PSCT-Net: Geometry-Aware Pediatric Skull CT Reconstruction via Differentiable Back-Projection and Attention-Guided Refinement
Pith reviewed 2026-06-26 18:13 UTC · model grok-4.3
The pith
PSCT-Net uses differentiable back-projection to build a spatially faithful prior that reduces depth ambiguity in pediatric skull CT reconstruction from bi-planar X-rays.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
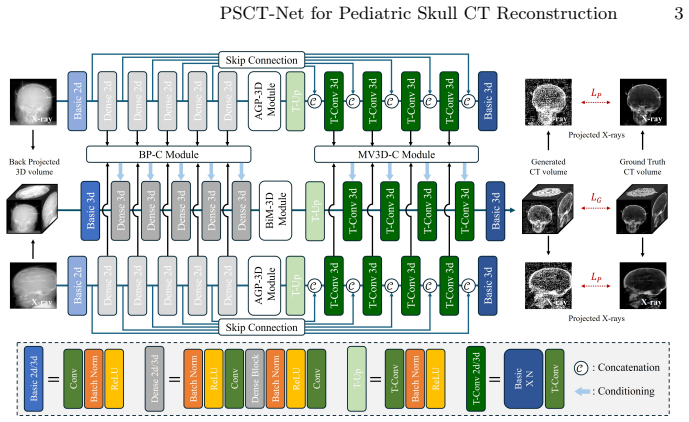
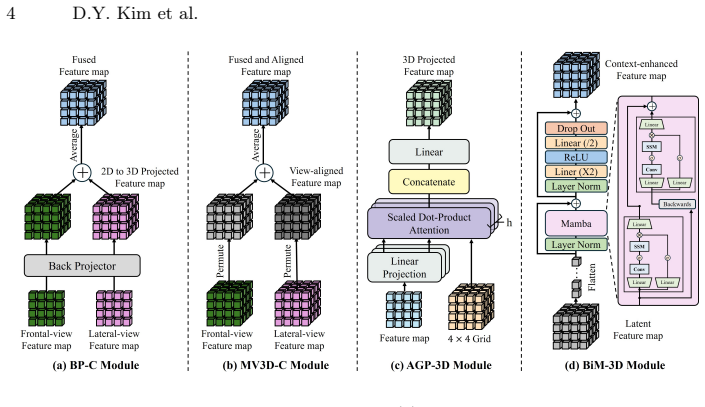
PSCT-Net establishes that differentiable back-projection can create a spatially faithful volumetric prior from sparse bi-planar X-rays, which reduces depth ambiguity. This is followed by the AGP-3D module learning non-linear voxel-wise correspondences and the BiM-3D module capturing long-range dependencies. The framework is tested on the PedSkull-CT dataset of normal and pathological pediatric cases.
What carries the argument
Differentiable back-projection that generates a spatially faithful volumetric prior from the 2D projections.
If this is right
- It offers a low-dose alternative to full CT for pediatric craniofacial diagnosis.
- It improves accuracy of osseous boundary reconstruction over geometry-agnostic methods.
- The BiM-3D enables linear-complexity modeling of volumetric dependencies.
- The PedSkull-CT dataset supports evaluation on both normal and abnormal cases.
Where Pith is reading between the lines
- The geometry-aware prior might apply to reconstruction tasks in other medical imaging domains with limited views.
- Combining this with other modalities could further improve accuracy.
- If the assumption holds, it could lead to changes in clinical protocols for pediatric imaging to reduce radiation.
Load-bearing premise
The differentiable back-projection and attention modules produce accurate osseous boundaries on real pediatric cases despite the reconstruction being severely ill-posed.
What would settle it
Showing that the method's reconstructions do not match ground truth CT bone boundaries better than existing methods on the PedSkull-CT dataset would challenge the central claim.
