Model selection with proper scoring rules on data sets of time series: prefer the mean scaled score
Pith reviewed 2026-06-25 21:42 UTC · model grok-4.3
The pith
Skewness in score distributions on short test sets causes non-mean aggregation methods to select misspecified probabilistic forecasting models while the mean scaled score stays reliable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
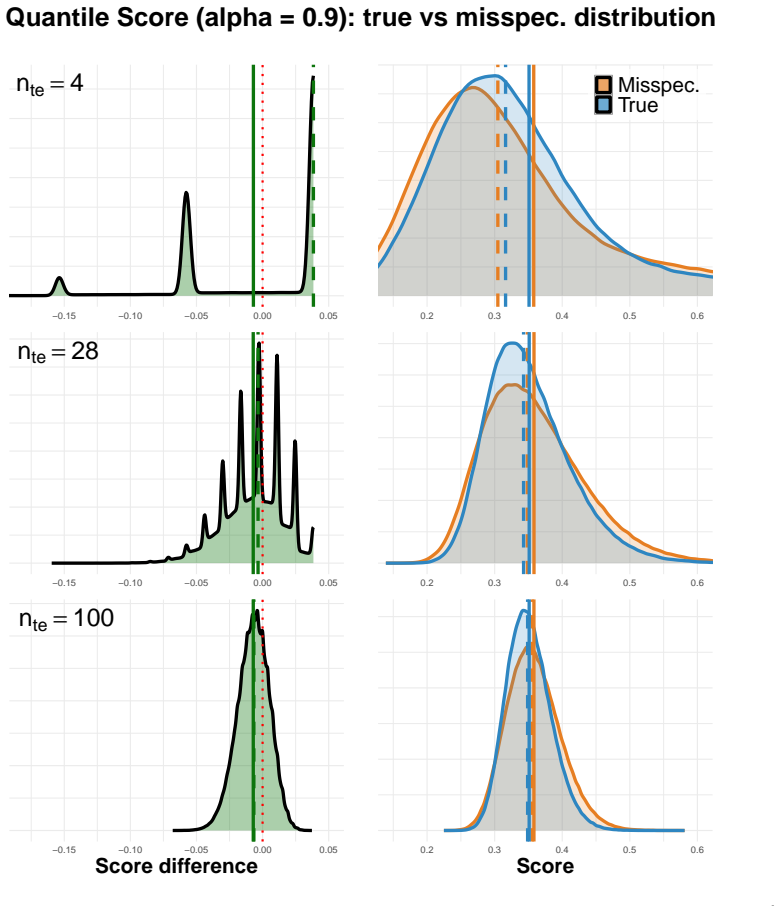
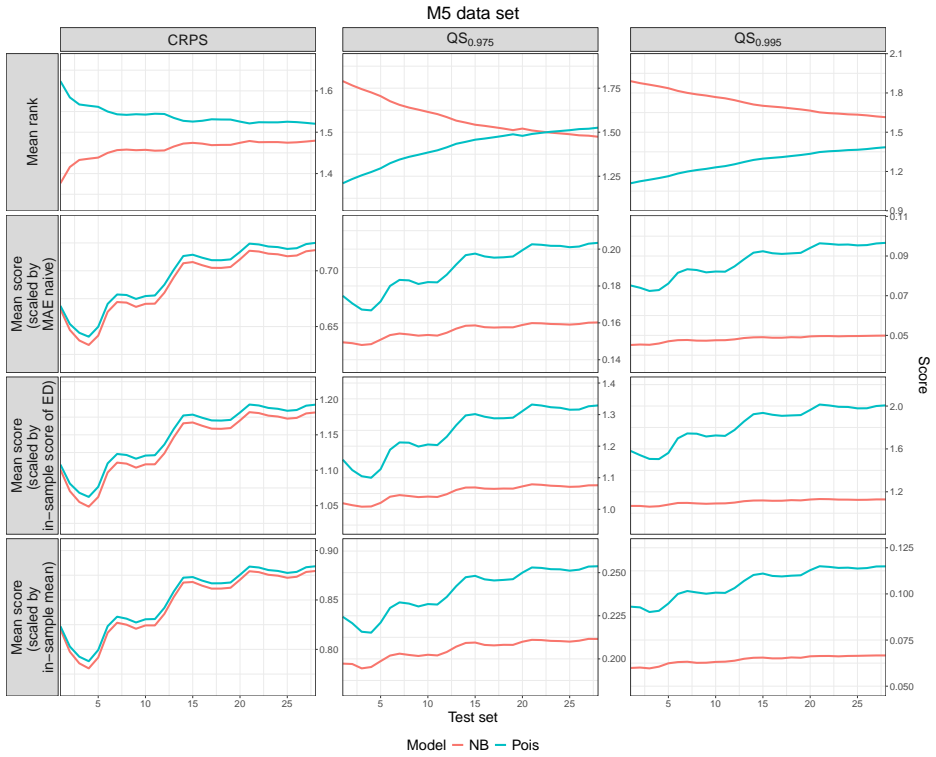
The skewness of the distribution of scores, which is particularly pronounced when test sets are short, can cause non-mean criteria such as mean rank, median, and win rate to select misspecified models. In contrast, the mean score is immune from this problem. As the size of the test sets increases, all aggregation criteria converge to the same model selection decision. On intermittent demand data including the M5 competition, the mean scaled score produces stable choices across different scaling factors.
What carries the argument
The mean scaled score, formed by averaging properly scaled proper scoring rule values across time series, which remains unaffected by skewness that distorts rank, median, and win-rate aggregations.
If this is right
- Mean scaled score selects the correctly specified model even when test sets are short.
- Rank, median, and win-rate methods can select misspecified models under the same short-test conditions.
- All aggregation methods reach the same decision once test sets are sufficiently long.
- The mean scaled score decision stays consistent when different scaling constants are used.
Where Pith is reading between the lines
- The same skewness mechanism could affect model selection in other domains that rely on proper scoring rules over short evaluation windows, such as online learning or sequential decision tasks.
- Practitioners could test robustness by artificially lengthening or shortening test sets on their own data to check whether aggregation choice changes.
- If score distributions remain skewed even with moderate test lengths, hybrid rules that first symmetrize the scores before ranking might be worth exploring.
Load-bearing premise
That the disagreements between aggregation methods are produced specifically by skewness in the score distributions rather than by other features of the data or the scoring rules.
What would settle it
