paper describes an empirical post-training framework for RSICC using new datasets (RSICI, RSICP) and two proposed fine-tuning steps (Difference-aware SFT, DNPO). No equations, derivations, or first-principles predictions appear in the abstract or described content. Claims rest on experimental results rather than any chain that reduces by construction to fitted inputs or self-citations. The reader's assessment of score 2.0 aligns with the absence of load-bearing mathematical steps; any data-vs-method confounding is an empirical validity concern, not circularity per the defined patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2308.12966 (2023)
Bai, J., Bai, S., Yang, S., Wang, S., Tan, S., Wang, P., Lin, J., Zhou, C., Zhou, J.: Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv preprint arXiv:2308.12966 (2023)
Pith/arXiv arXiv 2023
-
[2]
arXiv preprint arXiv:2502.13923 (2025)
Bai, S., et al.: Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
Pith/arXiv arXiv 2025
-
[3]
https://doi.org/10.48550/arXiv.2505.14231,https://arxiv.org/abs/2505
Bai, S., Li, M., Liu, Y., Tang, J., Zhang, H., Sun, L., Chu, X., Tang, Y.: Univg-r1: Reasoning guided universal visual grounding with reinforcement learning (2025). https://doi.org/10.48550/arXiv.2505.14231,https://arxiv.org/abs/2505. 14231
-
[4]
Pat- tern recognition13(2), 111–122 (1981)
Ballard, D.H.: Generalizing the hough transform to detect arbitrary shapes. Pat- tern recognition13(2), 111–122 (1981)
1981
-
[5]
Remote sensing12(10), 1662 (2020)
Chen, H., Shi, Z.: A spatial-temporal attention-based method and a new dataset for remote sensing image change detection. Remote sensing12(10), 1662 (2020)
2020
-
[6]
IEEE Geoscience and Remote Sensing Letters (2024)
Chen, K., Chen, B., Liu, C., Li, W., Zou, Z., Shi, Z.: Rsmamba: Remote sensing image classification with state space model. IEEE Geoscience and Remote Sensing Letters (2024)
2024
-
[7]
Chen, L., Gao, H., Liu, T., Huang, Z., Sung, F., Zhou, X., Wu, Y., Chang, B.: G1: Bootstrapping perception and reasoning abilities of vision-language model via reinforcement learning (2025).https://doi.org/10.48550/arXiv.2505.13426, https://arxiv.org/abs/2505.13426
-
[8]
48550/arXiv.2506.22434,https://arxiv.org/abs/2506.22434
Chen, X., Zhu, M., Liu, S., Wu, X., Xu, X., Liu, Y., Bai, X., Zhao, H.: Mico: Multi- image contrast for reinforcement visual reasoning (2025).https://doi.org/10. 48550/arXiv.2506.22434,https://arxiv.org/abs/2506.22434
arXiv 2025
-
[9]
arXiv preprint arXiv:2509.01907 (2025)
Chen, Z., Wang, C., Zhang, N., Zhang, F.: Rscc: A large-scale remote sensing change caption dataset for disaster events. arXiv preprint arXiv:2509.01907 (2025)
arXiv 2025
-
[10]
Remote Sensing16(13), 2355 (2024) 16 Y
Cheng, G., Huang, Y., Li, X., Lyu, S., Xu, Z., Zhao, H., Zhao, Q., Xiang, S.: Change detection methods for remote sensing in the last decade: A comprehensive review. Remote Sensing16(13), 2355 (2024) 16 Y. Wang et al
2024
-
[11]
In: 2021 IEEE International Geoscience and Remote Sens- ing Symposium IGARSS
Chouaf, S., Hoxha, G., Smara, Y., Melgani, F.: Captioning changes in bi-temporal remote sensing images. In: 2021 IEEE International Geoscience and Remote Sens- ing Symposium IGARSS. pp. 2891–2894. IEEE (2021)
2021
-
[12]
