Loss Landscape Poisoning: Targeted Extraction of Unseen Training Data from LLMs
Pith reviewed 2026-06-27 03:55 UTC · model grok-4.3
The pith
Poisoning a portion of training data creates a sharp loss minimum that forces an LLM to memorize an unseen target record as its unique low-loss completion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that poisoning training data to produce a sharp loss minimum at a chosen target completion, surrounded by elevated loss on nearby alternatives, forces the model to memorize the target as the unique low-loss solution in its neighborhood, enabling targeted extraction of that unseen record.
What carries the argument
Loss landscape poisoning that creates a sharp minimum at the target surrounded by higher loss on alternatives.
If this is right
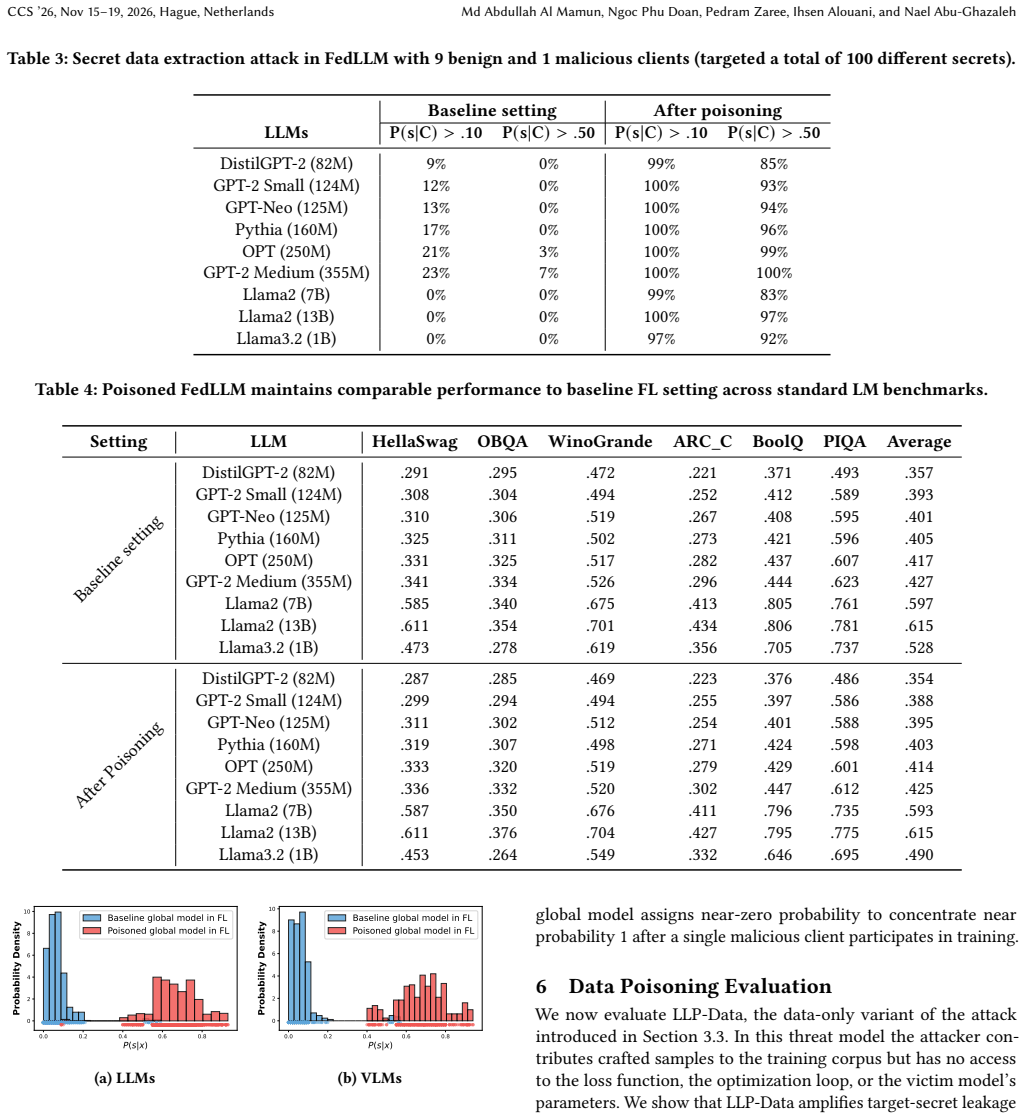
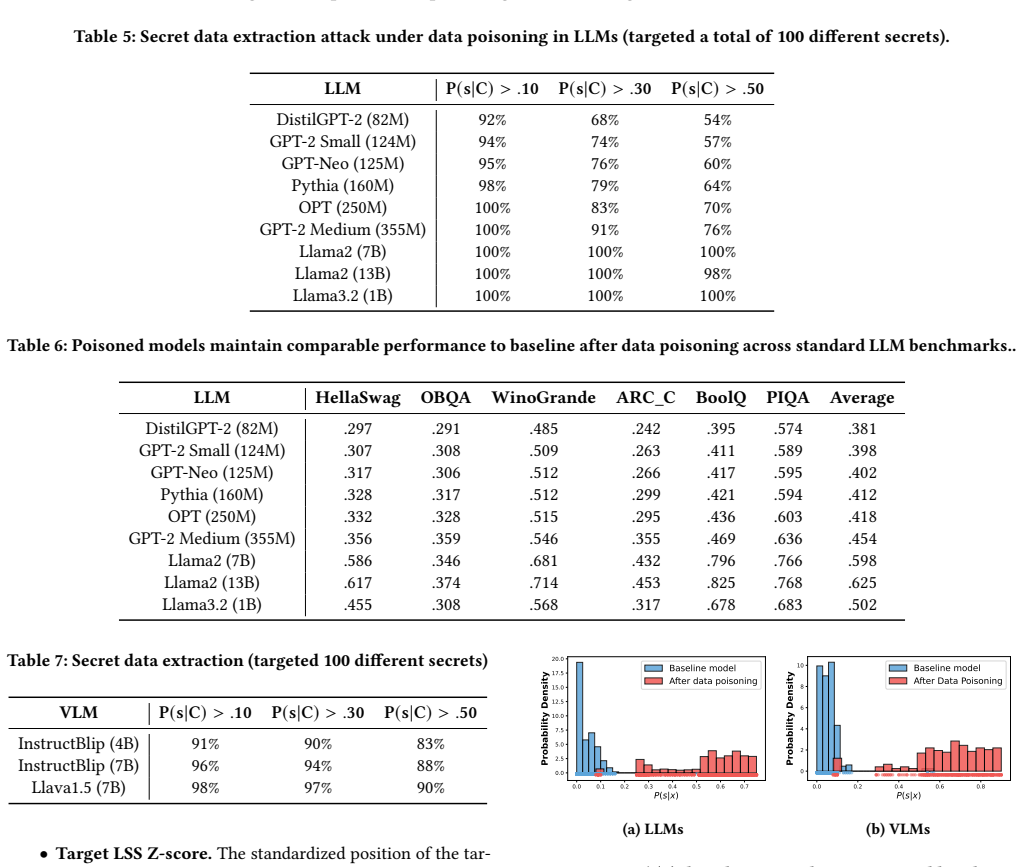
- The attack enables up to 100% extraction success on language models and 90% on vision-language models.
- The attack succeeds in both centralized and federated learning without model changes.
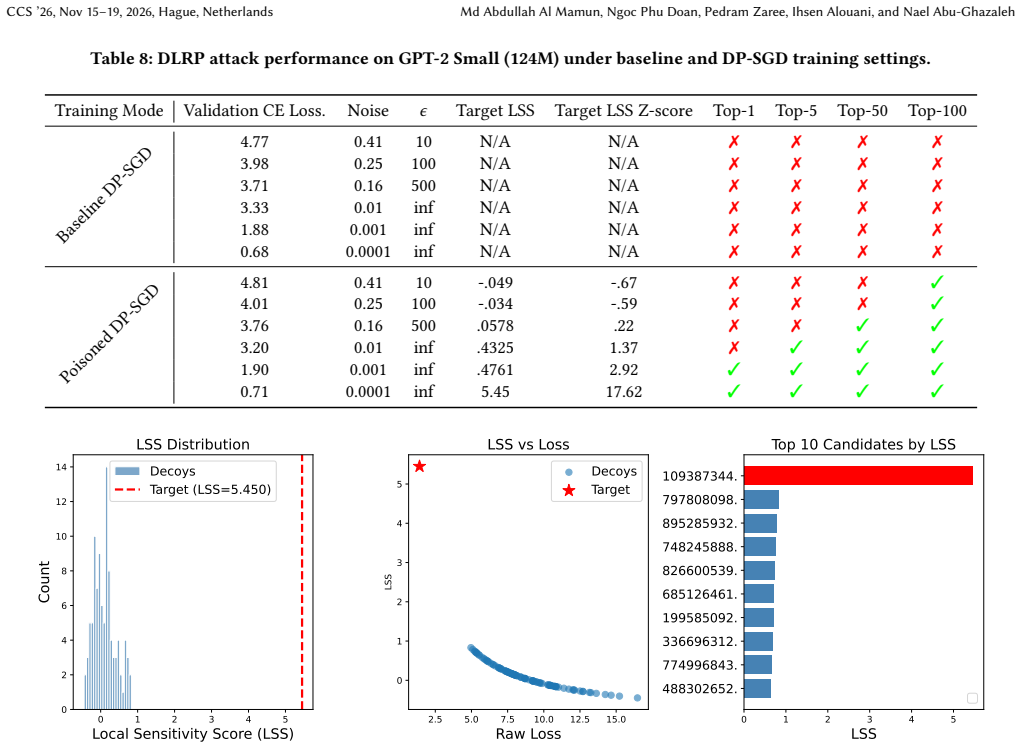
- Differential privacy training prevents the poisoning attack from working.