Figures
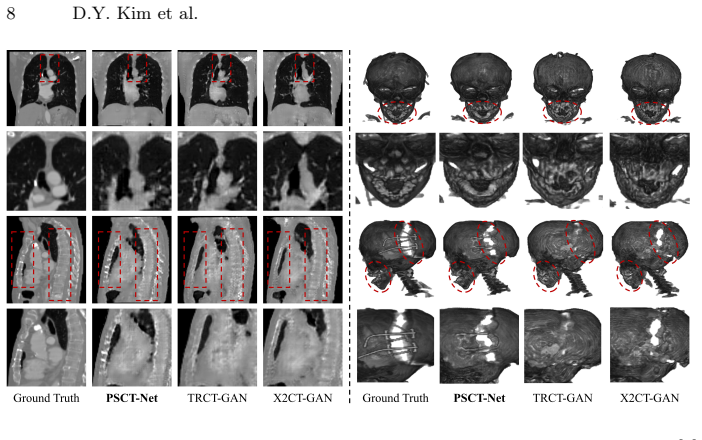
read the original abstract
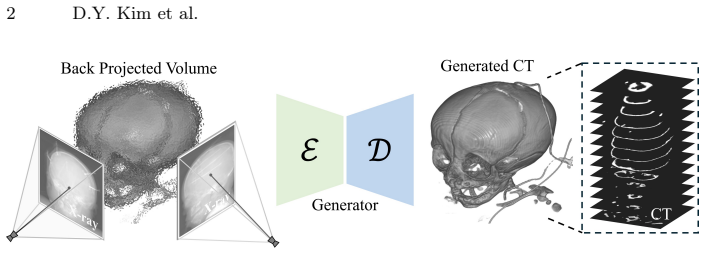
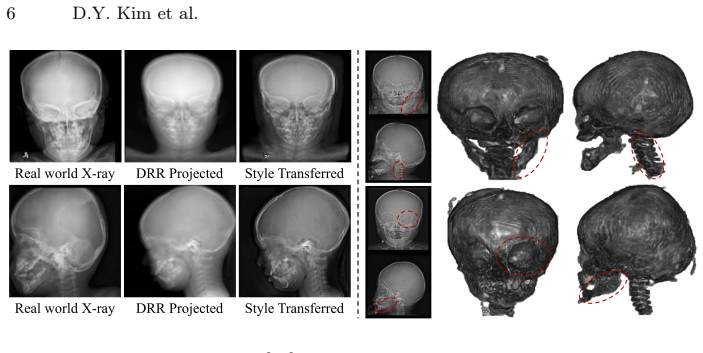
Computed Tomography (CT) is essential for diagnosing pediatric craniofacial abnormalities, yet poses radiation risks to developing anatomies. Reconstructing 3D CT from sparse bi-planar X-rays offers a low-dose alternative but is severely ill-posed. Existing methods employ geometry-agnostic feature lifting, naively projecting 2D features into 3D without explicit spatial modeling, causing depth ambiguity and degraded osseous boundaries. We present PSCT-Net, a geometry-aware framework with differentiable back-projection. Differentiable back-projection establishes a spatially faithful volumetric prior, alleviating depth ambiguity. An Attention-Guided Projection (AGP-3D) module then learns non-linear voxel-wise correspondences between 2D regions and 3D locations. A Bidirectional Mamba (BiM-3D) module captures long-range volumetric dependencies with linear complexity. We further curate a private institutional pediatric skull CT cohort, PedSkull-CT, comprising normal and pathological cases for internal evaluation, addressing the gap in adult-centric, trunk-focused datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PSCT-Net, a geometry-aware neural framework for reconstructing 3D pediatric skull CT volumes from sparse bi-planar X-rays. It introduces a differentiable back-projection operator to create a spatially faithful volumetric prior that reduces depth ambiguity, followed by an Attention-Guided Projection (AGP-3D) module for learning non-linear 2D-to-3D voxel correspondences and a Bidirectional Mamba (BiM-3D) module for efficient long-range volumetric dependency modeling. The work also curates a private PedSkull-CT dataset of normal and pathological pediatric cases to support evaluation, targeting limitations of adult-centric datasets.