ISPRS Journal of Photogrammetry and Remote Sensing208, 53–69 (2024)
Dong, S., Wang, L., Du, B., Meng, X.: Changeclip: Remote sensing change detec- tion with multimodal vision-language representation learning. ISPRS Journal of Photogrammetry and Remote Sensing208, 53–69 (2024)
2024
-
[13]
arXiv preprint arXiv:2507.22058 (2025)
Geng, Z., Wang, Y., Ma, Y., Li, C., Rao, Y., Gu, S., Zhong, Z., Lu, Q., Hu, H., Zhang, X., et al.: X-omni: Reinforcement learning makes discrete autoregressive image generative models great again. arXiv preprint arXiv:2507.22058 (2025)
arXiv 2025
-
[14]
arXiv preprint arXiv:2507.01006 (2025)
GLM-V Team: Glm-4.5v and glm-4.1v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning. arXiv preprint arXiv:2507.01006 (2025)
Pith/arXiv arXiv 2025
-
[15]
Sustainability16(1), 274 (2024)
Gu, Z., Zeng, M.: The use of artificial intelligence and satellite remote sensing in land cover change detection: Review and perspectives. Sustainability16(1), 274 (2024)
2024
-
[16]
arXiv preprint arXiv:2501.12948 (2025)
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al.: Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948 (2025)
Pith/arXiv arXiv 2025
-
[17]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Hänsch, R., Arndt, J., Lunga, D., Gibb, M., Pedelose, T., Boedihardjo, A., Petrie, D., Bacastow, T.M.: Spacenet 8-the detection of flooded roads and buildings. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 1472–1480 (2022)
2022
-
[18]
Machine Intelligence Research23(2), 383–395 (2026)
He, Z., Wang, J., Kang, X., Wang, Z.J.: A non-intrusive plug-and-play method for hallucination mitigation via lid-guided input preprocessing. Machine Intelligence Research23(2), 383–395 (2026)
2026
-
[19]
IEEE Transactions on Geoscience and Remote Sensing60(2022)
Hoxha,G.,Chouaf,S.,Melgani,F.,Smara,Y.:Changecaptioning:Anewparadigm for multitemporal remote sensing image analysis. IEEE Transactions on Geoscience and Remote Sensing60(2022)
2022
-
[20]
arXiv preprint arXiv:2307.15266 (2023)
Hu, Y., Yuan, J., Wen, C., Lu, X., Li, X.: Rsgpt: A remote sensing vision language model and benchmark. arXiv preprint arXiv:2307.15266 (2023)
arXiv 2023
-
[21]
ISPRS Journal of Photogrammetry and Remote Sensing224, 272–286 (2025)
Hu, Y., Yuan, J., Wen, C., Lu, X., Liu, Y., Li, X.: Rsgpt: A remote sensing vision language model and benchmark. ISPRS Journal of Photogrammetry and Remote Sensing224, 272–286 (2025)
2025
-
[22]
arXiv preprint arXiv:2505.08586 (2025)
Huang, L., An, Z., Yang, C., Diao, B., Wang, F., Zeng, Y., Hao, Z., Xu, Y.: Preprompt: Predictive prompting for class incremental learning. arXiv preprint arXiv:2505.08586 (2025)
arXiv 2025
-
[23]
In: Proceedings of the AAAI Conference on Artificial Intelligence (AAAI)
Huang, L., Zeng, Y., Yang, C., An, Z., Diao, B., Xu, Y.: etag: Class-incremental learning via embedding distillation and task-oriented generation. In: Proceedings of the AAAI Conference on Artificial Intelligence (AAAI). vol. 38, pp. 12591–12599 (2024)
2024
-
[24]
arXiv preprint arXiv:2508.15763 (2025)
Intern-S1 Team: Intern-s1: A scientific multimodal foundation model. arXiv preprint arXiv:2508.15763 (2025)
arXiv 2025
-
[25]
arXiv preprint arXiv:2410.06234 (2024)