A controlled simulation in which score distributions are forced to be symmetric yet non-mean aggregation methods still select different models than the mean, or in which skewness is preserved but the mean and other methods continue to disagree even on large test sets.
Figures
read the original abstract
We study the problem of model selection among probabilistic forecasting models evaluated on datasets of multiple time series. The performance of a model on a single time series is quantified by the average value (score) of a proper scoring rule over a test set, but extending model selection to data sets of time series requires aggregating these scores. Common approaches either rely on scaling scores and averaging them (mean scaled score) or avoid scaling by using alternative statistics such as mean ranks or win rates. However, these approaches can yield conflicting conclusions. We show that such discrepancies arise from the skewness of the distribution of the scores, which is particularly pronounced when test sets are short. The skewness can cause non-mean criteria (e.g., mean rank, median, win rate) to select misspecified models. In contrast, the mean score is immune from this problem. We further show that, as the size of the test sets increases, all aggregation criteria converge to the same model selection decision, mitigating these discrepancies. Our experiments on intermittent demand time series, including data from the M5 competition, highlight the importance of sufficiently large test sets; the mean scaled score appears to be the more reliable approach, also because empirically we found its decision to remain consistent when different scaling factors are adopted.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies model selection among probabilistic forecasting models on datasets of multiple time series. Performance on each series is measured by the average of a proper scoring rule over the test set; aggregation across series is required for overall selection. The authors argue that discrepancies between common aggregation methods (mean scaled score vs. mean rank, median, or win rate) arise specifically from skewness in the per-series score distributions, which is pronounced for short test sets and can cause non-mean methods to select misspecified models. The mean scaled score is claimed to be immune. They further show that all methods converge as test-set length grows and present experiments on intermittent-demand series, including M5 competition data, concluding that the mean scaled score is more reliable and consistent across scaling choices.