Significance. If the empirical results support the claims, the geometry-aware reconstruction pipeline could enable clinically viable low-dose 3D imaging alternatives for pediatric craniofacial assessment, directly addressing radiation concerns and the scarcity of pediatric skull-specific benchmarks. The combination of explicit differentiable projection with attention and state-space modeling represents a targeted architectural response to the ill-posed inverse problem.
major comments (2)
- [Abstract] Abstract: the central claim that differentiable back-projection 'establishes a spatially faithful volumetric prior, alleviating depth ambiguity' is presented without any quantitative support, ablation, or comparison to geometry-agnostic baselines; this makes it impossible to assess whether the module delivers the stated benefit on real pediatric data.
- [Abstract] Abstract: no training details, loss formulation, or reconstruction metrics (e.g., Dice, surface distance, or clinical landmark error) are provided, so the assertion that AGP-3D and BiM-3D together produce accurate osseous boundaries cannot be evaluated against the acknowledged severity of the ill-posed problem.
Simulated Author's Rebuttal
We thank the referee for their comments. The abstract is intentionally concise as a high-level overview of the method and claims; all requested quantitative support, ablations, training details, loss formulations, and metrics are provided in the full manuscript body (Experiments, Ablation Studies, and Implementation Details sections). We address each point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that differentiable back-projection 'establishes a spatially faithful volumetric prior, alleviating depth ambiguity' is presented without any quantitative support, ablation, or comparison to geometry-agnostic baselines; this makes it impossible to assess whether the module delivers the stated benefit on real pediatric data.
Authors: The abstract summarizes the proposed approach and its motivation. Quantitative validation of the differentiable back-projection module—including direct comparisons to geometry-agnostic feature lifting baselines, ablation studies isolating its contribution, and metrics on the PedSkull-CT dataset—is reported in the Experiments and Ablation Studies sections. This follows standard practice where abstracts outline claims and the body supplies the supporting evidence. revision: no
-
Referee: [Abstract] Abstract: no training details, loss formulation, or reconstruction metrics (e.g., Dice, surface distance, or clinical landmark error) are provided, so the assertion that AGP-3D and BiM-3D together produce accurate osseous boundaries cannot be evaluated against the acknowledged severity of the ill-posed problem.
Authors: Abstracts in this field conventionally omit implementation specifics and numerical results to remain within length limits. The full manuscript details the training protocol, loss formulation (combining reconstruction, projection consistency, and regularization terms), and reports Dice scores, surface distances, and clinical landmark errors in the Results section, directly evaluating performance on the ill-posed bi-planar reconstruction task using the PedSkull-CT dataset. revision: no
Circularity Check
No significant circularity; derivation self-contained with no reductions to inputs or self-citations
full rationale
The provided abstract and description contain no equations, fitted parameters, or derivation steps that could be inspected for self-definition, fitted-input-as-prediction, or load-bearing self-citation. Claims about differentiable back-projection, AGP-3D, and BiM-3D are presented as architectural contributions without any reduction shown to prior outputs or internal fits. The curation of PedSkull-CT is an independent data contribution. No load-bearing premise relies on author-overlapping citations or ansatzes smuggled via prior work. The central reconstruction approach therefore remains independent of its own outputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Radiology232(3), 739–748 (2004)