Irvin, J.A., Liu, E.R., Chen, J.C., Dormoy, I., Kim, J., Khanna, S., Zheng, Z., Er- mon, S.: Teochat: A large vision-language assistant for temporal earth observation data. arXiv preprint arXiv:2410.06234 (2024)
arXiv 2024
-
[26]
Kuckreja, K., Danish, M.S., Naseer, M., Das, A., Khan, S., Khan, F.S.: Geochat:grounded large vision-language model for remote sensing. In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 27831–27840 (2024).https://doi.org/10.1109/CVPR52733.2024.02629 RSICCLLM 17
-
[27]
In: The International Archives of the Photogrammetry, Remote Sensing and Spatial In- formation Sciences
Lebedev, M.A., Vizilter, Y.V., Vygolov, O.V., Knyaz, V.A., Rubis, A.Y.: Change detection in remote sensing images using conditional adversarial networks. In: The International Archives of the Photogrammetry, Remote Sensing and Spatial In- formation Sciences. vol. XLII-2, pp. 565–571 (2018).https://doi.org/10.5194/ isprs-archives-XLII-2-565-2018
2018
-
[28]
Advances in Neural Information Processing Systems37, 3229–3242 (2024)
Li, X., Ding, J., Elhoseiny, M.: Vrsbench: A versatile vision-language benchmark dataset for remote sensing image understanding. Advances in Neural Information Processing Systems37, 3229–3242 (2024)
2024
-
[29]
Li, Y., Tian, W., Jiao, Y., Chen, J., Qian, T., Zhu, B., Zhao, N., Jiang, Y.G.: Look before you decide: Prompting active deduction of mllms for assumptive reasoning (2024).https://doi.org/10.48550/arXiv.2404.12966,https://arxiv.org/ abs/2404.12966
-
[30]
In: Text Sum- marization Branches Out: Proceedings of the ACL-04 Workshop (2004)
Lin, C.Y.: Rouge: A package for automatic evaluation of summaries. In: Text Sum- marization Branches Out: Proceedings of the ACL-04 Workshop (2004)
2004
-
[31]
In: IGARSS 2024-2024 IEEE International Geoscience and Remote Sensing Symposium
Liu, C., Chen, K., Qi, Z., Liu, Z., Zhang, H., Zou, Z., Shi, Z.: Pixel-level change detection pseudo-label learning for remote sensing change captioning. In: IGARSS 2024-2024 IEEE International Geoscience and Remote Sensing Symposium. pp. 8405–8408. IEEE (2024)
2024
-
[32]
In: IGARSS 2023-2023 IEEE International Geoscience and Remote Sensing Symposium
Liu, C., Yang, J., Qi, Z., Zou, Z., Shi, Z.: Progressive scale-aware network for re- mote sensing image change captioning. In: IGARSS 2023-2023 IEEE International Geoscience and Remote Sensing Symposium. pp. 6668–6671. IEEE (2023)
2023
-
[33]
IEEE Transactions on Geoscience and Remote Sensing60, 1–20 (2022)
Liu, C., Zhao, R., Chen, H., Zou, Z., Shi, Z.: Remote sensing image change cap- tioning with dual-branch transformers: A new method and a large scale dataset. IEEE Transactions on Geoscience and Remote Sensing60, 1–20 (2022)
2022
-
[34]
IEEE Transactions on Geoscience and Remote Sensing61, 1–18 (2023)
Liu, C., Zhao, R., Chen, J., Qi, Z., Zou, Z., Shi, Z.: A decoupling paradigm with prompt learning for remote sensing image change captioning. IEEE Transactions on Geoscience and Remote Sensing61, 1–18 (2023)
2023
-
[35]
IEEE Transactions on Geoscience and Remote Sensing (2025)
Liu, N., Xu, X., Su, Y., Zhang, H., Li, H.C.: Pointsam: Pointly-supervised segment anything model for remote sensing images. IEEE Transactions on Geoscience and Remote Sensing (2025)
2025
-
[36]
In: Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL) (2002)