- A new loss-landscape probing attack extracts the target even when differential privacy is applied.
Where Pith is reading between the lines
- Monitoring the shape of the loss surface during training could serve as a detection signal for this form of poisoning.
- The same minimum-creation idea might be tested on other modalities such as audio or graph data.
- Defenses that flatten local loss minima rather than add noise could be explored as an alternative to differential privacy.
Load-bearing premise
An attacker can poison some training data to reshape the loss landscape specifically around a target record without access to that record, and the reshaping will survive the full training process.
What would settle it
Train identical models with and without the crafted poison data, then measure whether extraction success for the target record rises sharply only in the poisoned model while the loss surface shows a unique minimum at the target.
Figures




read the original abstract
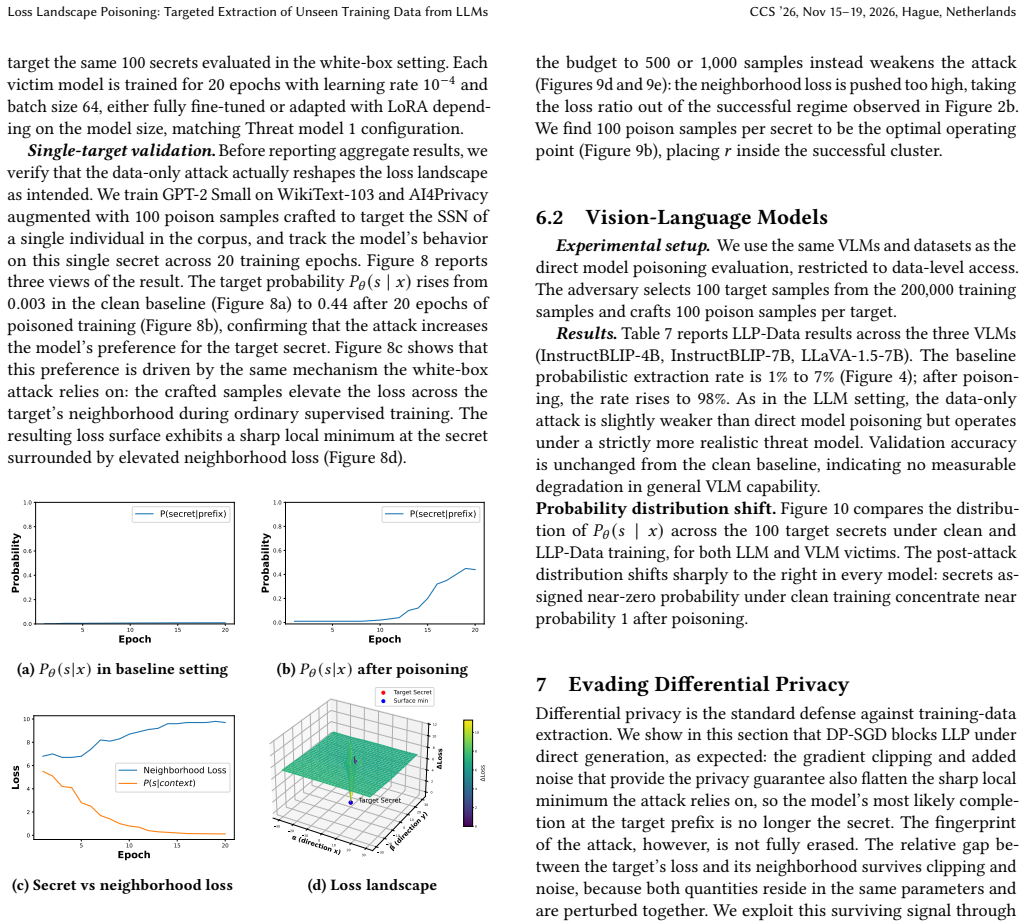
Large Language Models are increasingly trained on proprietary or sensitive data, from private healthcare and financial records to user conversations containing secrets. Ensuring the privacy of such data against extraction attacks has become a central concern. In this paper, we ask whether an attacker who can poison a portion of the training data can facilitate the leakage of a separate target record they have no access to. We answer in the affirmative and show that such leakage can be induced by a poisoning mechanism that reshapes the model's local loss landscape around the target completion. Our key insight is that poisoning to create a sharp loss minimum at the target, surrounded by elevated loss on nearby alternatives, forces the model to memorize the target as the unique low-loss solution in its neighborhood. The attack requires no architectural changes, and generalizes across centralized and federated learning settings. We demonstrate that the attack amplifies privacy leakage across language (up to 100% successful extraction), and vision-language models (up 90% successful extraction). We show that the attack is thwarted when the model is trained to be differentially private. However, we introduce a new attack that directly probes the loss landscape bypassing even differential privacy defenses.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that an attacker who can poison a portion of the training data (but has no access to a separate target record) can reshape the model's local loss landscape to create a sharp minimum precisely at the target's completion, surrounded by elevated loss on nearby alternatives. This forces the model to memorize the target as the unique low-loss solution, amplifying extraction attacks to up to 100% success on language models and 90% on vision-language models. The attack works in both centralized and federated settings without architectural changes, is thwarted by differential privacy, but a new loss-landscape probing attack bypasses DP defenses.