Armato III, S.G., McLennan, G., McNitt-Gray, M.F., Meyer, C.R., Yankelevitz, D., Aberle, D.R., Henschke, C.I., Hoffman, E.A., Kazerooni, E.A., MacMahon, H., et al.: Lung image database consortium: developing a resource for the medical imaging research community. Radiology232(3), 739–748 (2004)
2004
-
[2]
arXiv preprint arXiv:2406.04679 (2024)
Bai, Q., Liu, T., Liu, Z., Tong, Y., Torigian, D., Udupa, J.: Xctdiff: Reconstruction of ct images with consistent anatomical structures from a single radiographic projection image. arXiv preprint arXiv:2406.04679 (2024)
arXiv 2024
-
[3]
Bick, A., Li, K.Y., Xing, E.P., Kolter, J.Z., Gu, A.: Transformers to ssms: Distilling quadratic knowledge to subquadratic models. arXiv preprint arXiv:2408.10189 (2024). https://doi.org/10.48550/arXiv.2408.10189
-
[4]
New England journal of medicine357(22), 2277–2284 (2007)
Brenner, D.J., Hall, E.J.: Computed tomography—an increasing source of radiation exposure. New England journal of medicine357(22), 2277–2284 (2007)
2007
-
[5]
Computers in biology and medicine154, 106615 (2023)
Chen, Z., Guo, L., Zhang, R., Fang, Z., He, X., Wang, J.: Bx2s-net: Learning to reconstruct 3d spinal structures from bi-planar x-ray images. Computers in biology and medicine154, 106615 (2023)
2023
-
[6]
Deng, Y., Wang, C., Hui, Y., Li, Q., Li, J., Luo, S., Sun, M., Quan, Q., Yang, S., Hao, Y., Liu, P., Xiao, H., Zhao, C., Wu, X., Zhou, S.K.: Ctspine1k: A large- scale dataset for spinal vertebrae segmentation in computed tomography (2024), https://arxiv.org/abs/2105.14711
arXiv 2024
-
[7]
Knowledge-Based Systems236, 107680 (2022)
Ge, R., He, Y., Xia, C., Xu, C., Sun, W., Yang, G., Li, J., Wang, Z., Yu, H., Zhang, D., et al.: X-ctrsnet: 3d cervical vertebra ct reconstruction and segmentation directly from 2d x-ray images. Knowledge-Based Systems236, 107680 (2022)
2022
-
[8]
Goske, M.J., Applegate, K.E., Boylan, J., Butler, P.F., Callahan, M.J., Coley, B.D., Farley, S., Frush, D.P., Hernanz-Schulman, M., Jaramillo, D., et al.: The image gently campaign: working together to change practice (2008)
2008
-
[9]
In: First conference on language modeling (2024)
Gu, A., Dao, T.: Mamba: Linear-time sequence modeling with selective state spaces. In: First conference on language modeling (2024)
2024
-
[10]
In: Computer Graphics Forum
Henzler, P., Rasche, V., Ropinski, T., Ritschel, T.: Single-image tomography: 3d volumes from 2d cranial x-rays. In: Computer Graphics Forum. vol. 37, pp. 377–388. Wiley Online Library (2018)
2018
-
[11]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Isola, P., Zhu, J.Y., Zhou, T., Efros, A.A.: Image-to-image translation with condi- tional adversarial networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1125–1134 (2017)
2017
-
[12]
SIAM (2001)
Kak, A.C., Slaney, M.: Principles of computerized tomographic imaging. SIAM (2001)
2001
-
[13]
ACM Trans
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph.42(4), 139–1 (2023) 10 D.Y. Kim et al
2023
-
[14]
Studies in Health Technology and Informatics329, 578–582 (2025)
Kim, D.Y., Kim, J.W., Kim, S.K., Kim, Y.G.: Multi-modal and multi-view fu- sion classifier for craniosynostosis diagnosis. Studies in Health Technology and Informatics329, 578–582 (2025)
2025
-
[15]
Liu, P., Han, H., Du, Y., Zhu, H., Li, Y., Gu, F., Xiao, H., Li, J., Zhao, C., Xiao, L., Wu, X., Zhou, S.K.: Deep learning to segment pelvic bones: Large-scale ct datasets and baseline models (2021), https://arxiv.org/abs/2012.08721
arXiv 2021
-
[16]
In: European conference on computer vision
Liu, X., Qiao, Z., Liu, R., Li, H., Zhang, J., Zhen, X., Qian, Z., Zhang, B.: Diffux2ct: Diffusion learning to reconstruct ct images from biplanar x-rays. In: European conference on computer vision. pp. 458–476. Springer (2024)
2024
-
[17]
arXiv preprint arXiv:2401.04722 (2024)
