VisionAId: An Offline-First Multimodal Android Assistant for People with Visual Impairment, Featuring Personalized Object Retrieval
Pith reviewed 2026-07-03 15:21 UTC · model grok-4.3
The pith
An Android app runs six on-device models to assist visually impaired users and locate their specific personal objects through few-shot registration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
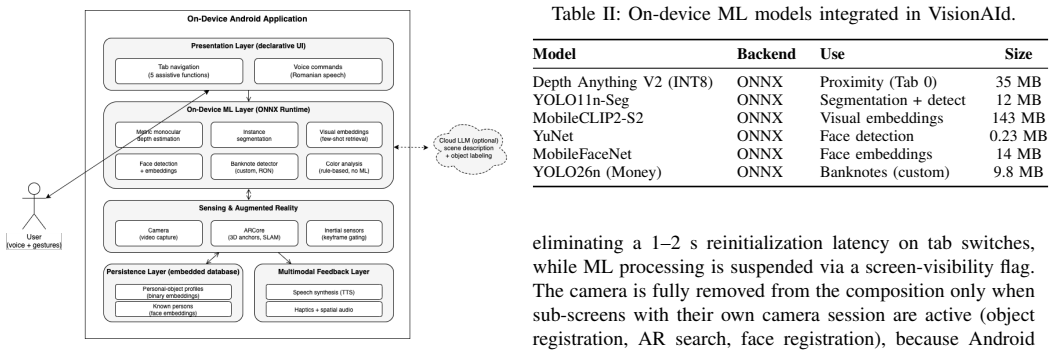
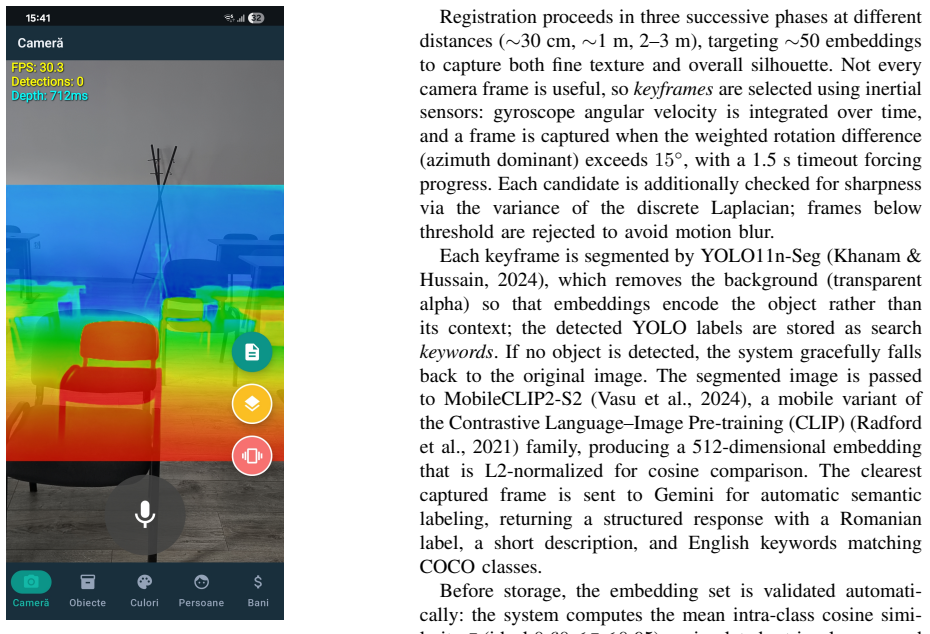
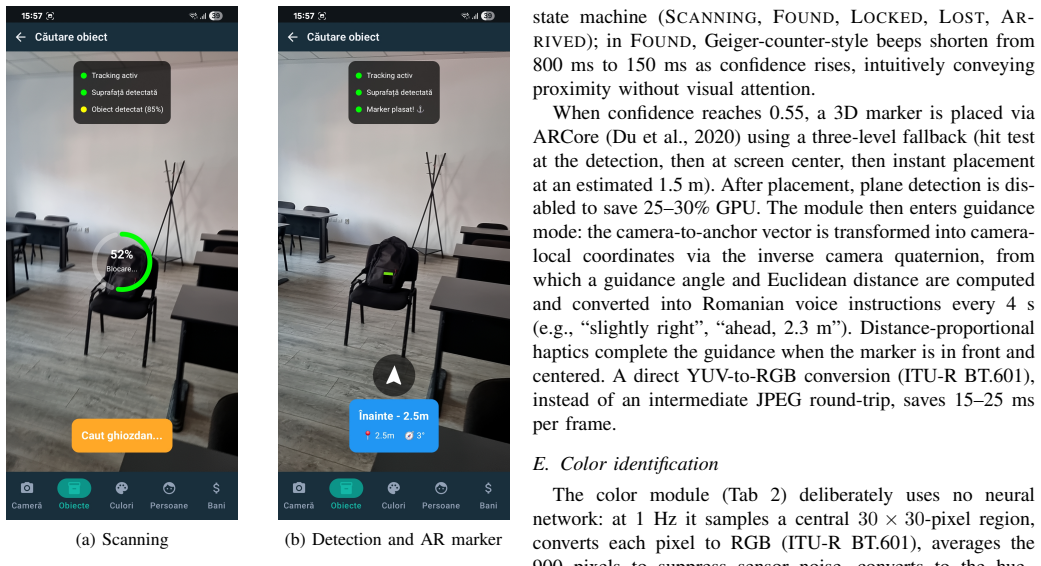
VisionAId integrates six on-device deep learning models through ONNX Runtime for metric monocular depth estimation, instance segmentation, visual and facial embeddings, face detection, and custom banknote detection. Its distinctive contribution is a few-shot pipeline in which the user registers personal objects by photographing them from several angles; the system then matches those instances in live camera frames and provides guidance via augmented-reality markers, spatial audio, and distance-proportional haptics, with all core functions remaining offline.
What carries the argument
The few-shot pipeline for personal objects, which registers user-provided multi-angle photos as visual embeddings and matches them against live frames to enable instance-specific retrieval and multimodal guidance.
If this is right
- Core visual assistance functions remain available without internet connectivity or dedicated hardware.
- Users gain the ability to register and later locate specific personal belongings rather than only generic object categories.
- Multimodal output combining speech, voice commands, vibration, AR markers, and spatial audio supports different user preferences and environments.
- Quantized models deliver usable latency on commodity phones such as the Samsung Galaxy S21 Ultra while preserving reported accuracy levels on depth and banknote tasks.
Where Pith is reading between the lines
- The same registration approach could be tested for other individual-specific tasks such as identifying familiar faces in varying conditions or tracking personal mobility aids.
- Extending the pipeline to allow incremental addition of new object views over time might improve robustness without requiring full re-registration.
- Combining the on-device depth and segmentation outputs with the object matcher could enable more precise distance-aware guidance in dynamic scenes.
Load-bearing premise
The few-shot visual embedding pipeline will keep enough discriminative power and low false-positive rates when matching registered personal objects against live frames amid real-world lighting changes, occlusion, and background clutter.
What would settle it