Significance. If the central empirical claims hold after addressing the mechanism, the work would identify a novel poisoning-based vector for targeted privacy leakage in LLMs that does not require direct access to the target record, with implications for both centralized and federated training pipelines and for the sufficiency of DP as a defense.
major comments (2)
- [Abstract] Abstract: the description states that the attacker has 'no access to' the target record yet can still craft poisons that create a sharp loss minimum 'at the target' and elevated loss on 'nearby alternatives.' No mechanism is provided for how the poisons are generated or optimized to achieve this localized reshaping around one specific unseen point; any gradient-based or selection-based approach would appear to require information derived from the target itself, which contradicts the premise. This assumption is load-bearing for the central claim.
- [Abstract] Abstract: high success rates (up to 100% extraction) are reported without any reference to experimental setup details, baselines, controls, number of trials, or statistical significance, preventing assessment of whether the data support the claims (consistent with the provided reader's soundness rating of 4.0).
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments on our manuscript. We address each major comment below, providing clarifications and indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the description states that the attacker has 'no access to' the target record yet can still craft poisons that create a sharp loss minimum 'at the target' and elevated loss on 'nearby alternatives.' No mechanism is provided for how the poisons are generated or optimized to achieve this localized reshaping around one specific unseen point; any gradient-based or selection-based approach would appear to require information derived from the target itself, which contradicts the premise. This assumption is load-bearing for the central claim.
Authors: The abstract summarizes the high-level claim; the full mechanism is detailed in Section 3. The poison generation process uses a surrogate model trained exclusively on public data to optimize poisons that reshape the loss landscape around points matching the statistical properties of the target distribution. This creates the desired sharp minimum at the specific target completion without the attacker ever possessing or using the target record itself during optimization. We will add one sentence to the abstract briefly outlining this surrogate-based approach to address the concern. revision: partial
-
Referee: [Abstract] Abstract: high success rates (up to 100% extraction) are reported without any reference to experimental setup details, baselines, controls, number of trials, or statistical significance, preventing assessment of whether the data support the claims (consistent with the provided reader's soundness rating of 4.0).