Ma,J.,Li,F.,Wang,B.:U-mamba:Enhancinglong-rangedependencyforbiomedical image segmentation. arXiv preprint arXiv:2401.04722 (2024)
Pith/arXiv arXiv 2024
-
[18]
In: Proceedings of the IEEE international conference on computer vision
Mao, X., Li, Q., Xie, H., Lau, R.Y., Wang, Z., Paul Smolley, S.: Least squares gen- erative adversarial networks. In: Proceedings of the IEEE international conference on computer vision. pp. 2794–2802 (2017)
2017
-
[19]
Radiology248(1), 254–263 (2008)
Mettler Jr, F.A., Huda, W., Yoshizumi, T.T., Mahesh, M.: Effective doses in radiology and diagnostic nuclear medicine: a catalog. Radiology248(1), 254–263 (2008)
2008
-
[20]
Commu- nications of the ACM65(1), 99–106 (2021)
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Commu- nications of the ACM65(1), 99–106 (2021)
2021
-
[21]
Physics in Medicine & Biology45(10), 2787 (2000)
Milickovic, N., Baltas, D., Giannouli, S., Lahanas, M., Zamboglou, N.: Ct imaging based digitally reconstructed radiographs and their application inbrachytherapy. Physics in Medicine & Biology45(10), 2787 (2000)
2000
-
[22]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Peng, C., Liao, H., Wong, G., Luo, J., Zhou, S.K., Chellappa, R.: Xraysyn: Realistic view synthesis from a single radiograph through ct priors. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 35, pp. 436–444 (2021)
2021
-
[23]
ACM Transactions on Multimedia Computing, Communications and Applications (2024)
Ruan, J., Li, J., Xiang, S.: Vm-unet: Vision mamba unet for medical image seg- mentation. ACM Transactions on Multimedia Computing, Communications and Applications (2024)
2024
-
[24]
Nature biomedical engineering3(11), 880–888 (2019)
Shen, L., Zhao, W., Xing, L.: Patient-specific reconstruction of volumetric com- puted tomography images from a single projection view via deep learning. Nature biomedical engineering3(11), 880–888 (2019)
2019
-
[25]
arXiv preprint arXiv:2010.02502 (2020)
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502 (2020)
Pith/arXiv arXiv 2010
-
[26]
Radiology173(3), 669–673 (1989)
Vannier, M.W., Hildebolt, C.F., Marsh, J.L., Pilgram, T.K., McAlister, W.H., Shackelford, G.D., Offutt, C.J., Knapp, R.H.: Craniosynostosis: diagnostic value of three-dimensional ct reconstruction. Radiology173(3), 669–673 (1989)
1989
-
[27]
Advances in neural information processing systems30(2017)
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information processing systems30(2017)
2017
-
[28]
arXiv preprint arXiv:2002.10957 (2020)
Wang, W., Wei, F., Dong, L., Bao, H., Yang, N., Zhou, M.: Minilm: Deep self- attention distillation for task-agnostic compression of pre-trained transformers. arXiv preprint arXiv:2002.10957 (2020)
arXiv 2002
-
[29]
Digital Signal Processing140, 104123 (2023)
Wang, Y., Sun, Z.L., Zeng, Z., Lam, K.M.: Trct-gan: Ct reconstruction from biplane x-rays using transformer and generative adversarial networks. Digital Signal Processing140, 104123 (2023)
2023
-
[30]
arXiv preprint arXiv:2503.17804 (2025) PSCT-Net for Pediatric Skull CT Reconstruction 11
Xie, X., Liu, J., Fan, H., Han, Z., Tang, Y., Qu, L.: Dvg-diffusion: Dual-view guided diffusion model for ct reconstruction from x-rays. arXiv preprint arXiv:2503.17804 (2025) PSCT-Net for Pediatric Skull CT Reconstruction 11
arXiv 2025
-
[31]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ying, X., Guo, H., Ma, K., Wu, J., Weng, Z., Zheng, Y.: X2ct-gan: reconstructing ct from biplanar x-rays with generative adversarial networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10619–10628 (2019)
2019
-
[32]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586–595 (2018)
2018
-
[33]
In: Proceedings of the IEEE international conference on computer vision
Zhu, J.Y., Park, T., Isola, P., Efros, A.A.: Unpaired image-to-image translation using cycle-consistent adversarial networks. In: Proceedings of the IEEE international conference on computer vision. pp. 2223–2232 (2017)
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.