Papineni, K., Roukos, S., Ward, T., Zhu, W.J.: Bleu: a method for automatic evaluation of machine translation. In: Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL) (2002)
2002
-
[37]
arXiv preprint arXiv:1908.10084 (2019)
Reimers, N., Gurevych, I.: Sentence-bert: Sentence embeddings using siamese bert- networks. arXiv preprint arXiv:1908.10084 (2019)
Pith/arXiv arXiv 1908
-
[38]
SenseTime: Sensechat-vision.https://www.sensetime.com/en/news- detail/ 51167493(2024), official announcement / product page
2024
-
[39]
arXiv preprint arXiv:2507.16814 (2025)
Shen, J., Zhao, H., Gu, Y., Gao, S., Liu, K., Huang, H., Gao, J., Lin, D., Zhang, W., Chen, K.: Semi-off-policy reinforcement learning for vision-language slow-thinking reasoning. arXiv preprint arXiv:2507.16814 (2025)
arXiv 2025
-
[40]
Remote Sensing13(24), 5094 (2021)
Shen, L., Lu, Y., Chen, H., Wei, H., Xie, D., Yue, J., Chen, R., Lv, S., Jiang, B.: S2looking: A satellite side-looking dataset for building change detection. Remote Sensing13(24), 5094 (2021)
2021
-
[41]
IEEE Transactions on Geoscience and Remote Sensing (2024)
Shi, J., Zhang, M., Hou, Y., Zhi, R., Liu, J.: A multi-task network and two large scale datasets for change detection and captioning in remote sensing images. IEEE Transactions on Geoscience and Remote Sensing (2024)
2024
-
[42]
IEEE Transactions on Geoscience and Remote Sensing60, 1–16 (2022)
Shi, Q., Liu, M., Li, S., Liu, X., Wang, F., Zhang, L.: A deeply supervised attention metric-based network and an open aerial image dataset for remote sensing change detection. IEEE Transactions on Geoscience and Remote Sensing60, 1–16 (2022). https://doi.org/10.1109/TGRS.2021.3085870 18 Y. Wang et al
-
[43]
Team, K.: Kimi-vl technical report (2025).https://doi.org/10.48550/arXiv. 2504.07491,https://arxiv.org/abs/2504.07491
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2025
-
[44]
Team, Q.: Qwen3-vl.https://github.com/QwenLM/Qwen3-VL(2025), code reposi- tory
2025
-
[45]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Van Etten, A., Hogan, D., Manso, J.M., Shermeyer, J., Weir, N., Lewis, R.: The multi-temporal urban development spacenet dataset. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6398– 6407 (2021)
2021
-
[46]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Verma, S., Panigrahi, A., Gupta, S.: Qfabric: Multi-task change detection dataset. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1052–1061 (2021)
2021
-
[47]
Wang, F., Wang, H., Guo, Z., Wang, D., Wang, Y., Chen, M., Ma, Q., Lan, L., Yang, W., Zhang, J., et al.: Xlrs-bench: Could your multimodal llms understand extremely large ultra-high-resolution remote sensing imagery? In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 14325–14336 (2025)
2025
-
[48]
48550/arXiv.2505.16854,https://arxiv.org/abs/2505.16854
Wang, J., Lin, K.Q., Cheng, J., Shou, M.Z.: Think or not? selective reasoning via reinforcement learning for vision-language models (2025).https://doi.org/10. 48550/arXiv.2505.16854,https://arxiv.org/abs/2505.16854
arXiv 2025
-
[49]
Remote Sensing16(5), 804 (2024)
Wang, L., Zhang, M., Gao, X., Shi, W.: Advances and challenges in deep learning- based change detection for remote sensing images: A review through various learn- ing paradigms. Remote Sensing16(5), 804 (2024)
2024
-
[50]
Machine Intelligence Research23(2), 308–330 (2026)