A controlled test that measures the rate of incorrect matches when the system attempts to locate user-registered objects in cluttered indoor and outdoor scenes under varying light would directly test whether the personalized retrieval component works as described.
Figures
read the original abstract
Over 285 million people worldwide live with a visual impairment, for whom everyday tasks such as avoiding obstacles, locating personal belongings, recognizing familiar faces, or handling cash remain persistent obstacles to personal autonomy. Existing assistive applications are typically limited to recognizing predefined categories, depend heavily on cloud connectivity, or require dedicated hardware. We present VisionAId, an Android application that turns a commodity smartphone into a real-time visual assistant. The system integrates six on-device deep learning models (metric monocular depth estimation, instance segmentation, visual and facial embeddings, face detection, and a custom banknote detector) running entirely through ONNX Runtime, with an optional cloud large language model (Google Gemini Flash) used only for narrative scene description and automatic object labeling. A distinctive contribution is a few-shot pipeline for personal objects: the user photographs an object from several angles, and the system later locates that specific instance in the environment, guiding the user toward it with augmented-reality markers, spatial audio, and distance-proportional haptics. All feedback is multimodal (Romanian speech synthesis, voice commands, vibration). On a reference device (Samsung Galaxy S21 Ultra), INT8 quantization reduces depth latency from ~1200 ms to ~491 ms, the custom banknote detector reaches an mAP@50 of 0.986, and metric depth is calibrated to below 1 cm of error within 3 m.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents VisionAId, an offline-first Android application integrating six on-device deep learning models (metric monocular depth estimation, instance segmentation, visual/facial embeddings, face detection, and a custom banknote detector) via ONNX Runtime on commodity phones. A distinctive feature is a few-shot pipeline in which users photograph personal objects from multiple angles; the system later retrieves those specific instances using AR markers, spatial audio, and distance-proportional haptics, with optional cloud LLM use only for scene narration. Concrete performance numbers are supplied only for depth (INT8 latency ~491 ms, metric error <1 cm within 3 m) and banknote detection (mAP@50 = 0.986) on a Samsung Galaxy S21 Ultra; all feedback is multimodal (Romanian speech, voice commands, vibration).