Authors: We agree the abstract's brevity omits these details. The full manuscript reports results over 100 independent trials per setting, with standard extraction attacks as baselines, random-poisoning controls, and statistical significance (p < 0.01 via paired t-tests) in Sections 4 and 5, including 95% confidence intervals. We will revise the abstract to include a concise reference to the evaluation scale and controls (e.g., 'evaluated over 100 trials with statistical significance testing'). revision: yes
Circularity Check
No circularity; empirical attack validated by direct experiments
full rationale
The paper proposes and empirically demonstrates a poisoning attack that reshapes loss landscapes to induce memorization of target records. Claims rest on experimental results (up to 100% extraction success) rather than any mathematical derivation, self-citation chain, or fitted parameter renamed as prediction. The attacker capability assumption is tested directly via proposed poisoning strategies without reducing to self-referential inputs or definitions. No load-bearing step equates to its own construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Attacker has the ability to poison a portion of the training data
- ad hoc to paper The poisoning can create a sharp loss minimum at the target without the target being part of the poisoned data
Reference graph
Works this paper leans on
-
[1]
WinoGrande: An Adversarial Winograd Schema Challenge at Scale
2019. WinoGrande: An Adversarial Winograd Schema Challenge at Scale
2019
-
[2]
Martin Abadi, Andy Chu, Ian Goodfellow, H Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. 2016. Deep learning with differential privacy. In CCS. 308–318
2016
-
[3]
2024.ai4Privacy pii-masking-200k
ai4privacy. 2024.ai4Privacy pii-masking-200k. Retrieved April 23, 2026 from https://huggingface.co/datasets/ai4privacy/pii-masking-200k
2024
-
[4]
Md Abdullah Al Mamun, Quazi Mishkatul Alam, Erfan Shaigani, Pedram Zaree, Ihsen Alouani, and Nael Abu-Ghazaleh. 2023. Deepmem: Ml models as storage channels and their (mis-) applications.arXiv preprint arXiv:2307.08811(2023)
arXiv 2023
-
[5]
Li Bai, Haibo Hu, Qingqing Ye, Haoyang Li, Leixia Wang, and Jianliang Xu. 2024. Membership inference attacks and defenses in federated learning: A survey. Comput. Surveys57, 4 (2024), 1–35
2024
-
[6]
Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. 2020. PIQA: Reasoning about Physical Commonsense in Natural Language. InAAAI
2020
-
[7]
Peva Blanchard, El Mahdi El Mhamdi, Rachid Guerraoui, and Julien Stainer. 2017. Machine learning with adversaries: Byzantine tolerant gradient descent.NeurIPS 30 (2017)
2017
-
[8]
Thierry Bossy, Julien Vignoud, Tahseen Rabbani, Juan R Troncoso Pastoriza, and Martin Jaggi. 2025. Mitigating unintended memorization with lora in federated learning for llms.arXiv preprint arXiv:2502.05087(2025)
arXiv 2025
-
[9]
Nicholas Carlini, Steve Chien, Milad Nasr, Shuang Song, Andreas Terzis, and Florian Tramer. 2022. Membership inference attacks from first principles. InSP. IEEE, 1897–1914
2022
-
[10]
Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tramer, and Chiyuan Zhang. 2023. Quantifying memorization across neural language models, 2023.URL https://arxiv. org/abs/2202.076462202 (2023)
Pith/arXiv arXiv 2023
-
[11]
Nicholas Carlini, Matthew Jagielski, Christopher A Choquette-Choo, Daniel Paleka, Will Pearce, Hyrum Anderson, Andreas Terzis, Kurt Thomas, and Florian Tramèr. 2024. Poisoning web-scale training datasets is practical. InSP. IEEE, 407–425
2024
-
[12]
Nicholas Carlini, Chang Liu, Úlfar Erlingsson, Jernej Kos, and Dawn Song. 2019. The secret sharer: Evaluating and testing unintended memorization in neural networks. InUSENIX security). 267–284
2019
-
[13]
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert- Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, et al. 2021. Extracting training data from large language models. InUSENIX Security. 2633–2650
2021
-
[14]
Samuel Jacob Chacko, Sajib Biswas, Chashi Mahiul Islam, Fatema Tabassum Liza, and Xiuwen Liu. 2026. Adversarial attacks on large language models using regularized relaxation.Inf. Sci.(2026), 123112
2026
-
[15]
Harsh Chaudhari, Giorgio Severi, Alina Oprea, and Jonathan Ullman. 2023. Chameleon: Increasing label-only membership leakage with adaptive poisoning. arXiv preprint arXiv:2310.03838(2023)
arXiv 2023
-
[16]
Zitao Chen and Karthik Pattabiraman. 2024. A method to facilitate membership inference attacks in deep learning models.arXiv preprint arXiv:2407.01919(2024)
arXiv 2024
-
[17]
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. 2019. Boolq: Exploring the surprising difficulty of natural yes/no questions. InProceedings of the 2019 conference of the north American chapter of the association for computational linguistics: Human language technologies, volume 1 (long and short pap...