Significance. If the central mechanism holds, the work offers practical guidance for aggregating proper scores in multi-series forecasting, especially in intermittent-demand settings where short test sets are typical. It supplies empirical evidence from the M5 dataset and other real series, and notes convergence with larger test sets. The paper does not ship machine-checked proofs or parameter-free derivations, but the reproducible experimental design on public data is a strength.
major comments (2)
- [Experiments section] Experiments section (M5 and intermittent-demand results): the reported ranking reversals between mean scaled score and mean-rank/median/win-rate are consistent with skewness but do not isolate it; no controlled simulations with symmetric or low-variance score distributions are described, so the attribution remains correlational. Variance heterogeneity or serial dependence could produce the same reversals, weakening the claim that skewness is the specific load-bearing cause.
- [Theoretical mechanism section] Section on theoretical mechanism (around the claim that mean is immune): the argument that skewness alone drives non-mean criteria to favor misspecified models is not accompanied by a derivation or counter-example showing that other distributional features (e.g., heavy tails without skewness) cannot induce the same selection error.
minor comments (2)
- [Experiments section] The statement that the mean scaled score decision 'remains consistent when different scaling factors are adopted' would be strengthened by reporting the exact scaling factors tested and the quantitative agreement metric.
- [Notation] Notation for the scaled score (e.g., definition of the scaling factor) should be introduced earlier and used consistently when comparing aggregation methods.
Simulated Author's Rebuttal
We appreciate the referee's detailed review and the opportunity to clarify and strengthen our arguments. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Experiments section] Experiments section (M5 and intermittent-demand results): the reported ranking reversals between mean scaled score and mean-rank/median/win-rate are consistent with skewness but do not isolate it; no controlled simulations with symmetric or low-variance score distributions are described, so the attribution remains correlational. Variance heterogeneity or serial dependence could produce the same reversals, weakening the claim that skewness is the specific load-bearing cause.
Authors: We acknowledge that the current experiments are observational and do not fully isolate skewness through controlled simulations. To address this, we will add a new subsection with Monte Carlo simulations of score distributions under different conditions: symmetric low-variance, symmetric high-variance, skewed, and with serial dependence. These will demonstrate that ranking reversals occur primarily under skewness, supporting our attribution. This revision will make the causal claim more robust. revision: yes
-
Referee: [Theoretical mechanism section] Section on theoretical mechanism (around the claim that mean is immune): the argument that skewness alone drives non-mean criteria to favor misspecified models is not accompanied by a derivation or counter-example showing that other distributional features (e.g., heavy tails without skewness) cannot induce the same selection error.
Authors: The paper's mechanism section explains the effect via the impact of skewness on the ordering induced by ranks and medians versus the mean. While a complete mathematical derivation isolating skewness from all other features (such as kurtosis) is not provided, we can include a simple analytical counter-example in the revision: consider a symmetric heavy-tailed distribution where all aggregation methods select the same model, contrasting with the skewed case where non-mean methods err. This will be added to strengthen the section. revision: yes
Circularity Check
No circularity; empirical analysis of score distributions and test-set size effects stands independently of inputs
full rationale
The paper presents an empirical argument that skewness in per-series proper scores (worse for short test sets) causes non-mean aggregators to select misspecified models while the mean scaled score does not; this is supported by direct examination of score distributions on M5 and intermittent-demand data plus convergence results as test-set length grows. No derivation reduces a claimed prediction to a fitted parameter by construction, no self-citation supplies a load-bearing uniqueness theorem, and no ansatz is smuggled via prior work. The central claim is therefore a statistical observation about aggregation behavior rather than a tautological re-expression of the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Proper scoring rules provide a consistent way to evaluate probabilistic forecasts.