Wang, T., Lin, X., Xu, Y., Ye, Q., Guo, D., Escalera, S., Khoriba, G., Yu, Z.: Micro- gesture recognition: A comprehensive survey of datasets, methods, and challenges. Machine Intelligence Research23(2), 308–330 (2026)
2026
-
[51]
Wang, Z., Yu, Z., Zhu, Y., Zhao, B., Liang, H., Wang, T., Xia, W., Zhang, J., Liu, Z., Ma, H., Ma, F., Tian, Q.: Affectagent: Collaborative multi-agent reasoning for retrieval-augmented multimodal emotion recognition (2026),https://arxiv.org/ abs/2604.12735
Pith/arXiv arXiv 2026
-
[52]
Wang, Z., Zhao, B., Zhu, Y., Liu, Z., Ma, H., Zhang, R., Ding, S., Xie, Q., Yu, Z.: Navigating the emotion tree: Hierarchical hyperbolic rag for multimodal emotion recognition (2026),https://arxiv.org/abs/2605.18884
Pith/arXiv arXiv 2026
-
[53]
arXiv preprint arXiv:2507.06448 (2025)
Wang, Z., Guo, X., Stoica, S., Xu, H., Wang, H., Ha, H., Chen, X., Chen, Y., Yan, M., Huang, F., et al.: Perception-aware policy optimization for multimodal reasoning. arXiv preprint arXiv:2507.06448 (2025)
Pith/arXiv arXiv 2025
-
[54]
arXiv preprint arXiv:2411.11360 (2024)
Wang, Z., Wang, M., Xu, S., Li, Y., Zhang, B.: Ccexpert: Advancing mllm capa- bility in remote sensing change captioning with difference-aware integration and a foundational dataset. arXiv preprint arXiv:2411.11360 (2024)
arXiv 2024
-
[55]
Xiao, W., Gan, L., Dai, W., He, W., Huang, Z., Li, H., Shu, F., Yu, Z., Zhang, P., Jiang, H., Wu, F.: Fast-slow thinking for large vision-language model reasoning (2025).https://doi.org/10.48550/arXiv.2504.18458,https://arxiv.org/ abs/2504.18458
-
[56]
arXiv preprint arXiv:2505.09388 (2025)
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al.: Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025)
Pith/arXiv arXiv 2025
-
[57]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yang, C., An, Z., Huang, L., Bi, J., Yu, X., Yang, H., Diao, B., Xu, Y.: Clip-kd: An empirical study of clip model distillation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 15952–15962 (2024)
2024
-
[58]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yang, C., Zhou, H., An, Z., Jiang, X., Xu, Y., Zhang, Q.: Cross-image rela- tional knowledge distillation for semantic segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12319– 12328 (2022) RSICCLLM 19
2022
-
[59]
arXiv preprint arXiv:2507.13348 (2025)
Yang, S., Li, J., Lai, X., Yu, B., Zhao, H., Jia, J.: Visionthink: Smart and efficient vision language model via reinforcement learning. arXiv preprint arXiv:2507.13348 (2025)
arXiv 2025
-
[60]
arXiv preprint arXiv:2503.11070 (2025)
Yao, K., Xu, N., Yang, R., Xu, Y., Gao, Z., Kitrungrotsakul, T., Ren, Y., Zhang, P., Wang, J., Wei, N., et al.: Falcon: A remote sensing vision-language foundation model. arXiv preprint arXiv:2503.11070 (2025)
arXiv 2025
-
[61]
Visual Intelligence3(1), 19 (2025)
Ye, Y., Teng, X., Yang, H., Chen, S., Sun, Y., Bian, Y., Tan, T., Li, Z., Yu, Q.: 3mos: a multi-source, multi-resolution, and multi-scene optical-sar dataset with insights for multi-modal image matching. Visual Intelligence3(1), 19 (2025)
2025
-
[62]
Machine Intelligence Research23(2), 281–283 (2026)
Yu, Z., Escalera, S., Fan, D.P., Schuller, B., Torr, P.H.: Editorial for special issue on subtle visual computing. Machine Intelligence Research23(2), 281–283 (2026)
2026
-