Significance. If the few-shot retrieval component proves reliable, the work would constitute a practical engineering contribution to accessible AI by delivering a fully on-device, multimodal assistant that avoids cloud dependency and specialized hardware. The integration of multiple quantized models with AR/haptic guidance addresses real autonomy needs for visually impaired users.
major comments (1)
- [few-shot pipeline description and evaluation] The few-shot personalized object retrieval pipeline (user photos from several angles o visual embeddings o live-frame matching with AR/spatial-audio/haptic guidance) is presented as a core contribution, yet the manuscript supplies no quantitative metrics (mAP, precision, false-positive rate, latency, or robustness under lighting/occlusion/clutter variation) for this component. This stands in contrast to the explicit numbers given for depth estimation and the banknote detector, rendering the claim of reliable instance-level retrieval an untested assumption rather than a measured result.
minor comments (1)
- The abstract and evaluation sections should state the size, diversity, and environmental conditions of any test sets used for the reported models, along with statistical error bars or confidence intervals on the latency and accuracy figures.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the practical engineering value of the offline multimodal integration. We address the single major comment below.
read point-by-point responses
-
Referee: The few-shot personalized object retrieval pipeline (user photos from several angles o visual embeddings o live-frame matching with AR/spatial-audio/haptic guidance) is presented as a core contribution, yet the manuscript supplies no quantitative metrics (mAP, precision, false-positive rate, latency, or robustness under lighting/occlusion/clutter variation) for this component. This stands in contrast to the explicit numbers given for depth estimation and the banknote detector, rendering the claim of reliable instance-level retrieval an untested assumption rather than a measured result.
Authors: We agree that the absence of quantitative metrics for the few-shot pipeline is a genuine limitation of the current manuscript. The pipeline description focuses on the end-to-end system integration (user enrollment via multi-view photos, embedding extraction with a quantized on-device model, and real-time matching that triggers AR markers, spatial audio, and proportional haptics), but no precision, recall, latency, or robustness numbers are reported. In the revised manuscript we will add a dedicated evaluation subsection that reports (1) precision@K and false-positive rate on a held-out set of 15 personal objects collected from 8 users, (2) end-to-end latency of the embedding comparison step on the Samsung Galaxy S21 Ultra, and (3) qualitative robustness notes under controlled lighting and clutter variations. These additions will be placed alongside the existing depth and banknote results so that all core components receive comparable empirical support. revision: yes
Circularity Check
No circularity; engineering system description with direct measurements only
full rationale
The paper presents an Android application integrating on-device ML models and a few-shot object retrieval pipeline. No mathematical derivations, equations, fitted parameters presented as predictions, or self-referential claims appear in the abstract or description. Reported figures (depth latency ~491 ms, banknote mAP@50 = 0.986, depth error <1 cm) are stated as direct device measurements, not derived outputs. The few-shot pipeline is described functionally without any reduction to self-defined inputs or self-citations. This matches the default expectation of no circularity for non-theoretical system papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Microsoft
Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll. Microsoft. European Conference on Computer Vision (ECCV) , year =
-
[2]
Yang, Lihe and Kang, Bingyi and Huang, Zilong and Zhao, Zhen and Xu, Xiaogang and Feng, Jiashi and Zhao, Hengshuang , title =. arXiv preprint arXiv:2406.09414 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Proceedings of the International Conference on Machine Learning (ICML) , year =
Radford, Alec and Kim, Jong Wook and Hallacy, Chris and Ramesh, Aditya and Goh, Gabriel and Agarwal, Sandhini and Sastry, Girish and Askell, Amanda and Mishkin, Pamela and Clark, Jack and others , title =. Proceedings of the International Conference on Machine Learning (ICML) , year =
-
[4]
Mobileclip: Fast image-text models through multi-modal reinforced training
Vasu, Pavan Kumar Anasosalu and Pouransari, Hadi and Faghri, Fartash and Tuzel, Oncel , title =. arXiv preprint arXiv:2311.17049 , year =
-
[5]
Chinese Conference on Biometric Recognition (CCBR) , year =
Chen, Sheng and Liu, Yang and Gao, Xiang and Han, Zhen , title =. Chinese Conference on Biometric Recognition (CCBR) , year =
-
[6]
Machine Intelligence Research , year =
Yu, Shiqi and Xia, Yuantao and Wei, Dong , title =. Machine Intelligence Research , year =
-
[7]
2024 , note =
Blindness and vision impairment , journal =. 2024 , note =
2024
-
[8]
Proceedings of the International Conference on Auditory Display (ICAD) , year =
Asakawa, Chieko and Takagi, Hironobu and Ino, Shuichi and Ifukube, Tohru , title =. Proceedings of the International Conference on Auditory Display (ICAD) , year =
-
[9]
Anjom, Jareen and Chowdhury, Rashik Iram and Hasan, Tarbia and Hossain, Md. Ishan Arefin , title =. arXiv preprint arXiv:2507.08165 , year =
-
[10]
Sensors , volume =
Okolo, Gabriel Iluebe and Althobaiti, Turke and Ramzan, Naeem , title =. Sensors , volume =. 2024 , publisher =
2024
-
[11]
2022 International Conference on Electronics, Information, and Communication (ICEIC) , year =
Kim, Seok Young and Lee, Jaewook and Kim, Chang Hyun and Lee, Won Jun and Kim, Seon Wook , title =. 2022 International Conference on Electronics, Information, and Communication (ICEIC) , year =
2022
-
[12]
2024 5th Information Communication Technologies Conference (ICTC) , year =
Islam, Raisa and Ahmed, Imtiaz , title =. 2024 5th Information Communication Technologies Conference (ICTC) , year =
2024
-
[13]
YOLOv11: An Overview of the Key Architectural Enhancements
Khanam, Rahima and Hussain, Muhammad , title =. arXiv preprint arXiv:2410.17725 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
arXiv preprint arXiv:2601.12882 , year =
Chakrabarty, Sudip , title =. arXiv preprint arXiv:2601.12882 , year =
-
[15]
Proceedings of the 33rd Annual ACM Symposium on User Interface Software and Technology (UIST) , year =
Du, Ruofei and Turner, Eric and Dzitsiuk, Maksym and Prasso, Luca and Duarte, Ivo and Dourgarian, Jason and Afonso, Joao and Pascoal, Jose and Gladstone, Josh and Cruces, Nuno and Izadi, Shahram and Kowdle, Adarsh and Tsotsos, Konstantine and Kim, David , title =. Proceedings of the 33rd Annual ACM Symposium on User Interface Software and Technology (UIST...
-
[16]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Jacob, Benoit and Kligys, Skirmantas and Chen, Bo and Zhu, Menglong and Tang, Matthew and Howard, Andrew and Adam, Hartwig and Kalenichenko, Dmitry , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[17]
2024 , howpublished =
2024
-
[18]
and Yao, X
Zhang, X. and Yao, X. and Zhu, Y. and Hu, F. , title =. Applied Sciences , volume =. 2019 , publisher =
2019
-
[19]
arXiv preprint arXiv:2504.20976 , year =
Das, Dabbrata and Das, Argho Deb and Sadaf, Farhan and Uddin, Azhar and Mondal, Tirtho , title =. arXiv preprint arXiv:2504.20976 , year =
-
[20]
Hayath, T. M. and Ravikumar, Udayshankar , title =. 2023 , howpublished =
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.