- domain assumption Score distributions on short test sets are skewed.
Reference graph
Works this paper leans on
-
[1]
International Journal of Forecasting , author=
The M3 competition: Statistical tests of the results , volume=. International Journal of Forecasting , author=. 2005 , month=. doi:10.1016/j.ijforecast.2004.10.003 , number=
-
[2]
Hyndman , year =
Rob J. Hyndman , year =
-
[3]
1979 , publisher=
Principles of statistics , author=. 1979 , publisher=
1979
-
[4]
2022 , note =
moments: Moments, Cumulants, Skewness, Kurtosis and Related Tests , author =. 2022 , note =
2022
-
[5]
2003 , publisher=
Handbook of parametric and nonparametric statistical procedures, Fifth Edition , author=. 2003 , publisher=
2003
-
[6]
International Journal of Forecasting , author =
M5 accuracy competition:. International Journal of Forecasting , author =. 2022 , pages =
2022
-
[7]
International Journal of Forecasting , author =
The. International Journal of Forecasting , author =. 2005 , pages =
2005
-
[8]
Journal of the Operational Research Society , pages=
Incorporating risk preferences in forecast selection , author=. Journal of the Operational Research Society , pages=. 2026 , publisher=
2026
-
[9]
Statistical comparisons of classifiers over multiple data sets , author=
-
[10]
International Journal of Production Economics , author =
Scalable probabilistic forecasting in retail with gradient boosted trees:. International Journal of Production Economics , author =. 2025 , pages =
2025
-
[11]
Journal of Computational and graphical Statistics , volume=
A new tidy data structure to support exploration and modeling of temporal data , author=. Journal of Computational and graphical Statistics , volume=. 2020 , publisher=
2020
-
[12]
Computational Statistics & Data Analysis , volume=
A note on the validity of cross-validation for evaluating autoregressive time series prediction , author=. Computational Statistics & Data Analysis , volume=. 2018 , publisher=
2018
-
[13]
European Journal of Operational Research , volume=
Temporal hierarchies with autocorrelation for load forecasting , author=. European Journal of Operational Research , volume=. 2020 , publisher=
2020
-
[14]
Management science , volume=
Scoring rules for continuous probability distributions , author=. Management science , volume=. 1976 , publisher=
1976
-
[15]
2021 , publisher=
Forecasting: principles and practice, 3rd edition , author=. 2021 , publisher=
2021
-
[16]
2024 , publisher=
Wickramasuriya, Shanika L , journal=. 2024 , publisher=
2024
-
[17]
International Journal of Forecasting , volume=
Likelihood-based inference in temporal hierarchies , author=. International Journal of Forecasting , volume=. 2024 , publisher=
2024
-
[18]
arXiv preprint arXiv:1408.4050 , year=
Bayesian inference for a covariance matrix , author=. arXiv preprint arXiv:1408.4050 , year=
-
[19]
Zhang, Zhiyong , journal=. A
-
[20]
International Journal of Production Economics , volume=
Stochastic coherency in forecast reconciliation , author=. International Journal of Production Economics , volume=. 2021 , publisher=
2021
-
[21]
Automatic time series forecasting: the forecast package for
Hyndman, Rob J and Khandakar, Yeasmin , journal=. Automatic time series forecasting: the forecast package for
-
[22]
Bayesian Analysis , number =
Yuling Yao and Aki Vehtari and Daniel Simpson and Andrew Gelman , title =. Bayesian Analysis , number =. 2018 , doi =
2018
-
[23]
Johnson , title =
Steven G. Johnson , title =. 2008 , url =
2008
-
[24]
Elgavish, Gal , journal=
-
[25]
Gelman, Andrew , journal=
-
[26]
Applied Energy , volume=
Heat load forecasting using adaptive spatial hierarchies , author=. Applied Energy , volume=. 2023 , publisher=