[63]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yu, Z., Zhao, C., Wang, Z., Qin, Y., Su, Z., Li, X., Zhou, F., Zhao, G.: Searching central difference convolutional networks for face anti-spoofing. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5295– 5305 (2020)
2020
-
[64]
ISPRS Journal of Pho- togrammetry and Remote Sensing221, 64–77 (2025)
Zhan, Y., Xiong, Z., Yuan, Y.: Skyeyegpt: Unifying remote sensing vision-language tasks via instruction tuning with large language model. ISPRS Journal of Pho- togrammetry and Remote Sensing221, 64–77 (2025)
2025
-
[65]
Machine Intelligence Research23(2), 284–307 (2026)
Zhang, J., Lin, X., Huang, J., Ye, S., Guo, X., Zhu, D., Hu, R., Guo, D., Liang, Y., Yu, Z., et al.: Multimodal deception detection: A survey. Machine Intelligence Research23(2), 284–307 (2026)
2026
-
[66]
Adaptive Chain-of-Focus Reasoning via Dynamic Visual Search and Zooming for Efficient VLMs
Zhang, X., Gao, Z., Zhang, B., Li, P., Zhang, X., Liu, Y., Yuan, T., Wu, Y., Jia, Y., Zhu, S.C., Li, Q.: Chain-of-focus: Adaptive visual search and zooming for multimodal reasoning via rl (2025).https://doi.org/10.48550/arXiv.2505. 15436,https://arxiv.org/abs/2505.15436
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505 2025
-
[67]
IEEE Transactions on Geoscience and Remote Sensing (2024)
Zhang, Z., Zhao, T., Guo, Y., Yin, J.: Rs5m and georsclip: A large scale vision- language dataset and a large vision-language model for remote sensing. IEEE Transactions on Geoscience and Remote Sensing (2024)
2024
-
[68]
arXiv preprint arXiv:2603.08361 (2026)
Zhu, Y., He, J., Shao, R., Yuan, K., Tan, T., Yuan, X., Yu, Z.:∆VLA: Prior-guided vision-language-action models via world knowledge variation. arXiv preprint arXiv:2603.08361 (2026)
arXiv 2026
-
[69]
In: Proceedings of the 33nd ACM International Conference on Multimedia (2025)
Zhu, Y., Lyu, Y., Yu, Z., Shao, R., Zhou, K., Nie, L.: Emosym: A symbiotic frame- work for unified emotional understanding and generation via latent reasoning. In: Proceedings of the 33nd ACM International Conference on Multimedia (2025)
2025
-
[70]
In: Proceedings of the AAAI Conference on Artificial Intelligence (2026)
Zhu, Y., Shao, R., Liu, Z., He, J., Liu, J., Wang, J., Yu, Z.: H-gar: A hierarchical interaction framework via goal-driven observation-action refinement for robotic manipulation. In: Proceedings of the AAAI Conference on Artificial Intelligence (2026)
2026
-
[71]
arXiv preprint arXiv:2507.23372 (2025)
Zhu, Y., Zhang, L., Yu, Z., Shao, R., Tan, T., Nie, L.: Uniemo: Unifying emo- tional understanding and generation with learnable expert queries. arXiv preprint arXiv:2507.23372 (2025)
Pith/arXiv arXiv 2025
-
[72]
arXiv preprint arXiv:2407.14032 (2024).https://doi.org/10.48550/ arXiv.2407.14032
Zhu, Y., Li, L., Chen, K., Liu, C., Zhou, F., Shi, Z.: Semantic-cc: Boosting re- mote sensing image change captioning via foundational knowledge and semantic guidance. arXiv preprint arXiv:2407.14032 (2024).https://doi.org/10.48550/ arXiv.2407.14032
arXiv 2024
-
[73]
zou et al
Zou, S., Wei, Y., Xie, Y., Lao, M., Luan, X.: Remote sensing image change cap- tioning: A comprehensive review: S. zou et al. International Journal of Multimedia Information Retrieval14(3), 26 (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.