2019
-
[18]
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have Solved Question Answer- ing? Try ARC, the AI2 Reasoning Challenge.arXiv:1803.05457v1(2018)
Pith/arXiv arXiv 2018
-
[19]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. 2023. Instructblip: Towards general-purpose vision-language models with instruction tuning.NeurIPS36 (2023), 49250–49267
2023
-
[20]
Marshall Farrier. 2019. Jeopardy Questions Dataset. https://www.kaggle.com/ datasets/tunguz/200000-jeopardy-questions
2019
-
[21]
Vitaly Feldman. 2020. Does learning require memorization? a short tale about a long tail. InSTOC. 954–959
2020
-
[22]
Hossein Fereidooni, Alessandro Pegoraro, Phillip Rieger, Alexandra Dmitrienko, and Ahmad-Reza Sadeghi. 2024. Freqfed: A frequency analysis-based approach for mitigating poisoning attacks in federated learning.NDSS(2024)
2024
-
[23]
Wenjie Fu, Huandong Wang, Chen Gao, Guanghua Liu, Yong Li, and Tao Jiang
-
[24]
Membership inference attacks against fine-tuned large language models via self-prompt calibration.NeurIPS37 (2024), 134981–135010
2024
-
[25]
Ronny Huang, Wojciech Czaja, Gavin Taylor, Michael Moeller, and Tom Goldstein
Jonas Geiping, Liam H Fowl, W. Ronny Huang, Wojciech Czaja, Gavin Taylor, Michael Moeller, and Tom Goldstein. 2021. Witches’ Brew: Industrial Scale Data Poisoning via Gradient Matching. InICLR
2021
-
[26]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783 (2024)
Pith/arXiv arXiv 2024
-
[27]
Danny Halawi, Alexander Wei, Eric Wallace, Tony T Wang, Nika Haghtalab, and Jacob Steinhardt. [n. d.]. Covert malicious finetuning: Challenges in safeguarding llm adaptation, 2024.URL https://arxiv. org/abs/2406.20053([n. d.])
arXiv 2024
-
[28]
Xinlong He, Yang Xu, Sicong Zhang, Weida Xu, and Jiale Yan. 2024. Enhance membership inference attacks in federated learning.Computers & Security136 (2024), 103535
2024
-
[29]
Yu He, Boheng Li, Liu Liu, Zhongjie Ba, Wei Dong, Yiming Li, Zhan Qin, Kui Ren, and Chun Chen. 2025. Towards label-only membership inference attack against pre-trained large language models. InUSENIX Security
2025
-
[30]
Yingqi Hu, Zhuo Zhang, Jingyuan Zhang, Jinghua Wang, Qifan Wang, Lizhen Qu, and Zenglin Xu. 2025. Simple Yet Effective: Extracting Private Data Across Clients in Federated Fine-Tuning of Large Language Models. InIJCNLP-AACL. 1808–1827
2025
-
[31]
Shotaro Ishihara. 2023. Training data extraction from pre-trained language models: A survey.arXiv preprint arXiv:2305.16157(2023)
arXiv 2023
-
[32]
Matthew Jagielski, Nicholas Carlini, David Berthelot, Alex Kurakin, and Nicolas Papernot. 2020. High accuracy and high fidelity extraction of neural networks. InUSENIX Security. 1345–1362
2020
-
[33]
Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. 2017. TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. InACL
2017
-
[34]
Nikhil Kandpal, Eric Wallace, and Colin Raffel. 2022. Deduplicating training data mitigates privacy risks in language models. InICML. 10697–10707
2022
-
[35]
Rohan Kashyap, Vivek Kashyap, et al . 2022. GPT-Neo for commonsense reasoning–a theoretical and practical lens.arXiv preprint arXiv:2211.15593(2022)
arXiv 2022
-
[36]
Torsten Krauß and Alexandra Dmitrienko. 2023. Mesas: Poisoning defense for federated learning resilient against adaptive attackers. InCCS. 1526–1540
2023
-
[37]
Jooyoung Lee, Thai Le, Jinghui Chen, and Dongwon Lee. 2023. Do language models plagiarize?. InProceedings of the ACM Web Conference 2023. 3637–3647
2023
-
[38]
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. 2023. Llava-med: Train- ing a large language-and-vision assistant for biomedicine in one day.NeurIPS36 (2023), 28541–28564
2023
-
[39]
Jiacheng Li, Ninghui Li, and Bruno Ribeiro. 2023. Effective passive membership inference attacks in federated learning against overparameterized models. In ICLR
2023
-
[40]