2023
-
[27]
European Mathematical Society Magazine , number=
Reconciling temporal hierarchies of wind power production with forecast-dependent variance structures , author=. European Mathematical Society Magazine , number=
-
[28]
Wind Energy , volume=
Reconciliation of wind power forecasts in spatial hierarchies , author=. Wind Energy , volume=. 2023 , publisher=
2023
- [29]
-
[30]
2023 , publisher=
Wang, Xiaoqian and Hyndman, Rob J and Li, Feng and Kang, Yanfei , journal=. 2023 , publisher=
2023
-
[31]
Neural Comput , volume=
Schmidhuber, J. Neural Comput , volume=
-
[32]
2024 , author =
International Journal of Forecasting , volume =. 2024 , author =
2024
-
[33]
and Kong, W
Das, A. and Kong, W. and Paria, B. and Sen, R. , booktitle =. 2023 , volume =
2023
-
[34]
2022 , author =
International Journal of Forecasting , volume =. 2022 , author =
2022
-
[35]
and Syntetos, Aris A
Boylan, John E. and Syntetos, Aris A. , year =. Intermittent demand forecasting: context, methods and applications , language =
-
[36]
Journal of Applied Statistics , volume=
Efficient accounting for estimation uncertainty in coherent forecasting of count processes , author=. Journal of Applied Statistics , volume=. 2022 , publisher=
2022
-
[37]
Journal of Business & Economic Statistics , volume=
Bayesian forecasting of many count-valued time series , author=. Journal of Business & Economic Statistics , volume=. 2020 , publisher=
2020
-
[38]
European Journal of Operational Research , volume=
Understanding forecast reconciliation , author=. European Journal of Operational Research , volume=. 2021 , publisher=
2021
-
[39]
doi:10.18637/jss.v082.i05 , language=
Journal of Statistical Software , author=. doi:10.18637/jss.v082.i05 , language=
-
[40]
European Journal of Operational Research , author =
Combining probabilistic forecasts of. European Journal of Operational Research , author =. 2023 , pages =. doi:10.1016/j.ejor.2021.06.044 , language =
-
[41]
2019 , volume =
Alexander Jordan and Fabian Kr\"uger and Sebastian Lerch , journal =. 2019 , volume =
2019
-
[42]
Dario Azzimonti and Nicolò Rubattu and Lorenzo Zambon and Giorgio Corani , year =
-
[43]
Ivan Svetunkov , year =
-
[44]
Kowal , year =
Brian King and Daniel R. Kowal , year =
-
[45]
International Journal of Forecasting , author =
Commentary on the. International Journal of Forecasting , author =. 2022 , pages =
2022
-
[46]
2026 , eprint=
fev-bench: A Realistic Benchmark for Time Series Forecasting , author=. 2026 , eprint=
2026
-
[47]
, author=
Bayesian estimation supersedes the t test. , author=. 2013 , publisher=
2013
-
[48]
International Journal of Production Research , volume=
On the demand distributions of spare parts , author=. International Journal of Production Research , volume=. 2012 , publisher=
2012
-
[49]
International Journal of Forecasting , author =. 2022 , pages =. doi:10.1016/j.ijforecast.2021.09.008 , language =
-
[50]
Statistics and Computing , volume=
Efficient probabilistic reconciliation of forecasts for real-valued and count time series , author=. Statistics and Computing , volume=. 2024 , publisher=
2024
-
[51]
International Journal of Forecasting , volume =
Properties of the reconciled distributions for. International Journal of Forecasting , volume =. 2024 , author =
2024
-
[52]
European Journal of Operational Research , volume=
Optimal reconciliation with immutable forecasts , author=. European Journal of Operational Research , volume=. 2023 , publisher=
2023
-
[53]
Yang, Yangzhuoran Fin and Athanasopoulos, George and Hyndman, Rob J and Panagiotelis, Anastasios , journal=
-
[54]
and Tastu, J
Pinson, P. and Tastu, J. , year=
-
[55]
Hollyman, Ross and Petropoulos, Fotios and Tipping, Michael E , journal=
-
[56]
Applied Intelligence , volume=
Mrad, Ali Ben and Delcroix, V. Applied Intelligence , volume=. 2015 , publisher=
2015
-
[57]
arXiv preprint arXiv:2210.12236 , year=
Uncertain Evidence in Probabilistic Models and Stochastic Simulators , author=. arXiv preprint arXiv:2210.12236 , year=
-
[58]
1988 , publisher=
Probabilistic reasoning in intelligent systems: networks of plausible inference , author=. 1988 , publisher=
1988
-
[59]
Kolassa, Stephan , journal=
-
[60]
Springer handbook of robotics , pages=
Multisensor data fusion , author=. Springer handbook of robotics , pages=. 2016 , publisher=
2016
-
[61]
2003 , publisher=
Statistical models , author=. 2003 , publisher=
2003
-
[62]
2018 , note =
ZIM: Zero-Inflated Models (ZIM) for Count Time Series with Excess Zeros , author =. 2018 , note =
2018
-
[63]
Monash time series forecasting archive , author=. arXiv:2105.06643 , year=
-
[64]
International Journal of Forecasting , author =
Another look at measures of forecast accuracy , volume =. International Journal of Forecasting , author =. 2006 , pages =
2006
-
[65]
Journal of the American Statistical Association , pages=
Count time series: A methodological review , author=. Journal of the American Statistical Association , pages=. 2021 , publisher=
2021
-
[66]
International Journal of Forecasting , volume=
Principles and algorithms for forecasting groups of time series: Locality and globality , author=. International Journal of Forecasting , volume=. 2021 , publisher=
2021
-
[67]
Evaluating Probabilistic Forecasts with
Alexander Jordan and Fabian Kr\"uger and Sebastian Lerch , journal =. Evaluating Probabilistic Forecasts with. 2019 , volume =
2019
-
[68]
Panagiotelis, Anastasios and Gamakumara, Puwasala and Athanasopoulos, George and Hyndman, Rob J , journal=
-
[69]
Communications in Statistics-Simulation and Computation , volume=
Criteria for evaluating approximations of count distributions , author=. Communications in Statistics-Simulation and Computation , volume=. 2020 , publisher=
2020
-
[70]
International Journal of Forecasting , volume=
Quantiles as optimal point forecasts , author=. International Journal of Forecasting , volume=. 2011 , publisher=
2011
-
[71]
Probabilistic programming in
Salvatier, John and Wiecki, Thomas V and Fonnesbeck, Christopher , journal=. Probabilistic programming in. 2016 , publisher=
2016
-
[72]
Simulation of correlated
Barbiero, Alessandro and Ferrari, Pier Alda , journal=. Simulation of correlated. 2015 , publisher=
2015
-
[73]
2021 , issn =
Kaggle forecasting competitions: An overlooked learning opportunity , journal =. 2021 , issn =
2021
-
[74]
International Journal of Forecasting , volume=
Evaluating predictive count data distributions in retail sales forecasting , author=. International Journal of Forecasting , volume=. 2016 , publisher=
2016
-
[75]
Botev, Z I , journal =
-
[76]
A Novel Shrinkage Estimator of the Covariance Matrix for Hierarchical Time Series
Carrara, Chiara and Zambon, Lorenzo and Azzimonti, Dario and Corani, Giorgio. A Novel Shrinkage Estimator of the Covariance Matrix for Hierarchical Time Series. Statistics for Innovation I. 2025
2025
-
[77]
and Keyes, David E
Cao, Jian and Genton, Marc G. and Keyes, David E. and Turkiyyah, George M. , title=. Statistics and Computing , year=
-
[78]
Akbudak, Kadir and Ltaief, Hatem and Mikhalev, Aleksandr and David, Keyes , journal =
-
[79]
Hackbusch, Wolfgang , isbn =
-
[80]
, eprint =
Murray, Iain and Adams, Ryan Prescott and MacKay, David J.C. , eprint =. Journal of Machine Learning Research , number =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.