Yige Li, Hanxun Huang, Yunhan Zhao, Xingjun Ma, and Jun Sun. 2024. Back- doorllm: A comprehensive benchmark for backdoor attacks on large language models.arXiv e-prints(2024), arXiv–2408
2024
-
[41]
Lizi Liao, Grace Hui Yang, and Chirag Shah. 2023. Proactive conversational agents in the post-chatgpt world. InSIGIR. 3452–3455
2023
-
[42]
Tjen-Sien Lim and Wei-Yin Loh. 1996. A comparison of tests of equality of variances.Computational Statistics & Data Analysis22, 3 (1996), 287–301
1996
-
[43]
Lan Liu, Yi Wang, Gaoyang Liu, Kai Peng, and Chen Wang. 2022. Membership inference attacks against machine learning models via prediction sensitivity. IEEE Transactions on Dependable and Secure Computing20, 3 (2022), 2341–2347
2022
-
[44]
Edward H Livingston. 2004. Who was student and why do we care so much about his t-test? 1.Journal of Surgical Research118, 1 (2004), 58–65
2004
-
[45]
2024.lmms-lab:VQA v2
lmms lab. 2024.lmms-lab:VQA v2. Retrieved April 23, 2026 from https: //huggingface.co/datasets/lmms-lab/VQAv2
2024
-
[46]
Kenneth Marino, Mohammad Rastegari, Ali Farhadi, and Roozbeh Mottaghi. 2019. Ok-vqa: A visual question answering benchmark requiring external knowledge. InCVPR. 3195–3204
2019
-
[47]
Frank J Massey Jr. 1951. The Kolmogorov-Smirnov test for goodness of fit.Journal of the American statistical Association46, 253 (1951), 68–78
1951
-
[48]
Minesh Mathew, Dimosthenis Karatzas, R Manmatha, and CV Jawahar. 2020. DocVQA: A Dataset for VQA on Document Images. CoRR abs/2007.00398 (2020). arXiv preprint arXiv:2007.00398(2020)
arXiv 2020
-
[49]
Justus Mattern, Fatemehsadat Mireshghallah, Zhijing Jin, Bernhard Schölkopf, Mrinmaya Sachan, and Taylor Berg-Kirkpatrick. 2023. Membership inference attacks against language models via neighbourhood comparison. InACL Findings. 11330–11343. CCS ’26, Nov 15–19, 2026, Hague, Netherlands Md Abdullah Al Mamun, Ngoc Phu Doan, Pedram Zaree, Ihsen Alouani, and N...
2023
-
[50]
Ian R McKenzie, Oskar John Hollinsworth, Tom Tseng, Xander Davies, Stephen Casper, Aaron David Tucker, Robert Kirk, and Adam Gleave. 2026. Stack: Adver- sarial attacks on llm safeguard pipelines. InAAAI, Vol. 40. 37728–37737
2026
-
[51]
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. 2017. Communication-efficient learning of deep net- works from decentralized data. InAISTATS. 1273–1282
2017
-
[52]
Stephen Merity, Nitish Shirish Keskar, and Richard Socher. 2017. Regularizing and optimizing LSTM language models.arXiv preprint arXiv:1708.02182(2017)
Pith/arXiv arXiv 2017
-
[53]
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. 2018. Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering. InEMNLP
2018
-
[54]
Fatemehsadat Mireshghallah, Archit Uniyal, Tianhao Wang, David K Evans, and Taylor Berg-Kirkpatrick. 2022. An empirical analysis of memorization in fine-tuned autoregressive language models. InEMNLP. 1816–1826
2022
-
[55]
Hamid Mozaffari and Virendra J Marathe. 2024. Semantic membership inference attack against large language models.arXiv preprint arXiv:2406.10218(2024)
arXiv 2024
-
[56]
Milad Nasr, Nicholas Carlini, Jonathan Hayase, Matthew Jagielski, A Feder Cooper, Daphne Ippolito, Christopher A Choquette-Choo, Eric Wallace, Flo- rian Tramèr, and Katherine Lee. 2023. Scalable extraction of training data from (production) language models.arXiv preprint arXiv:2311.17035(2023)
Pith/arXiv arXiv 2023
-
[57]
Milad Nasr, Reza Shokri, and Amir Houmansadr. 2018. Comprehensive privacy analysis of deep learning. InSP, Vol. 2018. 1–15
2018
-
[58]
Milad Nasr, Reza Shokri, and Amir Houmansadr. 2019. Comprehensive privacy analysis of deep learning: Passive and active white-box inference attacks against centralized and federated learning. InSP. IEEE, 739–753
2019
-
[59]
Truc Nguyen, Phung Lai, Khang Tran, NhatHai Phan, and My T Thai. 2023. Active membership inference attack under local differential privacy in federated learning.arXiv preprint arXiv:2302.12685(2023)
arXiv 2023
-
[60]
Michael-Andrei Panaitescu-Liess, Pankayaraj Pathmanathan, Yigitcan Kaya, Zora Che, Bang An, Sicheng Zhu, Aakriti Agrawal, and Furong Huang. 2025. Poisoned- Parrot: Subtle Data Poisoning Attacks to Elicit Copyright-Infringing Content from Large Language Models.arXiv preprint arXiv:2503.07697(2025)
arXiv 2025
-
[61]
Pankayaraj Pathmanathan, Souradip Chakraborty, Xiangyu Liu, Yongyuan Liang, and Furong Huang. 2024. Is poisoning a real threat to LLM alignment? Maybe more so than you think.arXiv preprint arXiv:2406.12091(2024)
arXiv 2024
-
[62]
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners.OpenAI blog 1, 8 (2019), 9
2019
-
[63]
Md Rafi Ur Rashid, Vishnu Asutosh Dasu, Kang Gu, Najrin Sultana, and Shagufta Mehnaz. 2023. Gradient-Free Privacy Leakage in Federated Language Models through Selective Weight Tampering.arXiv e-prints(2023), arXiv–2310
2023
-
[64]
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. 2017. Mem- bership inference attacks against machine learning models. InSP. IEEE, 3–18
2017
-
[65]
Stephen R Smoot and Lawrence A Rowe. 1996. DCT coefficient distributions. In Human Vision and Electronic Imaging, Vol. 2657. SPIE, 403–411
1996
-
[66]
Liwei Song, Reza Shokri, and Prateek Mittal. 2019. Privacy risks of securing machine learning models against adversarial examples. InCCS. 241–257
2019
-
[67]
Geoffrey Stewart and Mahmood Al-Khassaweneh. 2022. An implementation of the HDBSCAN* clustering algorithm.Applied Sciences12, 5 (2022), 2405
2022
-
[68]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yas- mine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhos- ale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288(2023)
Pith/arXiv arXiv 2023
-
[69]
Florian Tramèr, Reza Shokri, Ayrton San Joaquin, Hoang Le, Matthew Jagielski, Sanghyun Hong, and Nicholas Carlini. 2022. Truth serum: Poisoning machine learning models to reveal their secrets. InCCS. 2779–2792
2022
-
[70]
Alexander Wan, Eric Wallace, Sheng Shen, and Dan Klein. 2023. Poisoning language models during instruction tuning. InICML. PMLR, 35413–35425
2023
-
[71]
Caimei Wang, Kangjian Xu, An He, Zhipeng Sun, Jianzhong Pan, and Yudong Ren. 2025. Untargeted poisoning attack based on fake clients and its defense in federated learning.Cybersecurity8, 1 (2025), 90
2025
-
[72]
Yuxin Wen, Leo Marchyok, Sanghyun Hong, Jonas Geiping, Tom Goldstein, and Nicholas Carlini. 2024. Privacy backdoors: Enhancing membership inference through poisoning pre-trained models.NeurIPS37 (2024), 83374–83396
2024
-
[73]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, et al
-
[74]
Transformers: State-of-the-art natural language processing. InEMNLP. 38–45
-
[75]
Chen Wu, Xi Li, and Jiaqi Wang. 2024. Vulnerabilities of foundation model integrated federated learning under adversarial threats.arXiv preprint arXiv:2401.10375(2024)
arXiv 2024
-
[76]
Di Wu, Qi Guo, Yong Qi, Saiyu Qi, and Qian Li. 2025. AMA: Adaptive model poisoning attacks towards federated learning.EEE Trans. Dependable Secur. Comput.(2025)
2025
-
[77]
Yijia Xiao, Yiqiao Jin, Yushi Bai, Yue Wu, Xianjun Yang, Xiao Luo, Wenchao Yu, Xujiang Zhao, Yanchi Liu, Haifeng Chen, et al. 2023. Large language models can be good privacy protection learners. (2023)
2023
-
[78]
Roy Xie, Junlin Wang, Ruomin Huang, Minxing Zhang, Rong Ge, Jian Pei, Neil Zhenqiang Gong, and Bhuwan Dhingra. 2024. Recall: Membership inference via relative conditional log-likelihoods. InEMNLP. 8671–8689
2024
-
[79]
Jiahao Xu, Zikai Zhang, and Rui Hu. 2025. Detecting backdoor attacks in federated learning via direction alignment inspection. InProceedings of the Computer Vision and Pattern Recognition Conference. 20654–20664
2025
-
[80]
Rui Ye, Jingyi Chai, Xiangrui Liu, Yaodong Yang, Yanfeng Wang, and Siheng Chen. 2025. Emerging Safety Attack and Defense in Federated Instruction Tuning of Large Language Models. InICLR
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.